作者主页:paper jie_博客
本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。
本文录入于《MySQL》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造,将MySQL基础知识一网打尽,希望可以帮到读者们哦。
其他专栏:《算法详解》《C语言》《javaSE》《数据结构》等
内容分享:本期将会分享MySQL表的索引与事务
目录
索引
什么是索引
索引是一种特殊的文件,包含对数据表中所有记录的引用指针.可以对表中的一列或多列创建索引,还可以指定索引,个类索引都会有各自的数据结构来实现
作用
数据库中的表,数据,索引他们的关系就是字典,字典中的字,字典的目录关系
索引所起到的作用就是帮助数据快速定位,检索数据
索引对于提高数据库查找的性能有很大的帮助
索引的使用
这里,我们要知道, 创建一些约束,如:primary key, unique, foreign key 时,会自动创建索引.
查看索引
show index from 表名;栗子:
mysql> show index from student;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student | 0 | PRIMARY | 1 | id | A | 8 | NULL | NULL | | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+创建索引
对于非主键,唯一约束,外键的字段,可以创建普通索引
create index 索引名 on 表名(字段);栗子:
mysql> show index from course2;
Empty set (0.00 sec)
mysql> create index idx_id on course2(id);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from course2;
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| course2 | 1 | idx_id | 1 | id | A | 3 | NULL | NULL | YES | BTREE | | |
+---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+删除索引
drop index 索引名 on 表名;栗子:
mysql> drop index idx_id on course2;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0索引的利弊与场景使用
索引它也不是完全有利的,索引是一种数据结构,它也会占一定的磁盘空间,有额外的开销.且在改动数据的时候,索引也需要更新,这也会占用一定的时间开销.所以我们在使用索引的时候需要考虑以下几点:
1. 数据量较大,且经常对这些列进行查询
2. 该数据库中的数据修改或新增操作频率低
3. 索引会占据额外的磁盘空间
*索引使用的数据结构*
在数据库中,索引使用的数据结构是B+树,而B+树是有B树演变过来的
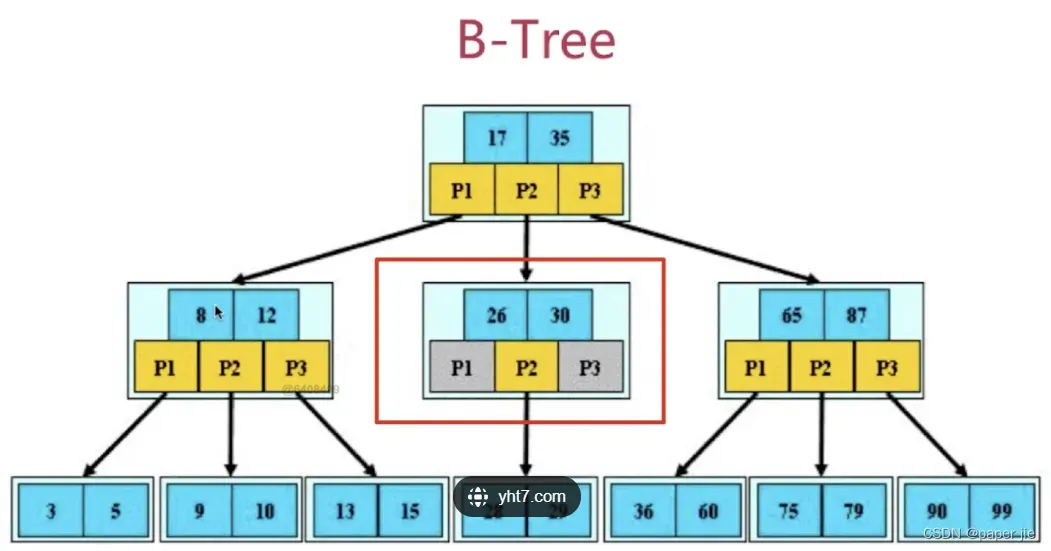
B树
特点:
B树它是一个N叉搜索树
它的节点上的值是有序的
假设一个节点上有N个key,这N个值又会划分出N+1个区间
好处:
它树的高度比二叉搜索树降低了很多
在使用B树查询的时候,一个结点比较的次数虽然多了,但同一个节点的key只需要一次硬盘IO,而比较又是在内存中进行,速度就快了不少
B树图形:
B+树
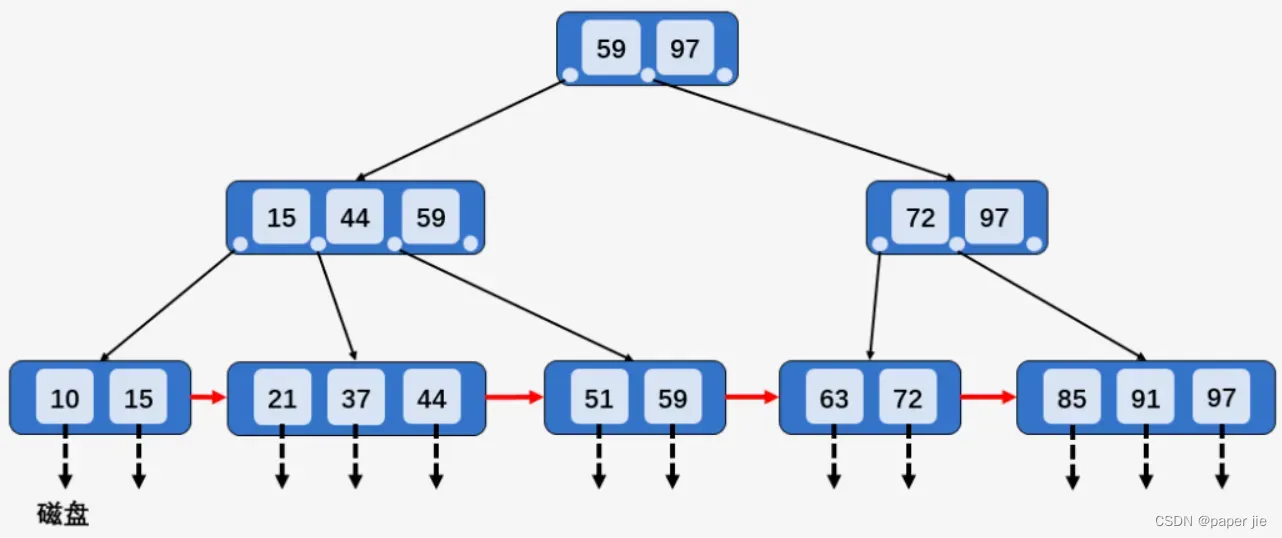
特点:
是在B树基础上改动,仍然是N叉搜索树,仍然是有序的
假设一个节点上有N个key值,则N个值有N个区间
且每一个节点的最大值会重复出现在子结点中
叶子节点使用了链表将它们串起来
好处:
叶子节点存有数据的全集,比如查询id >=4 and id<= 10,需要从根节点开始一直找到叶子节点的4,然后开始沿着链表遍历到10.就不需要回溯了
针对B树的查询时间是稳定的.查询任何数据都是需要从根结点查询到叶子节点的,过程中的IO是一样的
使用B+树结构,就只需要在叶子节点存储数据集,其他节点存储比较的值就行,这要会节约大量的空间
B+树图形:
事务
什么是事务
事务就是指逻辑上的一组操作,将这组操作捆绑在一起,要么全部失败,要么全部成功.在不同的环境中,都会有事务.数据库中对应的就是数据库事务.
为什么要有事务
这很好理解,这里举一栗子:
小明有2000块钱,小花有1000块钱.小明这时需要向小花转账500块钱,小花需要接受500块钱,对应的MySQL语句就是:
updata user set money = money - 500 where name = '小明';
updata user set money = money + 500 where name = '小花';这时第一条语句执行了,但是在执行第二条语句前服务器挂了.这时就会发生: 小明的账号少了500,而小花的账号却没有多500块,这钱就不翼而飞了.
因此就需要事务来控制这些语句,要是都执行,要么都失败.
事务的使用
1. 开始事务: start transaction
2. 执行多条sql语句
3. 回滚或提交: rollback / commit
这里rollback是全部失败, commit是全部成功
*事务的特性*
原子性
通过事务,将多个操作打包到一起.(失败都失败,成功都成功)
一致性
相当于原子性的延续,数据库中出了问题,就不会出现上面”钱消失了”的情况
持久性
事务的修改,都是会写入硬盘的,不管是电脑关机还是重启系统丢不会丢失
*隔离性*
多个事务并发执行的时候就会带来一些问题.这里就可以通过隔离性来对这里的问题进行处理~(这里就需要看你是更加注重准确还是速度快)
这里有几个经典的bug:
经典bug1: 脏读
当有两个事务1,2. 事务1在修改某个数据,但是还没有提交. 事务2读取到了这个数据,结果事务1后序又修改了这个数据. 这就是一个脏的数据.(因为一个事务里有多条操作,可以多次修改).
这时我们就需要通过给操作加锁来解决问题.(核心就是降低并发程度)
这就好比上厕所把门锁了,别人就看不到你上厕所了
经典bug2: 不可重复读
有事务1,2. 事务1先修改数据(这里加锁了), 此时事务2想读这个数据,就需要等事务1提交. 等事务1提交后,事务2就开始读数据(这里事务2会多次读取这个数据),结果后面来了一个事务3有修改了这个数据,这就导致事务2在读的过程中两次读到的结果不一样.这就是写加锁了,但是读没加锁.所以就出现了读数据的时候事务3又写了.
这就好比在淘宝上买东西第一遍我们看到的20块钱,结果在付钱的时候看到的是40块钱.
解决方式就是给读也加锁~
经典bug3: 幻读
事务1,2 事务1修改数据,提交. 事务2开始读数据,这时事务3新增了其他的数据,此时事务2读出来的结果集就不同了
这就好比在使用count()聚合函数一样,第一次是5,第二个是10
解决方式就是:串行化,不再进行任何的并发
注意
以上这几种是否是bug其实还是看情况而定,根据需要的是准确性还是速度而定~
文章出处登录后可见!