聚类分析概述
聚类分析是一种无监督学习(无监督学习:机器学习中的一种学习方法,一种没有明确目的的训练方法,也不可能提前知道结果会是什么;数据不需要标签),使用对于未知类别。将样本按照一定的规则划分为若干个簇,相似(相关)的样本聚集在同一个簇中,不相似的样本划分为不同的簇,从而分析样本之间的内在关系。属性以及它们之间的关系。这是一个想法,而不是一种方法。
层次聚类
层次聚类是一种聚类算法,它通过计算不同类别的数据点之间的相似度来创建层次嵌套的聚类树。在聚类树中,不同类别的原始数据点是树的最底层,树的顶层是聚类的根节点。作为一个简单的例子,如图所示,这里的簇形成了一个简单的层次结构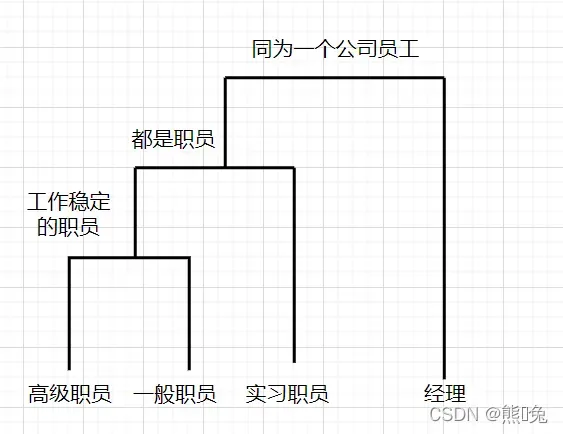
现在来看看下面的几个小球,我们现在对它进行划分,可以将其划分为2个簇,3个簇,甚至还可以将一个小球作为一个簇,即分为6个簇,那么问题来了,我们最后应该选择划分为几个簇才是最合适的呢?这也是聚类算法中最需要解决的问题。
在层次聚类中,我们通常通过计算相似度来将数据分成簇。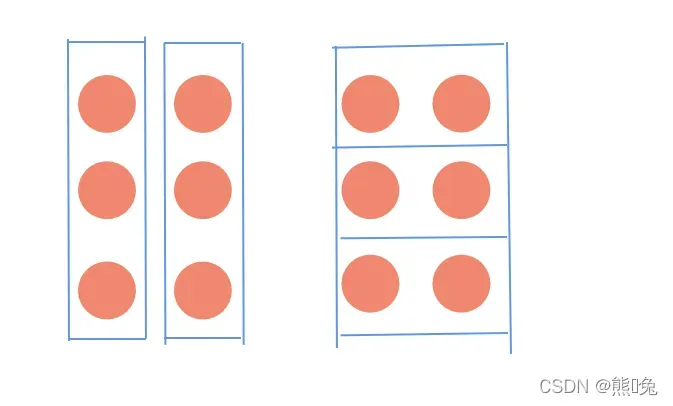
相似度的计算:层次聚类使用欧式距离来计算不同类型数据点间的距离,即相似度。(如图例所示,计算数据点之间的距离来进行分簇)欧式距离公式:D=sqrt((x1-y1)^2 + (x2-y2)^2)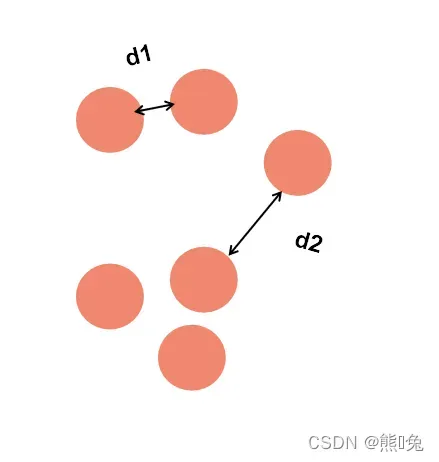
而层次聚类算法根据层次分解的顺序分为:自底向上和自顶向下,即凝聚的层次聚类算法(agglomerative)和分裂的层次聚类算法(pisive)。
Agglomerative Hierarchical Clustering Algorithm:一开始每个数据都是一个类,然后根据同一个类搜索,最后形成一个类。
划分层次聚类算法:首先,所有数据都属于一个类,然后根据排除不同,最后每个个体成为一个“类”。
自底向上合并算法:通过计算每个类别的数据点与所有数据点的距离来确定它们之间的相似度。距离越小,相似度越高。
如图表格中的数据为各个数据点之间的距离,会发现BD之间的距离是最小的,因此将BD进行合并后再计算BD与其他数据点之间的距离,然后再寻找距离最小的数据点进行合并,迭代进行以上操作。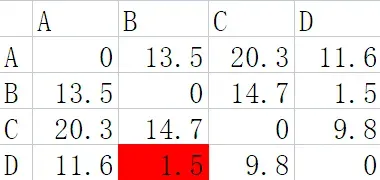
由此可以推导出凝聚层次聚类算法的过程:
1、将每一个对象看作一类,计算两两之间的最小距离;
2、 将距离最小的两个类合并成一个新类;
3、 再重新计算新类与所有类之间的距离;
4、重复以上操作,直到所有类最后合并成一类;
分层算法也有优缺点:
优势:
1、不需要预先制定聚类数;
2、可以发现类的层次关系;
3、可以聚类成其它形状;
缺点:
1、计算的复杂度较高;
2、奇异值也能产生很大影响;
K-Means算法
K-Means算法是基于划分的聚类算法,计算样本点与簇质心的距离,与簇质心相近的样本点划分为同一类簇。两个样本距离越远,则相似度越低。
基本概念:
1、要得到簇的个数,需要指定k值,例如k=3,则表示需要将数据分成3个簇;
2、质心,即为均值,向量的各个维度取平均,例如图中黑点便是红色数据点的质心(x轴数据取均值,y轴数据取均值)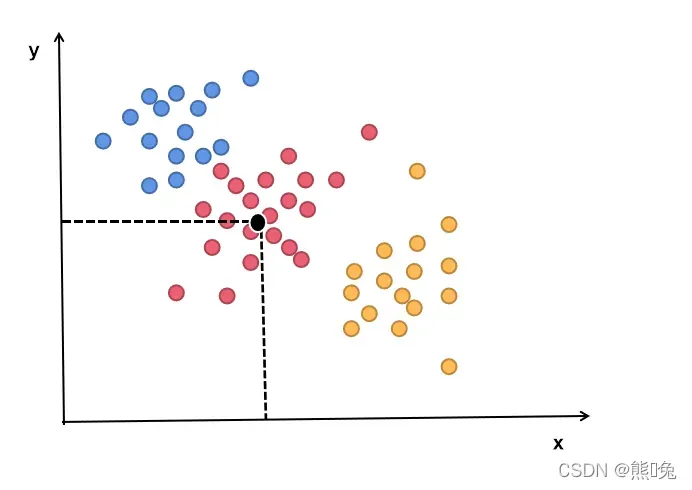
3、距离的度量:常用欧式距离和余弦相似度(数据需先标准化)
4、优化目标:机器学习算法中优化目标是必不可少的一步。这里优化的是各个数据点到中心点的距离,距离越小越好。

以下图示便是K-Means算法工作流程:这里假设k=2,随机初始化两个点,然后将数据点与这两个点分别两两进行距离计算,然后进行分类,如c图,接着进行质心的更新,得到红色的质心与蓝色的质心后,再继续计算两两之间的距离,最后得到图f,在这之后无论进行多少次质心的更新,数据的簇不会有很大变化了。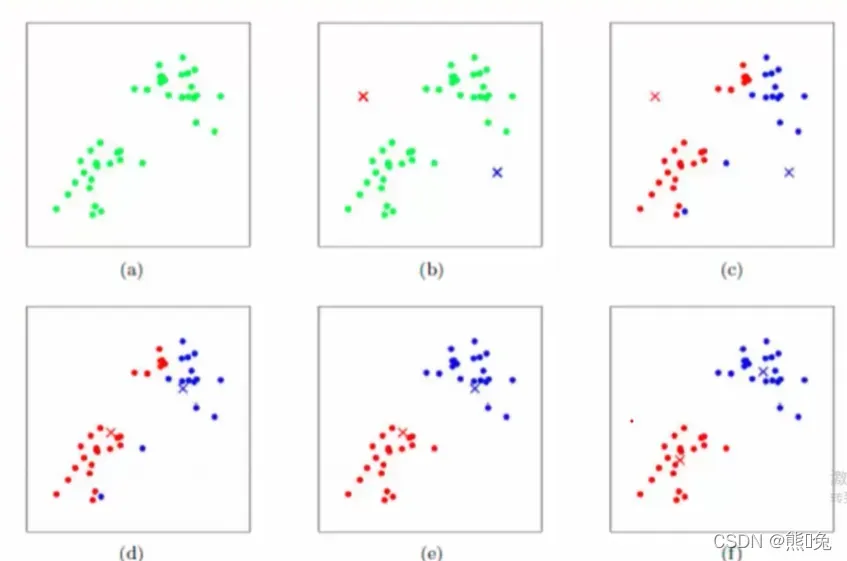
优势:
1、简单,适合常规数据集;
缺点:
1、k值难确定,因为这是一个无监督算法,数据没有标签分类;
2、若与数据集较大的,此方法的复杂度会很高,因为要不断的进行质心的更新;
DBSCAN算法
DBSCAN是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
基本概念:
1、核心对象:若某个点的密度达到算法设定的阈值,则其为核心点。即r领域内点的数量个数不小于minPS,假设一个阈值为3,现以某个点为中心的领域内点的数量为7,即认为这个点为核心对象;
2、距离阈值:设定的半径r;
(以上两个值需要自己指定,不需要指定簇数)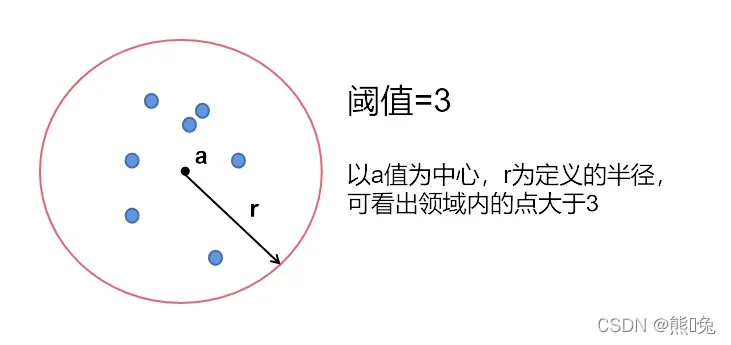
3、直接密度可达:若某点p在点q的r领域内,且q是核心点则p-q直接密度可达;
4、边界点:属于某个类的非核心点,不能发展下线了;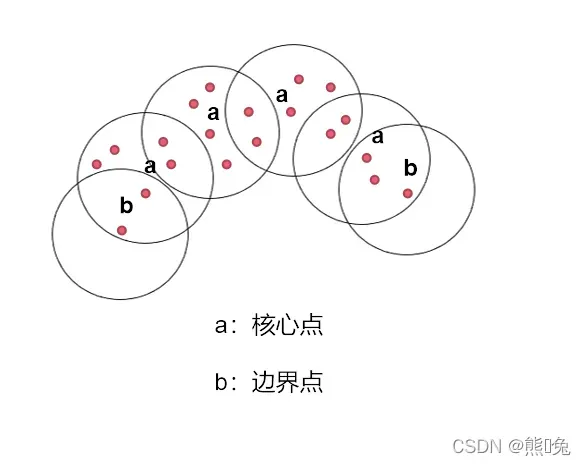
工作过程:
参数data:输入数据集
参数r:指定半径,可以根据k距离来设定,找突变点(k距离:给定数据集data中,计算点dataI(i)到集合D的子集S中所有点之间的距离,距离按照从小到大的顺序排序,d(k)被称为k距离。
MinPS:密度阈值
优势:
1、不需要指定簇的个数
2、可以发现任意形状的簇
3、只需要指定两个参数
缺点:
1、参数难以选择
2、高维的数据选择较困难
版权声明:本文为博主熊️兔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_52669357/article/details/123148526