当我们在谈论 Pytorch checkpoint 时,我们可能在说两件不同的事情。
第一个是 General checkpoint,用它保存模型的参数、优化器的参数,以及 Epoch, loss 等任何你想要保存的东西。我们可以利用它进行断点续训,以及后续的模型推理。长时间训练大模型时,在代码中定期保存 checkpoint 也是一个好习惯。
第二个是 Gradient checkpoint,这是一种以时间换空间的技术:用更长的计算时间,换取显卡内存。
我们分别来看一下这两件完全不同的事情。
General checkpoint
When saving a general checkpoint, you must save more than just the model’s state_dict. It is important to also save the optimizer’s state_dict, as this contains buffers and parameters that are updated as the model trains. ——SAVING AND LOADING A GENERAL CHECKPOINT IN PYTORCH
在保存检查点的时候,如果你确定模型已经训练完毕,之后加载模型时只会用它做推理,那么你可以不保存优化器的参数。
但如果之后会进行断点续训,那么优化器参数是必须要保存的。像 Adam 这种优化器,更新参数时会用到历史梯度,必须将它们保存下来。
为了保险起见,一般的建议是:save both the model’s and optimizer’s state_dict
保存模型:
torch.save({
'epoch': EPOCH,
'model_state_dict': net.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': LOSS,
}, "./model.pt")
加载模型:
model = Net()
# optimizer should be the same as before
optimizer = optim.SGD(net.parameters())
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
Gradient checkpoint
前面提到,Gradient checkpoint 是一种节省显存的机制。首先的一个问题是,PyTorch 模型在训练过程中,显存存储的是什么?
PyTorch显存机制分析 这篇文章中说:
PyTorch 在进行深度学习训练的时候,有4大部分的显存开销,分别是模型参数 (parameters),模型参数的梯度 (gradients),优化器状态 (optimizer states) 以及中间激活值 (intermediate activations) 或者叫中间结果 (intermediate results)
前向传播中,中间激活值被保存下来;反向传播中,这些中间激活值被用来计算梯度,在计算完成后被销毁(释放)。
Gradient checkpoint 的思路是,在前向传播过程中不保存中间激活值;在反向传播要用到的时候再重新计算。这样当然节省了显存,但中间值被计算了两遍。
Pytorch 提供了两种使用梯度检查点的方式:torch.utils.checkpoint.checkpoint_sequential 以及 torch.utils.checkpoint.checkpoint
checkpoint_sequential
checkpoint_sequential 适用于前向传播逻辑简单的序列模型,即按照顺序执行列表中的 modules/functions。对于这种模型,可以把它分割成 N 个小块,对每一个小块做梯度检查。
import torch.nn as nn
from torch.utils.checkpoint import checkpoint_sequential
chunks = 3
model = nn.Sequential(...)
input_var = checkpoint_sequential(functions=model, segments=chunks, input=input_var, preserve_rng_state=True)
上面这段代码,把 sequential model 分成了三个小块。除了最后一个小块,其余两个小块(segment 1, segment 2)均以 torch.no_grad() 的方式进行,也就不需要保存中间激活值了。segment 1, segment 2 的输入会被保存,以便反向传播时重新计算它们的中间值。
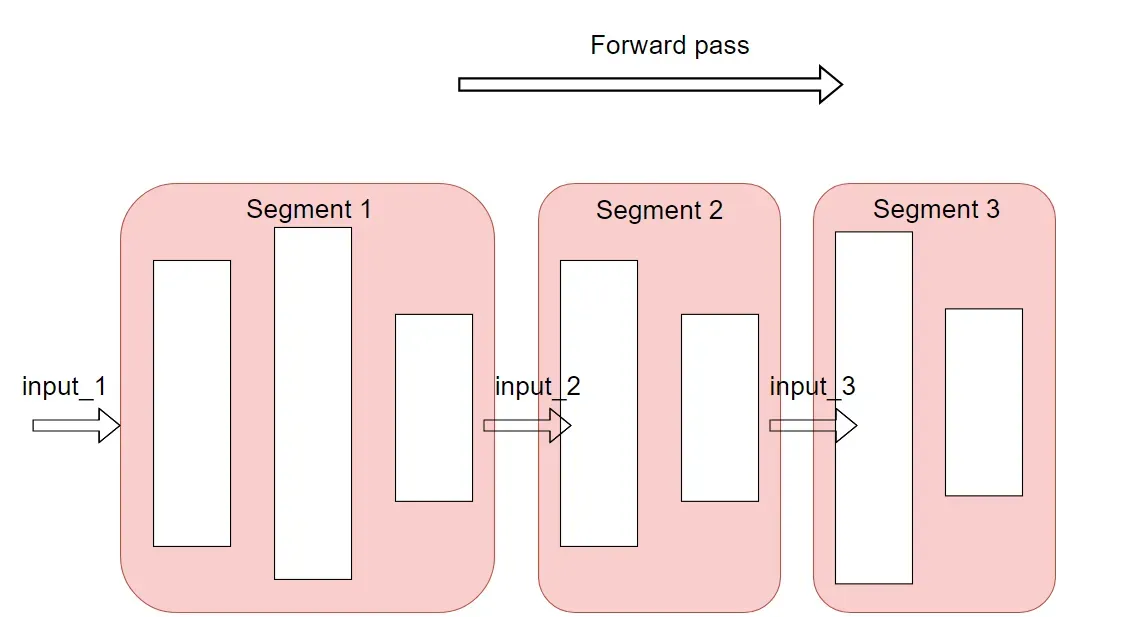
checkpoint
对于更复杂的模型结构,需要用 checkpoint
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.cnn_block_1 = nn.Sequential(*[
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.25)
])
self.cnn_block_2 = nn.Sequential(*[
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.25)
])
self.flatten = lambda inp: torch.flatten(inp, 1)
self.head = nn.Sequential(*[
nn.Linear(64 * 8 * 8, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 10)
])
def forward(self, X):
X = self.cnn_block_1(X)
X = self.dropout_1(X)
X = torch.utils.checkpoint.checkpoint(self.cnn_block_2, X)
X = self.dropout_2(X)
X = self.flatten(X)
X = self.head(X)
return X
我们对 cnn_block_2 设置了梯度检查——只需要给出 block of module,以及它的输入。有两点需要注意:
-
Use of torch.utils.checkpoint.checkpoint causes simple model to diverge 这篇讨论里提到,为什么不对
cnn_block_1设置梯度检查:
cnn_block_1的输入是原始输入,它的requires_grad=False,因为我们只需要对模型权重求梯度,不需要对原始输入求梯度。而被梯度检查的模块的输出的requires_grad与输入的requires_grad保持一致。在cnn_block_1中,它的输出requires_grad=False,导致模块的权重不会更新。因此这位作者建议,不要在紧跟着原始输入的模块上设置梯度检查。 -
另一个需要注意的点是,我们可以对包含
Dropout layer的模块设置梯度检查,但要注意preserve_rng_state这个参数。Dropout layer需要进行随机采样,随机数生成器的状态会随之改变。由于梯度检查需要进行两次前向传播,如果两次的随机数生成器的状态不一样,就会产生不同的结果。
preserve_rng_state=True(默认),意味着程序会保存前一次随机数生成器的状态,在第二次前向传播时,保证Dropout layer的结果与第一次相同。
官方文档对梯度检查中随机状态的解释:
Checkpointing is implemented by rerunning a forward-pass segment for each checkpointed segment during backward. This can cause persistent states like the RNG state to be advanced than they would without checkpointing. By default, checkpointing includes logic to juggle the RNG state such that checkpointed passes making use of RNG (through dropout for example) have deterministic output as compared to non-checkpointed passes. The logic to stash and restore RNG states can incur a moderate performance hit depending on the runtime of checkpointed operations.
设置 preserve_rng_state=True 会对性能造成一定程度的影响。
定点设置 General checkpoint 保存参数是一个好习惯;
Gradient checkpoint(梯度检查)是一项有用的技术,但需要在实战中练习。它可能会引起意想不到的 Bug,需要多加注意。
参考:
- TORCH.UTILS.CHECKPOINT
- Use of torch.utils.checkpoint.checkpoint causes simple model to diverge
- PyTorch 显存机制分析
文章出处登录后可见!