用于图像数据增强的深度学习
前言
数据增强意味着增加数据量。对于深度学习,大量的数据可以训练出更好的深度学习模型。
在图像增强方面,我们常用的方法如下:
- 旋转
- 翻动
- 飞涨
- 平底锅
- 缩放
- 对比度变换
- 噪音干扰
- 颜色变换
1. 使用tensorflow2.X的ImageDataGenerator进行数据增强

经过如下代码可以在img_temp文件夹中生成20张经过数据增强的图片
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
import numpy as np
# ---------------------------------- #
# 训练集进行的数据增强操作
# 1. rotation_range -> 随机旋转角度
# 2. width_shift_range -> 随机水平平移
# 3. width_shift_range -> 随机数值平移
# 4. rescale -> 数据归一化
# 5. shear_range -> 随机错切变换
# 6. zoom_range -> 随机放大
# 7. horizontal_flip -> 水平翻转
# 8. brightness_range -> 亮度变化
# 9. fill_mode -> 填充方式
# ---------------------------------- #
train_data = ImageDataGenerator(
rotation_range=50,
width_shift_range=0.1,
height_shift_range=0.1,
rescale=1/255.0,
shear_range=10,
zoom_range=0.1,
horizontal_flip=True,
brightness_range=(0.7, 1.3),
fill_mode='nearest'
)
img = load_img('./img/cat.8662.jpg')
img = img_to_array(img)
img = np.expand_dims(img, 0)
i = 0
for j in train_data.flow(img, batch_size=1, save_to_dir='img_temp', save_prefix='cat', save_format='jpeg'):
i += 1
if i == 20:
break

具体的函数说明可以在tensorflow官网中找到
以下是我经常使用的几个函数
def data_process(self, file_path, y):
img = tf.io.read_file(filename=file_path)
img = tf.image.decode_jpeg(img, channels=3)
# 归一化
img = tf.cast(img, tf.float32) / 255.0
# 数据预处理
# 1. 调节亮度
# 2. 随机调节对比度
# 3. 随机水平翻转一个图像(从左到右)
# 4. 垂直随机翻转图像(上下颠倒)
img = tf.image.random_brightness(img, 0.2)
img = tf.image.random_contrast(img, 0.2, 0.4)
img = tf.image.random_flip_left_right(img)
img = tf.image.random_flip_up_down(img)
img = tf.image.resize(img, size=self.input_size)
return img, y
2. 使用Albumentations进行数据增强
2.1 图像分类
import albumentations
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
"""
RandomGamma: 随机灰度系数
RandomBrightnessContrast: 随机改变输入图像的亮度和对比度
CLAHE: 自适应直方图均衡
HorizontalFlip: 围绕y轴水平翻转输入
ShiftScaleRotate: 随机平移,缩放和旋转输入
ColorJitter: 随机改变图像的亮度、对比度和饱和度
"""
train_transform = albumentations.Compose([
albumentations.OneOf([
albumentations.RandomGamma(gamma_limit=(60, 120), p=0.9),
albumentations.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.9),
albumentations.CLAHE(clip_limit=4.0, tile_grid_size=(4, 4), p=0.9),
albumentations.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, always_apply=False, p=0.5)
]),
albumentations.HorizontalFlip(p=0.7),
albumentations.ShiftScaleRotate(p=1),
albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)
])
img = Image.open('./img/cat.8662.jpg')
img = np.array(img)
img = train_transform(image=img)['image']
plt.imshow(img)
plt.show()
结果如下: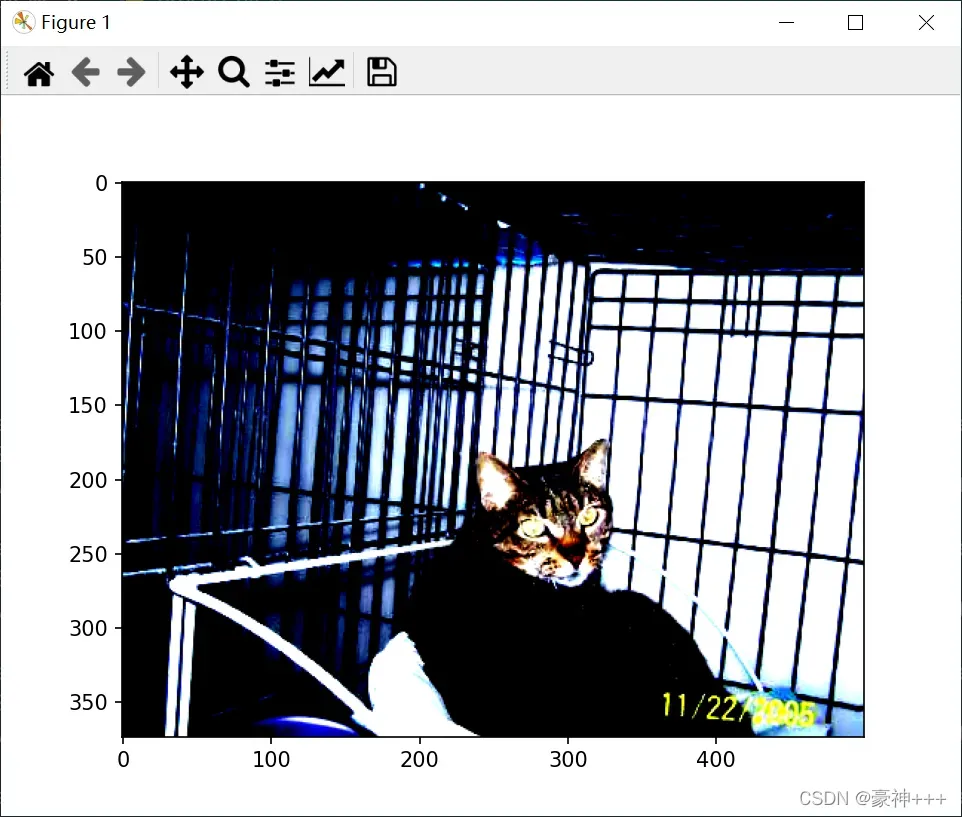
2.2 目标检测
此部分来自AI浩
import random
import cv2
from matplotlib import pyplot as plt
import albumentations as A
BOX_COLOR = (255, 0, 0) # Red
TEXT_COLOR = (255, 255, 255) # White
# 定义画框的函数
def visualize_bbox(img, bbox, class_name, color=BOX_COLOR, thickness=2):
"""Visualizes a single bounding box on the image"""
x_min, y_min, w, h = bbox
x_min, x_max, y_min, y_max = int(x_min), int(x_min + w), int(y_min), int(y_min + h)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color=color, thickness=thickness)
((text_width, text_height), _) = cv2.getTextSize(class_name, cv2.FONT_HERSHEY_SIMPLEX, 0.35, 1)
cv2.rectangle(img, (x_min, y_min - int(1.3 * text_height)), (x_min + text_width, y_min), BOX_COLOR, -1)
cv2.putText(
img,
text=class_name,
org=(x_min, y_min - int(0.3 * text_height)),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.35,
color=TEXT_COLOR,
lineType=cv2.LINE_AA,
)
return img
# 定义可视化函数
def visualize(image, bboxes, category_ids, category_id_to_name):
img = image.copy()
for bbox, category_id in zip(bboxes, category_ids):
class_name = category_id_to_name[category_id]
img = visualize_bbox(img, bbox, class_name)
plt.figure(figsize=(12, 12))
plt.axis('off')
plt.imshow(img)
plt.show()
# 299, 160, 446, 252
image = cv2.imread('./img/000013.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
bboxes = [[299, 160, 147, 92]]
category_ids = [17]
category_id_to_name = {17: 'cow'}
visualize(image, bboxes, category_ids, category_id_to_name)
# 数据增强
"""
RandomSizedBBoxSafeCrop裁剪图像的随机部分。它确保裁剪的部分将包含来自原始图像的所有边界框。
然后转换缩放作物的高度和宽度指定由各自的参数。侵蚀率参数控制了种植后原始包围盒的损失面积。
Erosion_rate = 0.2意味着增强的包围框的面积可能比原来的包围框的面积小20%。
"""
transform = A.Compose(
[A.RandomSizedBBoxSafeCrop(width=448, height=336, erosion_rate=0.2),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, always_apply=False, p=0.5),
A.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.9),
A.ShiftScaleRotate(p=1)
],
bbox_params=A.BboxParams(format='coco', label_fields=['category_ids']),
)
transformed = transform(image=image, bboxes=bboxes, category_ids=category_ids)
visualize(
transformed['image'],
transformed['bboxes'],
transformed['category_ids'],
category_id_to_name,
)
结果如下:
原图:
数据增强后:
版权声明:本文为博主豪神+++原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42025868/article/details/123031339