这两天在学习VAE相关的内容,感觉云里雾里emm…写个博客记录一下~
内容借鉴并整合了以下领导者:
变分自编码器VAE:原来是这么一回事
在半小时内了解变分自动编码器
花式解释AutoEncoder与VAE – 知乎 (zhihu.com)
【深度学习】AE与VAE_sinat_36197913的博客-CSDN博客_vae和ae
需要零个简单的数学公式
K-L散度(Kullback-Leibler pergence)
K-L散度又被称为相对熵(relative entropy),是对两个概率分布间差异的非对称性度量。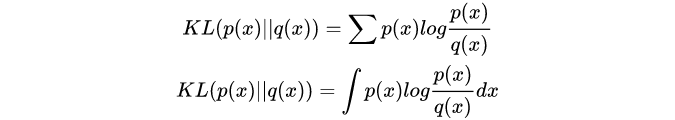
交叉熵就是特殊的KL散度,且KL(P, Q) != KL(Q, P).
Bayes Rule
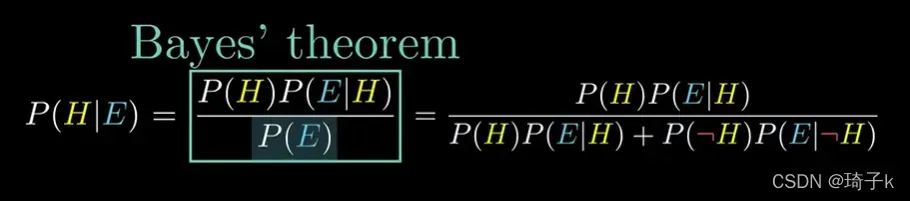
P(H): Prior,“先验概率”
P(H|E): 后验概率
竖线:只考虑总概率空间的有限部分。
P(E|H): Likelihood, “似然概率”
P(E): 全概率公式
结合下面的推导,这里主要使用: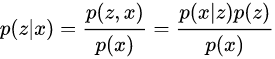
一、降维,自编码器以及为什么不可以用AE做生成任务
降维
降维是减少描述数据的特征数量的过程。可以通过选择(仅保留一些现有特征)或通过提取(基于旧特征组合来生成数量更少的新特征)来进行降维。我们称编码器为从“旧特征”表示中产生“新特征”表示(通过选择或提取)的过程,然后将其逆过程称为解码。降维可以被理解为数据压缩,其中编码器压缩数据(从初始空间到编码空间,也称为隐空间,latent space),而解码器则用于解压缩。当然,根据初始数据分布、隐空间大小和编码器的选择,压缩可能是有损的,即一部分信息会在编码过程中丢失,并且在解码时无法恢复。
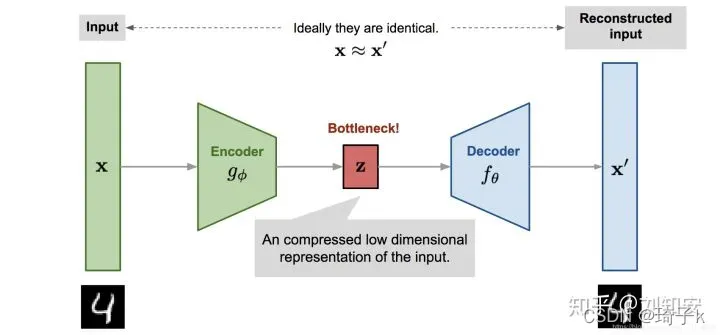
自动编码器
使用神经网络作为编码器和解码器,并使用迭代优化来学习最佳的编解码方案。因此,在每次迭代中,我们向自动编码器结构(编码器后跟解码器)提供一些数据,我们将编码和解码的输出与初始数据进行比较,并通过反向传播误差来更新网络的权重(训练自己)。
因此,直观地讲,整个自编码器结构(编码器+解码器)会构造出数据瓶颈(bottleneck),从而确保只有信息的主要部分可以通过瓶颈并进行重构。从我们的总体框架来看,考虑的编码器族[公式]由编码器网络结构定义,考虑的解码器族[公式]由解码器网络结构定义,而重构误差的减小则通过对编码器和解码器参数进行梯度下降来进行。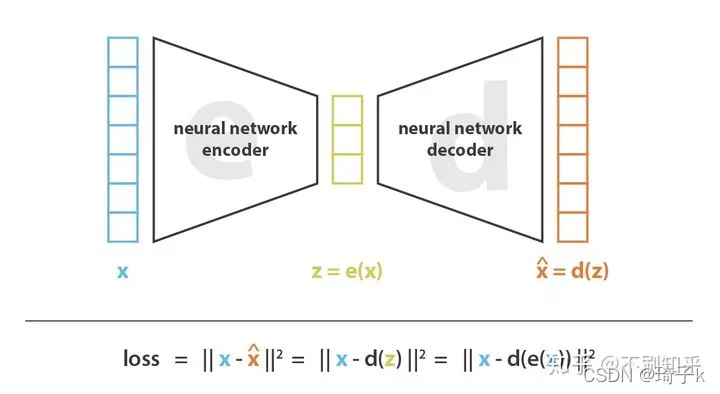
但是降维也带来了问题——
首先,在没有重建损失的情况下进行重要的降维通常会带来一个代价:隐空间中缺乏可解释和可利用的结构(缺乏规则性,lack of regularity)。其次,大多数时候,降维的最终目的不仅是减少数据的维数,而是要在减少维数的同时将数据主要的结构信息保留在简化的表示中。出于这两个原因,必须根据降维的最终目的来仔细控制和调整隐空间的大小和自编码器的“深度”(深度定义压缩的程度和质量)。
假设有一种强大的编码器和解码器,可以将任何N个初始训练数据放到实轴上(每个数据点都被编码为实值)并可以没有任何损失地解码。在这种情况下,自编码器的高自由度使得可以在没有信息损失的情况下进行编码和解码(尽管隐空间的维数较低)但会导致严重的过拟合,这意味着隐空间的某些点将在解码时给出无意义的内容。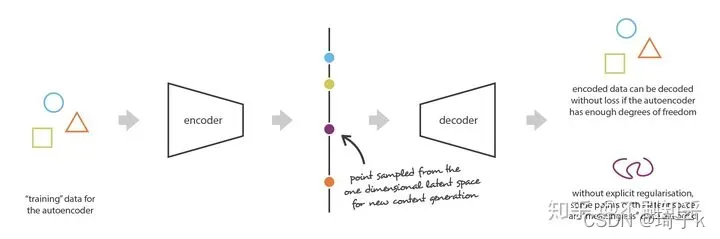
这也是很好理解的,因为AE的任务在于“仅以尽可能少的损失为目标进行训练”,而没有义务要管隐空间是如何组织的,正是由于隐空间的不规则性,妨碍了我们用AE生成新数据。所以——能不能人为干预,使得隐空间能规范些?
VAE变分自编码器
为了能够将我们的自编码器的解码器用于生成目的,我们必须确保隐空间足够规则。获得这种规律性的一种可能方案是在训练过程中引入显式的正规化(regularisation)。因此,正如我们在这篇文章的简介中提到的那样,变分自编码器可以定义为一种自编码器,其训练经过正规化以避免过度拟合,并确保隐空间具有能够进行数据生成过程的良好属性。
就像标准自编码器一样,变分自编码器是由编码器和解码器组成的结构,经过训练以最小化编码和解码数据与原始数据之间的重构误差。然而,为了引入潜在空间的一些正则化,我们对编码-解码过程进行了一些修改:我们不是将输入编码为潜在空间中的单个点,而是将其编码为潜在空间中的概率分布。然后按如下方式训练模型:
首先,将输入编码为潜在空间上的分布;
其次,从这个分布中对潜在空间中的一个点进行采样;
第三,对采样点进行解码,计算重构误差;
最后,重构误差通过网络反向传播。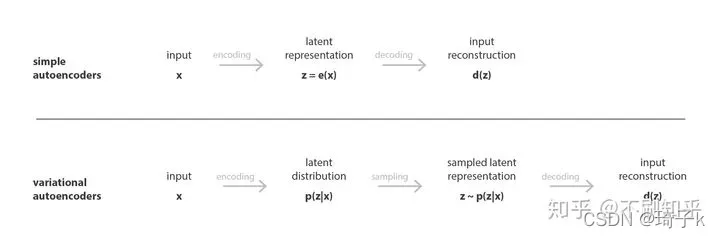
AE中间输出的是隐变量的具体取值,而VAE中间要输出的是隐变量的具体分布情况,这样一来,我们就可以从这个分布中另外取样,送入到decoder,就可以生成类似输入样本x的其他样本x’了,并且这两个会十分近似。
总体VAE的架构图如下所示: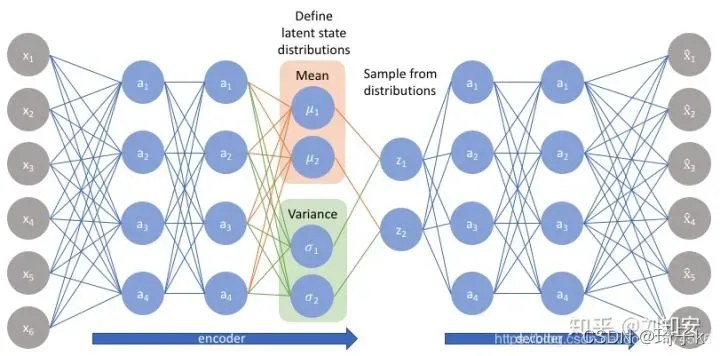
那么为什么将其编码为分布而不是特定值呢?
让我们从卢鹏老师那里做一个直观的解释: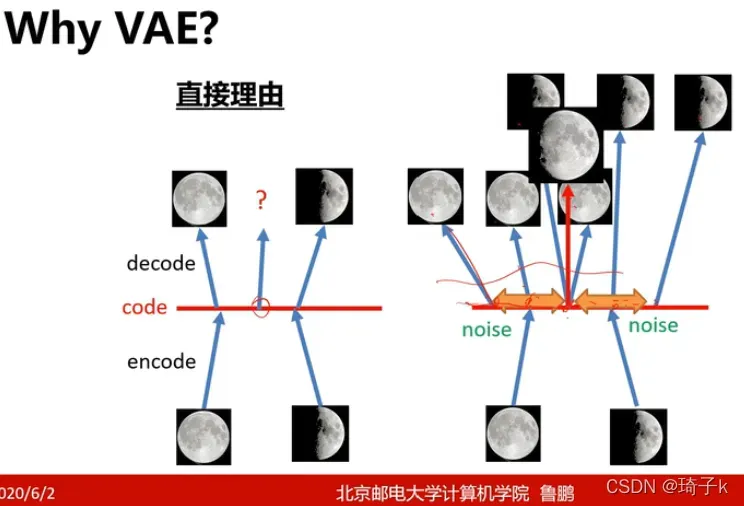
在引入noise之前,我们的decoder的输入和输出地映射可以看作是离散的,但是在加入noise之后,可以看作把不连续地变成连续的了。
除此之外,将输入编码为具有一定方差而不是单个点的分布还可以非常自然地表达隐空间规则化:编码器返回的分布被强制接近标准正态分布。【这也解释了为什么很多资料都说我们先验p(z)是服从N(0, 1)的,其实不一定,也可以用别的分布,这是我们人为规定的。】
btw: 这里给出原论文作者的解释:
把先验p(z)假设为标准正态分布的原因:理论上,任何一个分布都可以由正态分布经过一个复杂函数变换映射得到(理解:高斯混合分布可以由若干的小高斯分布加和而成),一定程度上,可以认为decoder 网络的前几层就是真的在试图从正态分布转化到latent variable 空间上。
正态分布只是人为给定的约束,之所以要加约束是因为每个可观测量x对应的隐变量z有无限种可能的分布,不加约束将无法控制学到的z满足哪一种分布。除了约束z满足正态分布还约束了z向量各个纬度相互独立,也就是让协方差矩阵为对角矩阵,目的都是降低z的自由度。
在训练VAE时最小化的损失函数由一个重构项(在最后一层)组成,“重构项”倾向于使编码解码方案尽可能地具有高性能,而一个正则化项(在隐层)通过使编码器返回的分布接近标准正态分布,来规范隐空间的组织。该正则化项为返回的分布与标准高斯之间的KL散度。
通过正则化获得的连续性和完整性往往会在潜在空间中编码的信息上产生“梯度”。例如,潜在空间中位于来自不同训练数据的两个编码分布的平均值之间的点应该被解码为提供第一个分布的数据和提供第二个分布的数据之间的某个东西。因为它可能在两种情况下被自编码器采样,也就是说,这个点应该具有两种分布的特征。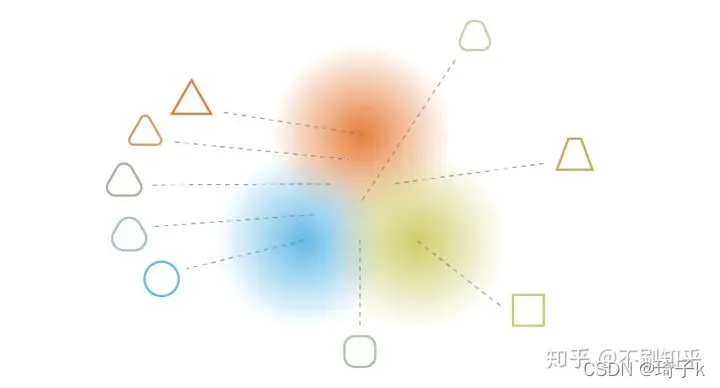
2. 数学推导
我们认为数据集中的每个样本也是这样生成的: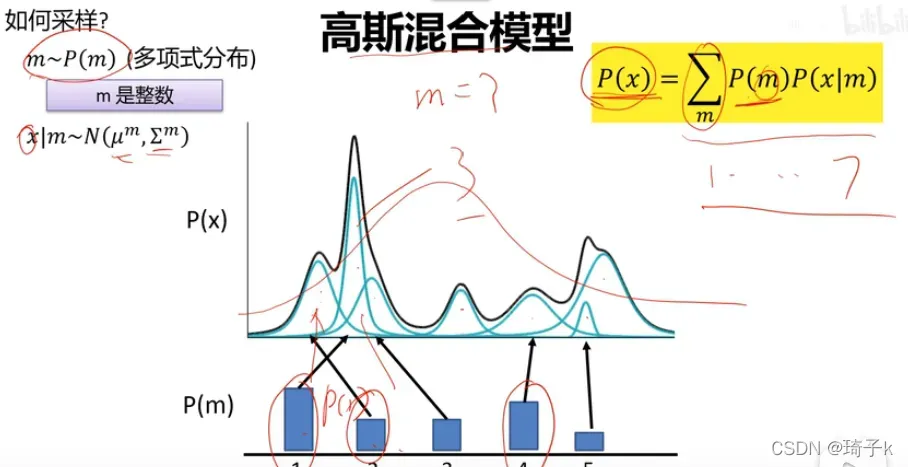
先选择一个高斯组件(对应Xk样本自己的那个高斯分布),再从这个高斯组件中产生当前的样本。如下图所示,我们采样z,然后用z去生成高斯组件(这个过程是神经网络学习的)。用无限个高斯分布去逼近真实分布(这里指的Px=Pz * P(x|z),给定z的情况下,每个小x都是高斯分布)。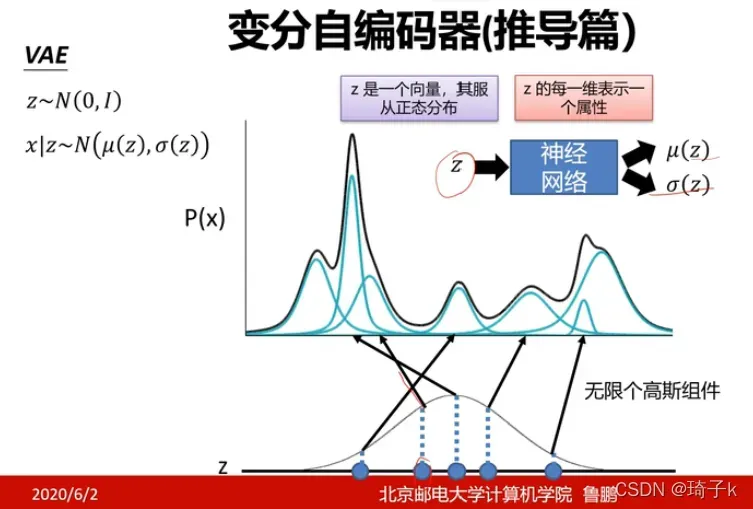
最大似然估计角
我们希望优化解码器的参数,使最大似然估计值最大。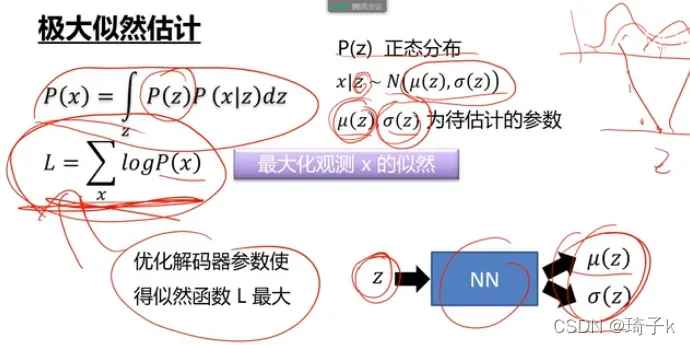
但是问题是,没法最大化L,因为P(x)不知道,P(x|z)也不知道(是神经网络学出来的,没有数学表达形式)。
变分推断的核心思想是:因为一般情况下后验概率p(z∣x)是不可求解的,所以变分推断采用了一种迂回的策略,即使用q(z|x)去近似p(z|x)。可以把p(z∣x)看作是AE中的编码器,p(x∣z)看作是AE中的解码器。
关于q(z|x)为什么是高斯分布?
【p(zΙx)这个真实的分布是不知道的,多半是一个奇奇怪怪的分布。
但从推导过程上看,我们需要从这个分布中抽样,所以我们考虑用一个已知的分布形式去近似这个p(zΙx),然后就选择了用高斯分布去近似它。】
每个样本通过encoder生成出来均值和方差,这个均值和方差通过用和标准正太分布的KL距离作为loss来尽量靠拢标准正太分布,但是还是和标准正太分布有差别的,也就是每个样本编码出来的分布还是不一样的。然后从正太分布中采了一个样,用这个均值和方差转换成这个样本自己对应的分布。
所以我们现在的目标变成了:由x产生z.
这是数学推导:
1、首先把z引入,q(z|x)dz是1,所以不改变值;
2、使用贝叶斯,P(z, x) = P(x) * P(z|x), 把P(x)替换掉;
3、上下同乘q(z|x),并拆Log乘为加法;
4、拆开之后后面那一项就是KL(q, p),度量的是q(z|x)与p(z|x)之间的距离。
但是p(z|x)不知道,所以只看前面一部分,后面是下界,但是算不出来。
p(x|z)、q(z|x)都是神经网络学的。
所以化简后,前面就是q(z|x)与P(z)的KL散度,表示神经网络输出的分布和标准正态分布的差异;而后面项其实就是“输入x产生z,再由z复原x”的意思,就是重构损失。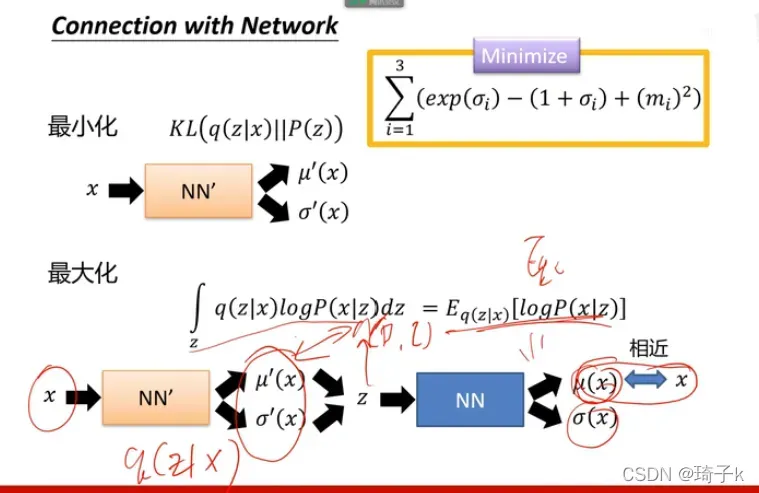
这也解释了为什么希望sigma学到1,因为我们是用N(0, 1)去监督的。
版权声明:本文为博主琦子k原创文章,版权归属原作者,如果侵权,请联系我们删除!