训练模型过程中,会遇到很多的随机性设置,设置随机性并多次实验的结果更加有说服力。但是现在发论文越来越要求模型的可复现性,这时候不得不控制代码的随机性问题
且每次随机的初始权重一样,有利于实验的比较和改进
须知:随机种子和神经网络训练没有直接关系,随机种子的作用就是产生权重为初始条件的随机数。神经网络效果的好坏直接取决于学习率和迭代次数。
简单的说,计算机中生成随机数的过程并不随机百,但是其初始数(种子)是随机的。在深度学习中,(比如深度神经网络)我们常常需要对网络中超参数设定初始值,比如权重,在这里我们需要用到一些生成随机数的函数,这些函数一般通过手动设定种子,如果种子设定为相同的,那么得到的初始权重就是一样的。
最优随机种子不应该去找,随机性的存在正好用来评估模型的鲁棒性。一个优秀的模型,不会因为随机初始的位置略微不同,而找不到最优的位置。这是模型本身应该要化解的工作,而不是人为选择一个随机数。
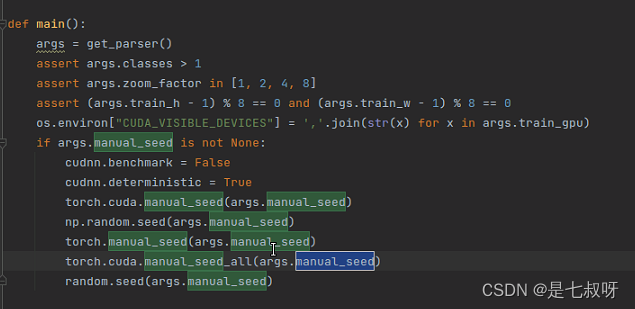
相关函数:
torch.manual_seed(number):为CPU中设置种子,生成随机数;torch.cuda.manual_seed(number):为特定GPU设置种子,生成随机数;torch.cuda.manual_seed_all(number):为所有GPU设置种子,生成随机数;
torch.manual_seed(1)是为了设置CPU的的随机数固定,使得紧跟着运行同一个.py文件的rand()函数==【随机函数】==生成的值是固定的随机!
但是设置随机种子后,是每次运行test.py文件的输出结果都一样,而不是每次随机函数生成的结果一样:
# test.py
import torch
torch.manual_seed(0)
print(torch.rand(1))
print(torch.rand(1))
输出:
tensor([0.4963])
tensor([0.7682])
如果你就是想要每次运行随机函数生成的结果都一样,那你可以在每个随机函数前都设置一模一样的随机种子:
# test.py
import torch
torch.manual_seed(0)
print(torch.rand(1))
torch.manual_seed(0)
print(torch.rand(1))
输出:
tensor([0.4963])
tensor([0.4963])
文章出处登录后可见!
已经登录?立即刷新