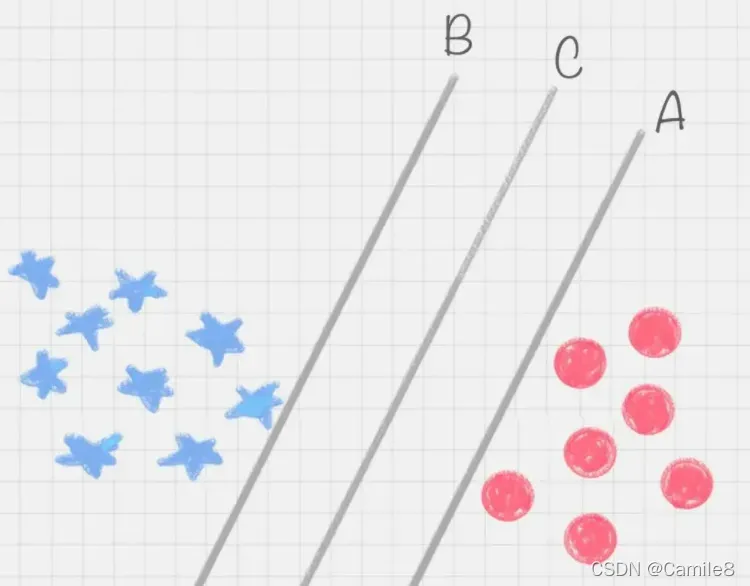
A,B,C这三条直线,都可以把红蓝球给分开。究竟哪一个最好呢?
相比于直线 A 和直线 B,直线 C 的划分更优,容错能力比较强。不会轻易的分错红色球和蓝色球。
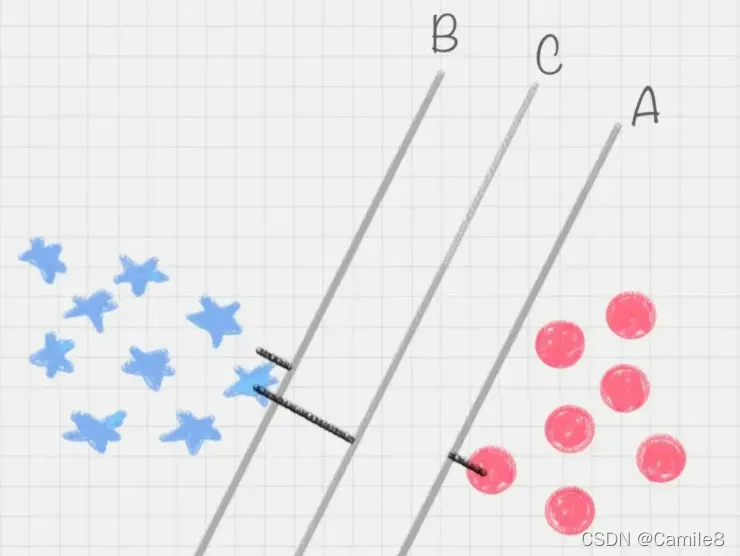
在保证决策面不变,且分类不产生错误的情况下,我们可以移动决策面 C,直到产生两个极限的位置:如图中的决策面 A 和决策面 B。极限的位置是指,如果越过了这个位置,就会产生分类错误。这样的话,两个极限位置 A 和 B 之间的分界线 C 就是最优决策面。转动这个最优决策面,你会发现可能存在多个最优决策面,它们都能把数据集正确分开,这些最优决策面的分类间隔可能是不同的,而那个拥有“最大间隔”(max margin)的决策面就是 SVM 要找的最优解。那么怎么确定最大间隔呢?
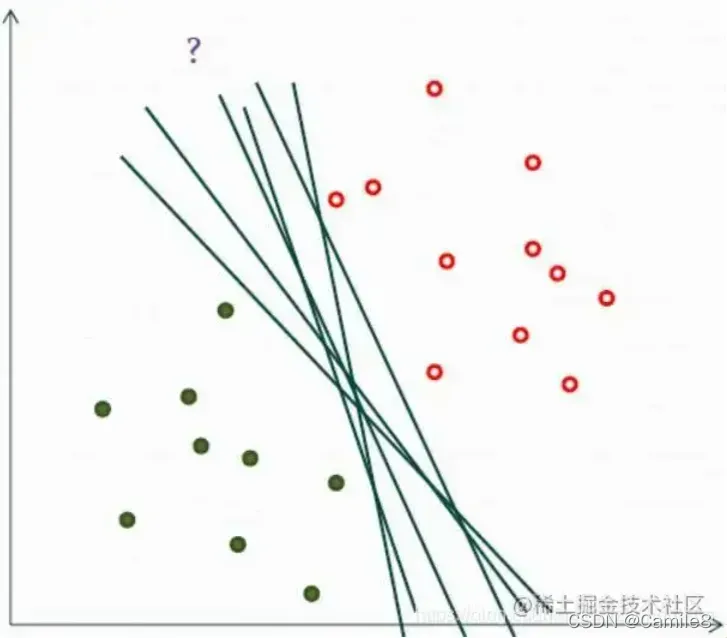
如果我们把红球和蓝球放到一个三维空间中,你会发现决策面变成了一个平面。这里有几个术语:
- 分离超平面:即能分离样本的最优超平面
- 支撑超平面:是分离超平面平移到极限位置后的两条直线
- 分离间隔:支撑超平面之间的距离
- 支持向量:它是这两个极端位置的样本。 (只有支持向量对确定分离超平面起作用,其他实例点没有。由于支持向量对确定分离超平面起决定性作用,所以这种模型称为支持向量机)
上面的例子是硬区间,也就是说分类完全准确,不能有误分类。还有软边距,允许一定数量的样本分类错误。
实际工作中的数据没有那么“干净”,或多或少都会存在一些噪点。所以线性可分是个理想情况。这时,我们需要使用到软间隔 SVM(近似线性可分),比如下面这种情况:允许有分类错误的点,但是尽可能的少就可以了。这个也是转成拉格朗日对偶问题进行求解
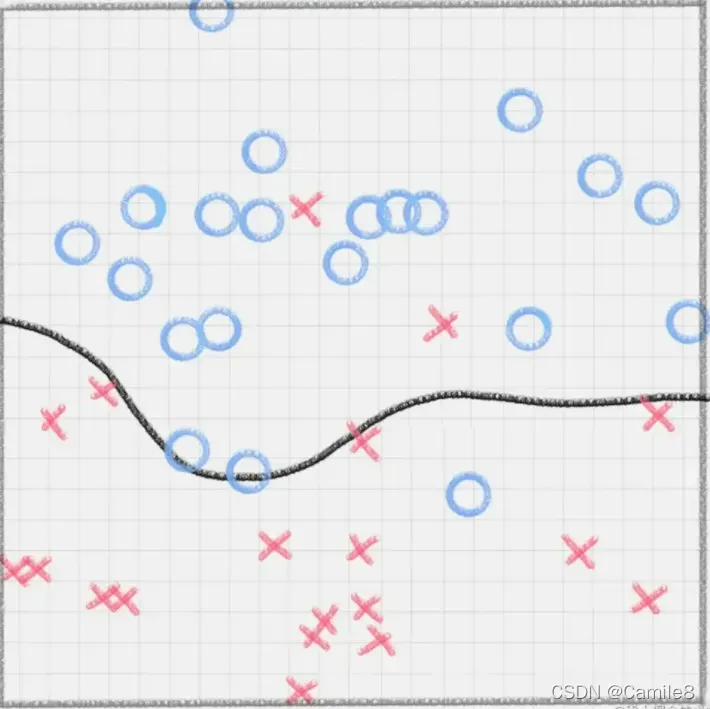
还存在一种情况,就是非线性支持向量机。图中的两类数据,分别分布为两个圆圈的形状。那么这种情况下,不论是多高级的分类器,只要映射函数是线性的,就没法处理,SVM 也处理不了。
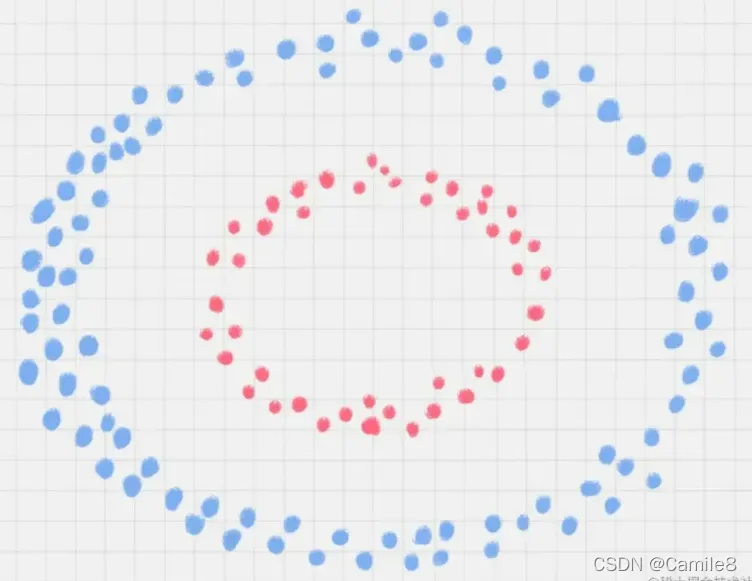
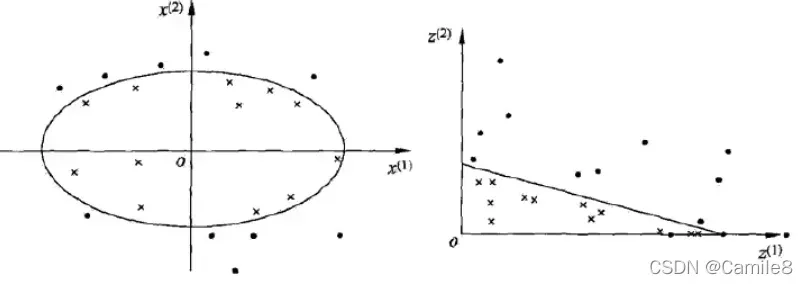
引入一个新概念:核函数。它可以将样本从原始空间映射到更高维的异质空间,使样本在新空间中线性可分。这样我们可以使用原始推导进行计算,只有所有推导都在新空间而不是原始空间中完成。
SVM 本身是一个二值分类器,最初是为二分类问题设计的,也就是回答 Yes 或者是 No。而实际上我们要解决的问题,可能是多分类的情况,比如对文本进行分类,或者对图像进行识别。
针对这种情况,我们可以将多个二元分类器组合成一个多分类器。常见的方法包括“一对多方法”和“一对一方法”。
# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(train_X,train_y)
# 用测试集做预测
prediction=model.predict(test_X)
print('准确率: ', metrics.accuracy_score(prediction,test_y))
# 运行结果
准确率: 0.9181286549707602
参考:【白话机器学习】算法理论+实战之支持向量机(SVM) – 掘金 (juejin.cn)
版权声明:本文为博主Camile8原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/lipeitong333/article/details/123042687