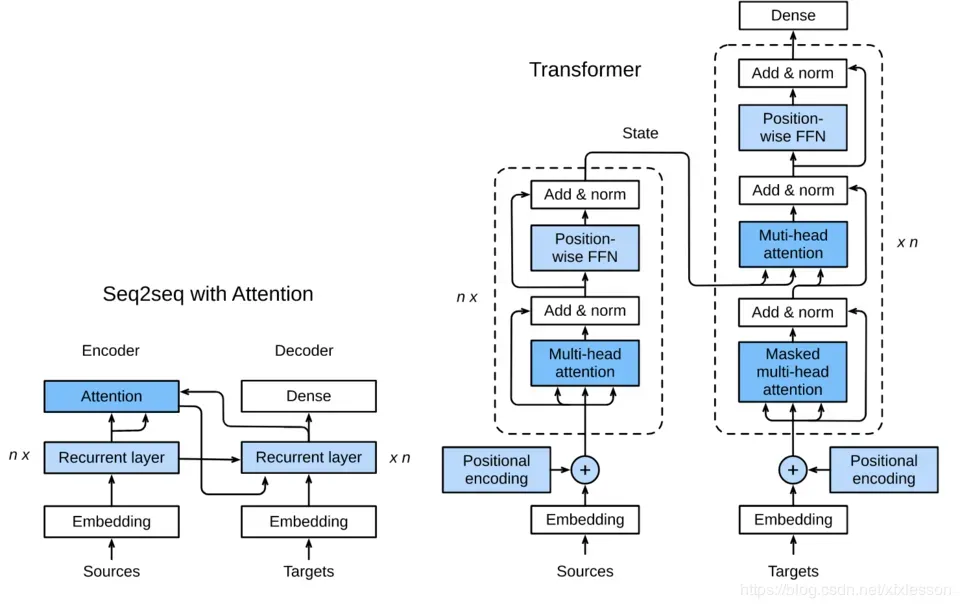
简单聊聊transformer里的mask ——转载自链接一
1.padding mask
在encoder和decoder两个模块里都有padding mask,位置是在softmax之前,为什么要使用padding mask,是因为由于encoder和decoder两个模块都会有各自相应的输入,但是输入的句子长度是不一样的,计算attention score会出现偏差,为了保证句子的长度一样所以需要进行填充,但是用0填充的位置的信息是完全没有意义的(多余的),经过softmax操作也会有对应的输出,会影响全局概率值,因此我们希望这个位置不参与后期的反向传播过程。以此避免最后影响模型自身的效果,既在训练时将补全的位置给Mask掉,也就是在这些位置上补一些无穷小(负无穷)的值,经过softmax操作,这些值就成了0,就不在影响全局概率的预测。
pytorch nn.Transformer的mask理解 – 知乎 (zhihu.com) //padding mask 讲得比较细
2.Sequence MASK
sequence MASK是只存在decoder的第一个mutil_head_self_attention里,为什么这样做?是因为在测试验证阶段,模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。因此我们要采取一个遮盖的方法(Mask)使得其在计算self-attention的时候只用i个时刻之前的token进行计算。
举例:“我爱中国共产党”,假如要预测“中”这个词,那么当前时刻的输入就是“我”以及“爱”的输入的叠加,一部分来自”我“的信息输出,一部分来自”爱”的信息输出,如果没有mask将后面的单词信息遮住,那么后面的单词对要预测的这个字“中”也会有相应的信息贡献,在训练的时候整个句子的前后字词的位置是已知的,所以不遮挡模型也是可以运行的,因为本身模型输入时就已经知道了句子的整个信息(也就是ground truth embeding)。 但是在进行模型预测(测试新的输入句子)时,输入的句子是未知的,随机的,模型不知道句子的信息,只能通过上一层的输出和原始的输入知道要预测字的前一个信息,进而依次预测后面的字的信息。这就造成了在训练时模型多训练了“中”后面的词,增加了训练时间,消耗了本没必要的空间及时间。在一开始训练时就mask掉,节省时间的同时也降低了过拟合的风险,提高了模型泛化能力。浅析Transformer训练时并行问题 – 知乎 (zhihu.com)
//Sequence mask 讲得比较细
【Pytorch】Transformer中的mask ——转载自链接三
- 由于Transformer的模型结构,在应用Transformer的时候需要添加mask来实现一些功能。
- 如Encdoer中需要输入定长序列而padding,可以加入mask剔除padding部分
- 如Decoder中为了实现并行而输入完整序列,需要加上mask剔除不应感知到的部分序列
- 在一些更灵活的应用中,有时候需要设计一些mask形式来调整可利用信息源的范围。因此,本文以官网Transformer做文本翻译为例***官网翻译示例,梳理一下Pytorch实现的Transformer是如何做mask操作的。(164条消息) Transformer的矩阵维度分析和Mask详解_我最怜君中宵舞的博客-CSDN博客_transformer中的mask//讲清楚了训练可以并行,推理和测试的时候不能并行的原因
简单层面讲了TransformerDecoder进行并行
(165条消息) Transformer decoder中masked attention的理解_寺里LZS的博客-CSDN博客
参考资料
简单聊聊transformer里的mask – 知乎 (zhihu.com)//大白话,讲的很好
(167条消息) Transformer 中的mask_Caleb_L的博客-CSDN博客_transformer中的mask
【Pytorch】Transformer中的mask – 知乎 (zhihu.com) //结合Pytorch代码解释,梳理一下Pytorch实现的Transformer是如何做mask操作的。
这个视频与这篇博客配套使用,讲的很清楚了
全网最详细Transformer中的mask操作及代码详解【推荐】【系列10-4-2】_哔哩哔哩_bilibili
transformer 中的 mask 操作-范仁义-读书编程笔记 (fanrenyi.com)//需要科学上网maybe
文章出处登录后可见!