论文标题:FastNeRF: High-Fidelity Neural Rendering at 200FPS (ICCV 2021)
建议预备知识:NeRF (BV1c34y1B7Hx)
论文链接:https://arxiv.org/abs/2103.10380

Abstract
最近对神经辐射场(NeRF)的研究表明,神经网络如何被用来编码复杂的3D环境,可以从新的视角光现实地photorealistically呈现rendered。渲染这些图像对计算量的要求非常高,而且最近的改进距离实现交互式速率还有很长的路要走,即使是在高端硬件上。基于移动和混合现实设备上的场景,我们提出了FastNeRF,这是第一个基于nerf的系统,能够在高端消费GPU上以200Hz的高保真逼真图像。我们的方法的核心是一个受图形启发的因子分解,它允许(i)在空间中的每个位置紧凑地缓存一个深度辐射地图,compactly caching a deep radiance map at each position in space,(ii)使用光线方向有效地查询该地图,以估计渲染图像中的像素值。大量的实验表明,该方法比原来的NeRF算法速度快3000倍,比现有的加速NeRF算法速度快至少一个数量级的速度,同时保持了视觉质量和可扩展性。

图1。FastNeRF以每秒数百帧的速度呈现高分辨率的逼真新视图。现有的类似方法,如NeRF,要慢几个数量级,只能以交互率呈现非常低分辨率的图像。
1.Introduction
所有基于nerf的方法面临的一个共同挑战是它们对渲染图像的高计算要求。这个挑战的核心在于NeRF的体积场景表示。
为了实现这个目标,我们使用缓存caching来交换内存memory,以提高计算效率。由于NeRF本质上是位置p∈R3和射线方向d∈R2到颜色c∈R3(RGB)和标量密度σ的函数,一种简单方法是在其输入参数的空间中建立该函数的缓存表示。由于σ只依赖于p,所以可以使用现有的方法来缓存它。然而,颜色c是射线方向d和位置p的函数。如果将这个5维空间离散化,每个维有512个bins,那么将需要大约176tb的内存——远远超过当前消费硬件上可用的内存。
理想情况下,我们应该分别处理方向和位置,从而避免在所需的缓存空间中的多项式爆炸。幸运的是,这个问题并不是NeRF所独有的;渲染方程(调制光的波长和时间)也是R5的函数,并有效地解决它是实时计算机图形学的主要挑战。因此,有大量的研究来研究近似这个函数的方法以及计算积分的有效方法。渲染方程最快的近似之一涉及使用球谐波,这样积分得到材料模型和照明模型的谐波系数的点积。受这种有效近似的启发,我们将问题分解为两个独立的函数,它们的输出用它们的内积组合来产生RGB值。第一个函数采用多层感知器(MLP)的形式,它以空间中的位置为条件,并返回一个由D分量参数化的紧凑的深辐射映射。第二个函数是一个以射线方向为条件的MLP,它为D深辐射映射分量产生D权重。
这种分解的架构,我们称之为FastNeRF,允许独立地缓存与位置相关和射线方向相关的输出。假设k和l分别表示位置和射线方向的bins箱数,缓存NeRF的内存复杂度为O(k3l2)。相比之下,缓存FastNeRF的复杂度为O(k3∗(1+D∗3)+l2∗D)。

由于这种内存复杂性的降低,FastNeRF可以缓存在高端消费GPU的内存中,从而实现非常快速的函数查找时间,从而导致测试时间性能的显著提高。
虽然缓存确实消耗了大量的内存,但值得注意的是,当前的NeRF实现也有很大的内存需求。NeRF的单个正向传递需要通过每像素的8层256隐藏单元MLP执行数百个正向传递。如果为了提高效率而并行处理像素,这将消耗大量的内存,即使是在中等分辨率下。由于许多自然场景(例如,客厅、花园)都非常稀疏,因此我们能够稀疏地存储我们的缓存。在某些情况下,这可以使我们的方法实际上比NeRF更节省内存。
总之,我们的主要贡献是:
- 第一个基于NeRF的系统,能够以200FPS的速度呈现逼真的新视图,比NeRF快数千倍。
- 一种受图形启发的因子分解,可以紧凑地缓存并随后查询以计算渲染图像中的像素值。
- 一个详细介绍了所拟议的因式分解如何在GPU上有效运行的蓝图。
3. Method
在本节中,我们将描述FastNeRF方法,这种方法比原始的神经辐射场(NeRF)系统[27]快3000倍(第3.1节)。这一突破允许在高端消费硬件上以超过200赫兹的频率渲染高分辨率的逼真图像。我们的方法的核心见解(第3.2节)包括将NeRF分解为两个神经网络:一个产生深度辐射图的位置依赖网络和一个产生权重的方向依赖网络。权重和深辐射图的内积估计了场景中在指定位置和从指定方向看到的颜色。这种架构,我们称之为FastNeRF,可以有效地缓存(第3.3节),显著地提高了测试时间效率,同时保持了NeRF的视觉质量。NeRF和FastNeRF网络架构的比较见图2。
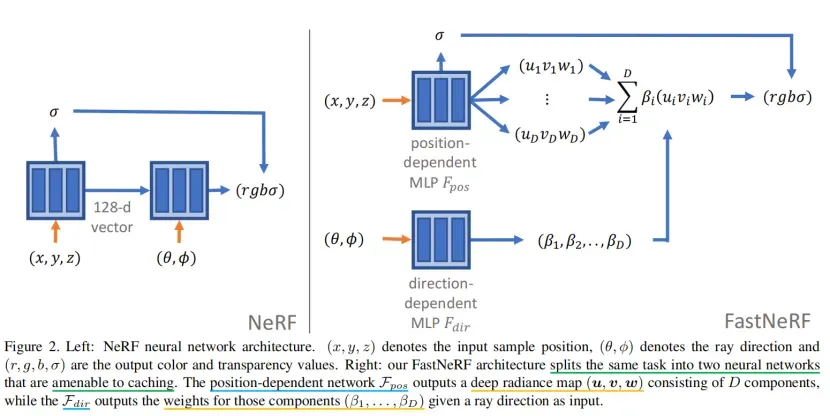
图2。左图:NeRF神经网络架构。(x、y、z)表示输入样本位置,(θ、φ)表示光线方向,(r、g、b、σ)为输出颜色和透明度值。右图:我们的FastNeRF架构将相同的任务分成两个易于缓存的神经网络。与位置相关的网络Fpos输出一个由D分量组成的深度辐射图(u,v,w),而Fdir输出这些分量的权重(β1,…,βD)作为输入。
3.1. Neural Radiance Fields
FNeRF : (p, d) → (c, σ),三维位置p∈R3和射线方向d∈R2到颜色值c和透明度σ。由于FNeRF依赖于射线方向,NeRF能够建模视点依赖的效应,如镜面反射,这是NeRF对传统三维重建方法的改进的一个关键维度。
训练一个NeRF网络需要一组场景的图像,以及捕捉图像的相机的外在和内在参数。在每次训练迭代中,从训练图像中随机选择一个像素的子集,并为每个像素生成一个三维射线。然后,沿着每条射线选择一组样本,并利用等式(1)计算像素颜色cˆ。
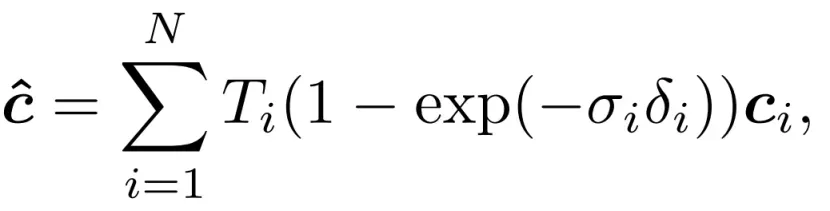
3.2. Factorized 因子分解的Neural Radiance Fields
远离神经渲染,我们记得在传统的计算机图形中,渲染方程[10]是形式的积分
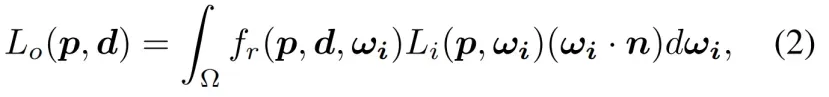
其中Lo(p、d)是离开d方向点p的辐射,fr(p、d、ωi)是捕获位置p处的材料特性的反射率函数,Li(p、ωi)描述了从ωi方向到达到p的光量,n对应于p方向的表面法线方向。

鉴于它的实际重要性,有效地评估这个积分一直是一个积极研究的课题,超过三十年的[10,44,9,35]。评价渲染方程的一种有效方法是用球谐波[4,47]近似fr(p,d,ωi)和Li(p,ωi)。

在这种情况下,积分的计算归结为两个球谐波近似的系数之间的点积。
有了这种见解,我们就可以回到神经渲染上来了。在NeRF的情况下,FNeRF:(p,d)也可以解释为在方向d上返回辐射离开点p。

这一关键的见解促使我们提出了一种新的网络网络架构,我们称之为FastNeRF。这种新颖的架构包括将NeRF的神经网络FNeRF分解为两个网络:一个只依赖于位置p,另一个只依赖于射线方向d。类似于使用球谐波评估渲染方程,我们的位置相关的Fpos和方向相关的Fdir函数产生的输出使用点积组合,以获得从方向d观察到的位置p的颜色值。至关重要的是,这种分解将一个接受r5输入的函数分解为两个函数,即接受r3和r2输入的函数。

如下一节所解释的,这使得缓存网络的输出成为可能,并允许在消费硬件上加速NeRF 3个数量级。图3是已实现的加速的可视化表示。
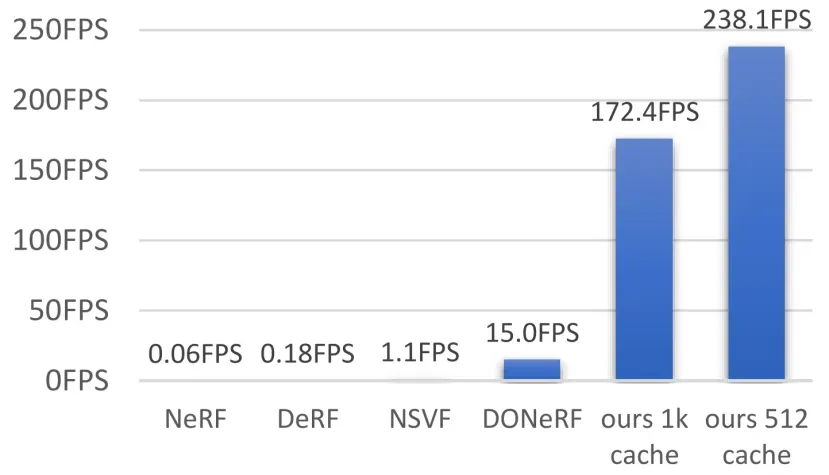
图3。速度评估我们的方法和之前的工作[27,37,18,30]在乐高场景从现实的360合成[27]数据集,渲染在800×800像素。对于之前的方法,当乐高场景的数字不可用时,我们使用了一个乐观的近似。
FastNeRF的位置依赖函数和方向依赖函数定义如下:
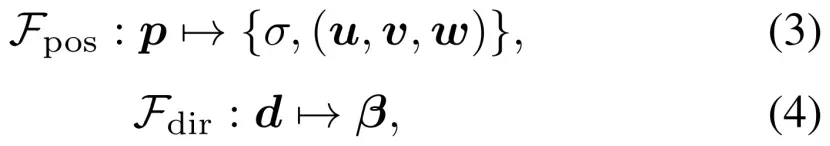
其中u,v,w是d维向量,形成一个深度辐射映射deep radiance map,描述了位置p处的视图相关辐射。Fdir,β的输出是深度辐射图的D分量的D维权重向量。权重和深辐射图的内积
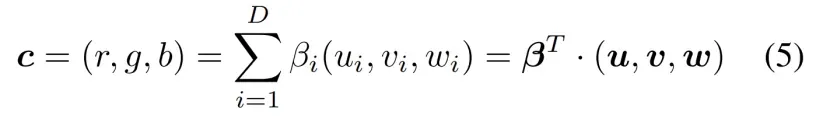
产生从d方向观察到的p位置的颜色c=(r,g,b)。
当使用公式(5)组合这两个函数时,得到的函数FFastNeRF(p,d)→(c,σ)与NeRF中使用的函数FNeRF具有相同的签名。

这有效地允许在运行时使用FastNeRF体系结构作为NeRF体系结构的临时替代品。
3.3. Caching
考虑到渲染单个像素需要评估的大量样本,计算F的成本主导了NeRF渲染的总成本。因此,为了加速NeRF,人们可以尝试通过缓存其对覆盖场景空间的一组输入的输出来降低F的测试时间成本。然后,可以用计算F所需时间的一小部分来计算缓存。
对于一个训练过的NeRF模型,我们可以定义一个边界框bounding box V,它覆盖了由NeRF捕获的整个场景。然后,我们可以在v的范围内对3个世界空间坐标(x,y,z)=p的k个值进行均匀采样。类似地,我们用θ∈h0,πi和φ∈h0,2πi对每个射线方向坐标(θ,φ)=d进行均匀采样l值。然后通过计算采样p和d的每个组合的F来生成缓存。

对于具有k=l=1024和密集存储的16位浮点值的标准NeRF模型,这种缓存的大小约为5600tb。即使对于高度稀疏的卷,人们只需要保留1%的输出,缓存的大小仍然会严重超过消费级硬件的内存容量。这种巨大的内存需求是由于同时使用了d和p作为FNeRF的输入而造成的。需要为d和p的每个组合保存一个单独的输出,从而导致内存复杂度为O(k3l2)。
我们的FastNeRF架构使缓存成为可行的。对于k=l=1024,D=8,两个包含{σ,(u,v,w))}和β的大小大约为54GB。对于中等稀疏的卷,其中占用了30%的空间,内存需求足够低,以适合消费级机器的CPU或GPU内存。在实践中,选择k和l取决于场景的大小和预期的图像分辨率。对于许多场景,一个较小的缓存k=512,l=256就足够了,这进一步降低了内存需求。请参阅用于计算这两种网络架构的缓存大小的公式的补充材料。
4. Implementation
除了使用第3.2节中描述的FastNeRF体系结构外,训练FastNeRF与训练NeRF[27]是相同的。我们分别使用8层和4层MLPs对FastNeRF的Fpos和Fview进行建模,并对输入[27]进行位置编码。8层的MLP有384个隐藏单元,我们使用128个隐藏单元来进行视图预测的4层网络。唯一的例外是新场景,我们发现256 MLP对8层MLP有更好的结果。虽然这使得网络大于基线,但缓存查找速度不受MLP复杂性的影响。与NeRF类似,我们将视图方向参数化为一个三维单位向量。其他的训练时间特征和设置包括粗/细网络和样本计数N遵循原始的NeRF工作[27](请见补充材料)。
在测试时,我们的方法和NeRF都将一组相机参数作为输入,用于为输出中的每个像素生成一条射线。然后沿着每条射线生产一些样品,并按照第3.1节进行集成。虽然FastNeRF可以使用其神经网络表示来执行,但在缓存时其性能大大提高。为了进一步提高性能,我们使用硬件加速光线追踪[34]跳过空白空间,在第一次接触来自密度体积的碰撞网格后才开始积分沿射线的点,然后访问每个体素,直到光线的透射率饱和。碰撞网格可以通过标记立方体[22]从密度体积导出的符号距离函数计算。对于大于5123的卷,我们首先将体积降采样2倍,以降低网格复杂度。我们对所有场景和数据集使用相同的网格划分和集成参数。值查找使用最近邻插值,Fview使用三线性采样,后者可以用高斯核或其他核进行处理,以“平滑”或编辑方向效果。我们注意到,从缓存中派生出的网格和卷也可以用于在路径跟踪框架中提供对阴影和全局照明的近似值。
5. Experiments
6. Application
7.结论
在本文中,我们提出了FastNeRF,这是一种新的NeRF扩展,可以在消费者硬件consumer hardware上渲染200hz或更多的逼真图像。通过分解NeRF的函数近似器,我们实现了显著的加速,实现了一个缓存步骤,使渲染内存绑定memory-bound而不是计算绑定。这允许将NeRF应用于实时场景。
文章出处登录后可见!