torch.utils.data.Dataloader是PyTorch数据加载工具的核心类。在网络脚本中使用流程一般如下:
train_loader = torch.utils.data.Dataloader(...)
for input, target in train_loader:
# 前向计算
output = model(input)
# 计算损失
loss = loss_fn(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 梯度更新
optimizer.step()
从使用方式可以看出,Dataloder本质上是将数据抽象成可迭代的python对象使用,除此之外还支持:
- map风格和iterable风格的数据集
- 自定义数据加载顺序
- 自动批处理
- 单/多进程数据加载
- 自动内存页面锁定
上述功能选项在Dataloder构造参数中配置:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
下面分为几个章节分别探究Dataloder的代码结构和上述功能的具体实现。
一、Dataloader整体架构
根据上述Dataloader的使用方式来看,Dataloader应该是一个iterrable(可迭代对象),内部需要维护一个iterator(迭代器)。python中for循环访问可迭代对象的内部流程如下:
- 调用可迭代对象的__iter__方法,拿到迭代器对象
- 调用迭代器的__next__方法,遍历内部数据
- 循环步骤2,直到迭代器内部数据流访问完成,捕获异常
对应下图,for循环先通过Dataloader类的__iter__方法拿到迭代器,即_SingleProcessDataLoaderIter类或_MultiProcessDataLoaderIter类,之后每次循环都会调用迭代器的__next__方法获取input和target数据(具体如何获得数据后面会介绍),直到全部数据访问完退出for循环。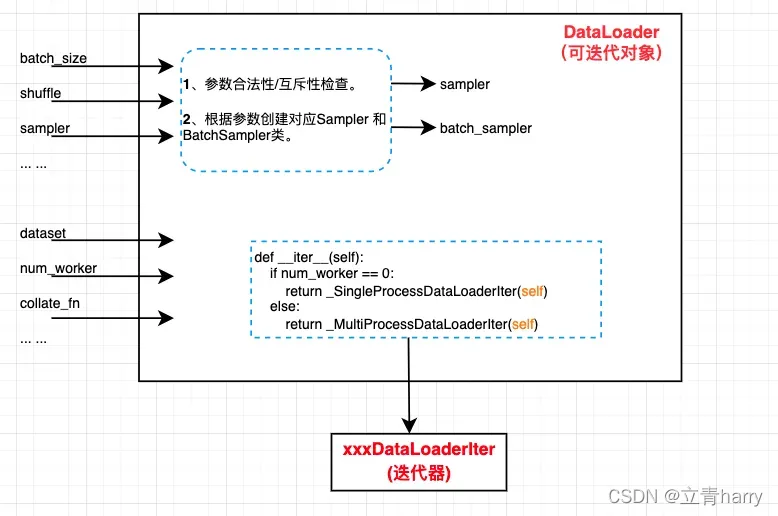
Dataloader类的工作比较简单,对用户参数做个检查,再创建出xxxDataLoaderIter迭代器需要的一些类(例如Sampler和BatchSampler)以及xxxDataLoaderIter迭代器,剩下对数据集的访问工作就全权委托xxxDataLoaderIter迭代器去做了。
在具体介绍xxxDataLoaderIter迭代器之前,先简单了解下其依赖的组件及大致工作流程。
xxxDataLoaderIter主要用到的组件有:
- Dataset类
- Sampler && BatchSampler类
- Fetcher类
- collate_fn函数
- pin_memory函数
每次for循环调用next(xxxDataLoaderIter),都由上述组件相互配合完成对具体数据的访问。大致流程如下: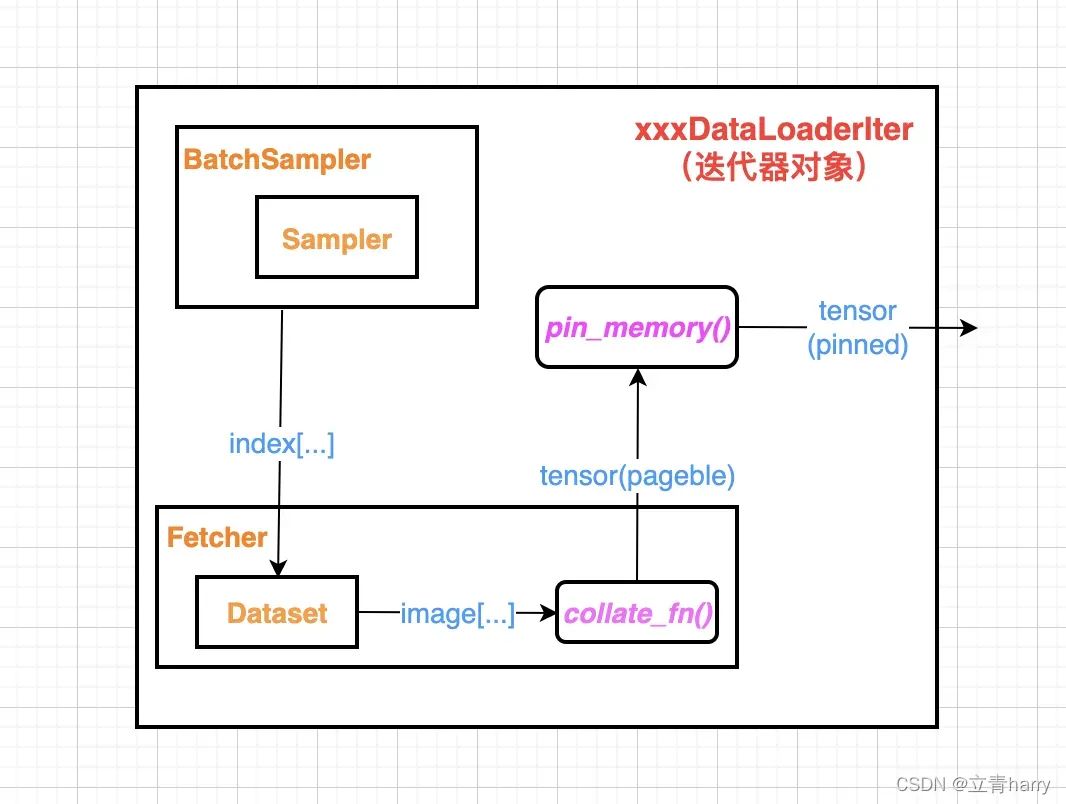
BatchSampler类每次产生一堆index下标,Fetcher类通过index下标将数据从Dataset类中取出来,然后通过collate_fn函数将取出来的数据整理成Tensor,如果开启了pin memory功能,还会将对应的pageble Tensor转换成pinned Tensor然后输出。
以上就是xxxDataLoaderIter迭代器的大致工作流程,至于每个组件的功能实现以及具体的_SingleProcessDataLoaderIter迭代器和_MultiProcessDataLoaderIter迭代器的工作原理,请看后续章节分析。
版权声明:本文为博主立青harry原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/u013608424/article/details/123172026