文章目录

LLaMA
与原始transformer的区别:
预归一化[GPT3]。为了提高训练稳定性,对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。使用了Zhang和Sennrich(2019)引入的RMSNorm规范化函数。
SwiGLU激活功能[PaLM]。用Shazeer(2020)引入的SwiGLU激活函数取代了ReLU非线性,以提高性能。论文使用
的尺寸,而不是PaLM中的4d。
旋转嵌入[GPTNeo]。删除了绝对位置嵌入,而是在网络的每一层添加了Su等人(2021)引入的旋转位置嵌入(RoPE)。
论文: LLaMA: Open and Efficient Foundation Language Models
论文解读: LLaMA:开放高效的基础语言模型(Meta AI-2023)
相关GitHub
-
llama构建本地知识库问答https://github.com/jerryjliu/llama_index
-
中文LLaMA模型https://github.com/ymcui/Chinese-LLaMA-Alpaca
在原版LLaMA扩充了中文词表并使用了中文数据进行二次预训练
开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型
开源了使用中文文本数据预训练的中文LLaMA以及经过指令精调的中文Alpaca
目前已开源的模型版本:7B(基础版、Plus版)、13B(基础版、Plus版)、33B(基础版) -
LLaMA增量预训练、有监督微调、RW、RLHF https://github.com/hiyouga/LLaMA-Efficient-Tuning
-
基于中文医学知识的LLaMA微调模型https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese
Alpaca
Alpaca是Stanford用52k指令数据微调LLaMA 7B后得到的预训练模型,作者声称在单轮指令执行的效果上,Alpaca的回复质量和openai的text-davinci-003相当,但是Alpaca的参数非常少(微调一个7B的llama需要在8张A100 80G上训练3个小时,花费至少100美元)。
官方博客介绍: Alpaca: A Strong, Replicable Instruction-Following Model
解读: Stanford Alpaca (羊驼):ChatGPT 学术版开源实现
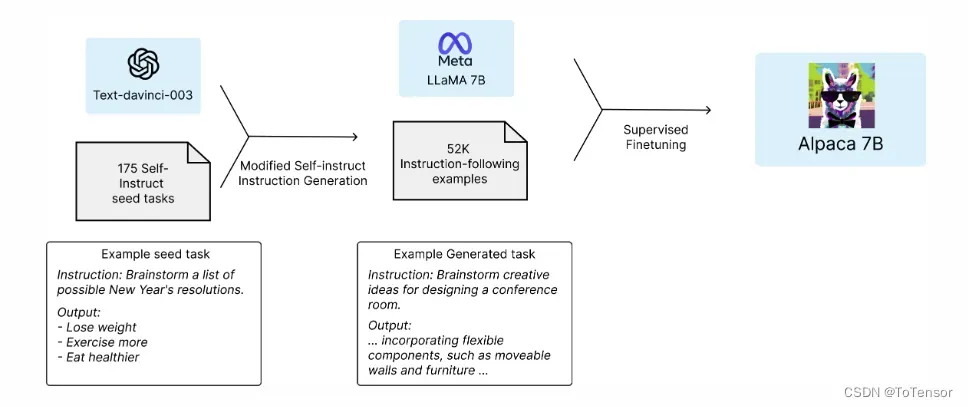
上图分别举例了种子数据和生成任务样例数据。
训练Alpaca全流程:
- 首先,基于175个人工编写的指令-输出对,作为self-instruct的种子集;
- 基于种子集,提示text-davinci-003生成更多的指令;
- 优化self-instruct:简化生成pipeline,大幅降低成本;
- 使用openai api生成52k不重复的指令和对应输出,成本低于500美元;
- 使用huggingface框架来微调llama模型。过程中,使用 fully sharded data parallel和mixed precision training两项技术;
相关GitHub
- Alpaca-LoRAhttps://github.com/tloen/alpaca-lora
- 中文Alpaca模型https://github.com/ymcui/Chinese-LLaMA-Alpaca
该中文Alpaca模型其实就是SFT后的中文LLaMA - 用清洗后的高质量数据微调出来的alpacahttps://github.com/gururise/AlpacaDataCleaned
Vicuna
Vicuna-13B是在LLaMa-13B的基础上使用监督数据微调得到的模型,数据集来自于ShareGPT.com产生的用户对话数据,共70K条。ShareGPT是一个ChatGPT数据共享网站,用户会上传自己觉得有趣的ChatGPT 回答。使用 GPT-4 作为判断的初步评估表明,Vicuna-13B 达到了 OpenAI ChatGPT 和 Google Bard 90% 以上的质量,同时在>90%的情况下优于 LLaMA 和 Stanford Alpaca 等其他模型。训练 Vicuna-13B 的费用约为300美元。
官方介绍: Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
解读: 大模型也内卷,Vicuna训练及推理指南,效果碾压斯坦福羊驼
Vicuna 的代码基于 Stanford Alpaca ,并额外支持多轮对话。 并且使用了与斯坦福羊驼(Stanford Alpaca)类似的超参数。
训练过程:
首先,研究人员从 http://ShareGPT.com(一个供用户分享 ChatGPT 对话内容的网站)收集了约 7 万个对话,并增强了 Alpaca 提供的训练脚本,以更好地处理多轮对话和长序列。训练是在一天内通过 8 卡 A100 GPU 配合 PyTOrch FSDP 进行的full fine-tune。为了提供演示服务,Vicuna研究人员建立了一个轻量级的分布式服务系统,创建了八个问题类别(如:角色扮演、编码/数学任务等)的 80 个不同问题,利用 GPT-4 来判断模型输出,借此对模型质量做初步评估。为了比较两个不同的模型,Vicuna研究人员将每个模型的输出组合成每个问题的单个提示。 然后将提示发送到 GPT-4,GPT-4 评估哪个模型提供更好的响应。
相关Github
- Chinese-Vicuna https://github.com/Facico/Chinese-Vicuna
- 官方Vicunahttps://github.com/lm-sys/FastChat
Vicuna 局限性
研究人员指出,与其他大语言模型类似,Vicuna也存在着一定的局限性。
比如,Vicuna在涉及编程、推理、数学以及事实准确性的任务上表现不佳。
此外,它也没有经过充分优化以保证安全性或减轻潜在的毒性或偏见。
Koala
估计是因为骆驼科的名字不够用了, 所以用其他动物的名称来命名
一张图解释:
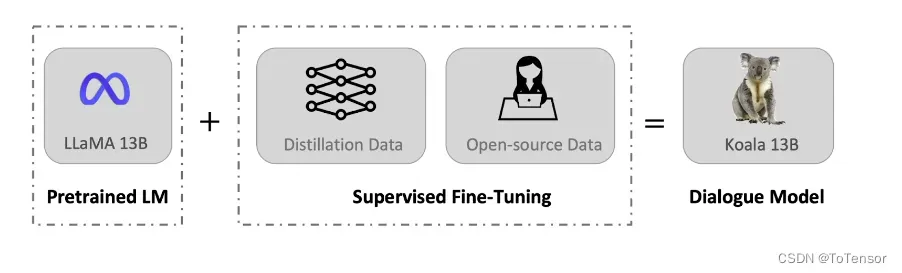
官方博客介绍: Koala: A Dialogue Model for Academic Research
解读: 130亿参数,8个A100训练,UC伯克利发布对话模型Koala
与 Vicuna 类似,Koala 也使用从网络收集的对话数据对 LLaMA 模型进行微调,其中重点关注与 ChatGPT 等闭源大模型对话的公开数据。
研究团队表示,Koala 模型在 EasyLM 中使用 JAX/Flax 实现,并在配备 8 个 A100 GPU 的单个 Nvidia DGX 服务器上训练 Koala 模型。完成 2 个 epoch 的训练需要 6 个小时。在公共云计算平台上,进行此类训练的成本通常低于 100 美元。
研究团队将 Koala 与 ChatGPT 和斯坦福大学的 Alpaca 进行了实验比较,结果表明:具有 130 亿参数的 Koala-13B 可以有效地响应各种用户查询,生成的响应通常优于 Alpaca,并且在超过一半的情况下与 ChatGPT 性能相当。
Baize (白泽)
论文: Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
官方Github:https://github.com/project-baize/baize-chatbot
解读: 用ChatGPT训练羊驼:「白泽」开源,轻松构建专属模型,可在线试玩
在新研究中,作者提出了一个自动收集 ChatGPT 对话的流水线,通过从特定数据集中采样「种子」的方式,让 ChatGPT 自我对话,批量生成高质量多轮对话数据集。其中如果使用领域特定数据集,比如医学问答数据集,就可以生成高质量垂直领域语料。
白泽提出的训练方法。通过利用 ChatGPT 的功能自动生成高质量的多轮聊天语料,让 ChatGPT 与自己进行对话,模拟用户和 AI 的响应。
为了在资源匮乏的环境中微调大语言模型,作者采用了有效利用计算资源的参数高效调优方法。该策略使最先进的语言模型保持了高性能和适应性。白泽改进了开源大型语言模型 LLaMA,通过使用新生成的聊天语料库对 LLaMA 进行微调,该模型在单个 GPU 上运行,使其可供更广泛的研究人员使用。
自聊天的过程是训练内容的基础,为了让 ChatGPT 能够有效生成数据,研究人员应用一个模板来定义格式和要求,让 ChatGPT 的 API 持续为对话双方生成抄本,直到达到自然停止点。对话以「种子」为中心,「种子」可以是一个问题,也可以是设置聊天主题的关键短语。
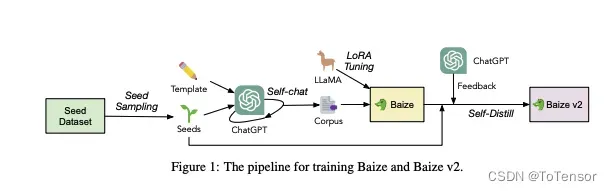
其实就是用LORA微调的LLaMA
骆驼(Luotuo)
这个技术文档将介绍我们昨天训练完成的“骆驼”中文模型。这个模型是在Meta开源的LLaMA基础上,参考Alpaca和Alpaca-LoRA两个项目,对中文进行了训练,并且取得了初步的效果。
官方Github: https://github.com/LC1332/Luotuo-Chinese-LLM
解读: 【开源GPT】三位华人小哥开源中文语言模型“骆驼”,单卡即可完成训练部署,花费几百训练自己的中文聊天模型
没啥好讲的了, 老套路, 基于LLaMA的SFT
BELLE
为了推动开源大语言模型的发展,大家投入了大量精力开发能够类似于ChatGPT的低成本模型。 首先,为了提高模型在中文领域的性能和训练/推理效率,我们进一步扩展了LLaMA的词汇表,并在34亿个中文词汇上进行了二次预训练。
此外,目前可以看到基于ChatGPT产生的指令训练数据方式有:1)参考Alpaca基于GPT3.5得到的self-instruct数据; 2)参考Alpaca基于GPT4得到的self-instruct数据;3)用户使用ChatGPT分享的数据ShareGPT。 在这里,我们着眼于探究训练数据类别对模型性能的影响。具体而言,我们考察了训练数据的数量、质量和语言分布等因素,以及我们自己采集的中文多轮对话数据,以及一些公开可访问的高质量指导数据集。
为了更好的评估效果,我们使用了一个包含一千个样本和九个真实场景的评估集来测试各种模型,同时通过量化分析来提供有价值的见解,以便更好地促进开源聊天模型的发展。
官方Github: https://github.com/LianjiaTech/BELLE
解读: 中文对话大模型BELLE全面开源!(附:数据+模型+轻量化)
Guanaco
Guanaco是一个基于目前主流的LLaMA-7B模型训练的指令对齐语言模型,原始52K数据的基础上,额外添加了534K+条数据,涵盖英语、日语、德语、简体中文、繁体中文(台湾)、繁体中文(香港)以及各种语言和语法任务。丰富的数据助力模型的提升和优化,其在多语言环境中展示了出色的性能和潜力。
GitHub:https://github.com/Guanaco-Model/Guanaco-Model.github.io
最近华盛顿大学提出QLoRA,使用4 bit量化来压缩预训练的语言模型,然后冻结大模型参数,并将相对少量的可训练参数以Low-Rank Adapters的形式添加到模型中,模型体量在大幅压缩的同时,几乎不影响其推理效果。该技术应用在微调LLaMA 65B中,通常需要780GB的GPU显存,该技术只需要48GB,训练成本大幅缩减。
QLoRA解读: 开源原驼(Guanaco)及背后的QLoRA技术,将微调65B模型的显存需求从780GB以上降低到48GB以下,效果直逼GPT-4,技术详解
LLaMA子孙模型是在太多了, 懒得再一一列举了, 在找资料的过程中, 发现有个Github仓库涵盖了大多数开源LLM, 真的太妙了,链接: https://github.com/chenking2020/FindTheChatGPTer
文章出处登录后可见!