2020年2月21日,Joseph Redmon 宣布退出计算机视觉领域,表明不再更YOLOv3。之后AlexeyAB 继承了 YOLO 系列的思想和理念,在 YOLOv3 的基础上不断进行改进和开发,于该年四月份发布了 YOLOv4。并得到了原作者 Joseph Redmon 的承认。
YOLOV4论文: https://arxiv.org/pdf/2004.10934.pdf
内容
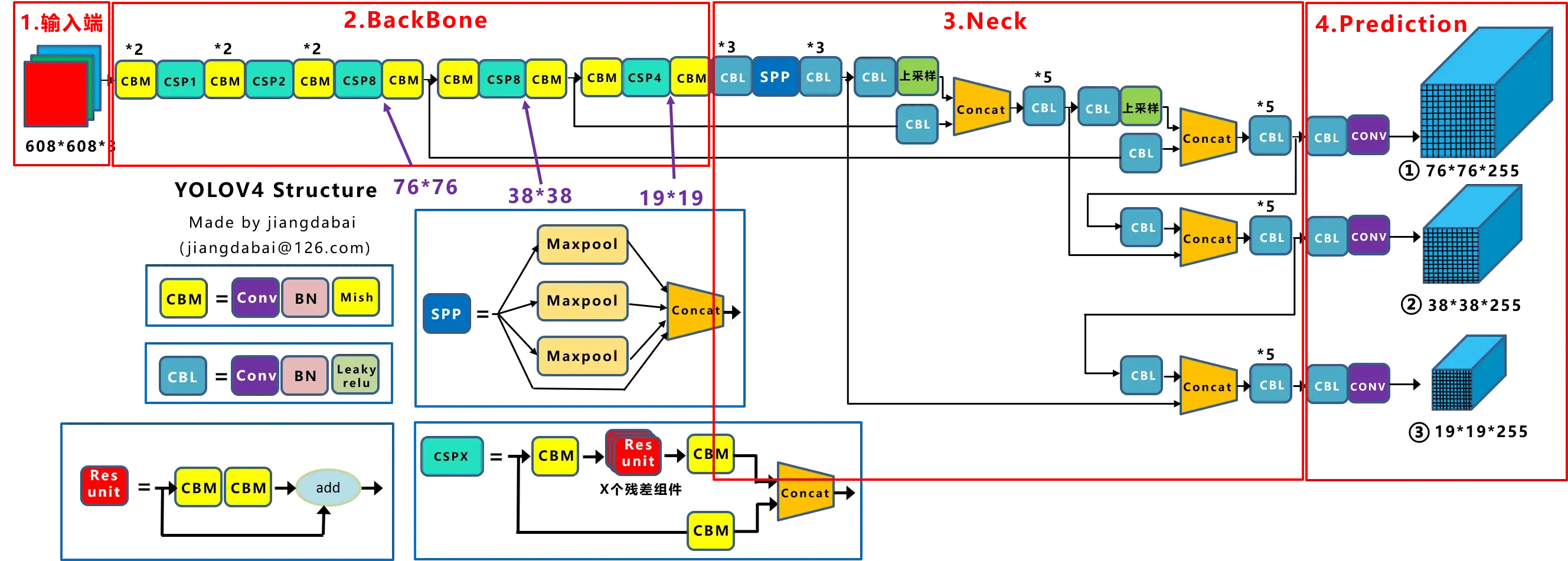
YOLOV4主要构成:
CBM和CBL模块:
SPP结构:
FPN+PAN结构 :
网络输出:
YOLOv4网络结构整体代码
YOLOV4主要构成:
Backbones(在不同图像细粒度上聚合并形成图像特征的卷积神经网络。):CSPDarknet53
Neck(一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。):(1)Additional blocks:SPP (2)Path-aggregation blocks:PANet(FPN+PAN)
Heads(对图像特征进行预测,生成边界框和并预测类别。):YOLOv3
CBM和CBL模块:
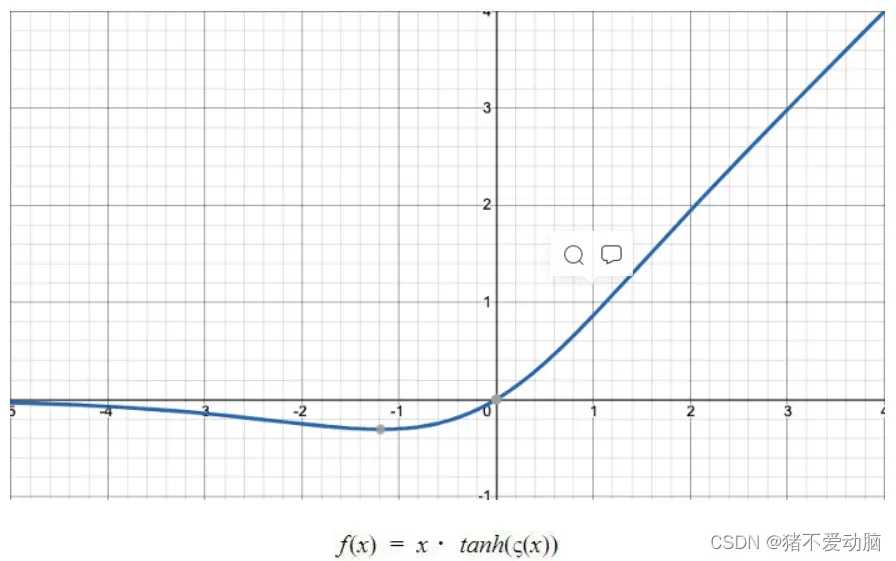
Mish:光滑的非单调激活函数
Mish(x) = x・tanh(ς(x)),其中, ς(x) = ln(1+e^x),是一个softmax激活函数和。
LeakyReLU:非饱和激活函数
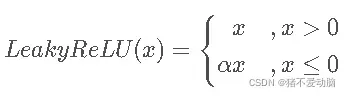
实现代码如下:
#CBM
class CBM(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,bias=False):
super().__init__()
self.Conv1 = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding=(kernel_size - 1) // 2)
self.BN = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.Conv1(x)
x = self.BN(x)
x = x * (torch.tanh(torch.nn.functional.softplus(x)))
return x#CBL
class CBL(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,bias=False):
super().__init__()
self.Conv1 = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding=(kernel_size - 1) // 2)
self.BN = nn.BatchNorm2d(out_channels)
self.Leakyrelu = nn.LeakyReLU(inplace=True)
def forward(self, x):
x = self.Conv1(x)
x = self.BN(x)
x = self.Leakyrelu(x)
return xSPP结构:
主要是通过解决不同大小的特征图如何进入全连接层,直接将任意大小的固定大小的特征图池化,得到固定数量的特征,从而增加感受野。
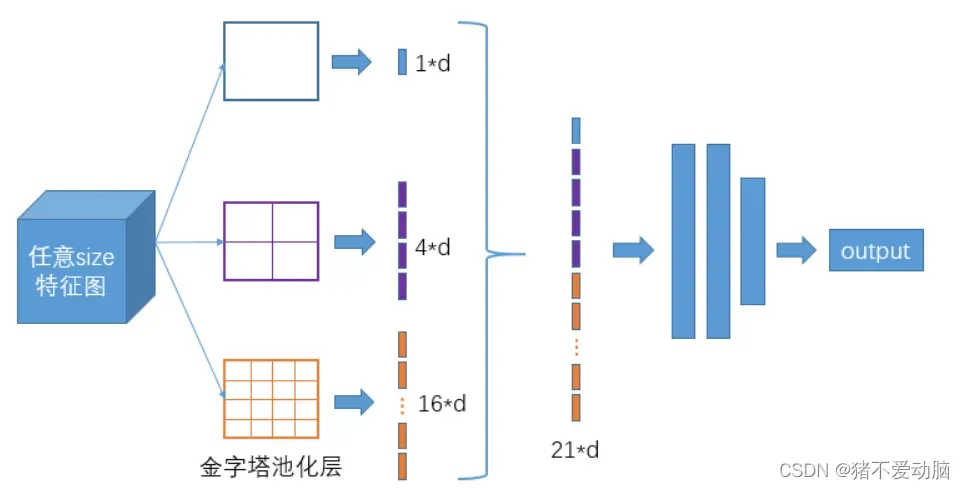
比如上图:对整个特征图进行一个最大值池化以及划分成2×2和4×4的网格之后进行最大值池化,分别得到1*d、4*d、16*d的特征,接着将每个池化得到的特征融合起来即可得到固定长度的特征个数。
实现代码如下:
#SPP
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.Maxpool1 = nn.MaxPool2d(kernel_size=5, stride=1, padding=5 // 2)
self.Maxpool2 = nn.MaxPool2d(kernel_size=9, stride=1, padding=9 // 2)
self.Maxpool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
def forward(self, x):
x1 = self.Maxpool1(x)
x2 = self.Maxpool2(x)
x3 = self.Maxpool3(x)
x = torch.cat((x, x1, x2, x3), dim=1)
return xCSP结构:
CSPNet论文地址:https://arxiv.org/pdf/1911.11929
CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
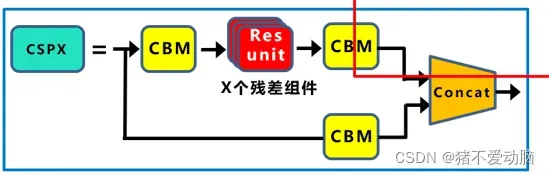
主要是将输入分为两个分支,一个分支先通过CBM,再经过Resunit * N(残差结构:为了使网络构建的更深),再通过一次CBM;另一个分支直接通过CBM;然后两个分支进行concat融合。
实现代码如下:
#Res_unit
class Res_unit(nn.Module):
def __init__(self, out_channels, nblocks=1, shortcut=True):
super().__init__()
self.CBM1 = CBM(out_channels,out_channels,kernel_size=1,stride=1)
self.CBM2 = CBM(out_channels,out_channels,kernel_size=3,stride=1)
self.shortcut = shortcut
self.module_list = nn.ModuleList()
for i in range(nblocks):
resblock_one = nn.ModuleList()
resblock_one.append(self.CBM1)
resblock_one.append(self.CBM2)
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
h = x
for res in module:
h = res(h)
x = x + h if self.shortcut else h
return x#CSP
class CSP(nn.Module):
def __init__(self,in_channels,out_channels,nblocks):
super().__init__()
self.CBM1 = CBM(in_channels,out_channels,kernel_size=1,stride=1)
self.CBM2 = CBM(in_channels,out_channels,kernel_size=1,stride=1)
self.CBM3 = CBM(out_channels,out_channels,kernel_size=1,stride=1)
self.Res_unit = Res_unit(out_channels,nblocks=nblocks)
def forward(self, x):
x1 = self.CBM1(x)
x1 = self.Res_unit(x1)
x1 = self.CBM3(x1)
x2 = self.CBM2(x)
x = torch.cat([x1, x2], dim=1)
return xPANet(FPN+PAN)结构 :
PANet(Pyramid Attention with Simple Network Backbones)是一种基于图像恢复金字塔注意力模块的图像修复模型,它能够从多尺度特征金字塔种提取到长距离与短距离的特征关系。
论文地址:https://arxiv.org/abs/2004.13824
FPN是自上向下的一个特征金字塔,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图,高维度向低维度传递语义信息。
PAN则是对FPN的补充,刚好反过来,是自下向上的金字塔,低维度向高维度再传递一次语义信息,将低层的定位特征传递上去。
两者的结合使网络能够将不同主干层的参数聚合到不同的检测层,从而获得图像语义信息和定位特征,进一步提高特征提取能力。
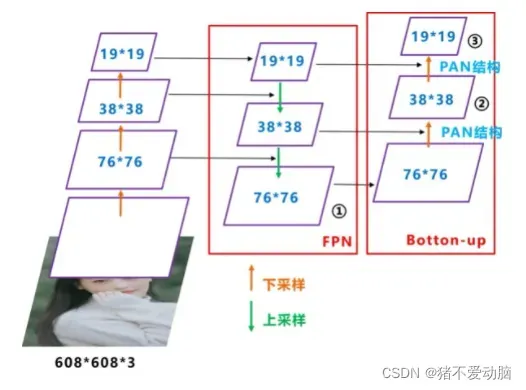
不同于原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat操作,特征图融合后的尺寸发生了变化。
网络输出:
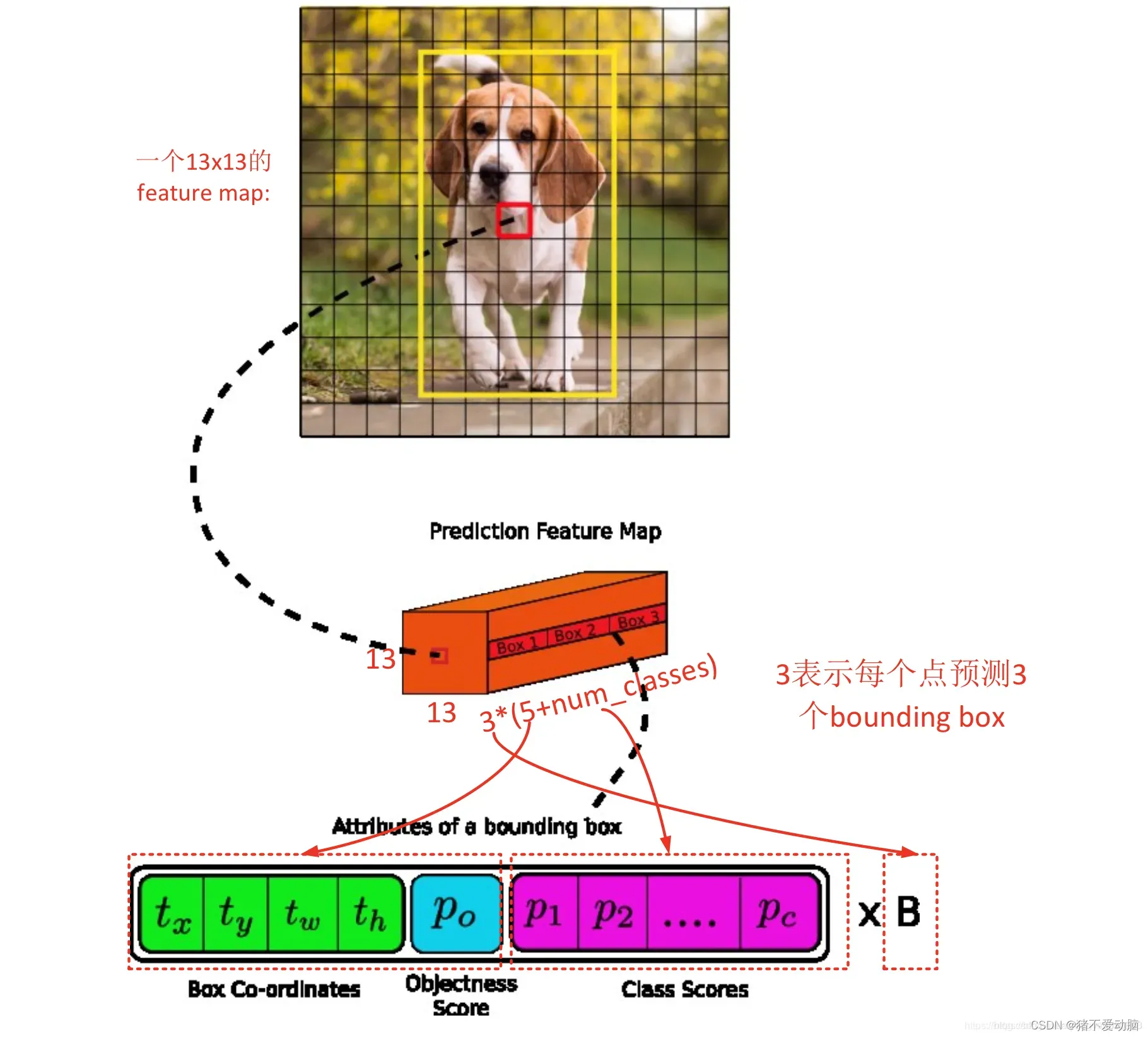
yolov4一共有9个anchor,3个输出,每个输出用3个anchor,所以输出的每个位置预测3个box。对于13×13(输入的图片为416*416)的输出,每个box的参数包括box中心的(,
)和宽高(
,
),及该box有物体的置信分数
,该box中为每类物体的概率
。
文章第一张图中网络输出中的(32倍降采样)19*19*255,(16倍降采样)38*38*255,(8倍降采样)76*76*255,是以coco数据集(80个类别)为例,输入608*608的图片计算得到的
YOLOv4网络结构整体代码
import torch
from torch import nn
from torch.nn import functional as F
#CBM
class CBM(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,bias=False):
super().__init__()
self.Conv1 = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding=(kernel_size - 1) // 2)
self.BN = nn.BatchNorm2d(out_channels)
def forward(self, x):
x = self.Conv1(x)
x = self.BN(x)
x = x * (torch.tanh(torch.nn.functional.softplus(x)))
return x
#CBL
class CBL(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,bias=False):
super().__init__()
self.Conv1 = nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding=(kernel_size - 1) // 2)
self.BN = nn.BatchNorm2d(out_channels)
self.Leakyrelu = nn.LeakyReLU(inplace=True)
def forward(self, x):
x = self.Conv1(x)
x = self.BN(x)
x = self.Leakyrelu(x)
return x
#Res_unit
class Res_unit(nn.Module):
def __init__(self, out_channels, nblocks=1, shortcut=True):
super().__init__()
self.CBM1 = CBM(out_channels,out_channels,kernel_size=1,stride=1)
self.CBM2 = CBM(out_channels,out_channels,kernel_size=3,stride=1)
self.shortcut = shortcut
self.module_list = nn.ModuleList()
for i in range(nblocks):
resblock_one = nn.ModuleList()
resblock_one.append(self.CBM1)
resblock_one.append(self.CBM2)
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
h = x
for res in module:
h = res(h)
x = x + h if self.shortcut else h
return x
#SPP
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.Maxpool1 = nn.MaxPool2d(kernel_size=5, stride=1, padding=5 // 2)
self.Maxpool2 = nn.MaxPool2d(kernel_size=9, stride=1, padding=9 // 2)
self.Maxpool3 = nn.MaxPool2d(kernel_size=13, stride=1, padding=13 // 2)
def forward(self, x):
x1 = self.Maxpool1(x)
x2 = self.Maxpool2(x)
x3 = self.Maxpool3(x)
x = torch.cat((x, x1, x2, x3), dim=1)
return x
#CSP
class CSP(nn.Module):
def __init__(self,in_channels,out_channels,nblocks):
super().__init__()
self.CBM1 = CBM(in_channels,out_channels,kernel_size=1,stride=1)
self.CBM2 = CBM(in_channels,out_channels,kernel_size=1,stride=1)
self.CBM3 = CBM(out_channels,out_channels,kernel_size=1,stride=1)
self.Res_unit = Res_unit(out_channels,nblocks=nblocks)
def forward(self, x):
x1 = self.CBM1(x)
x1 = self.Res_unit(x1)
x1 = self.CBM3(x1)
x2 = self.CBM2(x)
x = torch.cat([x1, x2], dim=1)
return x
#上采样
class UpSample(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, target_size):
assert (x.data.dim() == 4)
return F.interpolate(x, size=(target_size[2], target_size[3]), mode='nearest')
#Backbone
class Backbone(nn.Module):
def __init__(self):
super().__init__()
self.CBM1 = CBM(in_channels=3, out_channels=32, kernel_size=3, stride=1)
self.CBM2 = CBM(in_channels=32, out_channels=64, kernel_size=3, stride=2)
self.CSP1 = CSP(in_channels=64, out_channels=64, nblocks=1)
self.CBM3 = CBM(in_channels=128, out_channels=64, kernel_size=1, stride=1)
self.CBM4 = CBM(in_channels=64, out_channels=128, kernel_size=3, stride=2)
self.CSP2 = CSP(in_channels=128, out_channels=64, nblocks=2)
self.CBM5 = CBM(in_channels=128, out_channels=128, kernel_size=1, stride=1)
self.CBM6 = CBM(in_channels=128, out_channels=256, kernel_size=3, stride=2)
self.CSP3 = CSP(in_channels=256, out_channels=128, nblocks=8)
self.CBM7 = CBM(in_channels=256, out_channels=256, kernel_size=1, stride=1)
self.CBM8 = CBM(in_channels=256, out_channels=512, kernel_size=3, stride=2)
self.CSP4 = CSP(in_channels=512, out_channels=256, nblocks=8)
self.CBM9 = CBM(in_channels=512, out_channels=512, kernel_size=1, stride=1)
self.CBM10 = CBM(in_channels=512, out_channels=1024, kernel_size=3, stride=2)
self.CSP5 = CSP(in_channels=1024, out_channels=512, nblocks=4)
self.CBM811 = CBM(in_channels=1024, out_channels=1024, kernel_size=1, stride=1)
def forward(self, input):
CBM1 = self.CBM1(input)
CBM2 = self.CBM2(CBM1)
CSP1 = self.CSP1(CBM2)
CBM3 = self.CBM3(CSP1)
CBM4 = self.CBM4(CBM3)
CSP2 = self.CSP2(CBM4)
CBM5 = self.CBM5(CSP2)
CBM6 = self.CBM6(CBM5)
CSP3 = self.CSP3(CBM6)
CBM7 = self.CBM7(CSP3)
CBM8 = self.CBM8(CBM7)
CSP4 = self.CSP4(CBM8)
CBM9 = self.CBM9(CSP4)
CBM10 = self.CBM10(CBM9)
CSP5 = self.CSP5(CBM10)
CBM11 = self.CBM811(CSP5)
return CBM7, CBM9, CBM11
#Neck
class Neck(nn.Module):
def __init__(self):
super().__init__()
self.CBL1 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
self.CBL2 = CBL(in_channels=512, out_channels=1024, kernel_size=3, stride=1)
self.CBL3 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
self.SPP = SPP()
self.CBL4 = CBL(in_channels=2048, out_channels=512, kernel_size=1, stride=1)
self.CBL5 = CBL(in_channels=512, out_channels=1024, kernel_size=3, stride=1)
self.CBL6 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
self.CBL7 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.Upsample1 = UpSample()
self.CBL8 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL9 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL10 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=1)
self.CBL11 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL12 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=1)
self.CBL13 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL14 = CBL(in_channels=256, out_channels=128, kernel_size=1, stride=1)
self.Upsample2 = UpSample()
self.CBL15 = CBL(in_channels=256, out_channels=128, kernel_size=1, stride=1)
self.CBL16 = CBL(in_channels=256, out_channels=128, kernel_size=1, stride=1)
self.CBL17 = CBL(in_channels=128, out_channels=256, kernel_size=3, stride=1)
self.CBL18 = CBL(in_channels=256, out_channels=128, kernel_size=1, stride=1)
self.CBL19 = CBL(in_channels=128, out_channels=256, kernel_size=3, stride=1)
self.CBL20 = CBL(in_channels=256, out_channels=128, kernel_size=1, stride=1)
self.CBL21 = CBL(in_channels=128, out_channels=256, kernel_size=3, stride=2)
self.CBL22 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL23 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=1)
self.CBL24 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL25 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=1)
self.CBL26 = CBL(in_channels=512, out_channels=256, kernel_size=1, stride=1)
self.CBL27 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=2)
self.CBL28 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
self.CBL29 = CBL(in_channels=512, out_channels=1024, kernel_size=3, stride=1)
self.CBL30 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
self.CBL31 = CBL(in_channels=512, out_channels=1024, kernel_size=3, stride=1)
self.CBL32 = CBL(in_channels=1024, out_channels=512, kernel_size=1, stride=1)
def forward(self, CBM7, CBM9, CBM11):
CBL1 = self.CBL1(CBM11)
CBL2 = self.CBL2(CBL1)
CBL3 = self.CBL3(CBL2)
SPP = self.SPP(CBL3)
CBL4 = self.CBL4(SPP)
CBL5 = self.CBL5(CBL4)
CBL6 = self.CBL6(CBL5)
CBL7 = self.CBL7(CBL6)
UpSample1 = self.Upsample1(CBL7, CBM9.size())
CBL8 = self.CBL8(CBM9)
cat1 = torch.cat((CBL8, UpSample1), 1)
CBL9 = self.CBL9(cat1)
CBL10 = self.CBL10(CBL9)
CBL11 = self.CBL11(CBL10)
CBL12 = self.CBL12(CBL11)
CBL13 = self.CBL13(CBL12)
CBL14 = self.CBL14(CBL13)
UpSample2 = self.Upsample2(CBL14, CBM7.size())
CBL15 = self.CBL15(CBM7)
cat2 = torch.cat((CBL15, UpSample2), 1)
CBL16 = self.CBL16(cat2)
CBL17 = self.CBL17(CBL16)
CBL18 = self.CBL18(CBL17)
CBL19 = self.CBL19(CBL18)
CBL20 = self.CBL20(CBL19)
CBL21 = self.CBL21(CBL20)
cat3 = torch.cat((CBL21, CBL13), 1)
CBL22 = self.CBL22(cat3)
CBL23 = self.CBL23(CBL22)
CBL24 = self.CBL24(CBL23)
CBL25 = self.CBL25(CBL24)
CBL26 = self.CBL26(CBL25)
CBL27 = self.CBL27(CBL26)
cat4 = torch.cat((CBL27, CBL6), 1)
CBL28 = self.CBL28(cat4)
CBL29 = self.CBL29(CBL28)
CBL30 = self.CBL30(CBL29)
CBL31 = self.CBL31(CBL30)
CBL32 = self.CBL32(CBL31)
return CBL20, CBL26, CBL32
#Head
class Head(nn.Module):
def __init__(self, out_channels):
super().__init__()
self.CBL1 = CBL(in_channels=128, out_channels=256, kernel_size=3, stride=1)
self.conv1 = nn.Conv2d(256, out_channels, kernel_size=1, stride=1)
self.CBL2 = CBL(in_channels=256, out_channels=512, kernel_size=3, stride=1)
self.conv2 = nn.Conv2d(512, out_channels, kernel_size=1, stride=1)
self.CBL3 = CBL(in_channels=512, out_channels=1024, kernel_size=3, stride=1)
self.conv3 = nn.Conv2d(1024, out_channels, kernel_size=1, stride=1)
def forward(self, CBL20, CBL26, CBL32):
CBL1 = self.CBL1(CBL20)
output1 = self.conv1(CBL1)
CBL2 = self.CBL2(CBL26)
output2 = self.conv2(CBL2)
CBL3 = self.CBL3(CBL32)
output3 = self.conv3(CBL3)
return output1, output2, output3
#YOLOV4
class YOLOV4(nn.Module):
def __init__(self):
super().__init__()
self.bakbone = Backbone()
self.neck = Neck()
self.head = Head(out_channels=255)
def forward(self, input):
CBM7, CBM9, CBM11 = self.bakbone(input)
CBL20, CBL26, CBL32 = self.neck(CBM7, CBM9, CBM11)
output1, output2, output3 = self.head(CBL20, CBL26, CBL32)
return output1, output2, output3
def main():
model = YOLOV4()
tmp = torch.randn(2,3,608,608)
output1, output2, output3 = model(tmp)
print('output1:',output1.shape,'output2:',output2.shape,'output3:',output3.shape)
if __name__ == "__main__":
main()运行结果

_____________________________________________________
文章属于学习笔记,如有不妥之处,请指正。
版权声明:本文为博主猪不爱动脑原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_46292437/article/details/123026203