1 VITS2模型
1.1 摘要
单阶段文本到语音模型最近被积极研究,其结果优于两阶段管道系统。以往的单阶段模型虽然取得了较大的进展,但在间歇性非自然性、计算效率、对音素转换依赖性强等方面仍有改进的空间。本文提出VITS2,一种单阶段的文本到语音模型,通过改进之前工作的几个方面,有效地合成了更自然的语音。本文提出了改进的结构和训练机制,所提出的方法在提高多说话人模型中语音特征的自然度、相似性以及训练和推理效率方面是有效的。证明了所提出方法可以显著减少以前工作中对音素转换的强依赖,允许完全端到端单阶段方法。
论文地址:https://arxiv.org/pdf/2307.16430.pdf
演示地址:https://vits-2.github.io/demo/
VITS1讲解详见:https://mp.csdn.net/mp_blog/creation/editor/130904876
1.2 介绍
最近,基于深度神经网络的文本到语音的发展取得了重大进展。基于深度神经网络的文本到语音转换是一种从输入文本生成相应原始波形的方法;它有几个有趣的特性,通常使文本到语音任务具有挑战性。通过对特征的快速回顾,可以发现文本到语音任务涉及到将不连续的文本特征转换为连续的波形。输入和输出具有数百倍的时间步长差异,它们之间的对齐必须非常精确才能合成高质量的语音音频。此外,输入文本中不存在的韵律和说话人特征需要自然地表达,文本输入可以有多种说话方式,这是一个一对多的问题。合成高质量语音具有挑战性的另一个因素是,人们在听音频时专注于单个组件;因此,即使构成整个音频的数十万个信号中只有一小部分是非自然的,人类也可以很容易地感知它们。效率是导致任务困难的另一个因素。合成的音频具有很高的时间分辨率,通常每秒包含超过20,000个数据,需要高效的采样方法。
由于文本到语音的任务特点,解决方案也可以是复杂的。之前的工作通过将从输入文本生成波形的过程分为两个级联阶段来解决这些问题。一种流行的方法涉及从第一阶段的输入文本中生成中间语音表示,如梅尔语谱图或语言特征,然后以第二阶段的这些中间表示为条件生成原始波形。两级管道系统具有简化每个模型和便于训练的优点;然而,它们也有以下限制。
- 错误从第一阶段传播到第二阶段。
- 它不是利用模型内部学习到的表示,而是通过人类定义的特征(如梅尔语谱图或语言特征)进行中介。
- 生成中间特征所需的计算量。最近,为了解决这些限制,直接从输入文本中生成波形的单阶段模型已被积极研究。单阶段模型不仅优于两阶段管道系统,而且显示了生成与人类几乎不可区分的高质量语音的能力。
虽然之前的工作使用单阶段方法取得了巨大的成功,但模型vits存在以下问题:间歇性不自然、时长预测器效率低、输入格式复杂以缓解对齐和时长建模的局限性(使用空白标记)、多说话人模型中说话人相似性不足、训练速度慢以及对音素转换的依赖性强。本文提供了解决这些问题的方法。本文提出一种通过对抗性学习训练的随机时长预测器,利用transformer块和说话人条件文本编码器改进的归一化流,以更好地对多个说话人特征进行建模。实验结果表明,所提出的方法提高了质量和效率。此外,通过使用规范化文本作为模型输入的实验表明,该方法减少了对音素转换的依赖。因此,该方法更接近于完全的端到端单阶段方法。
1.3 模型
在本节中,我们描述了四个小节的改进:时长预测(duration prediction)、具有归一化流的增广变分自编码器(augmented variational autoencoder with normalizing flows)、对齐搜索(alignment search)和以说话人为条件的文本编码器(and speaker-conditioned text encoder)。本文提出一种使用对抗性学习来训练时长预测器的方法,以在训练和合成方面都具有较高的效率来合成自然语音。该模型本质上是使用上一项工作[4,17]中提出的单调对齐搜索(MAS)来学习对齐,并进一步建议进行修改以提高质量。提出了一种通过将transformer块引入到规范化流程中来提高自然性的方法,能在转换分布时捕获长期依赖。此外,本文还改进了多说话人模型中的说话人条件,以提高说话人相似度。
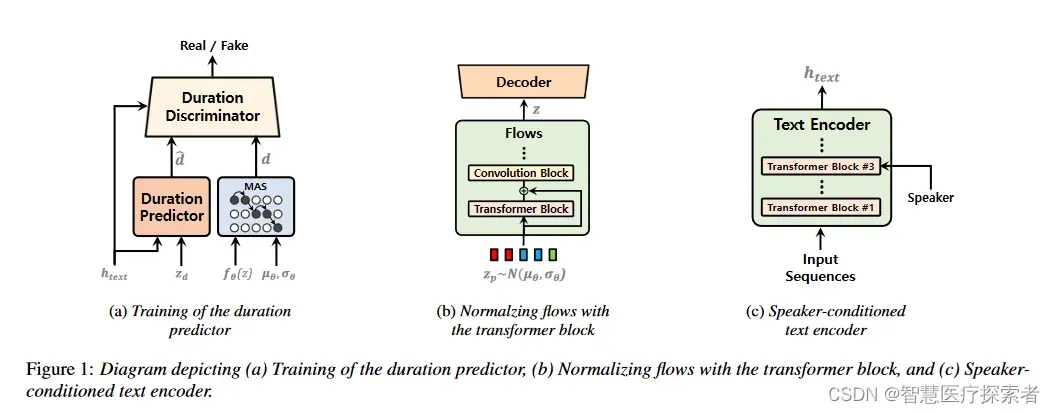
1.3.1 基于时间步进条件判别的随机时长预测器
之前的工作表明,基于流的随机时长预测器比确定性方法更有效地提高了合成语音的自然度。结果很好;然而,基于流的方法需要相对更多的计算和一些复杂的技术。本文提出一种具有对抗性学习的随机时长预测器,以合成更自然的语音,在训练和合成方面的效率都比之前的工作更高。建议的持续时间预测器和鉴别器的概述如图1a所示。我们应用对抗性学习来训练时间预测器,使用与生成器相同的输入条件判别器来适当区分预测的时间。我们使用文本的隐藏表示htext和高斯噪声zd作为生成器G的输入;使用MAS获得的对数尺度的htext和持续时间(以d表示)或从持续时间预测器(以dˆ表示)中预测的htext和持续时间(以d表示)作为鉴别器d的输入。一般生成对抗网络的鉴别器被输入固定长度的输入,而预测每个输入token的持续时间,并且输入序列的长度随每个训练实例而变化。为正确区分可变长度的输入,本文提出一种时间逐步判别器,可区分所有token的每个预测持续时间。我们使用两种类型的损失;对抗学习的最小二乘损失函数和均方误差损失函数:
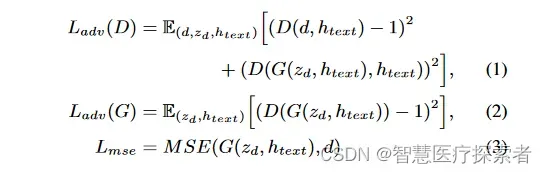
提出的时长预测器和训练机制允许在较短的步骤中学习时长,并且时长预测器被单独训练作为最后的训练步骤,从而减少了训练的整体计算时间。
1.3.2 带高斯噪声的单调对齐搜索
在之前的工作之后,我们将MAS引入到我们的模型中来学习对齐。该算法产生了在所有可能的单调对齐中具有最高概率的文本和音频之间的对齐,并训练模型以最大化其概率。该方法是有效的;然而,在搜索和优化特定的对齐之后,搜索其他更合适的对齐会受到限制。为了缓解这个问题,我们在计算的概率中添加了一个小的高斯噪声。这为模型提供了额外的机会来搜索其他对齐。我们只在训练开始时添加这种噪声,因为MAS使模型能够快速学习对齐。参考之前的工作[4],该工作详细描述了算法,正向操作中所有可能位置的Q值都计算出最大对数似然。我们在操作中计算的Q值上添加了小的高斯噪声。
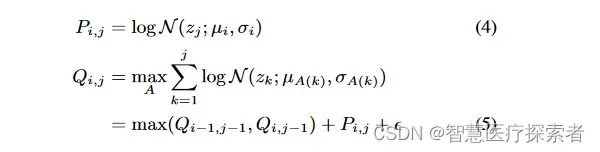
其中i和j分别表示输入序列和后验序列上的特定位置,z表示来自标准化流的转换潜变量。是从标准正态分布中采样的噪声、P的标准差和从0.01开始并每步递减2×10^−6的噪声尺度的乘积。
1.3.3 使用Transformer块的归一化流
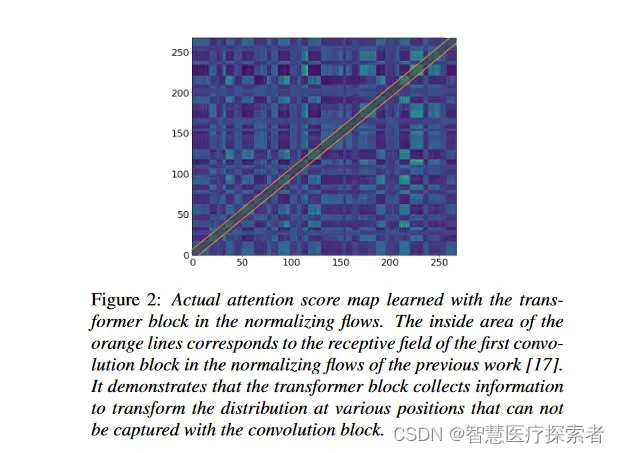
之前的工作展示了用归一化流增强的变分自编码器合成高质量语音音频的能力。归一化流包含卷积块,卷积块是捕获相邻数据模式的有效结构,使模型能够合成高质量的语音。在转换分布时,捕捉长期依赖关系的能力至关重要,因为语音的每个部分都与不相邻的其他部分相关。虽然卷积块可以有效捕获相邻模式,但由于其感受野的限制,在捕获长期依赖关系方面存在不足。因此,我们在归一化流中添加了一个带有残差连接的小transformer块,以捕获长期依赖关系,如图1b所示。图2显示了实际的注意力得分图和卷积块的感受野。可以确定,transformer块在变换分布时在不同位置收集信息,这是感受野不可能做到的。
1.3.4 说话人条件文本编码器
由于多说话人模型是根据说话人条件用单一模型合成多种特征的语音,表达每个说话人的个人语音特征是一个重要的质量因素,也是自然度的一个重要因素。已有工作表明,单阶段模型可以高质量地对多个说话人进行建模。考虑到说话人的特定发音和语调等特征会显著影响每个说话人的语音特征的表达,但输入文本中不包含这些特征,设计了一个以说话人信息为条件的文本编码器,通过在编码输入文本的同时学习这些特征来更好地模仿每个说话人的各种语音特征。我们将说话人向量设置在文本编码器的第三个transformer块上,如图1c所示。
1.4 实验
我们在两个不同的数据集上进行了实验。使用LJ语音数据集[20]验证自然度的提升,使用VCTK数据集[21]验证模型是否能更好地再现说话人特征。LJ语音数据集由单个说话者的13100个短音频片段组成,总长度约为24小时。音频格式是16位PCM,采样率为22.05 kHz,我们使用它没有任何操作。我们将数据集随机分为训练集(12,500个样本)、验证集(100个样本)和测试集(500个样本)。
VCTK数据集由109个具有不同口音的英语母语者发出的约44,000个短音频片段组成。音频剪辑的总长度约为44小时。音频格式为16位PCM,采样率为44.1 kHz。我们将采样率降低到22.05 kHz。我们将数据集随机分为训练集(43,470个样本)、验证集(100个样本)和测试集(500个样本)。采用80波段mel尺度谱图计算重建损失。与之前的工作[17]相比,我们使用相同的语谱图作为后验编码器的输入。快速傅里叶变换、窗口和跳数分别设置为1024、1024和256。
我们使用音素序列和规范化文本作为模型的输入进行了实验。我们使用开源软件[22]将文本序列转换为国际音标序列,并将该序列输入文本编码器。与之前的工作[17]相比,我们没有使用空白标记。对于规范化文本的实验,我们使用开源软件[23]用简单的规则规范化输入文本,并将其提供给文本编码器。
使用AdamW[24]优化器训练网络,β1 = 0.8, β2 = 0.99,权重衰减λ = 0.01。学习率衰减在每轮中以0.9991/8因子进行调度,初始学习率为2 × 10^−4。我们每一步为网络提供256个训练实例。继之前的工作[17]之后,应用带窗口的生成器训练。我们在四个NVIDIA V100 gpu上使用混合精度训练。生成波形的网络和持续时间预测器分别训练了800k和30k步。
1.5 结果
1.5.1 自然度评估
为了验证所提模型能够合成自然语音,进行了众包平均意见得分(MOS)测试。在听了从测试集中随机选择的音频样本后,打分者对他们的自然程度进行了从1到5的5分评分。考虑到之前的工作[17]已经显示出与人工记录相似的质量,我们还进行了比较平均意见分数(CMOS)测试,该测试适合通过直接比较来评估高质量样本。评价者在听了从测试集中随机选择的音频样本后,对他们相对偏好的自然程度进行了评分,总分为7分,从3到3分不等评价者被允许对每个音频样本进行一次评估。对所有音频样本进行归一化处理,以避免幅度差异对得分的影响。我们使用官方实现和之前工作[17]的预训练权重作为比较模型。评价结果见表1和表2a。该方法与已有工作[17]的MOS值差为0.09,CMOS值和置信区间分别为0.201和±0.105。实验结果表明,该方法显著提高了合成语音的质量。此外,我们使用[18]方法对CMOS进行了评估,该方法在不同的结构和训练机制下表现出良好的性能。为了评估,我们使用官方实现和预训练权重生成样本。实验结果的CMOS和置信区间分别为0.176和±0.125,表明该方法明显优于传统方法。
1.5.2 消融研究
为验证所提方法的有效性,进行了消融研究。为验证对抗学习训练的随机时间预测器的有效性,将其替换为具有相同结构的确定性时间预测器,并使用L2损失进行训练。确定性时间预测器的训练步骤与之前的工作[17]相同。为验证对齐搜索中使用的噪声调度的有效性,对模型进行无噪声训练。为了验证模型的有效性,在归一化流程中没有transformer模块的情况下对模型进行训练。评价结果如表1所示。确定性持续时间预测器、无噪声的对准搜索和无变压器块的归一化流的消融研究的MOS差值分别为0.14、0.15和0.06。由于不使用空白标记和线性语谱图,计算效率将得到提高,删除一些所提出的方法与之前的工作[17]相比,性能较低。实验结果表明,所提方法在提高图像质量方面是有效的。
1.5.3 说话人相似度评估
为了确认多说话人模型中说话人相似度的提升,通过众包的方式进行了类似于之前工作的相似度MOS测试。在测试中,从测试集中随机采样的人类录制音频作为参考,评分者以1到5的五分制对参考音频和相应合成音频之间的相似性进行评分。如4.1节所述,允许评价者对每个音频样本进行一次评估,并对音频样本进行归一化。评价结果见表2b。VITS2的评分比[17]高0.2个MOS,表明该方法在多说话人建模时能够有效提高说话人相似度。
1.5.4 减少对音素转换的依赖
之前的工作[17,26]在单阶段方法中表现出良好的性能,但仍然对音素转换有很强的依赖性。因为规范化的文本并没有告知它的实际发音,这使得学习准确的发音具有挑战性。这是目前实现完全端到端单阶段语音合成的一个关键障碍。本文提出,该方法通过可懂度测试显著改善了这个问题。在使用谷歌的自动语音识别API转录测试集中的500个合成音频后,我们以真实文本为参考计算字符错误率(CER)。我们将以下四个模型的结果与真实值进行了比较:提出的模型使用音素序列,提出的模型使用规范化文本,之前的工作使用音素序列,以及之前的工作使用规范化文本。表3给出了对比,这证实了提出的模型不仅优于之前的工作,而且我们的模型在使用归一化文本时的性能与使用音素序列的模型相当。它展示了数据驱动的、完全端到端方法的可能性。
1.5.5 综合和训练速度的比较
我们将该模型的综合和训练速度与之前的工作进行了比较。我们测量了从LJ语音数据集中随机选择的500个句子,从输入序列中生成原始波形的整个过程的同步经过时间。我们使用单个NVIDIA V100 GPU,批处理大小为1。我们还在四块NVIDIA V100 gpu上测量并平均了五个epoch中每个步骤的训练计算经过的时间。表4显示了结果。由于该预测器比以往的工作更高效、可单独训练、输入序列更短,因此提高了训练和合成速度;性能提升分别为20.5%和22.7%。
1.6 结论
本文提出VITS2,一种单阶段的文本到语音模型,可以有效地合成更自然的语音。通过在时长预测器中引入对抗学习,提高了训练推理效率和自然度。将transformer块添加到规范化流中,以捕获在转换分布时的长期依赖关系。通过在对齐搜索中引入高斯噪声,提高了合成质量。对音素转换的依赖显著减少,这对实现完全端到端单阶段语音合成构成了挑战。测试结果也表明,整体可懂度得到了提升。通过实验、质量评估和计算速度测量,验证了所提方法的有效性。在语音合成领域仍然存在着各种必须解决的问题,我们希望我们的工作可以作为未来研究的基础。
2 使用Bert-VITS2训练个性化语音
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境构建
git clone https://github.com/fishaudio/Bert-VITS2
cd Bert-VITS2
conda create -n vits2 python=3.9
conda activate vits2
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
pip install -r requirements.txt
pip install openai-whisper
2.3 预训练模型下载
2.3.1 bert模型
中文模型:https://huggingface.co/hfl/chinese-roberta-wwm-ext-large/tree/main
英文模型:https://huggingface.co/microsoft/deberta-v3-large/tree/main
日文模型:https://huggingface.co/ku-nlp/deberta-v2-large-japanese/tree/main
中文模型下载pytorch_model.bin文件,完成后放到bert/chinese-roberta-wwm-ext-large/目录下,命令查看如下:
[root@localhost Bert-VITS2]# ll bert/chinese-roberta-wwm-ext-large/
总用量 1276256
-rw-r--r-- 1 root root 3 11月 7 18:44 added_tokens.json
-rw-r--r-- 1 root root 690 11月 7 18:44 config.json
-rw-r--r-- 1 root root 1306484351 11月 8 10:37 pytorch_model.bin
-rw-r--r-- 1 root root 2063 11月 7 18:44 README.md
-rw-r--r-- 1 root root 113 11月 7 18:44 special_tokens_map.json
-rw-r--r-- 1 root root 20 11月 7 18:44 tokenizer_config.json
-rw-r--r-- 1 root root 268962 11月 7 18:44 tokenizer.json
-rw-r--r-- 1 root root 109540 11月 7 18:44 vocab.txt英文模型pytorch_model.bin,spm.model两个文件,完成后放到bert/deberta-v3-large/目录下,命令查看如下:
ll bert/deberta-v3-large/
总用量 855624
-rw-r--r-- 1 root root 580 11月 7 18:44 config.json
-rw-r--r-- 1 root root 560 11月 7 18:44 generator_config.json
-rw-r--r-- 1 root root 873673253 11月 8 17:14 pytorch_model.bin
-rw-r--r-- 1 root root 3263 11月 7 18:44 README.md
-rw-r--r-- 1 root root 2464616 11月 8 17:14 spm.model
-rw-r--r-- 1 root root 52 11月 7 18:44 tokenizer_config.json日文模型下载pytorch_model.bin文件,完成后放到bert/deberta-v2-large-japanese/目录下,命令查看如下:
ll bert/deberta-v2-large-japanese/
总用量 1458132
-rw-r--r-- 1 root root 947 11月 7 18:44 config.json
-rw-r--r-- 1 root root 1490693213 11月 8 17:18 pytorch_model.bin
-rw-r--r-- 1 root root 4921 11月 7 18:44 README.md
-rw-r--r-- 1 root root 173 11月 7 18:44 special_tokens_map.json
-rw-r--r-- 1 root root 353 11月 7 18:44 tokenizer_config.json
-rw-r--r-- 1 root root 2408886 11月 7 18:44 tokenizer.json测试bert模型:
export PYTHONPATH=$PYTHONPATH:${cur_dir}
python ./text/chinese_bert.py
python ./text/japanese_bert.py2.3.2 VITS2预训练模型
预训练模型:Stardust_minus/Bert-VITS2
mkdir -p data/models下载“Bert-VITS2中日底模”文件,下载完成后,解压缩,然后放到data/models目录下,命令查看显示如下:
[root@localhost Bert-VITS2]# ll data/models/
总用量 5813884
-rw-r--r-- 1 root root 561077905 11月 9 10:12 D_0.pth
-rw-r--r-- 1 root root 6887303 11月 9 10:12 DUR_0.pth
-rw-r--r-- 1 root root 705716525 11月 9 10:12 G_0.pth2.4 数据预处理
2.4.1 长音频分割与自动识别
mkdir -p data
mkdir -p data/long
mkdir -p data/short
mkdir -p data/long/zhang
新建data目录,在data的目录下新建long的文件夹,存储长音频文件,在long下新建用户zhang的长音频,把长音频放在data/long/zhang目录下,如下所示:
[root@localhost Bert-VITS2]# ll data/long/zhang
总用量 80912
-rw-r--r-- 1 root root 82851630 11月 10 07:18 long01.wav创建python文件
vi split_reg.pyimport os
from pathlib import Path
import librosa
from scipy.io import wavfile
import numpy as np
import whisper
def split_long_audio(model, filepaths, save_dir, person, out_sr=44100):
files = os.listdir(filepaths)
filepaths=[os.path.join(filepaths, i) for i in files]
for file_idx, filepath in enumerate(filepaths):
save_path = Path(save_dir)
save_path.mkdir(exist_ok=True, parents=True)
print(f"Transcribing file {file_idx}: '{filepath}' to segments...")
result = model.transcribe(filepath, word_timestamps=True, task="transcribe", beam_size=5, best_of=5)
segments = result['segments']
wav, sr = librosa.load(filepath, sr=None, offset=0, duration=None, mono=True)
wav, _ = librosa.effects.trim(wav, top_db=20)
peak = np.abs(wav).max()
if peak > 1.0:
wav = 0.98 * wav / peak
wav2 = librosa.resample(wav, orig_sr=sr, target_sr=out_sr)
wav2 /= max(wav2.max(), -wav2.min())
for i, seg in enumerate(segments):
start_time = seg['start']
end_time = seg['end']
wav_seg = wav2[int(start_time * out_sr):int(end_time * out_sr)]
wav_seg_name = f"{person}_{i}.wav"
i += 1
out_fpath = save_path / wav_seg_name
wavfile.write(out_fpath, rate=out_sr, data=(wav_seg * np.iinfo(np.int16).max).astype(np.int16))
# 使用whisper语音识别
def transcribe_one(audio_path):
audio = whisper.load_audio(audio_path)
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
lang = max(probs, key=probs.get)
options = whisper.DecodingOptions(beam_size=5)
result = whisper.decode(model, mel, options)
print(result.text)
return result.text
if __name__ == '__main__':
whisper_size = "medium"
model = whisper.load_model(whisper_size)
persons = ['zhang']
for person in persons:
audio_path = f"./data/short/{person}"
if os.path.exists(audio_path):
for filename in os.listdir(audio_path):
file_path = os.path.join(audio_path, filename)
os.remove(file_path)
split_long_audio(model, f"./data/long/{person}", f"./data/short/{person}", person)
files = os.listdir(audio_path)
file_list_sorted = sorted(files, key=lambda x: int(os.path.splitext(x)[0].split('_')[1]))
filepaths = [os.path.join(audio_path, i) for i in file_list_sorted]
for file_idx, filepath in enumerate(filepaths):
text = transcribe_one(filepath)
with open(f"./data/short/{person}/{person}_{file_idx}.lab", 'w') as f:
f.write(text)运行上面的文件
python split_reg.py运行完成后,长音频被切割为短音频,存储在data/short目录下,如下所示
[root@localhost Bert-VITS2]# ll data/short/zhang/
总用量 67336
-rw-r--r-- 1 root root 54 11月 10 11:46 zhang_0.lab
-rw-r--r-- 1 root root 418114 11月 10 11:46 zhang_0.wav
-rw-r--r-- 1 root root 89 11月 10 11:50 zhang_100.lab
-rw-r--r-- 1 root root 735632 11月 10 11:46 zhang_100.wav
-rw-r--r-- 1 root root 15 11月 10 11:50 zhang_101.lab
-rw-r--r-- 1 root root 151748 11月 10 11:46 zhang_101.wav
-rw-r--r-- 1 root root 36 11月 10 11:50 zhang_102.lab
-rw-r--r-- 1 root root 471032 11月 10 11:46 zhang_102.wav
-rw-r--r-- 1 root root 102 11月 10 11:50 zhang_103.lab
-rw-r--r-- 1 root root 769148 11月 10 11:46 zhang_103.wav
-rw-r--r-- 1 root root 49 11月 10 11:50 zhang_104.lab
-rw-r--r-- 1 root root 439280 11月 10 11:46 zhang_104.wav
-rw-r--r-- 1 root root 24 11月 10 11:50 zhang_105.lab
-rw-r--r-- 1 root root 176444 11月 10 11:46 zhang_105.wav
-rw-r--r-- 1 root root 48 11月 10 11:50 zhang_106.lab
-rw-r--r-- 1 root root 509840 11月 10 11:46 zhang_106.wav
-rw-r--r-- 1 root root 39 11月 10 11:50 zhang_107.lab2.4.2 生成预处理文本
vi gen_filelist.pyimport os
out_file = f"filelists/full.txt"
def process():
persons = ['zhang']
ch_language = 'ZH'
with open(out_file, 'w', encoding="Utf-8") as wf:
for person in persons:
path = f"./data/short/{person}"
files = os.listdir(path)
for f in files:
if f.endswith(".lab"):
with open(os.path.join(path, f), 'r', encoding="utf-8") as perFile:
line = perFile.readline()
result = f"./data/short/{person}/{f.split('.')[0]}.wav|{person}|{ch_language}|{line}"
wf.write(f"{result}\n")
if __name__ == "__main__":
process()运行文件
python gen_filelist.py运行成功后,在filelists下生成txt文件,如下所示:
[root@localhost Bert-VITS2]# ll filelists/
总用量 20
-rw-r--r-- 1 root root 12957 11月 10 15:22 full.txt2.4.3 调用文本预处理
python preprocess_text.py如出现nltk_data下载失败,解决方案:nltk_data下载失败问题解决
再次运行python preprocess_text.py,显示如下:
已根据默认配置文件default_config.yml生成配置文件config.yml。请按该配置文件的说明进行配置后重新运行。
如无特殊需求,请勿修改default_config.yml或备份该文件。更改根目录下config.yml配置文件,主要修改如下几个配置,修改后的结果如下:
dataset_path: ""
resample:
in_dir: "data/short"
out_dir: "data/short"
preprocess_text:
transcription_path: "filelists/full.txt"
cleaned_path: ""
train_path: "filelists/train.txt"
val_path: "filelists/val.txt"
config_path: "configs/config.json"
bert_gen:
config_path: "configs/config.json"
train_ms:
model: "data/models"
config_path: "configs/config.json"
webui:
device: "cuda"
model: "models/G_8000.pth"
config_path: "configs/config.json"
运行该脚本后,filelists文件夹下会生成.clean等文件,如下所示
[root@localhost Bert-VITS2]# ll filelists/
总用量 112
-rw-r--r-- 1 root root 12957 11月 10 15:22 full.txt
-rw-r--r-- 1 root root 42643 11月 10 15:43 full.txt.cleaned
-rw-r--r-- 1 root root 41524 11月 10 15:42 train.txt
-rw-r--r-- 1 root root 1119 11月 10 15:42 val.txt2.4.4 重采样
python resample.py重采样后的音频文件会覆盖原来的文件。
2.4.5 生成pt文件
python bert_gen.py运行完成后显示如下:
from a BertForSequenceClassification model).
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 131/131 [00:10<00:00, 13.06it/s]
bert生成完毕!, 共有131个bert.pt生成!
[root@localhost Bert-VITS2]# ll data/short/zhang/
总用量 110520
-rw-r--r-- 1 root root 316154 11月 10 16:21 zhang_0.bert.pt
-rw-r--r-- 1 root root 54 11月 10 11:46 zhang_0.lab
-rw-r--r-- 1 root root 418114 11月 10 15:53 zhang_0.wav
-rw-r--r-- 1 root root 545536 11月 10 16:21 zhang_100.bert.pt
-rw-r--r-- 1 root root 89 11月 10 11:50 zhang_100.lab
-rw-r--r-- 1 root root 735632 11月 10 15:53 zhang_100.wav
-rw-r--r-- 1 root root 135936 11月 10 16:21 zhang_101.bert.pt
-rw-r--r-- 1 root root 15 11月 10 11:50 zhang_101.lab
-rw-r--r-- 1 root root 151748 11月 10 15:53 zhang_101.wav
-rw-r--r-- 1 root root 217856 11月 10 16:21 zhang_102.bert.pt
-rw-r--r-- 1 root root 36 11月 10 11:50 zhang_102.lab
-rw-r--r-- 1 root root 471032 11月 10 15:53 zhang_102.wav
-rw-r--r-- 1 root root 578304 11月 10 16:21 zhang_103.bert.pt
-rw-r--r-- 1 root root 102 11月 10 11:50 zhang_103.lab
-rw-r--r-- 1 root root 769148 11月 10 15:53 zhang_103.wav2.5 模型训练
在train_ms.py的文件开头增加一行代码:
os.environ["LOCAL_RANK"] = '0'否则会报如下错误:
[root@localhost Bert-VITS2]# python train_ms.py
Traceback (most recent call last):
File "/opt/Bert-VITS2/train_ms.py", line 660, in <module>
run()
File "/opt/Bert-VITS2/train_ms.py", line 65, in run
local_rank = int(os.environ["LOCAL_RANK"])
File "/root/anaconda3/envs/vits2/lib/python3.9/os.py", line 679, in __getitem__
raise KeyError(key) from None
KeyError: 'LOCAL_RANK'开启模型训练:
python train_ms.py出现如下界面,则模型训练开始执行了:
[root@localhost Bert-VITS2]# python train_ms.py
11-10 16:31:06 INFO | data_utils.py:60 | Init dataset...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 126/126 [00:00<00:00, 48302.93it/s]
11-10 16:31:06 INFO | data_utils.py:75 | skipped: 3, total: 126
11-10 16:31:06 INFO | data_utils.py:60 | Init dataset...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 52298.05it/s]
11-10 16:31:06 INFO | data_utils.py:75 | skipped: 0, total: 5
Using noise scaled MAS for VITS2
Using duration discriminator for VITS2
INFO:models:Loaded checkpoint 'data/models/DUR_0.pth' (iteration 0)
ERROR:models:enc_p.tone_emb.weight is not in the checkpoint
WARNING:models:Seems you are using the old version of the model, the enc_p.ja_bert_proj.weight is automatically set to zero for backward compatibility
ERROR:models:enc_p.en_bert_proj.weight is not in the checkpoint
ERROR:models:enc_p.en_bert_proj.bias is not in the checkpoint
ERROR:models:emb_g.weight is not in the checkpoint
INFO:models:Loaded checkpoint 'data/models/G_0.pth' (iteration 0)
INFO:models:Loaded checkpoint 'data/models/D_0.pth' (iteration 0)
0it [00:00, ?it/s]中间报了一个错误
ERROR:models:enc_p.tone_emb.weight is not in the checkpoint那是因为预训练模型中不包含英文引起的,不影响训练。
2.6 tensorboard可视化
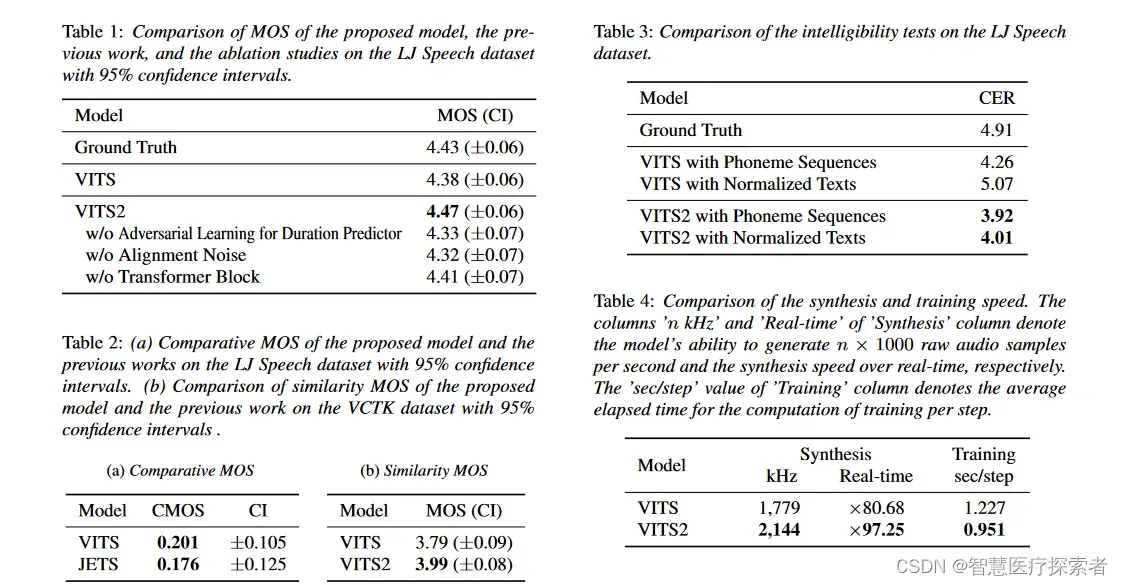
python -m tensorboard.main --logdir=data/models --host=192.168.1.160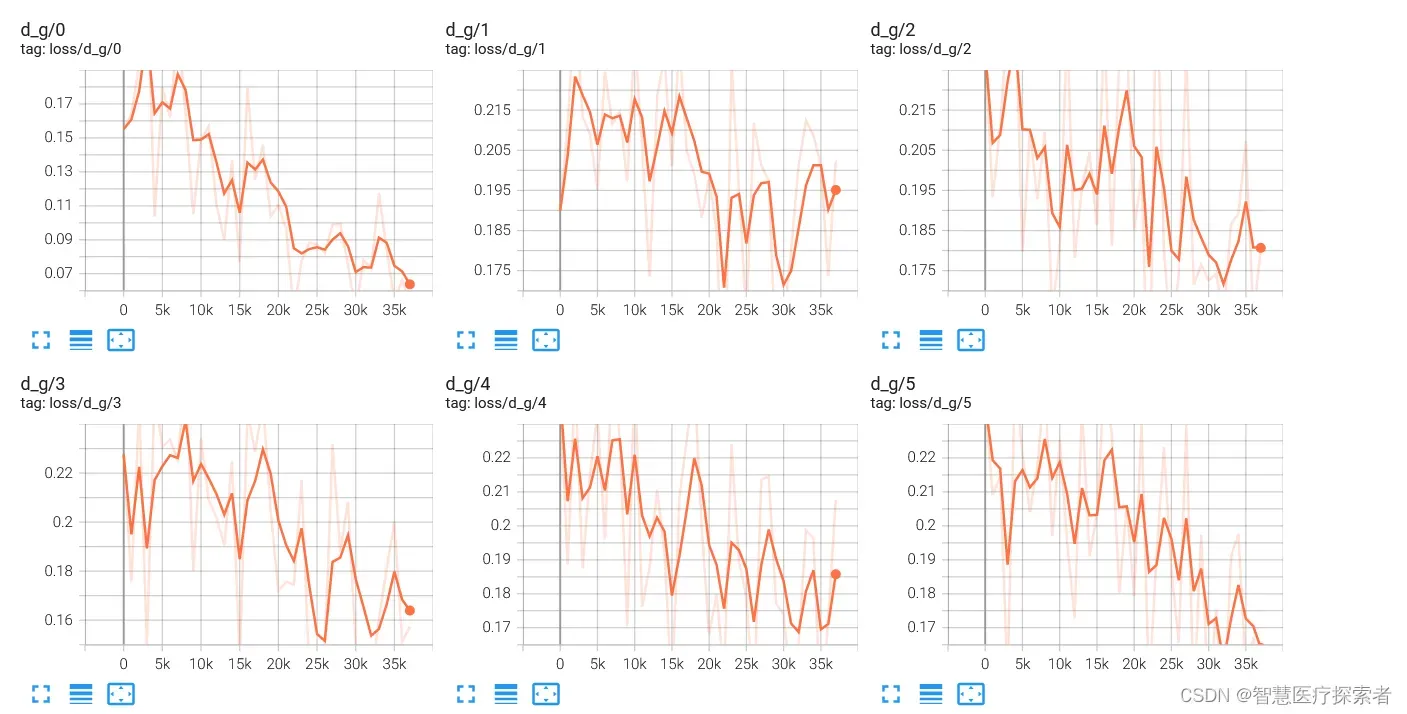
文章出处登录后可见!