SRGAN数据GAN理论在超分辨率重建(SR)方面的应用。
一、超分辨率技术
1.SR技术介绍
SR技术,是指从观测到的低分辨率图像重建出相对应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值,也可以应用于马赛克图片的恢复应用场景。
SR可分为两类:从多张低分辨率图像重建出高分辨率图像;从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution(SISR)。
SISR是一个逆问题。对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,为了让逆向的结果更加接近真实图片,则需要让模型在一定约束下,指定某个领域中进行可逆训练。这个约束,就是指现有的低分辨率像素的色度信息与位置信息。为了让模型更好的学习并利用这个信息,基于深度学习的SR通过神经网络直接通过优化低分辨率图像道高分辨率图像的loss来进行端到端的训练。
2.深度学习中的SR方法
在GAN出现之前,通常采用SRCNN、DRCN。该方法的大体思路是将低分辨率像素先扩展到高分辨率的像素大小,然后通过卷积方式训练网络,优化其与真实高分辨率图片的loss,最终形成模型。
后面出现了另一种高效的方法ESPCN(实时的基于卷积神经网络的图像超分辨率方法)。ESPCN的核心概念是亚像素卷积层,即先在原有的低像素图像上做卷积操作,最终输出一个含有多个feature map的结果,保证总像素点与高分辨率的像素点总是一致的,然后将多张低分辨率图像合并成一张高分辨率的图像。
例如,假设需要将低分辨率图片的像素扩大2倍(从128×128扩大到256×256),就直接将其进行卷积操作,最终输出放大倍数的平方4个feature map。以灰度图为例,将4个图片中的第一个像素取出成为重构图中的4个像素,依次类推,在重构图中的每2×2区域都是有这4幅图对应位置的像素组成,最终形成[batch_size,2×W,2×H,1]大小的高分辨率图像,这个变换陈伟亚像素卷积。
3.TensorFlow中的图片变换函数
def resize_image(images, size, method=ResizeMethod.BILINEAR, align_corners=False):
前两个参数分别是输入的图片及要变换的尺寸,图片的形状为[batch, height, width, channels]或[height, width, channels]。第3个参数的取值。
- ResizeMethod.BLINEAR:表示使用双线性茶汁算法变化图片。
- ResizeMethod.NEAREST_NEIGHBOR:表示使用邻近插值算法变化图片。
- ResizeMethod.BICUBIC:表示使双立方插值算法变化图片。
- ResizeMethod.AREA:表示使用面积插值算法变化图片
二、实例93:ESPCN实现MNIST数据集的超分辨重建
实例描述
通过使用ESPCN网络,在MNIST数据集上将低分辨率图片复原成高分辨率图片,并与其他复原函数的生成结果进行比较。
1.引入头文件,构建低分辨率样本
在头文件部分导入slim库,使用resize_bicubic来构建缩小的4倍低分辨率样本,将28×28的像素变成14×14(缩小2倍)
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import tensorflow.contrib.slim as slim
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/data/", one_hot=True)
batch_size = 30 # 获取样本的批次大小
n_input = 784 # MNIST data 输入 (img shape: 28*28)
n_classes = 10 # MNIST 列别 (0-9 ,一共10类)
x = tf.placeholder("float", [None, n_input])
img = tf.reshape(x,[-1,28,28,1])
x_small = tf.image.resize_bicubic(img, (14, 14))# 缩小2倍
2.通过TensorFlow函数实现超分辨率
分别使用bicubic、nearest_neighbor和bilinear方法将分辨率还原。
x_bicubic = tf.image.resize_bicubic(x_small, (28, 28))#双立方插值算法变化
x_nearest = tf.image.resize_nearest_neighbor(x_small, (28, 28))
x_bilin = tf.image.resize_bilinear(x_small, (28, 28))
3.建立ESPCN网络结构
建立一个简单的三层卷积网络:第1层使用5×5的卷积核,输出64通道的图片,slim卷积函数使用的是默认激活函数Relu;第2层使用3×3的卷积核,输出是32通道;最后一层使用3×3卷积核,生成4通道图片。这个4通道需要和恢复超分辨率缩放范围对应,4代表长、宽各放大2倍。接着使用tf.depth_to_space函数,将多张图片合并成一张图片。
tf.depth_to_space函数的意思是将深度数据按照块的模式展开重新排列,第一个输入是原始数据,第二个输入是块的尺寸,输入2则代表尺寸为2×2的块。而深度就是生成图片的通道数,即每个通道对应的像素值填充到指定大小的块中。
#espcn
net = slim.conv2d(x_small, 64, 5)
net =slim.conv2d(net, 32, 3)
net = slim.conv2d(net, 4, 3)
net = tf.depth_to_space(net,2)
4.构建loss及优化器
将图片重新调整形状(reshape)为(batch_size, 784)的形状,通过平方差来计算loss,设定学习率为0.01。
y_pred = tf.reshape(net,[-1,784])
cost = tf.reduce_mean(tf.pow(x - y_pred, 2))
optimizer = tf.train.AdamOptimizer(0.01 ).minimize(cost)
5.建立session,运行
training_epochs =100
display_step =20
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
total_batch = int(mnist.train.num_examples/batch_size)
# 启动循环开始训练
for epoch in range(training_epochs):
# 遍历全部数据集
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs})
# 显示训练中的详细信息
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("完成!")
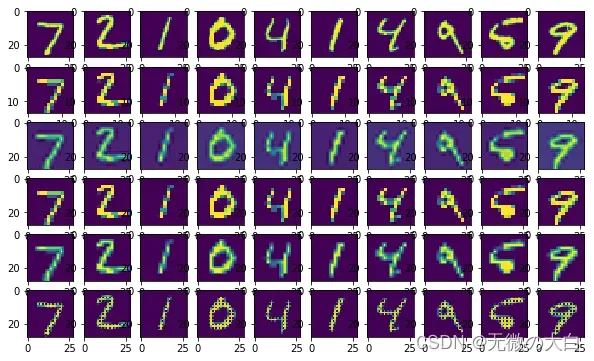
6.图示结果
为了比较效果,将原始图片、低分辨率图片、各种算法的变换图片及模型恢复图片一起显示。
show_num = 10
encode_s,encode_b,encode_n ,encode_bi,y_predv= sess.run(
[x_small,x_bicubic,x_nearest,x_bilin,y_pred], feed_dict={x: mnist.test.images[:show_num]})
f, a = plt.subplots(6, 10, figsize=(10, 6))
for i in range(show_num):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_s[i], (14, 14)))
a[2][i].imshow(np.reshape(encode_b[i], (28, 28)))
a[3][i].imshow(np.reshape(encode_n[i], (28, 28)))
a[4][i].imshow(np.reshape(encode_bi[i], (28, 28)))
a[5][i].imshow(np.reshape(y_predv[i], (28, 28)))
plt.show()
三、实例94:ESPCN实现flowers数据集的超分辨率重建
下面对彩色图片进行超分辨率的重构。彩色图片与MNIST样本不同的地方主要是,图片变成3通道,并且像素点更多,而MNIST像素点更稀疏。所以应用在训练模型上,会有一些细节进行调节。
本例主要实现对flowers数据集的图片处理。本例同样还是使用slim模块进行数据的操作。另外flowers是尺寸不一样的数据样本,所以本例需要借鉴统一尺寸处理的方法。
实例描述
通过使用ESPCN网络,在flowers数据集上将低分辨率图片复原成高分辨率图片并与其他复原函数生成结果进行比较。
1.引入头文件,创建样本数据源
同样使用slim,这次使用的数据源是flowers,将代码文件建立在models下的slim中。
放在slim文件外的话datasets模块会导入失败
slim文件中tf_slim更改一下,应该是TensorFlow1.×版本的问题。
height = width = 200
batch_size = 4
DATA_DIR="flowers"
#选择数据集validation
dataset = flowers.get_split('validation', DATA_DIR)
#创建一个provider
provider = slim.dataset_data_provider.DatasetDataProvider(dataset,num_readers = 2)
#通过provider的get拿到内容
[image, label] = provider.get(['image', 'label'])
print(image.shape)
这里自己做数据集时没做到存入不同大小图片,先剪辑相同大小再存入数据集,slim中的是将数据集导出再剪辑。
2.获取批次样本并通过TensorFlow函数实现超分辨率
通过resize_image_with_crop_or_pad函数统一样本大小,大的减掉,不够的加0填充。使用tf.train.batch函数获得指定批次数据image和labels
# 剪辑图片为统一大小
distorted_image = tf.image.resize_image_with_crop_or_pad(image, height, width)#剪辑尺寸,不够填充
################################################
images, labels = tf.train.batch([distorted_image, label], batch_size=batch_size)
print(images.shape)
x_smalls = tf.image.resize_images(images, (np.int32(height/2), np.int32(width/2)))# 缩小2*2倍
x_smalls2 = x_smalls/255.0
#还原
x_nearests = tf.image.resize_images(x_smalls, (height, width),tf.image.ResizeMethod.NEAREST_NEIGHBOR)
x_bilins = tf.image.resize_images(x_smalls, (height, width),tf.image.ResizeMethod.BILINEAR)
x_bicubics = tf.image.resize_images(x_smalls, (height, width),tf.image.ResizeMethod.BICUBIC)
先通过生成resize_images创建一个低分辨率图片x_samlls,然后将x_smalls通过不同算法的变化,生成对应的高分辨率图片。
3.建立ESPCN网络结构
输入的图片做归一化处理,统一除以255,使其变为0~1之间的书。最后一个卷积成输出为12通道,代表2×2的缩放比例,一共3个通道,所以再乘3。另外,各层使用tanh做激活函数,最后一层没有激活函数。
#网络模型
net = slim.conv2d(x_smalls2, 64, 5,activation_fn = tf.nn.tanh)
net =slim.conv2d(net, 32, 3,activation_fn = tf.nn.tanh)
net = slim.conv2d(net, 12, 3,activation_fn = None)#2*2*3
y_predt = tf.depth_to_space(net,2)
y_pred = y_predt*255.0
y_pred = tf.maximum(y_pred,0)
y_pred = tf.minimum(y_pred,255)
dbatch=tf.concat([tf.cast(images,tf.float32),y_pred],0)
y_pred是由y_predt转换而来,通过tf.maximum与tf.minimum函数将内部的值都变为0~255之间的数字。y_predt会参与损失值的计算。
y_pred进行最大值和最小值的规整处理,防止图片显示出现亮点,使图片显得不清晰。
dbatch是将生成的y_pred与images按照批次维度合并起来,该张量是为了后面进行质量评估使用的。
4.构建loss及优化器
对于全彩色训练的学习率设定还是需要非常小心,这里设置为0.000001,让其缓慢的变化。由于输入样本归一化处理了,所以计算loss时的images也需要归一化。
cost = tf.reduce_mean(tf.pow( tf.cast(images,tf.float32)/255.0 - y_predt, 2))
optimizer = tf.train.AdamOptimizer(0.000001 ).minimize(cost)
5.建立session,运行
起动session,运行150000次。
training_epochs =150000
display_step =200
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
#启动队列
tf.train.start_queue_runners(sess=sess)
# 启动循环开始训练
for epoch in range(training_epochs):
_, c = sess.run([optimizer, cost])
# 显示训练中的详细信息
if epoch % display_step == 0:
d_batch=dbatch.eval()
mse,psnr=batch_mse_psnr(d_batch)
ypsnr=batch_y_psnr(d_batch)
ssim=batch_ssim(d_batch)
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c),"psnr",psnr,"ypsnr",ypsnr,"ssim",ssim)
print("完成!")
在显示评估结果时,使用batch_mse_psnr、batch_y_psnr和batch_ssim这3个函数分别对节点dbatch的值进行运算,得到图片的质量评估值。
6.构建图片质量评估函数
SR图片有其自己的一套评估质量算法:常用的两个指标是PSNR和SSIM。这两个值越高,代表重建结果的像素值和标准越接近。对于PSNR的计算有两个方法:
- 基于R、G、B,分别计算三通道中的MSE值在求平均值,然后将结果代入求PSNR。
- 基于YUV,求图像YUV空间中的Y分量,计算Y分量的PSNR值。
YUV(亦成YCrCb)是另一种颜色编码方法,常被欧洲电视系统所采用。Y代表亮度信号,U(R-Y)与V(B-Y)分别代表两个色差信号。在没有U和V时,就会表现为只有亮度的黑白色,彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的兼容问题。
def batch_mse_psnr(dbatch):
im1,im2=np.split(dbatch,2)
mse=((im1-im2)**2).mean(axis=(1,2))
psnr=np.mean(20*np.log10(255.0/np.sqrt(mse)))
return np.mean(mse),psnr
def batch_y_psnr(dbatch):
r,g,b=np.split(dbatch,3,axis=3)
y=np.squeeze(0.3*r+0.59*g+0.11*b)
im1,im2=np.split(y,2)
mse=((im1-im2)**2).mean(axis=(1,2))
psnr=np.mean(20*np.log10(255.0/np.sqrt(mse)))
return psnr
def batch_ssim(dbatch):
im1,im2=np.split(dbatch,2)
imgsize=im1.shape[1]*im1.shape[2]
avg1=im1.mean((1,2),keepdims=1)
avg2=im2.mean((1,2),keepdims=1)
std1=im1.std((1,2),ddof=1)
std2=im2.std((1,2),ddof=1)
cov=((im1-avg1)*(im2-avg2)).mean((1,2))*imgsize/(imgsize-1)
avg1=np.squeeze(avg1)
avg2=np.squeeze(avg2)
k1=0.01
k2=0.03
c1=(k1*255)**2
c2=(k2*255)**2
c3=c2/2
return np.mean((2*avg1*avg2+c1)*2*(cov+c3)/(avg1**2+avg2**2+c1)/(std1**2+std2**2+c2))
7.图示结果
与前面例子类似,将原始图片与函数变化的图片及模型输出的图片一并显示。这里定义一个函数统一显示。
def showresult(subplot,title,orgimg,thisimg,dopsnr = True):
p =plt.subplot(subplot)
p.axis('off')
p.imshow(np.asarray(thisimg[0], dtype='uint8'))
if dopsnr :
conimg = np.concatenate((orgimg,thisimg))
mse,psnr=batch_mse_psnr(conimg)
ypsnr=batch_y_psnr(conimg)
ssim=batch_ssim(conimg)
p.set_title(title+str(int(psnr))+" y:"+str(int(ypsnr))+" s:"+str(ssim))
else:
p.set_title(title)
四、实例95:使用残差网络的ESPCN
在上例中ESPCN与BILINEAR的结果比较优势没有那么明显,这是因为普通算法在仅仅放大两倍的图片处理上是很优秀的,另一个原因也是由于例子中的网络结构过于简单(仅三层)。下面进行网络结构优化,实现在分辨率方法4倍任务上的图片重建
实例描述
将flowers数据集中的图片转成低分辨率,再通过使用带残差网络的ESPCN网络复原高分辨率图片,并与其他复原函数的生成结果进行比较。
1.修改输入图片的分辨率
images, labels = tf.train.batch([distorted_image, label], batch_size=batch_size)
print(images.shape)
x_smalls = tf.image.resize_images(images, (np.int32(height/4), np.int32(width/4)))# 缩小4*4倍
x_smalls2 = x_smalls/255.0

2.添加残差网络
添加两个函数,一个是leaky_relu为leaky relu激活函数,另一个是用于生成网络残差块的函数residual_block,实现一个中间有两层卷积的残差块。接着在整个网络构造中,通过一个卷积层与一个残差层完成图像特征的转换。残差层是由16个残差块与一个卷积层组成的网络。特征转换之后再通过5层神经网络完成最终的特征修复处理过程。
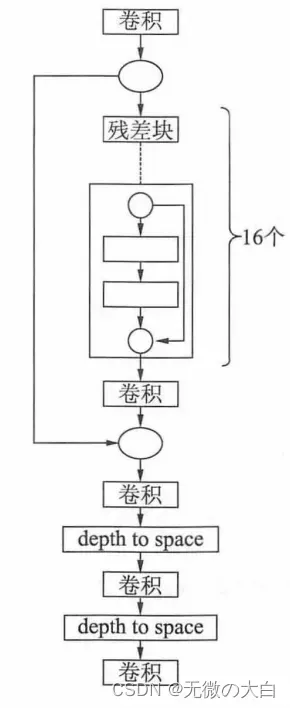
最下面的5层为修复特征数据,第1层是一个卷积层,第2层会按照2×2大小的像素块将第一层的结果展开,第3层与第1层一样,第4层与第2层一样,第5层也是一个卷积层。连续2次变换进行放大4倍的处理,最终通过3通道卷积生成最终图像。
def leaky_relu(x,alpha=0.1,name='lrelu'):
with tf.name_scope(name):
x=tf.maximum(x,alpha*x)
return x
# 两层卷积的残差块
def residual_block(nn,i,name='resblock'):
with tf.variable_scope(name+str(i)):
conv1=slim.conv2d(nn, 64, 3,activation_fn = leaky_relu,normalizer_fn=slim.batch_norm)
conv2=slim.conv2d(conv1, 64, 3,activation_fn = leaky_relu,normalizer_fn=slim.batch_norm)
return tf.add(nn,conv2)
net = slim.conv2d(x_smalls2, 64, 5,activation_fn = leaky_relu)
# 添加残差块
block=[]
for i in range(16):
block.append(residual_block(block[-1] if i else net,i))
conv2=slim.conv2d(block[-1], 64, 3,activation_fn = leaky_relu,normalizer_fn=slim.batch_norm)
sum1=tf.add(conv2,net)
conv3=slim.conv2d(sum1, 256, 3,activation_fn = None)
ps1=tf.depth_to_space(conv3,2)
relu2=leaky_relu(ps1)
conv4=slim.conv2d(relu2, 256, 3,activation_fn = None)
ps2=tf.depth_to_space(conv4,2)#再放大两倍 64
relu3=leaky_relu(ps2)
y_predt=slim.conv2d(relu3, 3, 3,activation_fn = None)#输出
3.修改学习率,进行网络训练
将学习率改为0.001,同样使用AdamOptimizer优化方法,循环100000次。
cost = tf.reduce_mean(tf.pow( tf.cast(images,tf.float32)/255.0 - y_predt, 2))
optimizer = tf.train.AdamOptimizer(learn_rate ).minimize(cost)
training_epochs =10000
display_step =400
4.添加检测点
网络结构的修改会使单次训练的时变长,因此有必要添加检查点文件保存功能。先对变量flags赋值定义检查点保存路径,在session中读取到检查点文件后解析出运行的迭代次数。在range中设置其实次数,让其继续训练。
# 检查点文件名
flags='b'+str(batch_size)+'_h'+str(height/4)+'_r'+str(learn_rate)+'_res'
# 判断文件存在
if not os.path.exists('save'):
os.mkdir('save')
save_path='save/tf_'+flags
if not os.path.exists(save_path):
os.mkdir(save_path)
saver = tf.train.Saver(max_to_keep=1) # 生成saver
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
kpt = tf.train.latest_checkpoint(save_path)
print(kpt)
startepo= 0
if kpt!=None:
saver.restore(sess, kpt)
ind = kpt.find("-")
startepo = int(kpt[ind+1:])
print("startepo=",startepo)
#启动队列
tf.train.start_queue_runners(sess=sess)
# 启动循环开始训练
for epoch in range(startepo,training_epochs):#按照指定次数迭代训练
_, c = sess.run([optimizer, cost])
# 显示训练中的详细信息
if epoch % display_step == 0:
d_batch=dbatch.eval()
mse,psnr=batch_mse_psnr(d_batch)
ypsnr=batch_y_psnr(d_batch)
ssim=batch_ssim(d_batch)
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c),"psnr",psnr,"ypsnr",ypsnr,"ssim",ssim)
saver.save(sess, save_path+"/tfrecord.cpkt", global_step=epoch)
print("完成!")
saver.save(sess, save_path+"/tfrecord.cpkt", global_step=epoch)

五、SRGAN的原理
在图像放大4倍以上时,前面所介绍的方法得到的结果显得过于平滑,而缺少一些细节上的真实感。这是因为,传统方法使用的待代价函数是基于像素点的最小均方差(MSE),该代价函数使重建结果有较高的信噪比,但缺少了高频信息,所以会出现过渡平滑的纹理。
SRGAN的思想是,使重建的高分辨率图像与真实的高分辨率图像,无论是在低层次像素值还是在高层次的抽象特征及整体概念及风格上都应相近。
其中,对整体概念和风格的评估可以使用一个判别器,判别一副高分辨率图像是由算法生成的还是真实图像。如果一个判别器无法区分出来,那么由算法生成的图像就达到了超分辨率 修复很成功的效果。
输入图片自身内容方面的损失值与来自对抗神经网络的损失值一起组成了最终d额损失值(loss)。而对于自己的内容方面,基于像素点的平方差是一部分,另一部分是基于特征空间的平方差。基于特征空间特征提取使用了VGG网络。
六、实例96:使用SRGAN实现flowers数据集的超分辨率修复
本例中用SRGAN在基于残差网络的ESPCN上面进行SR处理,由于在计算生成器loss中的一部分需要使用VGG网络来提取特征,因此本例会用用到VGG19预训练模型。为了方便训练,这里直接使用了前面训练好的ESPCN网络模型作为生成器,用其生成的图片作为判别器的输入,通过GAN的机制进行二次优化。
实例描述
将flowers数据集中的图片转为低分辨率,通过使用SRGAN网络将其还原成高分辨率并与其他复原函数进行比较。
1.引入头文件,图片预处理
images, labels = tf.train.batch([distorted_image, label], batch_size=batch_size)
print(images.shape)
images = tf.cast(images,tf.float32)
x_smalls=tf.image.resize_bicubic(images,[np.int32(height/4), np.int32(width/4)])# 缩小4*4倍
x_smalls2 = x_smalls/127.5-1 #(0--1)
图片中的每个像素点都在0~255之间,所以除以255/2之后就会变成0 ~2之间的值,再减去1,就得到了x_smalls2。
不太清楚两种归一化的不同好处。
2.构建生成器
def gen(x_smalls2 ):
# 卷积层
net = slim.conv2d(x_smalls2, 64, 5,activation_fn = leaky_relu)
# 16个残差块
block=[]
for i in range(16):
block.append(residual_block(block[-1] if i else net,i))
# 卷积层+残差
conv2=slim.conv2d(block[-1], 64, 3,activation_fn = leaky_relu,normalizer_fn=slim.batch_norm)
sum1=tf.add(conv2,net)
# 卷积
conv3=slim.conv2d(sum1, 256, 3,activation_fn = None)
# 放大两倍
ps1=tf.depth_to_space(conv3,2)
relu2=leaky_relu(ps1)
# 卷积
conv4=slim.conv2d(relu2, 256, 3,activation_fn = None)
ps2=tf.depth_to_space(conv4,2)#再放大两倍 64
relu3=leaky_relu(ps2)
# 卷积
y_predt=slim.conv2d(relu3, 3, 3,activation_fn = None)#输出
return y_predt
3.VGG的预输入处理
为了得到生成器基于内容的loss,要将生成的图片与真实图片分别输入VGG网络以得到他们的特征,然后在特征空间上计算loss。所以先将低分辨率图片作为输入放进生成器gen函数中,得到生成的图片resnetimg,并将图片还原成0~255区间正常像素值。同时准备好生成器的训练参数gen_var_list为后面的优化器使用做准备。
&esmp; 使用VGG模型时,必须在输入之前对图片做RGB均值的预处理。先定义处理RGB均值的函数,然后做具体变换。
def rgbmeanfun(rgb):
_R_MEAN = 123.68
_G_MEAN = 116.78
_B_MEAN = 103.94
print("build model started")
# Convert RGB to BGR
red, green, blue = tf.split(axis=3, num_or_size_splits=3, value=rgb)
rgbmean = tf.concat(axis=3, values=[red - _R_MEAN,green -_G_MEAN, blue - _B_MEAN,])
return rgbmean
resnetimg=gen(x_smalls2)
result=(resnetimg+1)*127.5
gen_var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
y_pred = tf.maximum(result,0)
y_pred = tf.minimum(y_pred,255)
dbatch=tf.concat([images,result],0)
rgbmean = rgbmeanfun(dbatch)
4.计算VGG特征空间的loss
VGG中前5个卷积层用于特征提取,所以在使用时,只取其第5个卷积层的输出节点,其他节点可以全部忽略。可以通过slim中的nets文件夹下对应的VGG源码找到对应的节点名称。
#vgg 特征值
_, end_points = vgg.vgg_19(rgbmean, num_classes=1000,is_training=False,spatial_squeeze=False)
conv54=end_points['vgg_19/conv5/conv5_4']
print("vgg.conv5_4",conv54.shape)
fmap=tf.split(conv54,2)
content_loss=tf.losses.mean_squared_error(fmap[0],fmap[1])
由于前面通过concat将两个图片放在一起来处理,得到结果后,要使用split将其分开,接着通过平方差算出基于特征空间的loss。
5.判别器的构建
判别器主要是通过一系列卷积层组合起来构成的,最终使用两个全连接层实现映射到一维的输出结果。
def Discriminator(dbatch, name ="Discriminator"):
with tf.variable_scope(name):
net = slim.conv2d(dbatch, 64, 1,activation_fn = leaky_relu)
ochannels=[64,128,128,256,256,512,512]
stride=[2,1]
for i in range(7):
net = slim.conv2d(net, ochannels[i], 3,stride = stride[i%2],activation_fn = leaky_relu,normalizer_fn=slim.batch_norm,scope='block'+str(i))
dense1 = slim.fully_connected(net, 1024, activation_fn=leaky_relu)
dense2 = slim.fully_connected(dense1, 1, activation_fn=tf.nn.sigmoid)
return dense2
6.计算loss,定义优化器
将判别的结果裁开,分别得到真实图片与生成图片的判别结果,以LSGAN的方式计算生成器与判别器的loss,在生成器loss中加入基于特征空间的loss。按照前面所讲的训练参数的获取方式获得判别器训练参数disc_var_list,使用AdamOptimizer优化loss值。
disc=Discriminator(dbatch)
D_x,D_G_z=tf.split(tf.squeeze(disc),2)
# 获取loss
adv_loss=tf.reduce_mean(tf.square(D_G_z-1.0))
gen_loss=(adv_loss+content_loss)
disc_loss=(tf.reduce_mean(tf.square(D_x-1.0)+tf.square(D_G_z)))
# 得到判别器的参数
disc_var_list=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES)
print("len-----",len(disc_var_list),len(gen_var_list))
for x in gen_var_list: # 去掉生成器的参数
disc_var_list.remove(x)
learn_rate =0.001
global_step=tf.Variable(0,trainable=0,name='global_step')
gen_train_step=tf.train.AdamOptimizer(learn_rate).minimize(gen_loss,global_step,gen_var_list)
disc_train_step=tf.train.AdamOptimizer(learn_rate).minimize(disc_loss,global_step,disc_var_list)
7.指定准备载入的预训练模型路径
这次需要对3个检查点路径进行配置,第一个是本程序的SRGAN检查点文件,第二个是srResNet检查点文件,最后一个是VGG模型文件。
#res 检查点
flags='b'+str(batch_size)+'_r'+str(np.int32(height/4))+'_r'+str(learn_rate)+'srgan'
save_path='save/srgan_'+flags
if not os.path.exists(save_path):
os.mkdir(save_path)
saver = tf.train.Saver(max_to_keep=1) # 生成saver
srResNet_path='./save/tf_b16_h64.0_r0.001_res/'
srResNetloader = tf.train.Saver(var_list=gen_var_list) # 生成saver
#vgg 检查点
checkpoints_dir = 'vgg_19_2016_08_28'
init_fn = slim.assign_from_checkpoint_fn(
os.path.join(checkpoints_dir, 'vgg_19.ckpt'),
slim.get_model_variables('vgg_19'))
8.起动session从检查点恢复变量
log_steps=100
training_epochs=16000
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
init_fn(sess)
kpt = tf.train.latest_checkpoint(srResNet_path)
print("srResNet_path",kpt,srResNet_path)
startepo= 0
if kpt!=None:
srResNetloader.restore(sess, kpt)
ind = kpt.find("-")
startepo = int(kpt[ind+1:])
print("srResNetloader global_step=",global_step.eval(),startepo)
kpt = tf.train.latest_checkpoint(save_path)
print("srgan",kpt)
startepo= 0
if kpt!=None:
saver.restore(sess, kpt)
ind = kpt.find("-")
startepo = int(kpt[ind+1:])
print("global_step=",global_step.eval(),startepo)
9.启动带协调器的队列线程,开始训练
本例中涉及的参数比较多,模型比较大,对导致每次迭代时间都很长,所以加入检查点是非常有必要的,这里涉及检查点的保存进度,如果间隔太短,对减慢训练速度,设置间隔太长,中途如果发生意外会导致浪费一部分训练时间,可以通过try的方式子啊异常捕获时再保存一次检查点,这样可以把中途训练的结果保存下来。
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
def train(endpoint,gen_step,disc_step):
#print(global_step.eval(),endpoint)
while global_step.eval()<=endpoint:
#print(global_step.eval(),global_step.eval()%log_steps)
if((global_step.eval()/2)%log_steps==0):# 一次走两步
#print(global_step.eval(),log_steps)
d_batch=dbatch.eval()
mse,psnr=batch_mse_psnr(d_batch)
ssim=batch_ssim(d_batch)
s=time.strftime('%Y-%m-%d %H:%M:%S:',time.localtime(time.time()))+'step='+str(global_step.eval())+' mse='+str(mse)+' psnr='+str(psnr)+' ssim='+str(ssim)+' gen_loss='+str(gen_loss.eval())+' disc_loss='+str(disc_loss.eval())
print(s)
f=open('info.train_'+flags,'a')
f.write(s+'\n')
f.close()
saver.save(sess, save_path+"/srgan.cpkt", global_step=global_step.eval())
#save()
sess.run(disc_step)
sess.run(gen_step)
train(training_epochs,gen_train_step,disc_train_step)
print('训练完成')
###显示
resultv,imagesv,x_smallv,x_nearestv,x_bilinv,x_bicubicv,y_predv = sess.run([result,images,x_smalls,x_nearests,x_bilins,x_bicubics,y_pred])
print("原",np.shape(imagesv),"缩放后的",np.shape(x_smallv))
conimg1 = np.concatenate((imagesv,x_bilinv))
ssim1=batch_ssim(conimg1)
conimg2 = np.concatenate((imagesv,y_predv))
ssim2=batch_ssim(conimg2)
plt.figure(figsize=(20,10))
showresult(161,"org",imagesv,imagesv,False)
showresult(162,"small/4",imagesv,x_smallv,False)
showresult(163,"near",imagesv,x_nearestv)
showresult(164,"biline",imagesv,x_bilinv)
showresult(165,"bicubicv",imagesv,x_bicubicv)
showresult(166,"pred",imagesv,y_predv)
plt.show()
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
except KeyboardInterrupt:
print("Ending Training...")
saver.save(sess, save_path+"/srgan.cpkt", global_step=global_step.eval())
finally:
coord.request_stop()
coord.join(threads)

文章出处登录后可见!