FaceChain写真开源项目插播:
最新 FaceChain支持多人合照写真、上百种单人写真风格,项目信息汇总:ModelScope 魔搭社区 。
github开源直达(觉得有趣的点个star哈。):GitHub – modelscope/facechain: FaceChain is a deep-learning toolchain for generating your Digital-Twin.
摘要
阿里巴巴最新自研的像素感知扩散超分模型已经开源,它把扩散模型强大的生成能力和像素级控制能力相结合,能够适应从老照片修复到AIGC图像超分的各种图像增强任务和各种图像风格,并且能够控制生成强度和增强风格。这项技术的直接应用之一是AIGC图像的后处理增强和二次生成,能够带来可观的效果提升。
论文&代码
论文链接:[arxiv]
背景介绍
随着大模型,特别是以文生图、ChatGPT为代表的AIGC大模型的快速发展,人工智能进入到发展的新时代和快车道。以文生图为例,基于大数据大模型训练的模型展示出惊人的生成能力,能够根据文本prompt输出逼真的自然图像,达到以假乱真的程度。创业公司StabilityAI基于latent diffusion框架训练并开源了Stable Diffusion(SD)文生图预训练模型,给普通大众接触和使用大模型的机会,其优越的性能也带来了学术研究和开源社区的热潮,在包括可控生成、个性化定义、图像编辑等等下游任务中都得到了广泛的应用和深刻的影响。本文着眼于底层视觉任务中的超分辨率与修复算法,这类任务需要特别倚重模型的生成能力以恢复栩栩如生、真实感的纹理细节,而这正是SD这一类的生成模型所擅长的,因此将SD应用到超分辨率任务正在成为一个研究热点,已经有包括LDM、StableSR等工作涌现,本文介绍了一种全新的基于SD生成先验的图像超分辨率和修复算法,在多个任务上都有着SOTA的表现。
先看看成品
|
|
|
|
|
|



研究基础
在介绍图像超分辨率与修复之前,我们先回顾一下基于SD的可控图像翻译任务 (Image-to-Image Translation),即给定一张控制图像如canny、pose、depth等生成出符合控制图像结构的结果。大规模文生图模型如SD我们可以理解为具备了生成自然界任意图像的能力,那么可控图像翻译任务本质上就是要在SD的潜空间中找到符合控制图像的结果,所以代表性工作如ControlNet、T2I-Adapter等都是通过引入额外的分支网络,将控制条件引入到SD主网络中,实现其潜能的激发。超分辨率任务和图像翻译本质上是一样的,都是Image-to-Image的mapping,但不同的是,超分辨率任务的控制条件是一张低分辨率的图像,期待输出的结果需要与这张低分辨率图像做到像素层面上的对应,因此是一种更强约束的图像翻译。考虑到这一点,我们可以从前人的工作如ControlNet中得到启发。一个初步的想法就是直接拿ControlNet来做超分,但遗憾的是,实验发现,用ControlNet做超分,往往做不到像素级的精确控制,会出现输出高清图与输入低清图存在语义结构上差异,如下图所示:

这主要是因为ControlNet只采用了加的方式传入控制条件信息,而这种方式的控制相对较弱,达不到像素级的感知。
我们的方法
PACA模块
所以我们核心要解决的问题就是如何强化SD对像素级控制信息的感知。我们设计的主要框架图如下:
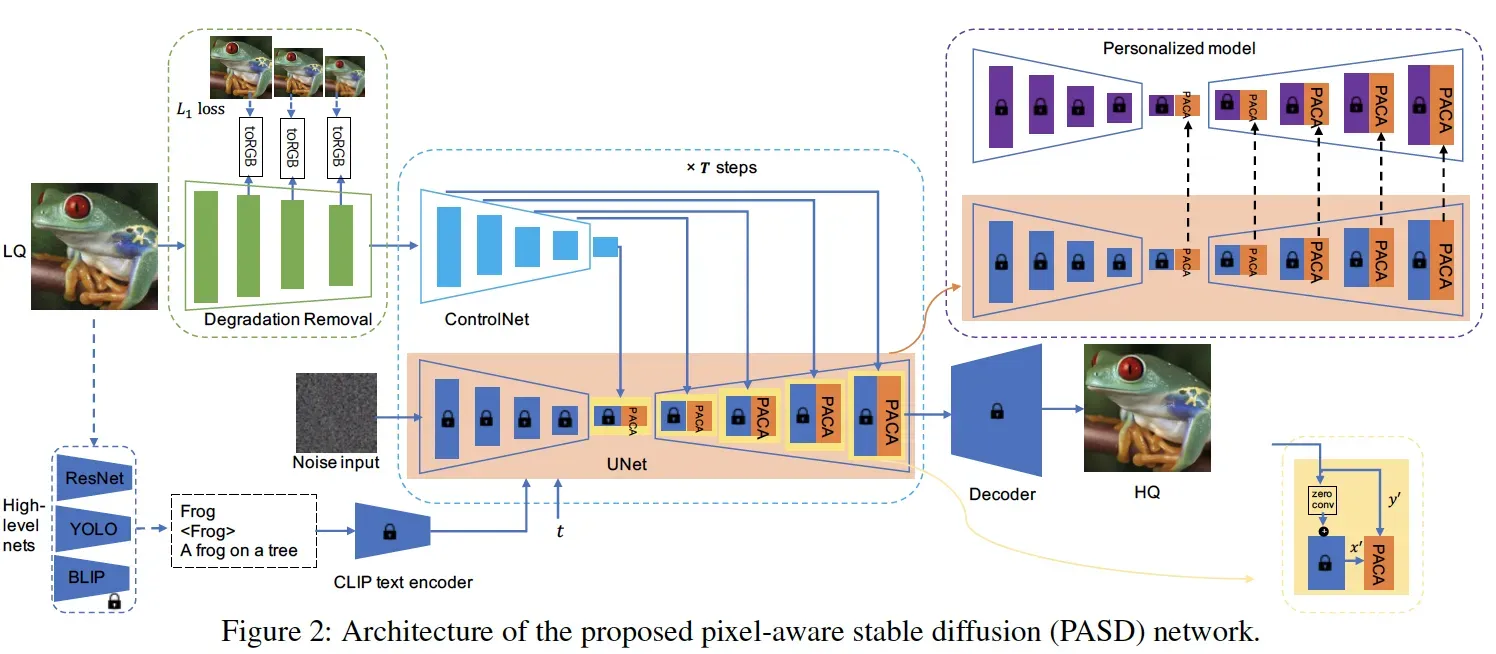
与ControlNet采用的简单的加的方式不同,我们引入特别的Pixel-Aware Cross Attention (PACA) 模块来强化像素级信息的传输,其形式与经典的cross attention类似:
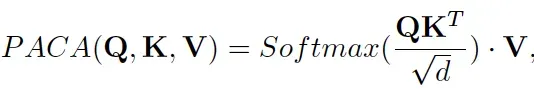
其中Q的来源是SD得到的特征x,而Q和V则是来源于类ControlNet分支网络得到的特征y。这里的y与x有着完全相同的size,我们会把y映射成长度为h*w的embedding。这里的长度h*w蕴含了像素级的信息,因为类ControlNet分支没有使用VAE中的encoder,我们认为y依然保留着控制图像原始的像素信息。正因为此,我们认为PACA强化了像素级信息的感知能力。
降质去除模块
特别的对于真实超分场景,因为输入低清图像往往存在着各类的降质因素,而我们希望基于SD的模块专注于生成能力,所以引入了一个前置的Degradation Removal模块来对真实降质图像做一个简单的去degradations的操作,我们的实验也发现这样的结构有利于改善真实超分的效果。
High-Level信息
为了进一步的增强超分和修复的效果,我们实验发现high-level的语义信息往往对结果有正向的助益,所以我们引入分类、检测、图像打标等网络来提供额外的语义信息,并将这些信息结构化整理成文本prompt输入到SD中。同时,根据Classier-free Guidance理论,我们引入一些负向prompt包括noisy、blurry、lowres等,实验也表明这些信息的因素对结果也有帮助。
实验结果
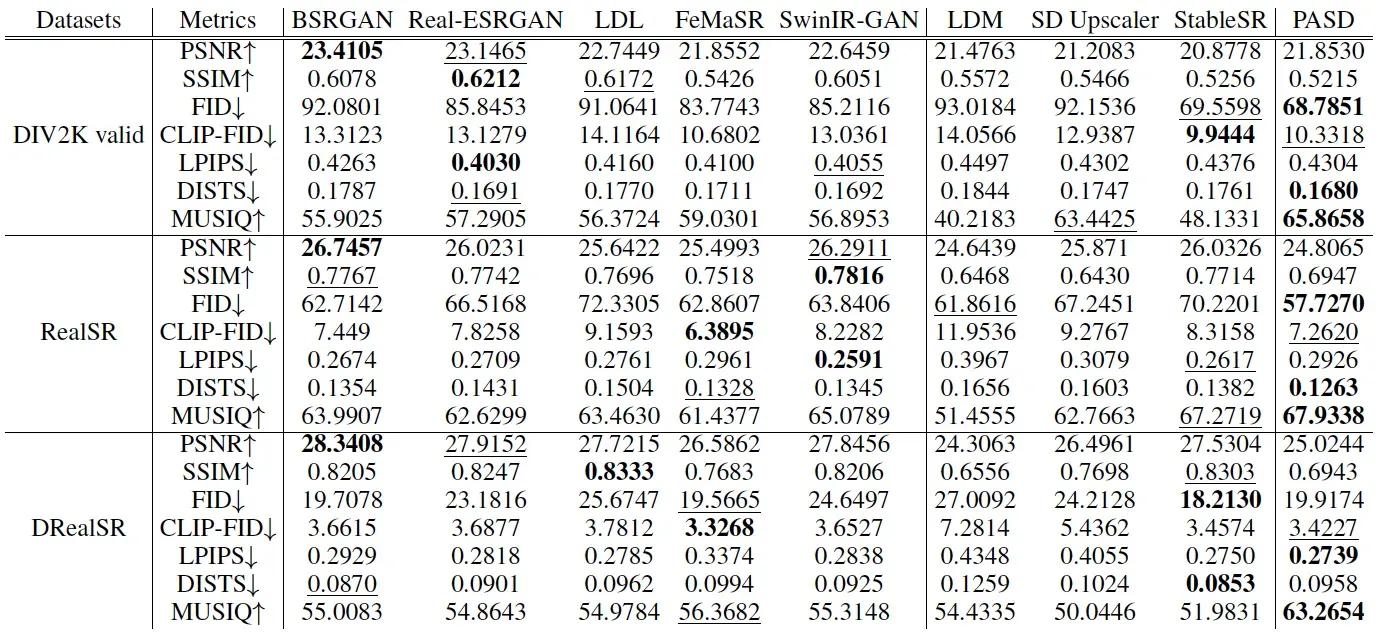
图像超分辨率
我们在多个合成和采集的benchmark上验证了我们的算法,在多项指标上有着SOTA的表现:
在视觉对比实验中也有类似的发现:

自定义风格化
除了超分辨和修复任务之外,我们还发现,通过切换基模,我们的算法能够方便的实现任意的风格变换:

这本质上是把Image-to-Image mapping与stylization的生成能力分开,我们引入的分支网络解决pixel-wise的image-to-image mapping,而基模解决stylization的生成。这打开了图像风格化的一个全新思路。
图像上色
因为我们提出的算法本质上是一个Pixel-Aware的图像翻译,因此它适合于任意的相关任务,包括图像上色等。我们也在图像上色任务中进行了训练,初步的实验也显示了优于SOTA的效果:

参考文献
Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. Arxiv. 2021.
Lvmin Zhang and Maneesh Agrawala. Adding Conditional Control to Text-to-Image Diffusion Models. Arxiv. 2023.
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models. Arxiv. 2023.
Wang, Jianyi and Yue, Zongsheng and Zhou, Shangchen and Chan, Kelvin CK and Loy, Chen Change. Exploiting Diffusion Prior for Real-World Image Super-Resolution. Arxiv. 2023.
视觉算法招募
长期开放视觉算法实习生和正式员工岗位,欢迎添加微信(309107918)联系!
关于我们:通义开放视觉智能是阿里巴巴应用视觉能力研发和开放中心,在视觉感知理解和视觉生成编辑两大技术方向上研发并开放了数以百计的视觉能力、模型及实用套件;并将视觉各领域、应用场景的大模型服务,通过通义万相、ModelScope等开放给开发者和各行业,持续推进视觉技术的应用创新和产品研发,从而带来规模化的视觉AI用户生态及云智能服务价值。
文章出处登录后可见!