前言
关系抽取是自然语言处理中的一个基本任务。关系抽取通常用三元组(subject, relation, object)表示。但在关系抽取中往往会面临的关系三元组重叠问题。《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》提出的CASREL模型可以有效的处理重叠关系三元组问题。
论文名称:《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》
论文链接:https://aclanthology.org/2020.acl-main.136.pdf
代码地址:https://github.com/weizhepei/CasRel (keras版)
数据采用的是百度数据,下载地址 阿里云盘分享
{"text": "1997年,李柏光从北京大学法律系博士毕业", "spo_list": [{"predicate": "毕业院校", "object_type": "学校", "subject_type": "人物", "object": "北京大学", "subject": "李柏光"}]}
{"text": "当《三生三世》4位女星换上现代装:第四,安悦溪在《三生三世十里桃花》中饰演少辛,安悦溪穿上现代装十分亮眼,气质清新脱俗", "spo_list": [{"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "安悦溪", "subject": "三生三世十里桃花"}]}
{"text": "山东海益宝水产股份有限公司成立于2002年,坐落在风景秀丽的中国胶东半岛,是一家以高科技海产品的育苗、养殖、研发、加工、销售为一体的综合性新型产业化水产企业,拥有标准化深海围堰基地,是山东省水产养殖行业的龙头企业之一,同时也是国内日本红参与胶东参杂交参种产业化生产基地", "spo_list": [{"predicate": "成立日期", "object_type": "日期", "subject_type": "机构", "object": "2002年", "subject": "山东海益宝水产股份有限公司"}]}
{"text": "《骑士之爱与游吟诗人》是上海社会科学院出版社2012年出版的图书,作者是英国的 菲奥娜·斯沃比", "spo_list": [{"predicate": "出版社", "object_type": "出版社", "subject_type": "图书作品", "object": "上海社会科学院出版社", "subject": "骑士之爱与游吟诗人"}, {"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "菲奥娜·斯沃比", "subject": "骑士之爱与游吟诗人"}]}
{"text": "2011年,担任爱情片《失恋33天》的编剧,该片改编自鲍鲸鲸的同名小说,由文章、白百何共同主演6", "spo_list": [{"predicate": "作者", "object_type": "人物", "subject_type": "图书作品", "object": "鲍鲸鲸", "subject": "失恋33天"}, {"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "白百何", "subject": "失恋33天"}, {"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "文章", "subject": "失恋33天"}]}
{"text": "邢富业,男,汉族,1963年1月出生,祖籍山东省莱芜市,现工作于山东能源新汶矿业集团协庄煤矿", "spo_list": [{"predicate": "出生日期", "object_type": "日期", "subject_type": "人物", "object": "1963年1月", "subject": "邢富业"}, {"predicate": "民族", "object_type": "文本", "subject_type": "人物", "object": "汉族", "subject": "邢富业"}, {"predicate": "出生地", "object_type": "地点", "subject_type": "人物", "object": "山东省莱芜市", "subject": "邢富业"}]}
{"text": "史岳,中国新锐摄影师,以拍摄写意风格的电影著称,毕业于北京电影学院摄影系,曾拍摄近百部电影、电视剧、广告作品", "spo_list": [{"predicate": "国籍", "object_type": "国家", "subject_type": "人物", "object": "中国", "subject": "史岳"}, {"predicate": "毕业院校", "object_type": "学校", "subject_type": "人物", "object": "北京电影学院", "subject": "史岳"}]}
{"text": "刘冬元,(1953-1992)中共党员,祁阳县凤凰乡凤凰村人,1953年11月出生,1969年参加工作,先后任凤凰公社话务员、广播员,上司源乡中学副校长,白果市乡中学校长、辅导区主任、金洞学区业务专干、百里乡人民政府纪检员", "spo_list": [{"predicate": "出生日期", "object_type": "日期", "subject_type": "人物", "object": "1953年11月", "subject": "刘冬元"}, {"predicate": "出生地", "object_type": "地点", "subject_type": "人物", "object": "祁阳县凤凰乡凤凰村", "subject": "刘冬元"}]}
{"text": "《铁杉树丛第三季》是由伊莱·罗斯执导,法米克·詹森/比尔·斯卡斯加德/兰登·莱伯隆/卡内赫迪奥·霍恩/乔尔·德·拉·冯特等主演的电视剧,于2015年开播", "spo_list": [{"predicate": "导演", "object_type": "人物", "subject_type": "影视作品", "object": "伊莱·罗斯", "subject": "铁杉树丛第三季"}, {"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "法米克·詹森", "subject": "铁杉树丛第三季"}, {"predicate": "主演", "object_type": "人物", "subject_type": "影视作品", "object": "比尔·斯卡斯加德", "subject": "铁杉树丛第三季"}]}定义的关系共有18中,存放于命名为rel.json的文件中。
{
"0": "出品公司",
"1": "国籍",
"2": "出生地",
"3": "民族",
"4": "出生日期",
"5": "毕业院校",
"6": "歌手",
"7": "所属专辑",
"8": "作词",
"9": "作曲",
"10": "连载网站",
"11": "作者",
"12": "出版社",
"13": "主演",
"14": "导演",
"15": "编剧",
"16": "上映时间",
"17": "成立日期"
}1.模型简介
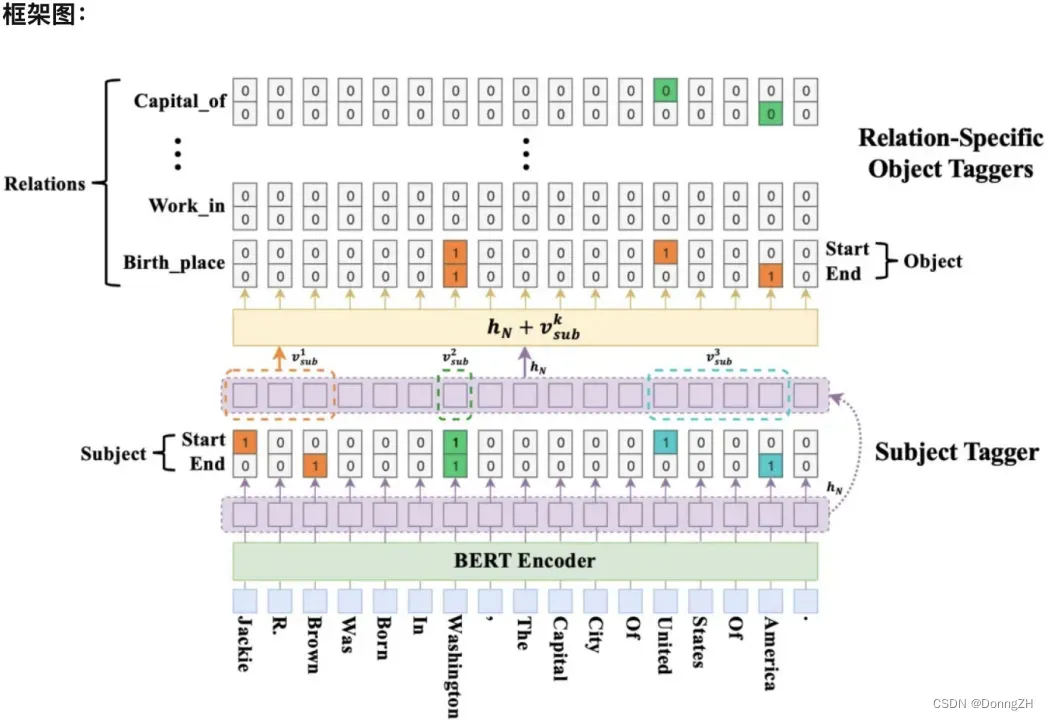
1-1 CASREL 分为两个步骤
1.识别出句子中的subject
2.根据subject识别出所有可能的relation和object
1-2 模型分为三个部分
1.BERT-based encoder module:编码
2.subject tagging module:目的是识别出句子中的 subject。
3.relation-specific object tagging module:根据 subject,寻找可能的 relation 和 object。
2 代码实现
2-1 引入必要的库
import torch
from fastNLP import Vocabulary
from transformers import BertTokenizer, AdamW
from collections import defaultdict
from random import choice
import json
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from transformers import BertModel
import pandas as pd
from tqdm import tqdm2-1 定义Config
写好config,将基本的配置放入config中,方便配置统一设置。
#定义Class Config类
class Config:
"""
句子最长长度是294 这里就不设参数限制长度了,每个batch 自适应长度
"""
def __init__(self):
#指定GPU
self.device = torch.device('cuda:1' if torch.cuda.is_available() else 'cpu')
#给出bert路径
self.bert_path = './Pretrain_model/bert-base-chinese'
#限定域关系抽取,指定关系的种类数
self.num_rel = 18
#给出文件路径
self.train_data_path = './Jupyter_files/Codes/train.json'
self.dev_data_path = './Jupyter_files/Codes/dev.json'
self.test_data_path = './Jupyter_files/Codes/test.json'
self.batch_size = 5
self.rel_dict_path = './CasRelPyTorch/data/baidu/rel.json'
id2rel = json.load(open(self.rel_dict_path, encoding='utf8'))
self.rel_vocab = Vocabulary(unknown=None, padding=None)
self.rel_vocab.add_word_lst(list(id2rel.values())) # 关系到id的映射
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.learning_rate = 1e-5
self.bert_dim = 768
self.epochs = 102-3 定义数据处理流
继承Dataset类,生成MyDataset。
class MyDataset(Dataset):
def __init__(self, path):
super().__init__()
self.dataset = []
with open(path, encoding='utf8') as F:
for line in F:
line = json.loads(line)
self.dataset.append(line)
def __getitem__(self, item):
content = self.dataset[item]
text = content['text']
spo_list = content['spo_list']
return text, spo_list
def __len__(self):
return len(self.dataset)def collate_fn(batch):
# batch是一个列表,其中是一个一个的元组,每个元组是dataset中_getitem__的结果
batch = list(zip(*batch))
text = batch[0]
triple = batch[1]
del batch
return text, triple
#创建数据迭代器
def create_data_iter(config):
train_data = MyDataset(config.train_data_path)
dev_data = MyDataset(config.dev_data_path)
test_data = MyDataset(config.test_data_path)
train_iter = DataLoader(train_data, batch_size=config.batch_size, collate_fn=collate_fn)#shuffle=True,
dev_iter = DataLoader(dev_data, batch_size=config.batch_size, collate_fn=collate_fn)
test_iter = DataLoader(test_data, batch_size=config.batch_size,collate_fn=collate_fn)
return train_iter, dev_iter, test_iter查看迭代数据
config = Config()
train_iter, dev_iter, test_iter = create_data_iter(config)
for text, triple in (dev_iter):
print(text,triple)
2-4 定义Batch类
Batch类是用来处理迭代batch中的数据,生成tensor。
class Batch:
def __init__(self, config):
self.tokenizer = config.tokenizer
self.num_relations = config.num_rel
self.rel_vocab = config.rel_vocab
self.device = config.device
def __call__(self, text, triple):
text = self.tokenizer(text, padding=True).data
batch_size = len(text['input_ids'])
seq_len = len(text['input_ids'][0])
sub_head = []
sub_tail = []
sub_heads = []
sub_tails = []
obj_heads = []
obj_tails = []
sub_len = []
sub_head2tail = []
for batch_index in range(batch_size):
inner_input_ids = text['input_ids'][batch_index] # 单个句子变成索引后
inner_triples = triple[batch_index]
inner_sub_heads, inner_sub_tails, inner_sub_head, inner_sub_tail, inner_sub_head2tail, inner_sub_len, inner_obj_heads, inner_obj_tails = \
self.create_label(inner_triples, inner_input_ids, seq_len)
sub_head.append(inner_sub_head)
sub_tail.append(inner_sub_tail)
sub_len.append(inner_sub_len)
sub_head2tail.append(inner_sub_head2tail)
sub_heads.append(inner_sub_heads)
sub_tails.append(inner_sub_tails)
obj_heads.append(inner_obj_heads)
obj_tails.append(inner_obj_tails)
input_ids = torch.tensor(text['input_ids']).to(self.device)
mask = torch.tensor(text['attention_mask']).to(self.device)
sub_head = torch.stack(sub_head).to(self.device)
sub_tail = torch.stack(sub_tail).to(self.device)
sub_heads = torch.stack(sub_heads).to(self.device)
sub_tails = torch.stack(sub_tails).to(self.device)
sub_len = torch.stack(sub_len).to(self.device)
sub_head2tail = torch.stack(sub_head2tail).to(self.device)
obj_heads = torch.stack(obj_heads).to(self.device)
obj_tails = torch.stack(obj_tails).to(self.device)
return {
'input_ids': input_ids,
'mask': mask,
'sub_head2tail': sub_head2tail,
'sub_len': sub_len
}, {
'sub_heads': sub_heads,
'sub_tails': sub_tails,
'obj_heads': obj_heads,
'obj_tails': obj_tails
}
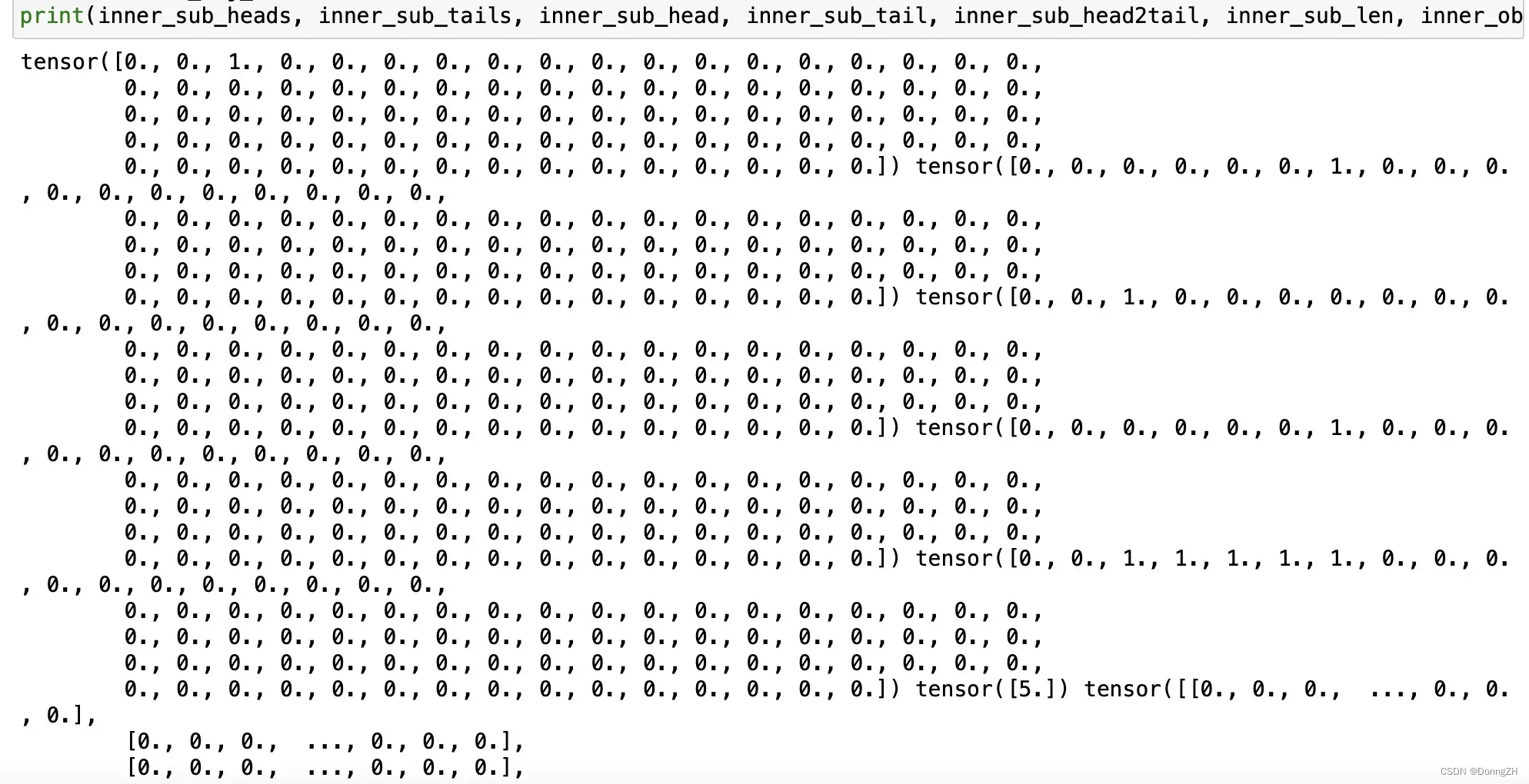
def create_label(self, inner_triples, inner_input_ids, seq_len):
inner_sub_heads, inner_sub_tails = torch.zeros(seq_len), torch.zeros(seq_len)
inner_sub_head, inner_sub_tail = torch.zeros(seq_len), torch.zeros(seq_len)
inner_obj_heads = torch.zeros((seq_len, self.num_relations))
inner_obj_tails = torch.zeros((seq_len, self.num_relations))
inner_sub_head2tail = torch.zeros(seq_len) # 随机抽取一个实体,从开头一个词到末尾词的索引
# 因为数据预处理代码还待优化,会有不存在关系三元组的情况,
# 初始化一个主词的长度为1,即没有主词默认主词长度为1,
# 防止零除报错,初始化任何非零数字都可以,没有主词分子是全零矩阵
inner_sub_len = torch.tensor([1], dtype=torch.float)
# 主词到谓词的映射
s2ro_map = defaultdict(list)
for inner_triple in inner_triples:
inner_triple = (
self.tokenizer(inner_triple['subject'], add_special_tokens=False)['input_ids'],
self.rel_vocab.to_index(inner_triple['predicate']),
self.tokenizer(inner_triple['object'], add_special_tokens=False)['input_ids']
)
sub_head_idx = self.find_head_idx(inner_input_ids, inner_triple[0])
obj_head_idx = self.find_head_idx(inner_input_ids, inner_triple[2])
if sub_head_idx != -1 and obj_head_idx != -1:
sub = (sub_head_idx, sub_head_idx + len(inner_triple[0]) - 1)
# s2ro_map保存主语到谓语的映射
s2ro_map[sub].append(
(obj_head_idx, obj_head_idx + len(inner_triple[2]) - 1, inner_triple[1])) # {(3,5):[(7,8,0)]} 0是关系
if s2ro_map:
for s in s2ro_map:
inner_sub_heads[s[0]] = 1
inner_sub_tails[s[1]] = 1
sub_head_idx, sub_tail_idx = choice(list(s2ro_map.keys()))
inner_sub_head[sub_head_idx] = 1
inner_sub_tail[sub_tail_idx] = 1
inner_sub_head2tail[sub_head_idx:sub_tail_idx + 1] = 1
inner_sub_len = torch.tensor([sub_tail_idx + 1 - sub_head_idx], dtype=torch.float)
for ro in s2ro_map.get((sub_head_idx, sub_tail_idx), []):
inner_obj_heads[ro[0]][ro[2]] = 1
inner_obj_tails[ro[1]][ro[2]] = 1
return inner_sub_heads, inner_sub_tails, inner_sub_head, inner_sub_tail, inner_sub_head2tail, inner_sub_len, inner_obj_heads, inner_obj_tails
@staticmethod
def find_head_idx(source, target):
target_len = len(target)
for i in range(len(source)):
if source[i: i + target_len] == target:
return i
return -1

2-5 模型定义
class CasRel(nn.Module):
def __init__(self, config):
super(CasRel, self).__init__()
self.config = config
self.bert = BertModel.from_pretrained(self.config.bert_path)
self.sub_heads_linear = nn.Linear(self.config.bert_dim, 1)
self.sub_tails_linear = nn.Linear(self.config.bert_dim, 1)
self.obj_heads_linear = nn.Linear(self.config.bert_dim, self.config.num_rel)
self.obj_tails_linear = nn.Linear(self.config.bert_dim, self.config.num_rel)
self.alpha = 0.25
self.gamma = 2
def get_encoded_text(self, token_ids, mask):
encoded_text = self.bert(token_ids, attention_mask=mask)[0]
return encoded_text
def get_subs(self, encoded_text):
pred_sub_heads = torch.sigmoid(self.sub_heads_linear(encoded_text))
pred_sub_tails = torch.sigmoid(self.sub_tails_linear(encoded_text))
return pred_sub_heads, pred_sub_tails
def get_objs_for_specific_sub(self, sub_head2tail, sub_len, encoded_text):
# sub_head_mapping [batch, 1, seq] * encoded_text [batch, seq, dim]
sub = torch.matmul(sub_head2tail, encoded_text) # batch size,1,dim
sub_len = sub_len.unsqueeze(1)
sub = sub / sub_len # batch size, 1,dim
encoded_text = encoded_text + sub
# [batch size, seq len,bert_dim] -->[batch size, seq len,relathion counts]
pred_obj_heads = torch.sigmoid(self.obj_heads_linear(encoded_text))
pred_obj_tails = torch.sigmoid(self.obj_tails_linear(encoded_text))
return pred_obj_heads, pred_obj_tails
def forward(self, input_ids, mask, sub_head2tail, sub_len):
"""
:param token_ids:[batch size, seq len]
:param mask:[batch size, seq len]
:param sub_head:[batch size, seq len]
:param sub_tail:[batch size, seq len]
:return:
"""
encoded_text = self.get_encoded_text(input_ids, mask)
pred_sub_heads, pred_sub_tails = self.get_subs(encoded_text)
sub_head2tail = sub_head2tail.unsqueeze(1) # [[batch size,1, seq len]]
pred_obj_heads, pre_obj_tails = self.get_objs_for_specific_sub(sub_head2tail, sub_len, encoded_text)
return {
"pred_sub_heads": pred_sub_heads,
"pred_sub_tails": pred_sub_tails,
"pred_obj_heads": pred_obj_heads,
"pred_obj_tails": pre_obj_tails,
'mask': mask
}
def compute_loss(self, pred_sub_heads, pred_sub_tails, pred_obj_heads, pred_obj_tails, mask, sub_heads,
sub_tails, obj_heads, obj_tails):
rel_count = obj_heads.shape[-1]
rel_mask = mask.unsqueeze(-1).repeat(1, 1, rel_count)
loss_1 = self.loss_fun(pred_sub_heads, sub_heads, mask)
loss_2 = self.loss_fun(pred_sub_tails, sub_tails, mask)
loss_3 = self.loss_fun(pred_obj_heads, obj_heads, rel_mask)
loss_4 = self.loss_fun(pred_obj_tails, obj_tails, rel_mask)
return loss_1 + loss_2 + loss_3 + loss_4
def loss_fun(self, logist, label, mask):
count = torch.sum(mask)
logist = logist.view(-1)
label = label.view(-1)
mask = mask.view(-1)
alpha_factor = torch.where(torch.eq(label,1), 1- self.alpha,self.alpha)
focal_weight = torch.where(torch.eq(label,1),1-logist,logist)
loss = -(torch.log(logist) * label + torch.log(1 - logist) * (1 - label)) * mask
return torch.sum(focal_weight * loss) / count2-6 加载训练参数
将训练的参数和模型封装到一个函数中,在调用时既方便又降低了在构造训练函数时的冗余。
def load_model(config):
device = config.device
model = CasRel(config)
model.to(device)
# prepare optimzier
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], "weight_decay": 0.01},
{"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0}]
optimizer = AdamW(optimizer_grouped_parameters, lr=config.learning_rate, eps=10e-8)
sheduler = None
return model, optimizer, sheduler, device2-7 定义训练函数
def train_epoch(model, train_iter, dev_iter, optimizer, batch, best_triple_f1, epoch):
for step, (text, triple) in enumerate(train_iter):
model.train()
inputs, labels = batch(text, triple)
logist = model(**inputs)
loss = model.compute_loss(**logist, **labels)
model.zero_grad()
loss.backward()
optimizer.step()
#每500步做一次验证
if step % 500 == 1:
sub_precision, sub_recall, sub_f1, triple_precision, triple_recall, triple_f1, df = test(model, dev_iter,batch)
if triple_f1 > best_triple_f1:
best_triple_f1 = triple_f1
#直接保存模型
torch.save(model, 'best_f1.pth')
#torch.save(model.state_dict(), 'best_f1.pth')
print('epoch:{},step:{},sub_precision:{:.4f}, sub_recall:{:.4f}, sub_f1:{:.4f}, triple_precision:{:.4f}, triple_recall:{:.4f}, triple_f1:{:.4f},train loss:{:.4f}'.format(
epoch, step, sub_precision, sub_recall, sub_f1, triple_precision, triple_recall, triple_f1,
loss.item()))
print(df)
return best_triple_f1def train(model, train_iter, dev_iter, optimizer, config,batch):
epochs = config.epochs
best_triple_f1 = 0
for epoch in range(epochs):
best_triple_f1 = train_epoch(model, train_iter, dev_iter, optimizer, batch, best_triple_f1, epoch)2-8 定义验证(测试)函数
使用pd.DataFrame()进行输出显示,并自定义计算准召率。
def test(model, dev_iter, batch):
model.eval()
df = pd.DataFrame(columns=['TP', 'PRED', "REAL", 'p', 'r', 'f1'], index=['sub', 'triple'])
df.fillna(0, inplace=True)
for text, triple in tqdm(dev_iter):
inputs, labels = batch(text, triple)
logist = model(**inputs)
pred_sub_heads = convert_score_to_zero_one(logist['pred_sub_heads'])
pred_sub_tails = convert_score_to_zero_one(logist['pred_sub_tails'])
sub_heads = convert_score_to_zero_one(labels['sub_heads'])
sub_tails = convert_score_to_zero_one(labels['sub_tails'])
batch_size = inputs['input_ids'].shape[0]
obj_heads = convert_score_to_zero_one(labels['obj_heads'])
obj_tails = convert_score_to_zero_one(labels['obj_tails'])
pred_obj_heads = convert_score_to_zero_one(logist['pred_obj_heads'])
pred_obj_tails = convert_score_to_zero_one(logist['pred_obj_tails'])
for batch_index in range(batch_size):
pred_subs = extract_sub(pred_sub_heads[batch_index].squeeze(), pred_sub_tails[batch_index].squeeze())
true_subs = extract_sub(sub_heads[batch_index].squeeze(), sub_tails[batch_index].squeeze())
pred_ojbs = extract_obj_and_rel(pred_obj_heads[batch_index], pred_obj_tails[batch_index])
true_objs = extract_obj_and_rel(obj_heads[batch_index], obj_tails[batch_index])
df['PRED']['sub'] += len(pred_subs)
df['REAL']['sub'] += len(true_subs)
for true_sub in true_subs:
if true_sub in pred_subs:
df['TP']['sub'] += 1
df['PRED']['triple'] += len(pred_ojbs)
df['REAL']['triple'] += len(true_objs)
for true_obj in true_objs:
if true_obj in pred_ojbs:
df['TP']['triple'] += 1
df.loc['sub','p'] = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
df.loc['sub','r'] = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
df.loc['sub','f1'] = 2 * df['p']['sub'] * df['r']['sub'] / (df['p']['sub'] + df['r']['sub'] + 1e-9)
sub_precision = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
sub_recall = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
sub_f1 = 2 * sub_precision * sub_recall / (sub_precision + sub_recall + 1e-9)
df.loc['triple','p'] = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
df.loc['triple','r'] = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
df.loc['triple','f1'] = 2 * df['p']['triple'] * df['r']['triple'] / (
df['p']['triple'] + df['r']['triple'] + 1e-9)
triple_precision = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
triple_recall = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
triple_f1 = 2 * triple_precision * triple_recall / (
triple_precision + triple_recall + 1e-9)
return sub_precision, sub_recall,sub_f1, triple_precision, triple_recall, triple_f1, df
def extract_sub(pred_sub_heads, pred_sub_tails):
subs = []
heads = torch.arange(0, len(pred_sub_heads))[pred_sub_heads == 1]
tails = torch.arange(0, len(pred_sub_tails))[pred_sub_tails == 1]
for head, tail in zip(heads, tails):
if tail >= head:
subs.append((head.item(), tail.item()))
return subs
def extract_obj_and_rel(obj_heads, obj_tails):
obj_heads = obj_heads.T
obj_tails = obj_tails.T
rel_count = obj_heads.shape[0]
obj_and_rels = [] # [(rel_index,strart_index,end_index),(rel_index,strart_index,end_index)]
for rel_index in range(rel_count):
obj_head = obj_heads[rel_index]
obj_tail = obj_tails[rel_index]
objs = extract_sub(obj_head, obj_tail)
if objs:
for obj in objs:
start_index, end_index = obj
obj_and_rels.append((rel_index, start_index, end_index))
return obj_and_rels
def convert_score_to_zero_one(tensor):
tensor[tensor>=0.5] = 1
tensor[tensor<0.5] = 0
return tensor2-9 定义main函数,开始训练
if __name__ == '__main__':
config = Config()
model, optimizer, sheduler, device = load_model(config)
train_iter, dev_iter, test_iter = create_data_iter(config)
batch = Batch(config)
train(model, train_iter, dev_iter, optimizer, config,batch)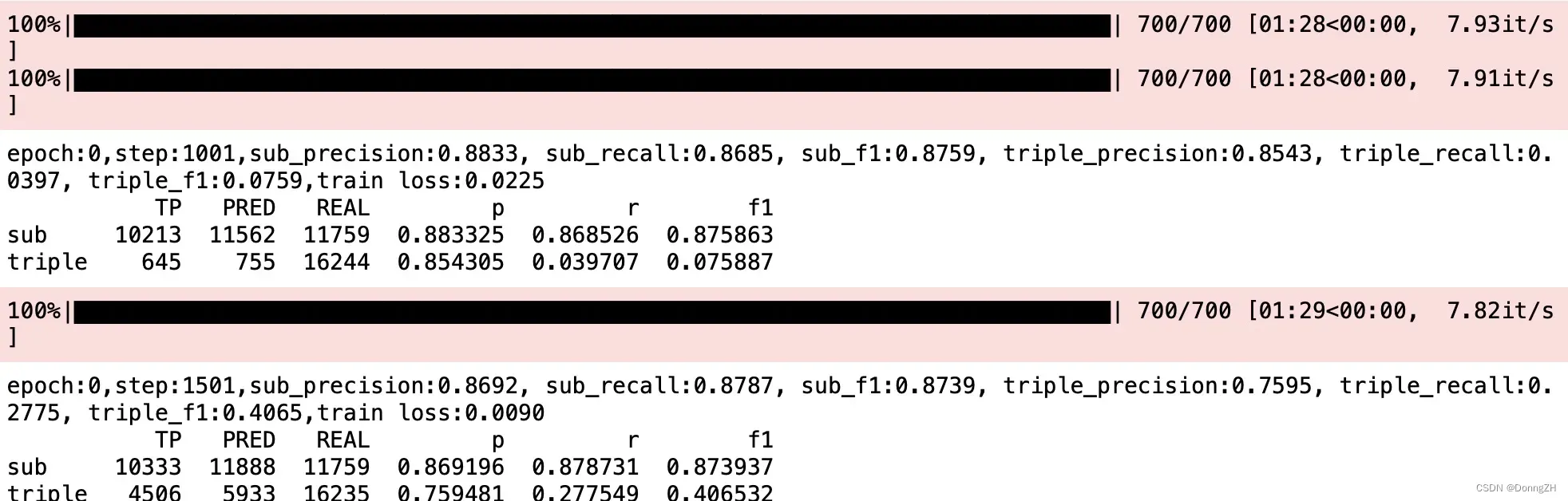
2-10 加载模型、测试
如果是需要部署服务,加载模型进行测试,那就需要将模型的类写到文件中。
model_dict=torch.load('/home/zhenhengdong/WORk/Relation_Extraction/Jupyter_files/Codes/best_f1.pth')
sub_precision, sub_recall,sub_f1, triple_precision, triple_recall, triple_f1, df = test(model_dict, test_iter, batch)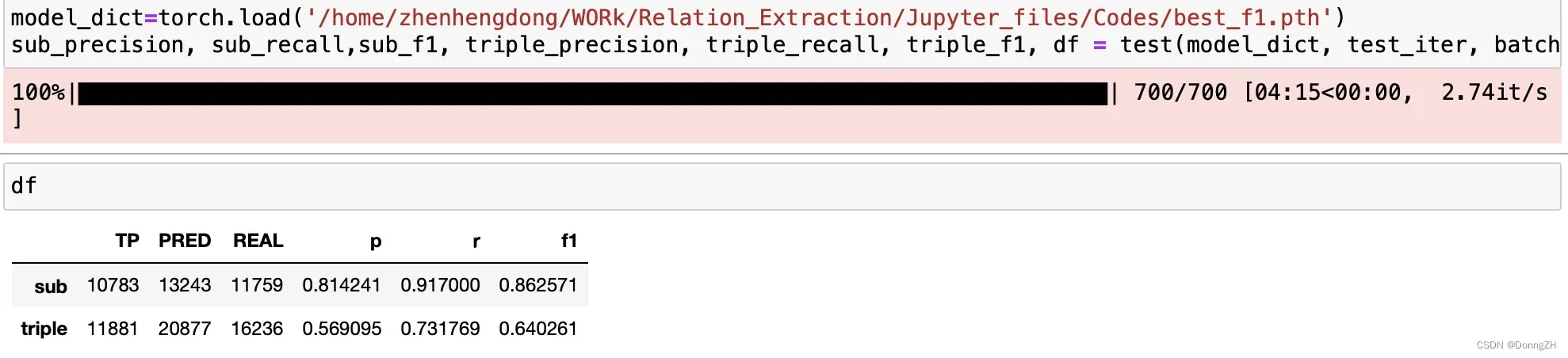
后记
reference :CasRel 关系抽取 | Kaggle
文章出处登录后可见!