
作者|BBuf、谢子鹏、冯文
2017 年,Google 提出了 Transformer 架构,随后 BERT 、GPT、T5等预训练模型不断涌现,并在各项任务中都不断刷新 SOTA 纪录。去年,清华提出了 GLM 模型(https://github.com/THUDM/GLM),不同于上述预训练模型架构,它采用了一种自回归的空白填充方法, 在 NLP 领域三种主要的任务(自然语言理解、无条件生成、有条件生成)上都取得了不错的结果。
很快,清华基于 GLM 架构又推出了 GLM-130B(https://keg.cs.tsinghua.edu.cn/glm-130b/zh/posts/glm-130b/),这是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿参数,在语言理解、语言建模、翻译、Zero-Shot 等方面都更加出色。
预训练模型的背后离不开开源深度学习框架的助力。在此之前,GLM 的开源代码主要是由 PyTorch、DeepSpeed 以及 Apex 来实现,并且基于 DeepSpeed 提供的数据并行和模型并行技术训练了 GLM-Large(335M),GLM-515M(515M),GLM-10B(10B)等大模型,这在一定程度上降低了 GLM 预训练模型的使用门槛。
即便如此,对更广大范围的普通用户来说,训练 GLM 这样的模型依然令人头秃,同时,预训练模型的性能优化还有更大的提升空间。
为此,我们近期将原始的 GLM 项目移植到了使用 OneFlow 后端进行训练的 One-GLM 项目。得益于 OneFlow 和 PyTorch 无缝兼容性,我们快速且平滑地移植了 GLM,并成功跑通了预训练任务(训练 GLM-large)。
此外,由于 OneFlow 原生支持 DeepSpeed 和 Apex 的很多功能和优化技术,用户不再需要这些插件就可训练 GLM 等大模型。更重要的是,针对当前 OneFlow 移植的 GLM 模型,在简单调优后就能在性能以及显存占用上有大幅提升。
具体是怎么做到的?下文将进行揭晓。
-
One-GLM:https://github.com/Oneflow-Inc/one-glm
-
OneFlow:https://github.com/Oneflow-Inc/oneflow
1
GLM-large 训练性能和显存的表现
首先先展示一下分别使用官方的 GLM 仓库以及 One-GLM 仓库训练 GLM-large 网络的性能和显存表现(数据并行技术),硬件环境为 A100 PCIE 40G,BatchSize 设置为 8。
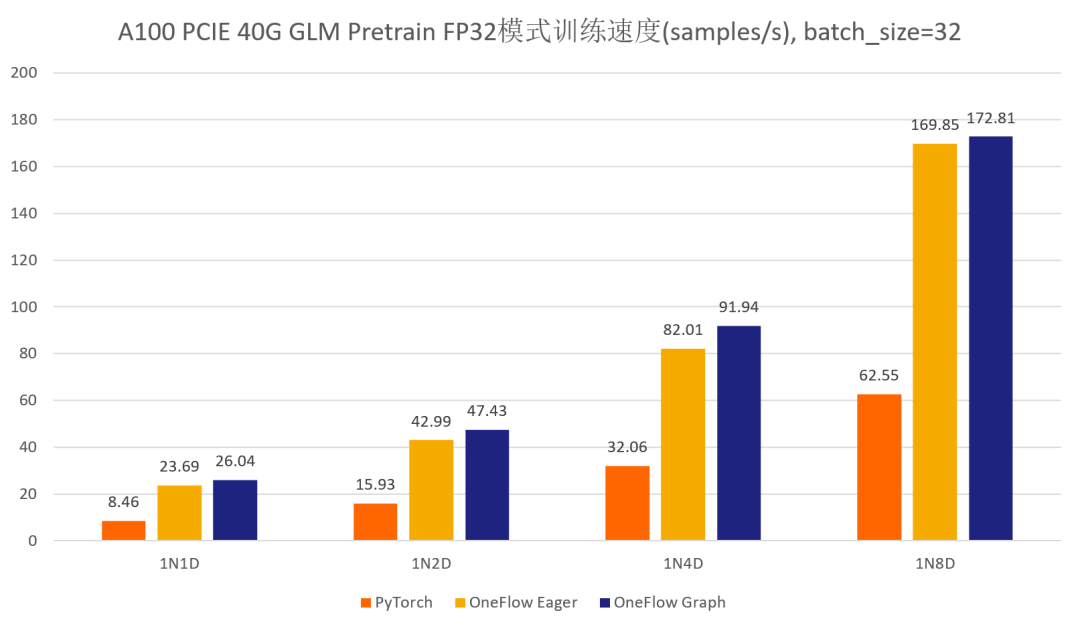
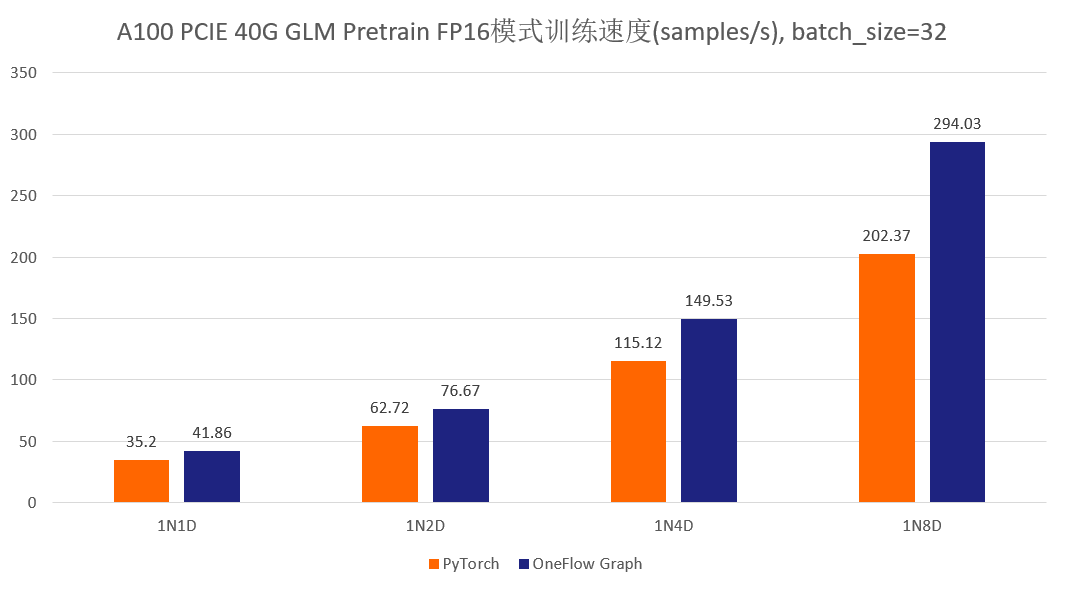
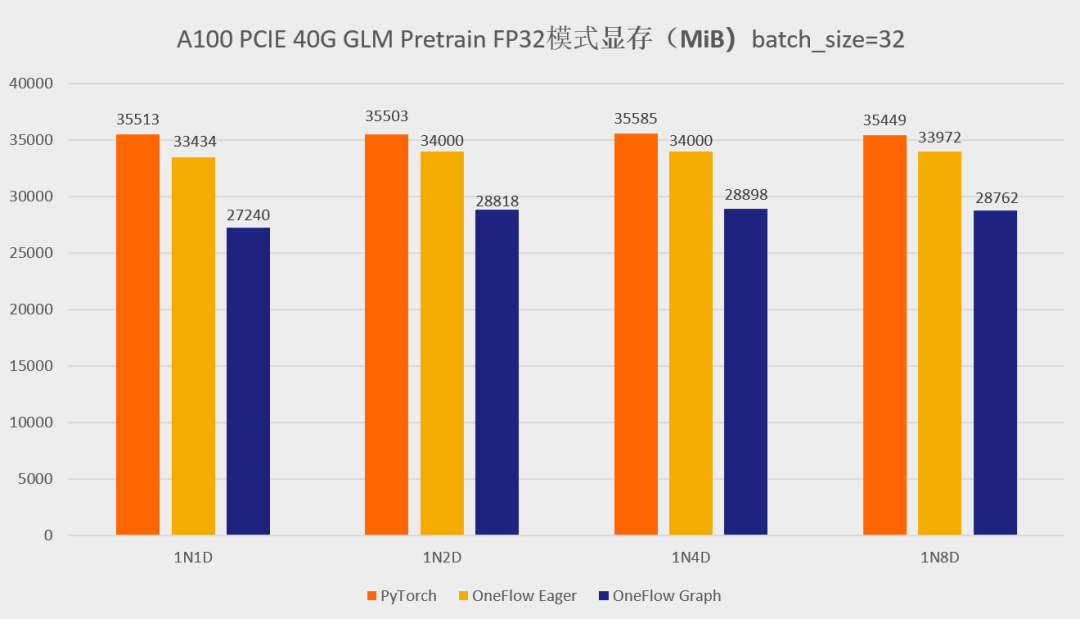
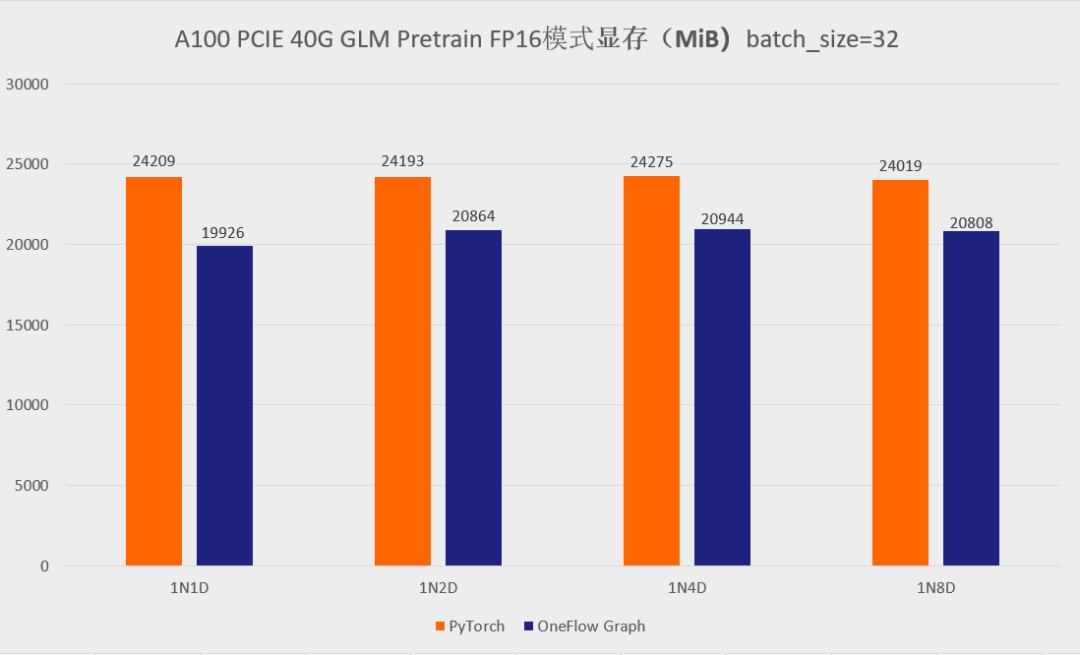
可以看到,在 GLM-large 的训练任务中,相比原始的基于 PyTorch、DeepSpeed、Apex 的 GLM 实现,OneFlow的性能有 120% – 276% 的加速,并且显存占用降低了10% -30%(测试结果均可用 oneflow >=0.9.0 复现)。
2
GLM 迁移,只需修改几行代码
由于 OneFlow 无缝兼容了 PyTorch 的生态,只需改动几行代码,就可以让用户轻松迁移 GLM 大模型到 One-GLM:
-
将 import torch 替换为 import oneflow as torch
-
将 import torch.xx 替换为 import oneflow.xx
-
将 from apex.optimizers import FusedAdam as Adam 替换为 from oneflow.optim import Adam
-
将 from apex.normalization.fused_layer_norm import FusedLayerNorm as LayerNorm 替换为 from oneflow.nn import LayerNorm
-
注释掉 torch.distributed.ReduceOp,torch.distributed.new_group,,torch.distributed.TCPStore,torch.distributed.all_reduce 这些API,它们是 PyTorch DDP 所需要的,但 OneFlow 的数据并行是由内部的 SBP 和 Global Tensor 机制实现,并不需要这些 API。
其它许多模型的迁移更简单,比如在和 torchvision 对标的 flowvision 中,许多模型只需通过在 torchvision 模型文件中加入 import oneflow as torch 即可得到,让用户几乎没有额外成本。
此外,OneFlow 还提供全局 “mock torch” 功能(https://docs.oneflow.org/master/cookies/oneflow_torch.html),在命令行运行 eval $(oneflow-mock-torch) 就可以让接下来运行的所有 Python 脚本里的 import torch 都自动指向 oneflow。
3
两大调优手段
loss 计算部分的优化
在原始的 GLM 实现中,loss计算部分使用到了 mpu.vocab_parallel_cross_entropy 这个函数 (https://github.com/THUDM/GLM/blob/main/pretrain_glm.py#L263) 。
通过分析这个函数,发现它实现了 sparse_softmax_cross_entropy 的功能,但在实现过程中,原始的 GLM 仓库使用了 PyTorch 的 autograd.Function 模块,并且使用了大量的小算子来拼接出 sparse_softmax_cross_entropy 整体的功能。而在 OneFlow 的算子库中,已经有 sparse_softmax_cross_entropy 这个算子对应的 CUDA 实现了,也就是 flow.sparse_softmax_cross_entropy 这个 API。
所以,我们将 GLM 对 sparse_softmax_cross_entropy 的 naive 实现替换为 flow.sparse_softmax_cross_entropy 这个 API,并进行了 loss 对齐实验。
结果如何?下图展示了基于 OneFlow 的 Graph 模式训练 GLM-large 模型前 1000 轮的 loss 对齐情况,并分别测试了 FP32 和 AMP 模式:
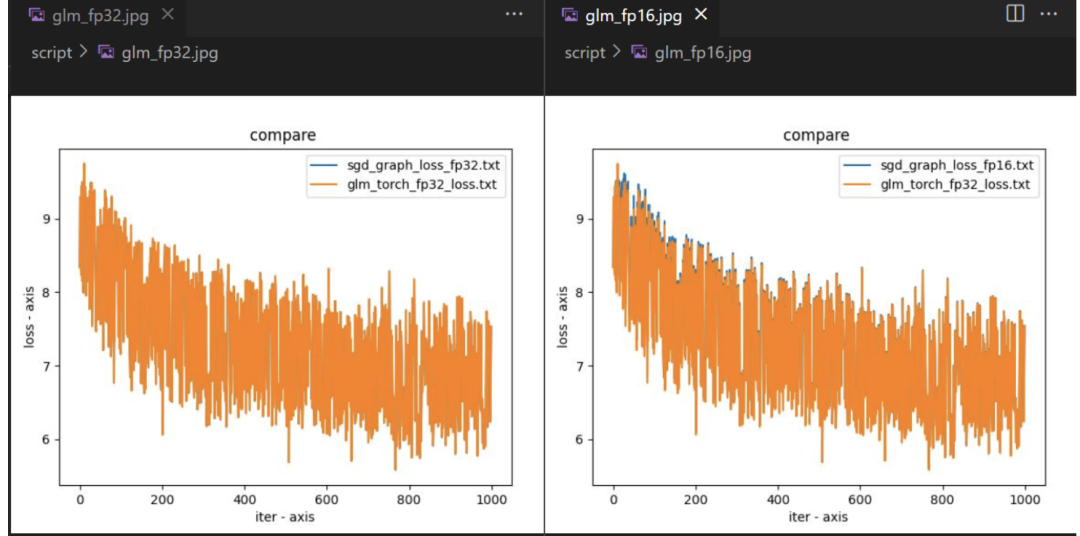
可以看到,将原始 GLM 的 naive sparse_softmax_cross_entropy 实现替换为 flow.sparse_softmax_cross_entropy 之后 loss 是完全对齐的,可以保证正确性。
相比原始的 GLM 的单卡性能,这个替换使得 One-GLM 的单卡性能有大幅提升,主要原因是 OneFlow 对 sparse_softmax_cross_entropy 算子做了极致的性能优化,并且减少了原始 GLM 中大量的碎算子拼凑带来的访存开销。此外,这样做也降低了 torch.autograd.Function 本身带来的一些系统开销。
CUDA Kernel Fuse
除上述优化外,GLM 模型本质上就是一个编解码的 Transformer 架构,所以我们将之前优化 GPT、BERT 的一些 Fuse Pattern 也带给了 One-GLM 模型。具体包含以下两个 Fuse Pattern :
-
fused_bias_add_gelu: 将 bias_add 和 gelu 算子融合在一起。
-
fused_bias_add_dropout:将 bias_add 和 dropout 算子融合在一起。
这两个 fuse 都可以显著改善计算的访存,并减少 Kernel Launch 带来的开销,由于 GLM 模型越大则层数就会越多,那么这种 Fuse Pattern 带来的的优势也会不断放大。
最终,在上述两方面的优化作用下,在 A100 PCIE 40G,batch_size = 8 环境中的训练 GLM-large 的任务时,单卡 FP32 模式的性能相比原始的 GLM 取得了 280%(FP32 模式) 和 307%( AMP 模式) 的训练加速。
4
LiBai 也能轻松搞定 GLM 推理
当模型规模过于庞大,单个 GPU 设备无法容纳大规模模型参数时,便捷好用的分布式训练和推理需求就相继出现,业内也随之推出相应的工具。
基于 OneFlow 构建的 LiBai 模型库让分布式上手难度降到最低,用户不需要关注模型如何分配在不同的显卡设备,只需要修改几个配置数据就可以设置不同的分布式策略。当然,加速性能更是出众。
-
LiBai :https://github.com/Oneflow-Inc/libai
-
LiBai 相关介绍:大模型训练之难,难于上青天?预训练易用、效率超群的「李白」模型库来了!
-
GLM:https://github.com/Oneflow-Inc/libai/tree/glm_project/projects/GLM
用 LiBai 搭建的 GLM 可以便捷地实现model parallel + pipeline parallel推理, 很好地解决单卡放不下大规模模型的问题。
那么,用户如何利用大规模模型训练与推理仓库 LiBai 来构建 GLM 的分布式推理部分?下面用一个小例子解释一下。
分布式推理具有天然优势
要知道,模型的参数其实就是许多 tensor,也就是以矩阵的形式出现,大模型的参数也就是大矩阵,并行策略就是把大矩阵分为多个小矩阵,并分配到不同的显卡或不同的设备上,基础的 LinearLayer 在LiBai中的实现代码如下:
class Linear1D(nn.Module):
def __init__(self, in_features, out_features, parallel="data", layer_idx=0, ...):
super().__init__()
if parallel == "col":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(0)])
elif parallel == "row":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.split(1)])
elif parallel == "data":
weight_sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])
else:
raise KeyError(f"{parallel} is not supported! Only support ('data', 'row' and 'col')")
self.weight = flow.nn.Parameter(
flow.empty(
(out_features, in_features),
dtype=flow.float32,
placement=dist.get_layer_placement(layer_idx), # for pipeline parallelism placement
sbp=weight_sbp,
)
)
init_method(self.weight)
...
def forward(self, x):
...在这里,用户可选择去如何切分 Linear 层的矩阵,如何切分数据矩阵,而OneFlow 中的 SBP 控制竖着切、横着切以及其他拆分矩阵的方案(模型并行、数据并行),以及通过设置 Placement 来控制这个 LinearLayer 是放在第几张显卡上(流水并行)。
所以,根据 LiBai 中各种 layer 的设计原理以及基于 OneFlow 中 tensor 自带的 SBP 和 Placement 属性的天然优势,使得用户搭建的模型能够很简单地就实现数据并行、模型并行以及流水并行操作。
GLM 推理的 Demo 演示
这里为用户展示 LiBai 中 GLM 的单卡和便捷的多卡推理 Demo,模型可在 HuggingFace 上获取:https://huggingface.co/models?filter=glm
-
单卡 generate 任务,我们选择 glm-10b 模型:
python demo.py# demo.py
import oneflow as flow
from projects.GLM.tokenizer.glm_tokenizer import GLMGPT2Tokenizer
from libai.utils import distributed as dist
from projects.GLM.configs.glm_inference import cfg
from projects.GLM.modeling_glm import GLMForConditionalGeneration
from projects.GLM.utils.glm_loader import GLMLoaderHuggerFace
from omegaconf import DictConfig
tokenizer = GLMGPT2Tokenizer.from_pretrained("/data/home/glm-10b")
input_ids = tokenizer.encode(
[
"Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai."
],
return_tensors="of",
)
inputs = {"input_ids": input_ids, "attention_mask": flow.ones(input_ids.size())}
inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=512)
sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])
placement = dist.get_layer_placement(0)
dist.set_device_type("cpu")
loader = GLMLoaderHuggerFace(GLMForConditionalGeneration, cfg, "/path/to/glm-10b")
model = loader.load()
model = model.half().cuda()
dist.set_device_type("cuda")
outputs = model.generate(
inputs=inputs['input_ids'].to_global(sbp=sbp, placement=placement),
position_ids=inputs['position_ids'].to_global(sbp=sbp, placement=placement),
generation_attention_mask=inputs['generation_attention_mask'].to_global(sbp=sbp, placement=placement).half(),
max_length=512
)
res = tokenizer.decode(outputs[0])
print(res)
>>> [CLS] Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.<|endoftext|> <|startofpiece|> Stanford University and a co-founder of <|endofpiece|>-
4卡 model parallel+pipeline parallel generate 任务,选择 glm-10b 模型:
python3 -m oneflow.distributed.launch --nproc_per_node 4 demo.py# demo.py
import oneflow as flow
from projects.GLM.tokenizer.glm_tokenizer import GLMGPT2Tokenizer
from libai.utils import distributed as dist
from projects.GLM.configs.glm_inference import cfg
from projects.GLM.modeling_glm import GLMForConditionalGeneration
from projects.GLM.utils.glm_loader import GLMLoaderHuggerFace
from omegaconf import DictConfig
# 只需简单配置并行方案
parallel_config = DictConfig(
dict(
data_parallel_size=1,
tensor_parallel_size=2,
pipeline_parallel_size=2,
pipeline_num_layers=2 * 24
)
)
dist.setup_dist_util(parallel_config)
tokenizer = GLMGPT2Tokenizer.from_pretrained("/data/home/glm-10b")
input_ids = tokenizer.encode(
[
"Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai."
],
return_tensors="of",
)
inputs = {"input_ids": input_ids, "attention_mask": flow.ones(input_ids.size())}
inputs = tokenizer.build_inputs_for_generation(inputs, max_gen_length=512)
sbp = dist.get_nd_sbp([flow.sbp.broadcast, flow.sbp.broadcast])
placement = dist.get_layer_placement(0)
loader = GLMLoaderHuggerFace(GLMForConditionalGeneration, cfg, "/path/to/glm-10b")
model = loader.load()
outputs = model.generate(
inputs=inputs['input_ids'].to_global(sbp=sbp, placement=placement),
position_ids=inputs['position_ids'].to_global(sbp=sbp, placement=placement),
generation_attention_mask=inputs['generation_attention_mask'].to_global(sbp=sbp, placement=placement),
max_length=512
)
res = tokenizer.decode(outputs[0])
if dist.is_main_process():
print(res)
>>> [CLS] Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.<|endoftext|> <|startofpiece|> Stanford University and a co-founder of <|endofpiece|>-
使用 One- GLM 训练的模型进行推理
LiBai对于OneFlow的模型加载同样方便,如果你希望使用one-glm训练后的模型进行推理,只需简单的将上述demo中的 GLMLoaderHuggerFace 替换为 GLMLoaderLiBai。
5
结语
基于 OneFlow 来移植 GLM 大模型非常简单,相比于原始版本 PyTorch GLM 训练 GLM-large 模型,OneFlow 能大幅提升性能和节省显存。
此外,通过使用 GLM-10B 这个百亿级大模型做推理,表明基于 OneFlow 的 LiBai 来做大模型推理可以开箱即用,并实现更高的推理速度,如果你想配置不同的并行方式来推理大模型,只需要简单配置文件的几个参数即可。
未来,OneFlow团队将探索使用 OneFlow 训练更大的 GLM-130B 千亿模型的可行性,相信基于 OneFlow 可以更快地训练 GLM-130B 千亿级别模型,加速国产大模型训练和推理任务。
欢迎Star、试用One-GLM:
-
One-GLM:https://github.com/Oneflow-Inc/one-glm
-
OneFlow:https://github.com/Oneflow-Inc/oneflow
其他人都在看
点击“阅读原文”,欢迎Star、试用OneFlow最新版本:https://github.com/Oneflow-Inc/oneflow/ https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
文章出处登录后可见!