1. ALBEF: ALign the image and text BEfore Fusing
1.1 论文与代码链接:
https://arxiv.org/abs/2107.07651
GitHub – salesforce/ALBEF: Code for ALBEF: a new vision-language pre-training method
1.2 目标任务:
视觉-文本 融合任务,如图文检索、视觉问答、NLVR (natural language vision reasoning)等
1.3 当前方法问题:
1)没有对齐视觉的 tokens 和 文字的 tokens, 因此给 多模编码器进行图文交互学习时带来挑战
2)训练多模模型,利用到了互联网上爬取的数据,这些数据中往往存在大量噪声,传统的图文特征融合训练模式(如 MLM, masked language modeling) 可能过拟合到噪声文本上,从而影响模型的泛化性能。
1.4 本文解决方案:
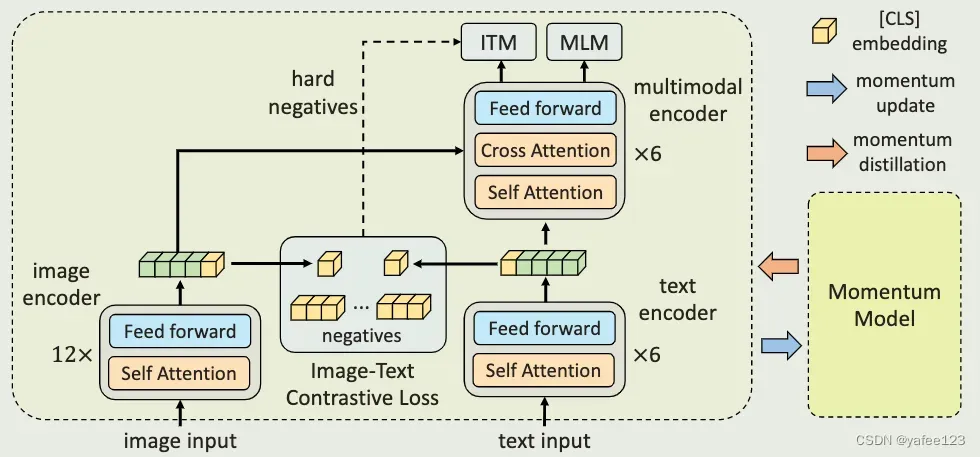
1) 通过跨模态 attention 的方式引入对比损失,在图文特征融合前对齐图像和文本表征,相对与大多数传统方案来说,不需要在高清图片上进行框级别的标注。
2)提出一种 动量蒸馏 (momentum distillation) 的方案,即通过自训练(self-training)的方式从动量模型提供的伪标签中进行学习。
在训练过程中,通过参数移动平均的方式更新动量模型,并利用动量模型生成伪标签(pseudo-targets) 作为额外的监督信息。利用动量蒸馏的方式,模型将不在惩罚模型合理的输出,即使这个输出与网络标签不一致,提升从网络噪声数据中学习的能力。
1.5 实验结果:
1)在图文检索任务中,本方案优于在大规模数据集中预训练的方案(CLIP & ALIGN)
2) 在 VQA 和 NLVR 任务中,本方案相对 SOTA 算法(VILIA)分别获得了 2.37% 和 3.84% 的指标提升,而且获得了更快的推理速度。
2. BLIP (Bootstrapping Language- Image Pretraining)
2.1 论文与代码链接:
https://arxiv.org/abs/2201.12086
2.2 目标任务:
视觉-文本 融合任务,如图文检索、视觉问答、NLVR (natural language vision reasoning)等
2.3 当前方法问题:
1)当前 视觉-语言 预训练(VLP)推动了 视觉语言预训练任务的性能,然而大多数现有的预训练模型或者擅长基于理解的任务(分类)或者基于生成的任务之一。encoder-based 架构不擅长生成类任务,encoder-decoder 架构不擅长分类相关任务(如 图文跨模态检索)
2)当前 VLP 模型的性能提升依赖于扩大图文对训练集,这些图文对通常是从互联网上爬取的,所以噪声相对较大。
2.4 本文解决方案:
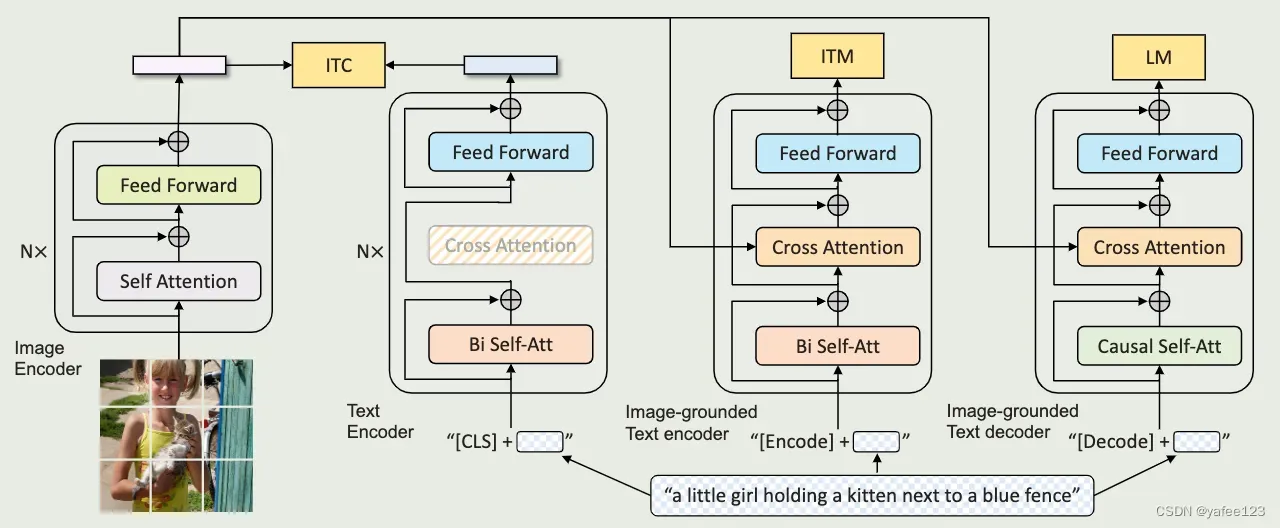
提出一种新的 VLP 框架,可以在视觉-语言的 理解任务 和 生成任务 之间灵活转换,而且可以通过booststraping 的方式有效利用噪声数据,即构造了一个 captioner 用于生成captions,一个 filters 移除噪声 captions。具体如下:
1)提出一种多模混合 encoder-decoder 架构 (MED):可以作为独立的编码器,也可以分别作为 基于图像的文本编码器和解码器。通过联合三种视觉-语言 的目标进行学习:图文对比学习、图文匹配 和 基于图像的语言建模(image-conditioned language modeling)。
2.5 实验结果:
1)在图文检索任务中,本方案相较 SOTA, top1 recall 提升了 2.7%
2)在 image caption 任务中,CIDEr 指标提升 2.8%
2) 在 VQA 本方案相对 SOTA 算法获得了 1.6% 的VQA score 指标提升
3. BLIP -2 (Bootstrapping Language- Image Pretraining)
3.1 论文与代码链接:
https://export.arxiv.org/pdf/2301.12597v1.pdf
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
3.2 目标任务:
视觉-文本 融合任务,如图文检索、视觉问答、NLVR (natural language vision reasoning)等
3.3 当前方法问题:
由于模型越来越大,VLP 预训练成本变得越来越高。
3.4 本文解决方案
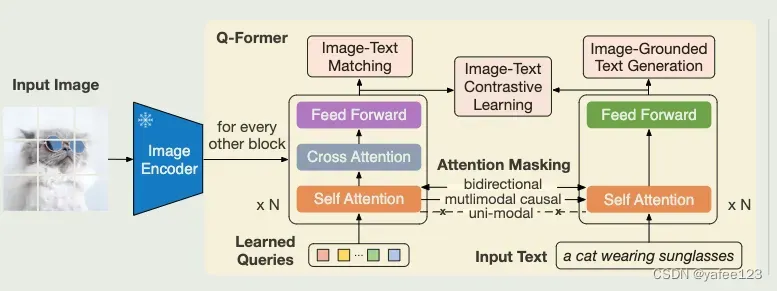
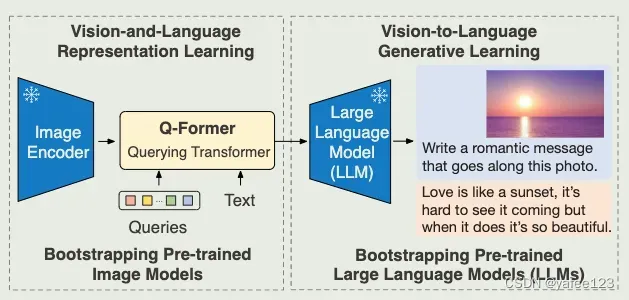
充分利用大模型原始能力,不做预训练,而通过设计一个轻量级的 Querying transformer(Q-former) 连接视觉大模型和语言大模型。Q-former 通过两阶段方式进行训练:
阶段 1:固定图像编码器,学习视觉-语言(vision-language)一致性的表征
阶段 2: 固定语言大模型,提升视觉到语言(vision-to-language)的生成能力
参考文献:
- Li, Junnan, et al. “Align before Fuse: Vision and Language Representation Learning with Momentum Distillation.” in NeuraIPS 2021.
- Li, Junnan, et al. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, in ICML 2022.
- Li, Junnan, et al. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, arxiv preprint 2023.
文章出处登录后可见!