异常检测
一、基本概念
从定义而言就是一种识别不正常情况与挖掘非逻辑数据的技术,也叫outliers。通俗的理解异常检测就是,有一堆数据,数据中有正常的数据也有异常的数据。异常检测就需要将数据中所有异常的数据检测出来。
1.1 三种异常检测的训练设定
1.Supervised: 训练数据集是有标注的,分为正常和异常。此训练方式默认了WDAD假设,认为标定的数据能够描摹出异常的分布。
2.Clean: 所有的训练集都是正常的,测试集中包含有正常和异常的,需要把异常点找出来。默认的是异常和正常的分布有较大的差别,所以能够通过分布的差异来判定。
3.Unsupervised:训练是混合正常和异常点的,没有标注的。其本质上就是聚类,认为异常就是outlier, 距离聚类中心较远的点。
(注:WDAD假设认为异常已经被一个充分定义的分布所描绘,也就是在充足的数据集下,我们应该能找到这个数据集的分布,并把这种异常给发现。)
1.2 较难识别的异常
对于异常值的比率 :
:
- 当异常点的比例大于5%时,适合使用二元混合模型。
- 使用这模型意味着服从了WDAD假设。
- 混合部分必须是可分离的
- 混合部分不能在高密度空间(HDR)有较大的重叠,否则无法区分
- 当异常点的较小,如1%、0.1%、0.01%等等,利用突变检测来检测异常
- 并不需要符合WDAD假设
- 当异常值不是突变或异常值时失败(当异常值和正态分布重叠或非常相似时)
- 当异常呈长尾分布时,说明异常类型多且不集中,很难很好地检测到。
1.6 ML做异常检测的方法
采用聚类Unsupervised的方法来做异常检测。主要是通过训练集映射到一个距离度量空间,寻找一个合适的阈值来区分开正常和异常。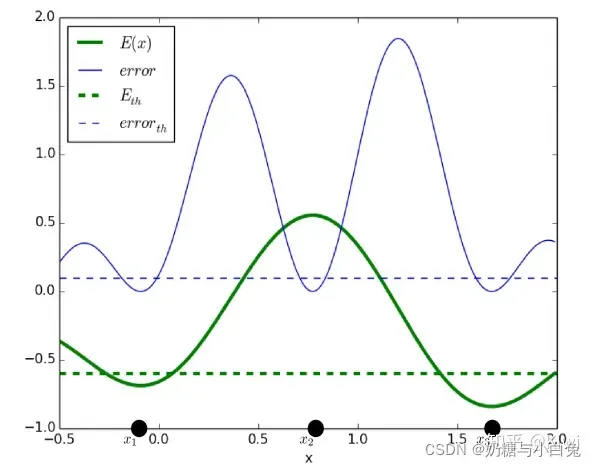
目前比较好的方法是周志华老师的Isolation Forest,通过对数据集进行不同维度上的切割,直到所有数据都划分开,或者数据划分到某一个程度。那么异常点总是能够轻易的被划分开来的,因为他们离群。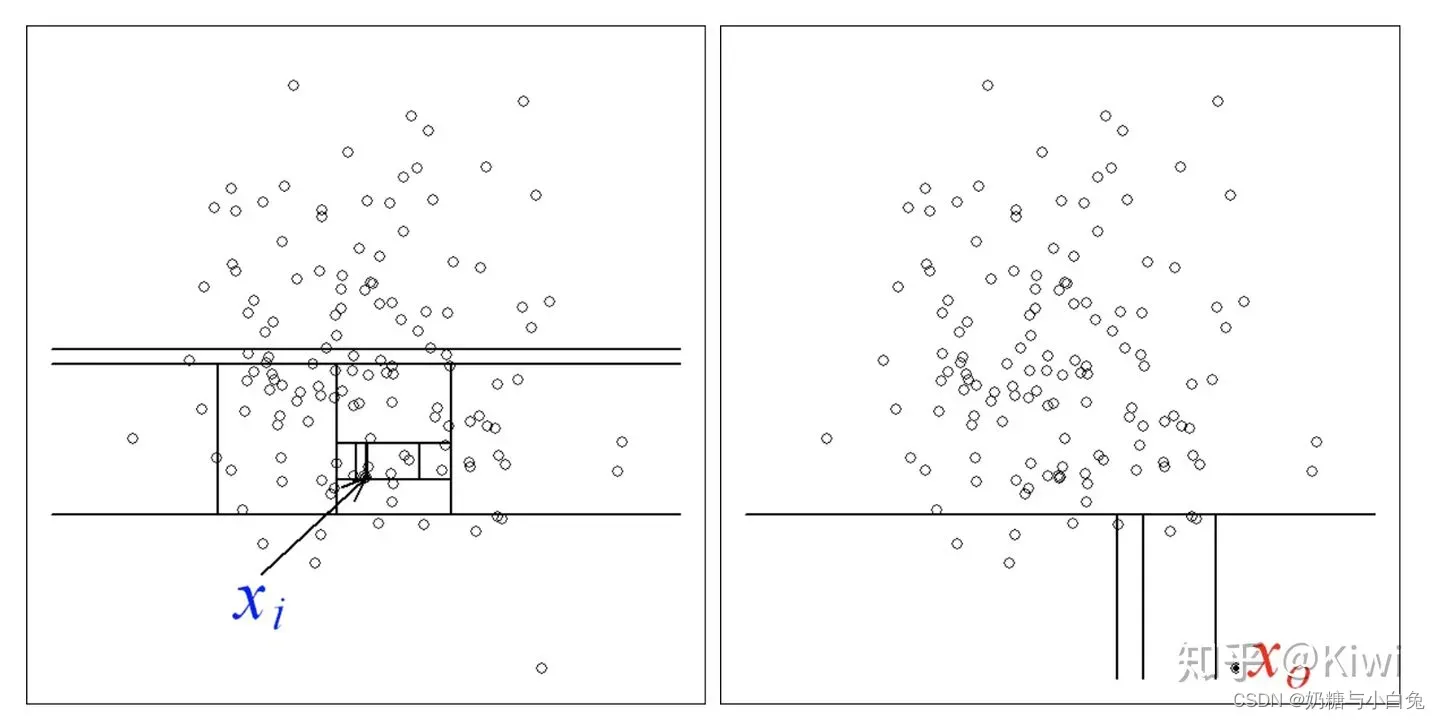
2.异常检测相关工作及方向
2.1 DAD研究的主要元素
(1)异常数据集
- 点集
举信用卡盗刷的例子,点集异常就是指单笔交易大金额支出,比如你都花1块2块的钱,突然有一天消费了1k,那可能就出现了异常情况。 - 连续集
连续集是指上下文相关的连续数据。某个中间数据出现异常情况,可能会导致梯度消失、爆炸等问题。 - 团队集
还是信用卡盗刷的例子,如果某天你的信用卡突然短时间内不停地消费50元,那机器可能会发现,这些团队数据集的消费出现了异常,这种情况我们也在其他场合经常遇到。
(2)异常检测模型
- 无监督学习、AutoEncoder、GAN、矩阵因子分解
- 半监督学习、强化学习
- Hybrid(混种)、特征提取+传统算法
- 单分类神经网络
(3) 异常检测应用 - 欺诈识别
- 网络入侵检测
- 医疗异常检测
- 传感器网络异常检测
- 视频监控
- 物联网大数据异常检测
- 日志异常检测
- 工业危害检测
2.2 异常检测论文分类
(1) 数据的连续性
(2) 数据标签的可用性
- 监督学习Supervised Learning
- 半监督学习Semi-supervised Learning
- 无监督学习Unsupervised Learning
(3) 基于训练对象的模型 - 深度混种模型Deep Hybrid Model(DHM)
- 单分类神经网络One-Class Neural Networks(OC-NN)
(4) 数据异常类型 - 点集Point
- 连续集Contextual
- 团队集Collective or Group
(5) 异常检测输出类型 - 异常分数Anomaly Score
- 标签Lable
(6) 异常检测应用
如何选择对应的型号?
| 原始数据类型 | 举例 | DAD模型选择 |
|---|---|---|
| 连续型Sequential | 视屏,DNA序列,自然语言文本 | CNN,RNN,LSTM |
| 非连续型Non-sequential | 图片,传感器 | CNN,AE及其变种 |
文章出处登录后可见!
已经登录?立即刷新