在美赛的时候,用了一下这个模型,发一下。
Word2Vec是一种用于将文本转换为向量表示的技术。它是Google在2013年开发的一种工具,主要用于将单词转换为向量表示,并在向量空间中找到单词之间的语义关系。Word2Vec模型有两种架构:连续词袋模型(Continuous Bag-of-Words,简称CBOW)和跳跃式模型(Skip-Gram)。
在CBOW模型中,模型试图从上下文中推断出当前单词,而在Skip-Gram模型中,模型试图从当前单词中推断出上下文单词。Word2Vec的目标是学习到一个向量空间,使得在这个向量空间中,语义上相似的单词在空间上也比较接近。具体地说,Word2Vec将单词表示为高维向量,这些向量被设计为捕捉到单词在上下文中出现的概率分布。这些向量被训练出来后,可以用于各种自然语言处理任务,如文本分类、语言翻译和情感分析等。
在一般情况下,Skip-gram算法对于训练较小的语料库或者低频单词表现较好,而CBOW算法对于训练较大的语料库或者高频单词表现较好。
话不多说,直接上代码。
import pandas as pd
from gensim.models import Word2Vec
# 读入数据
# 读取训练文本
with open('output.txt', 'r', encoding='utf-8') as f:
sentences = [line.strip().split() for line in f]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4, sg=1)
model.save('word2vec.model')
# 读取另一个文件,提取单词的特征向量并保存到vector.csv
df = pd.read_csv('word.csv',encoding="gbk")
word_list = df['Word'].tolist()
vectors = []
for word in word_list:
if word in model.wv:
vectors.append(model.wv[word])
else:
vectors.append([0] * 100) # 如果单词不在词汇表中,填充为0向量
vectors_df = pd.DataFrame(vectors)
vectors_df.to_csv('2.csv', index=False, header=None)然后我解释一下每一步都是干什么的。
with open('output.txt', 'r', encoding='utf-8') as f:
sentences = [line.strip().split() for line in f]
打开名为 “output.txt” 的文件并读取其中的文本,将其转化为一个嵌套列表的形式,每个列表表示文本中的一句话,每个句子中的单词被拆分成单独的元素。
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4, sg=1)
model.save('word2vec.model')
使用 Word2Vec 对句子进行训练。其中,vector_size 表示特征向量的维度,window 表示在每个单词周围的最大距离,min_count 表示单词的最小出现次数,workers 表示并行训练的线程数,sg 表示使用的算法类型(sg=1表示使用Skip-gram算法进行训练,而sg=0表示使用CBOW算法进行训练)。最后将训练好的模型保存在名为 “word2vec.model” 的文件中。
df = pd.read_csv('word.csv', encoding="gbk")
word_list = df['Word'].tolist()
使用 pandas 库读取名为 “word.csv” 的文件,提取其中 “Word” 列的数据,将其转化为列表形式。这个数据就是我们需要提取特征向量的数据
vectors = []
for word in word_list:
if word in model.wv:
vectors.append(model.wv[word])
else:
vectors.append([0] * 100)
对于列表中的每个单词,判断其是否在训练好的 Word2Vec 模型中。如果存在,则提取其特征向量并添加到 vectors 列表中;否则将其向量设为全为 0 的向量。
问题就在这,你要是训练用的文本不够多,没有你要提取向量的单词,你结果就是0.
vectors_df = pd.DataFrame(vectors)
vectors_df.to_csv('WordVector.csv', index=False, header=None)将 vectors 列表转化为 pandas 数据帧格式,并将其保存为名为 “WordVector.csv” 的文件
output.txt就是模型的训练数据,本来Google已经提供了训练数据了但我一直下载不成功。Google那个数据更大,应该要训练挺长时间的。
数据网址:https://code.google.com/archive/p/word2vec/
如果下载成功了那个,就可以把训练模型的代码改一下。(路径写对就行)
# 加载预训练模型
model_path = 'path/to/GoogleNews-vectors-negative300.bin.gz'
model = KeyedVectors.load_word2vec_format(model_path, binary=True)然后看数据
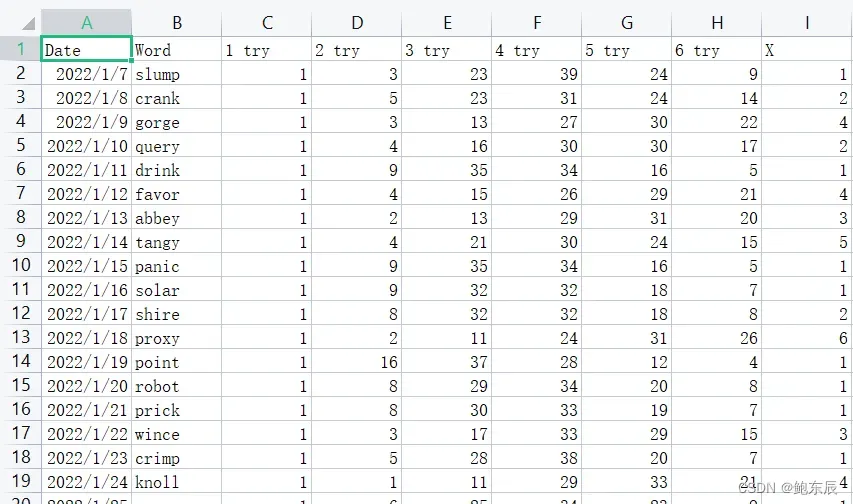
Word.csv长这样
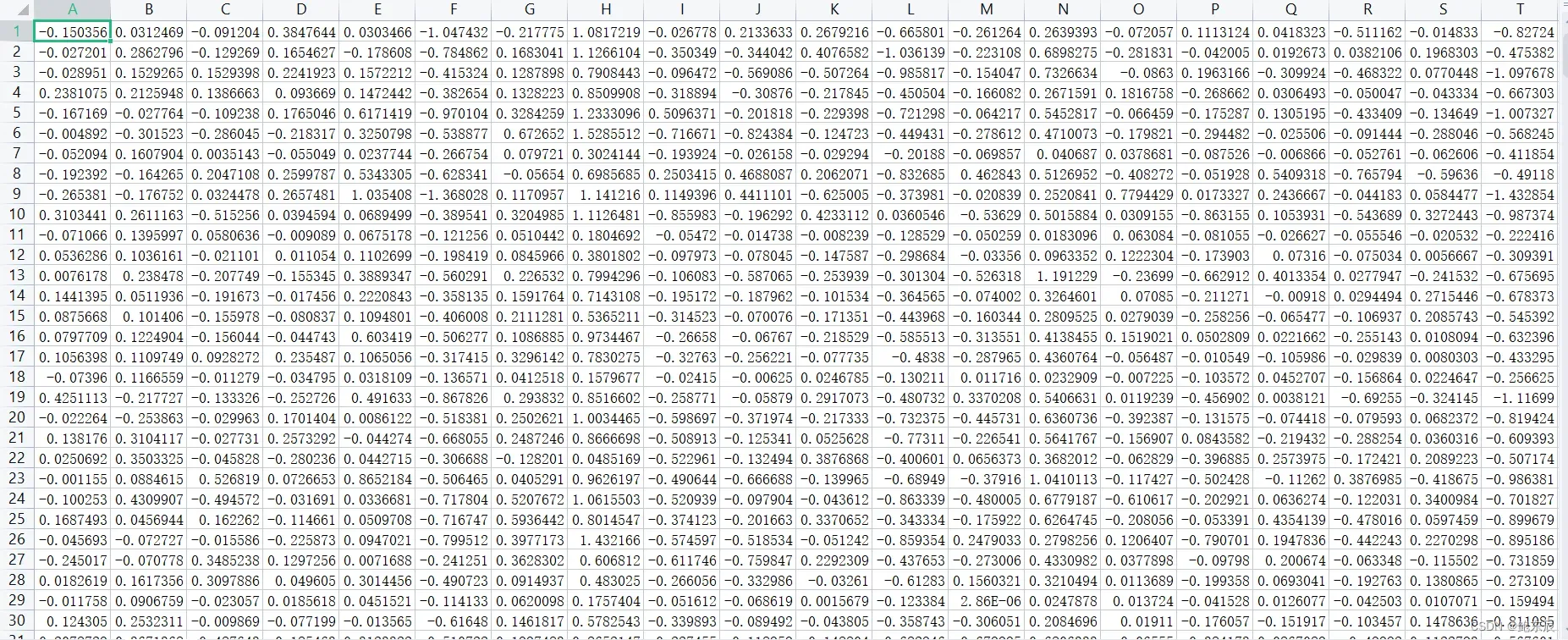
结果提取的向量长这样,每一行对应一个单词的特征向量 ,一共100列就是100维的特征向量。
文章出处登录后可见!