代码地址ByteTrack
0.前言和算法解读
ByteTrack本质上是利用多次匹配进而提高跟踪准确度的一种方法. 对于大多数MOT方法, 匹配过程是:
1.根据检测进行筛选, 低置信度的bbox就舍弃了.
2.利用Kalman滤波等方式来预测轨迹, 并将轨迹和筛选的bbox进行匹配(通常是匈牙利算法, KM算法或贪心算法)
3.对于没有匹配到的轨迹, 设置一个patience time, 超过这个时间就认为离开画面。如果在这个时间内还可以和新检测匹配上, 就恢复轨迹, 也就是Re-ID.
4.对于存在超过一定帧数但没有匹配上轨迹的检测, 初始化为新轨迹.
那么ByteTrack是怎么做的呢? 它主要是改变了第一点, 也就是对于低置信度检测, 它并不直接舍弃, 而是在优先匹配高置信度检测和轨迹匹配之后, 再将低置信度检测和剩余的轨迹进行匹配.
所以整篇文章的精髓就是下图:
以下是逐行解释。
输入:视频序列
, 目标检测模型
, Kalman滤波
, 检测的高, 低阈值
, 跟踪置信度阈值
输出:轨道
初始化:初始化轨迹集
在视频中的第k帧:
1.检测器得到结果
2.根据设置的检测的高, 低阈值
高置信度部分:
低置信度部分:
3.对轨迹集合中的每一个轨迹
, 利用Kalman滤波来更新:
4.第一次匹配:
将和预测轨迹
对于不匹配的检测框,放,同理,对于不匹配的轨迹,放
。
5.第二次匹配(关键)
对于置信度较低的检测,不直接丢弃,而是与剩余的轨迹匹配,即和
(我的理解: 这一步能够发挥作用的原因是由于遮挡, 模糊等问题可能导致检测的置信度下降, 但是其运动特性并没有消失, 因此可以和轨迹进行再匹配, 降低了FN的可能性.)
对于仍不能匹配的轨迹, 记为. 将其放入
, 可以在patience time内恢复. 若超过了patience time, 就删除.
6.新轨迹诞生
对于没有匹配轨迹的高置信度检测框,则将其初始化为新轨迹。
1.消融实验
在消融实验中,看到下面这张图很有意思: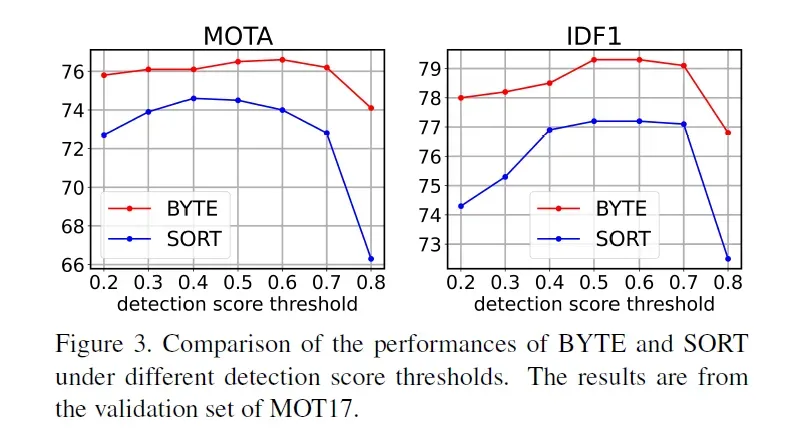
可以发现, 将ByteTrack和SORT作对比。检测高置信度阈值是个非常敏感的参数, 作者从0.2调到0.8, 可以看出来, 在这个阈值过高的时候,MOTA和IDF1是会下降的.(因为高阈值意味着可能更多的检测被舍弃, 进而有更大的FN)。如前面所说, ByteTrack利用二次匹配的特点, 可以对被舍弃的检测框进行二次匹配, 因此在高阈值下,它的MOTA下降并不明显.
那么对于低置信度的阈值呢?会不会不舍弃低置信度的检测, 会造成FP的增加呢? 作者做了实验, 发现对于置信度在之间的检测, 利用ByteTrack的策略, TP总是比FP多, 然而用传统的方法就不一定了, FP有可能比TP多. 因此, ByteTrack也增加了TP, 也减小了FP. 如下图所示:
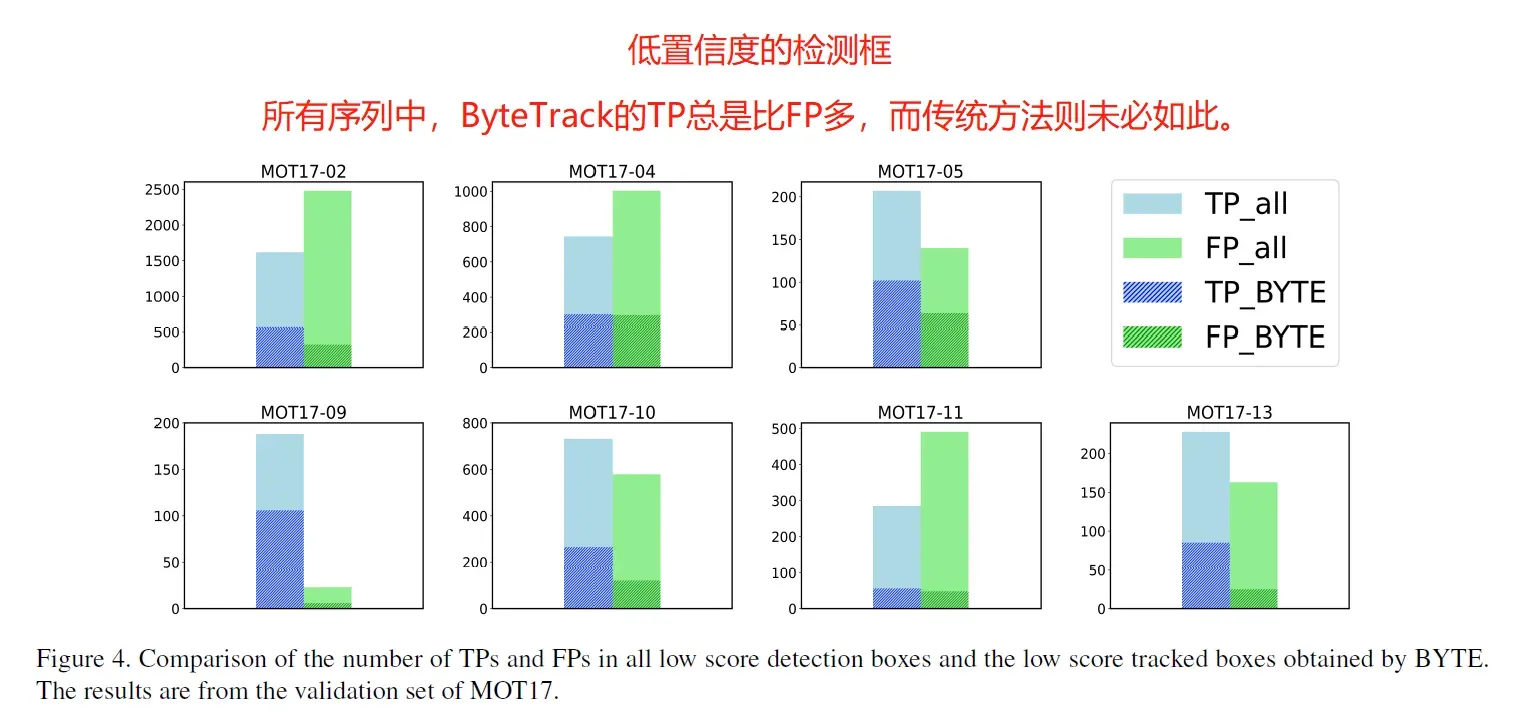
综上, 这就是它work的原因, 增加了低置信度的TP, 减小了因低于高置信度而舍弃bbox造成的FN.
2.具体实现
ByteTrack的这篇论文是用YoloX作主干, 进行以上的匹配策略, 效果很好. 作者提供了和其他许多方法结合的方式, 下面解读一下和MOTR结合的实现.
class BYTETracker(object):
def __init__(self, frame_rate=30):
self.tracked_stracks = [] # type: list[STrack]
self.lost_stracks = [] # type: list[STrack]
self.removed_stracks = [] # type: list[STrack]
self.frame_id = 0
self.low_thresh = 0.2 # 最低阈值
self.track_thresh = 0.8 # 跟踪得分阈值
self.det_thresh = self.track_thresh + 0.1 # 检测高分数阈值为跟踪阈值 + 0.1
self.buffer_size = int(frame_rate / 30.0 * 30)
self.max_time_lost = self.buffer_size # buffer_size也就是最大寿命
self.kalman_filter = KalmanFilter()
def update(self, output_results):
self.frame_id += 1
activated_starcks = [] # 活动的轨迹
refind_stracks = [] # 恢复的轨迹
lost_stracks = [] # 丢失的轨迹
removed_stracks = [] # 移除的轨迹
scores = output_results[:, 4] # output_results的第五列为score
bboxes = output_results[:, :4] # 前四列为x1y1x2y2
remain_inds = scores > self.track_thresh # 将大于跟踪阈值的检测筛选出来
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
inds_low = scores > self.low_thresh # 大于低阈值的索引(小于低阈值的直接放弃)
inds_high = scores < self.track_thresh # 小于跟踪阈值的索引(包括了低阈值的)
inds_second = np.logical_and(inds_low, inds_high) # 取交集,大于低阈值小于跟踪阈值
dets_second = bboxes[inds_second] # 根据索引筛选出检测和置信度
scores_second = scores[inds_second]
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets, scores_keep)] # 将检测存储为list[STrack], 注意detector的结果应为top-left bottom-right形式
# 将其转换为top-left width-height形式
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks: # 将不是active状态的轨迹加入unconfirmed列表, 是active的放入tracked_stracks列表
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
''' Step 2: First association, with Kalman and IOU'''
# 第一轮匹配, 匹配高置信度检测(> self.track_thresh) 和Kalman预测轨迹(顺带匹配lost)
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks) # 将已跟踪的和lost的不重复地凑起来, 相当于每次lost的也参与匹配
# Predict the current location with KF
STrack.multi_predict(strack_pool) # 将这些轨迹用Kalman滤波进行预测
dists = matching.iou_distance(strack_pool, detections) # 将Kalman预测和检测用IoU进行匹配. 注意,strack_pool是已有的轨迹,detections是新检测.
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.8)
# matches: [[轨迹,相应的检测]] u_track: 未匹配的轨迹 u_detection: 未匹配的检测
for itracked, idet in matches: # 在匹配的轨迹与检测当中
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked: # 如果轨迹的状态是正被跟踪, 就更新track(Type(STrack))的信息
track.update(detections[idet], self.frame_id)
activated_starcks.append(track) # 加入active的轨迹
else:
track.re_activate(det, self.frame_id, new_id=False) # 如果匹配到了但是不是被跟踪的, 就复活轨迹
refind_stracks.append(track)
''' Step 3: Second association, with IOU'''
# association the untrack to the low score detections
# 匹配大于low_thresh小于track_thresh的检测与上一轮没匹配的轨迹
if len(dets_second) > 0:
'''Detections'''
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
# r_tracked_stracks: 状态为被跟踪的未匹配的轨迹
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections_second) # 将未匹配的轨迹和较低置信度检测进行关联
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5) # u_track为仍未匹配的
for itracked, idet in matches: # 同第一轮匹配
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:
#track = r_tracked_stracks[it]
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost: # 仍未匹配的 记为lost
track.mark_lost()
lost_stracks.append(track)
'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''
# 第三轮 把未确认(原有轨迹中状态为inactive)的轨迹和第一轮未匹配的检测进行关联
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
for it in u_unconfirmed: # 还没有匹配到的轨迹 标记removed
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
""" Step 4: Init new stracks"""
# 仍未匹配的检测,如果置信度大于det_thresh(det_thresh = track_thresh + 1,比较大), 就初始化为新轨迹
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
""" Step 5: Update state"""
# 超过寿命的lost轨迹标记为removed
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
# print('Ramained match {} s'.format(t4-t3))
# 把前面的计算结果用上, 统统更新self的变量值, 包括tracked_stracks加入active的和恢复的,
# lost的去除恢复的和removed的之外, 加入新计算出的lost的
# 更新removed的
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)
self.lost_stracks.extend(lost_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)
self.removed_stracks.extend(removed_stracks)
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
# get scores of lost tracks
output_stracks = [track for track in self.tracked_stracks if track.is_activated]
return output_stracks # 输出active的被跟踪的tracks
文章出处登录后可见!