最近读了DeepWalk和Node2vec这两篇图学习的经典文章,对自己的笔记进行了整理。
DeepWalk算法笔记
应用背景
图嵌入(Graph Embedding)是一种将图数据(通常为高维稀疏的矩阵)映射为低维稠密向量的过程,能够很好地解决图数据难以高效地作为传统机器学习算法输入的问题。图嵌入是依据图地属性将图转换为向量或向量集。嵌入应该捕获图的拓扑结构、顶点和顶点的关系以及关于图、子图和顶点的其他相关信息。将更多的属性嵌入节点表示向量可以在下游任务中获得更好的结果。
DeepWalk是在2014年KDD会议提出的一种图嵌入算法,它将自然语言处理领域的经典方法Word2vec迁移到图地节点嵌入领域,Word2vec的思想是,给定两个单词,它们是否有在同一个句子中出现过?基于此评估两个单词的相似性,生成单词的嵌入表示(Word Embedding),因为计算机是不认识单词的,但是计算机认识向量,这就是embedding的必要性。Word2vec已被证明在捕获人类语言的语义和句法结构上非常成功。
DeepWalk将节点视为单词,将在图中的随机游走序列视为句子,训练Word2vec模型生成图节点的嵌入表示(Graph Embedding)。
功能描述
DeepWalk将一个图作为输入,对每个节点产生一个嵌入表示(向量)作为输出。论文给出了该算法应用于经典的空手道网络数据集的结果如图1所示。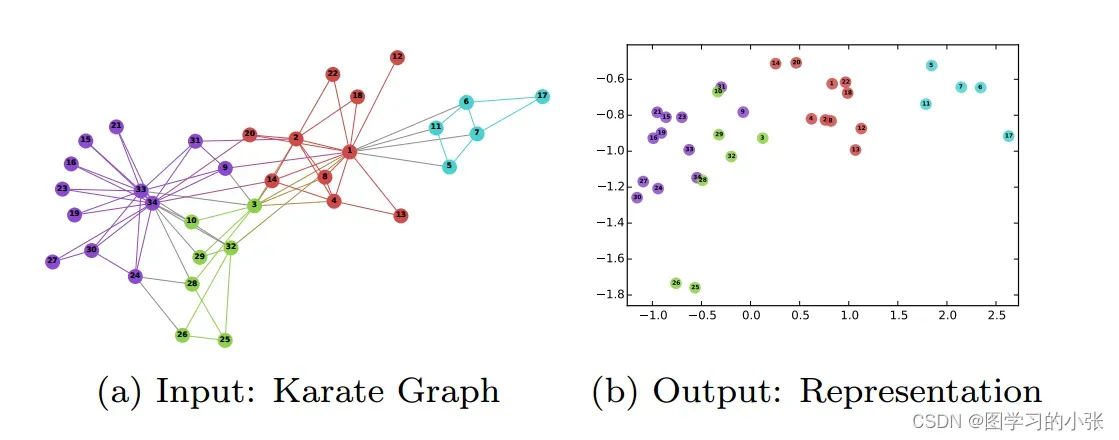
Karate Graph(空手道图)是图学习中的经典数据集,类似于机器学习中的鸢尾花数据集。图1(a)表示34个人组建的空手道俱乐部的无向图,图中的连接表示两个人相互认识,后续分成了不同颜色的派系。图1(b)是经过DeepWalk算法编码后的产生的d维向量(在本数据集上是二维),它会将图数据的每一个节点编码为一个二维向量,可视化嵌入空间,原图中相近的节点嵌入后依然相近。该结果说明DeepWalk生成的embedding隐式包含了图中的社群、连接、结构等信息。
DeepWalk会将复杂的图转换成一个embedding向量集,然后就可以方便地用机器学习算法对该向量集进行分类或聚类。它的编码和嵌入属于无监督过程,没有用到任何的标记信息,只用到了网络的连接、结构、社群属性的信息,因为随机游走不会考虑节点的特征和类别信息,它只会采样图节点之间的顺序、结构信息。
此外,文章认为DeepWalk学到的embeddings应该具有下列特性:
- 适应性(Adaptabilty):真实网络在持续地演化,新的节点和关系出现时不需要再重新训练整个网络,而是能够增量或在线训练。换句话说,网络的拓扑结构随着网络新的节点和连接动态变化。
- 社区意识(Community aware):应该反映社群的聚类信息,如空手道数据集(图1)所示,属于同一个社区的节点有着相似的表示,网络中会出现一些特征相似的点构成的团状结构,这些节点表示成向量后也必须相似。这允许在具有同质性的网络中进行泛化。
- 低维(Low dimensional):当标记数据稀缺时,低维模型可以更好地扩展并加速收敛和推理(防止过拟合)。即每个顶点的向量维度不能过高。
- 连续(Continuous):低维向量应该是连续的,每个元素的细微变化都会对结果有影响,并且能拟合平滑的决策边界,从而实现鲁棒性更强的分类任务
基本概念
随机游走(Random Walks)
假设将一个起始点的随机游走表示为,对应的随机过程定义为:,对应的随机过程定义为:
其中,k表示随机游走的第k步,
表示起始点,之后的第k+1节点是从第k个节点的邻居节点中随机选择一个,这样生成的随机游走序列属于均匀随机游走。
在DeepWalk算法的开始,我们会对图上的所有节点生成随机游走序列组成我们的语料库(对应word2vec),通过一连串的随机游走序列提取网络的信息。除了捕获社群信息外,随机游走还有其它两个比较好的优点:支持并行采样和在线增量学习(迭代学习不需要全局重新计算)。
幂律分布(Connection: Power laws)
在图学习中,幂律通常被用来描述节点度的分布,表明少数节点具有非常高的度,而大多数节点的度较低。这与文章中的单词分布的规律相似:少部分单词使用量非常多,而大部分单词使用量非常少。
图2展示了幂律分布现象,图2(a)是在一系列随机游走的分布图,横轴表示被媒体提及次数,纵轴表示用户节点的个数。可以这样通俗的理解:在视频网站的用户构成的图数据集中,只有小部分用户(网红、大V)的粉丝量(度数)是巨大的,而大多数用户都没有多少粉丝(度数很小)。图2(b)是英文维基百科上的10万篇文章的单词幂律分布图。横轴表示某个单词被采样到的次数,纵轴表示单词数,比如the\an\we这样的常用词出现较多,大多数单词的出现次数都很少。
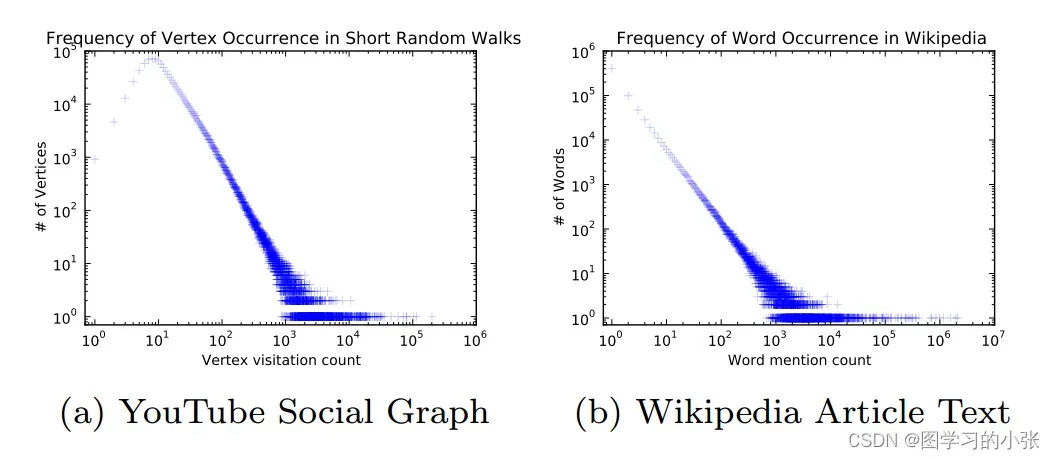
自然语言中的词频遵循幂律分布,真实的社交网络中的节点度数也存在相同的特性。而语言建模技术可以对这种分布行为进行有效的建模。这体现了DeepWalk的核心思想:随机游走的分布规律与NLP中句子序列在语料库中出现的规律有着类似的分布特征,那么就可以将NLP中生成词嵌入的模型用在图节点嵌入的任务中。
词嵌入学习的经典方法(Word2vec)
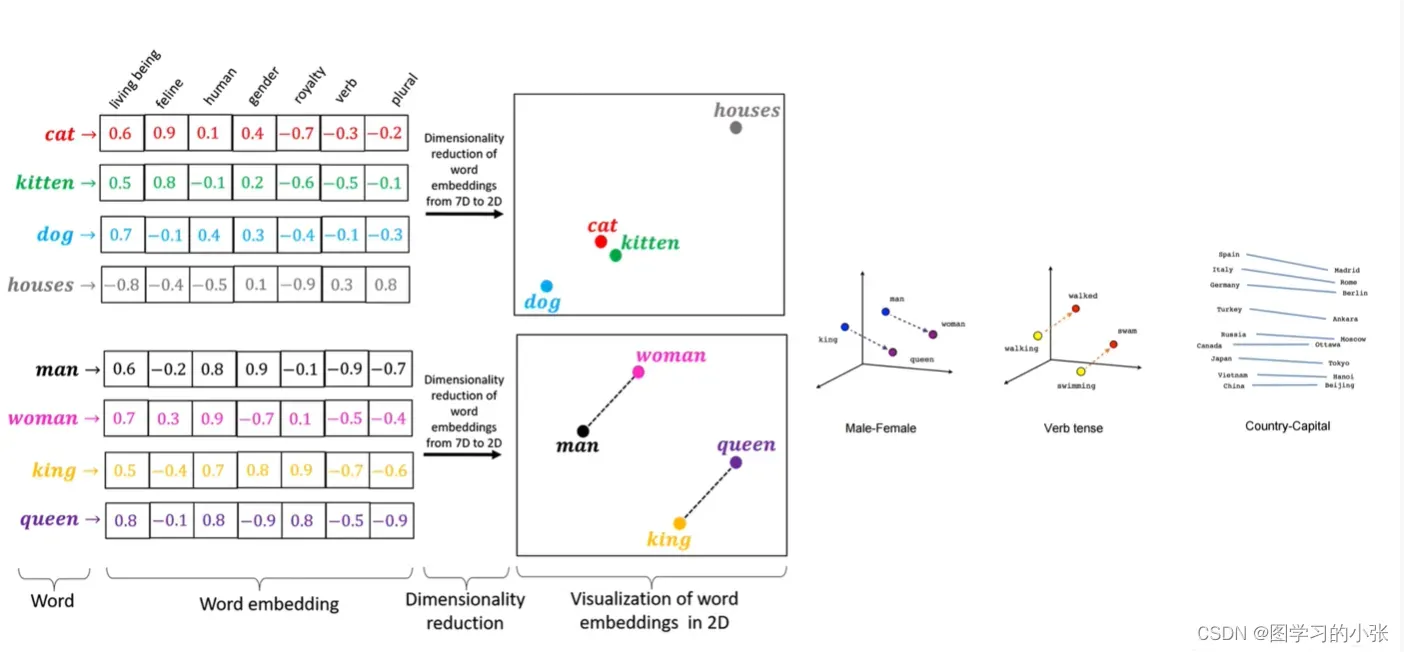
图3展示了词嵌入学习的效果,对于输入的每个单词,Word2vec会得到一个单词的向量表示,我们把得到的嵌入表示可视化到嵌入空间中,可以看到cat,dog等表示动物的单词距离就比较近,而house跟它们的距离比较远;man和woman、king和queen之间则是平行的关系。即语义相近的单词嵌入后依然相近。
DeepWalk模型与损失函数推导
传统的语言模型要解决的问题是:由上文的n-1个词预测第n个词,那模型的任务应该是最大化预测第n个词成功的概率,即:
如果我们想把传统的语言模型推广到图的随机游走,将一系列的随机游走路径当作句子,将路径上的每个节点当作单词,有:
但是这样我们这个问题还是无法解决,因为我们不是用节点本身做预测,而是用节点的embedding。因此,在算法的开始,我们首先需要定义一个映射函数
:
其中,V表示节点集,R是一个|V|×d的矩阵,即对于V中的每一个节点,都会映射到R中的一个d维向量,实际上就是初始化一个embedding矩阵。有了这个映射函数,公式(3)就变成了:
但是,随着随机游走长度的增加,计算这个目标函数就变成了n个条件概率的连乘,即:
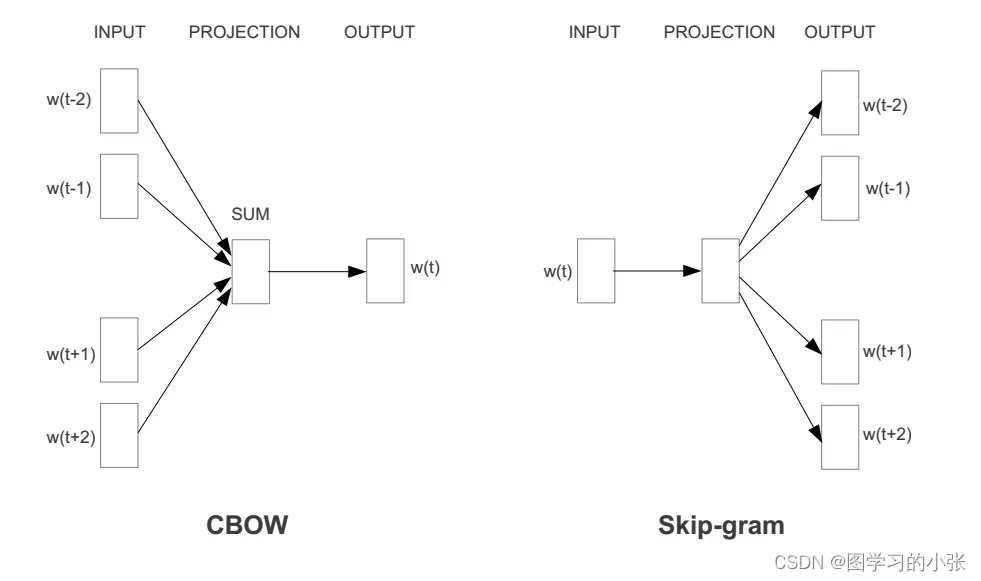
最终这个概率会变得很小,让计算这个目标函数变得不可行。我们上述讨论的推广都是在传统的语言模型的基础上,而2013年的Word2vec提出了一种传统语言建模的推广,把模型转变成了一种自监督学习的场景,即用周围上下文预测中间缺失的词(CBOW),也可以用中心词预测周围词(Skip-Gram)。自监督学习场景指的是,对于CBOW模型,输入上下文时,周围词就是标签;对于Skip-Gram模型,输入中间词,周围词就是标签。
Deepwalk使用的Skip-Gram模型,并且移除了Skip-Gram模型对输出周围词顺序的限制。于是,我们希望在输入中心词(节点)时,输出其周围词(节点)的似然概率越大越好,即:
是
节点的embedding,我们希望通过它预测他的周围节点,我们把这个式子推广为我们的损失函数(我们希望它越小越好),即(Deepwalk(Skip-Gram模型)):
通过这个损失函数,我们就能不断训练我们的模型更新矩阵
,最终使它收敛,此时我们就得到了训练好的embedding矩阵
,里面包含了对每一个节点形成的维度为d的嵌入表示。
在我们的模型训练过程中,每次只需要输入一个节点,用于预测它的周围节点(随机游走序列中),这样的话我们的模型就很小。并且Deepwalk模型取消了这些节点的顺序的分别,因为在图的随机游走中这个顺序是没有什么意义的。通过上述方法,把节点嵌入问题转化为了优化公式(8),这样就可以实现我们的一个目标:具有相同邻居的节点就会获得相似的表示(在原图聚类中的社群编码后仍然是一个社群)。
算法描述与解释(伪代码)
与word2vec中的语言模型一样,Deepwalk算法的输入也需要一个语料库(对应一系列随机游走序列)和词汇表(对应节点集)。我们通过随机游走捕获全图结构信息(盲人摸象),这样我们在开始时可以知道全图信息,也可以不知道全图信息,这不是一个必要的输入。
在算法的开始,我们还需要定义一些参数:
其中,w是训练Skip-Gram模型时左右窗口大小的参数,即对于每个节点,我们分别使用它预测周围多少个节点的嵌入表示,d是最终生成的节点嵌入embedding的维度,t是随机游走最大长度。
Deepwalk算法的伪代码如下:


在Skip-Gram算法中,对于给定的的嵌入向量,我们希望在随机游走中最大化它邻居的概率(第三行计算损失函数)。因此,它也会遇到和Word2Vec中相同的问题。当节点较多时,会造成数量极高的分类预测(比如社交网络中可能有上亿个节点),这使得计算
是不可行的,在配分函数的计算过程中,分母的归一化项太多无法直接计算。因此,为加快训练时间,Word2vec提出使用分层Softmax来近似概率分布,其原理如图7所示。
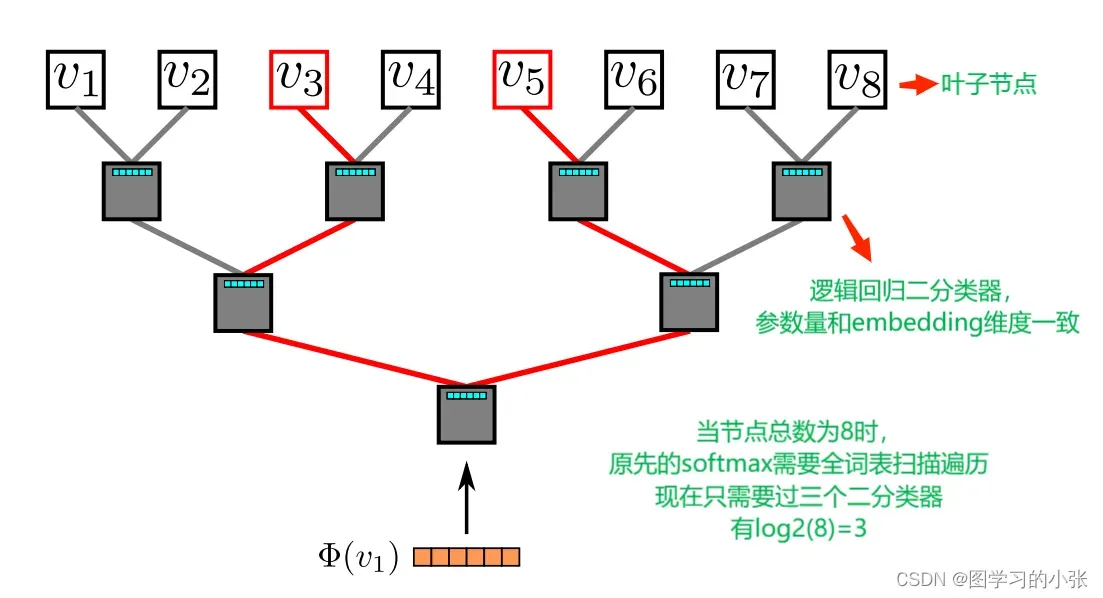
那么有:
现在
可以由分配给节点的父节点的二元分类器建模,有:
其中,
是节点的embedding,
是逻辑回归的权重,把这两个向量数量积的结果放到一个sigmod函数中计算后验概率,我们希望这两个向量积越大越好,根据sigmod函数的性质,这个积越大函数的结果就更接近1。这样,计算
的时间复杂度就从O(|V|)降到了O(log(|V|))。所以在DeepWalk中,其实是要训练两套权重,一个是N个节点的embedding(d维)矩阵,另一个是分层Softmax中N-1个逻辑回归二分类器的权重(每个逻辑回归权重的维度为d)。此外,我们可以为随机行走中的频繁节点分配更短的路径来进一步加快训练过程,霍夫曼编码就能很方便的做到这一点。
以上就是DeepWalk的整个流程,论文中用一张图对DeepWalk进行了概述,如图8所示。
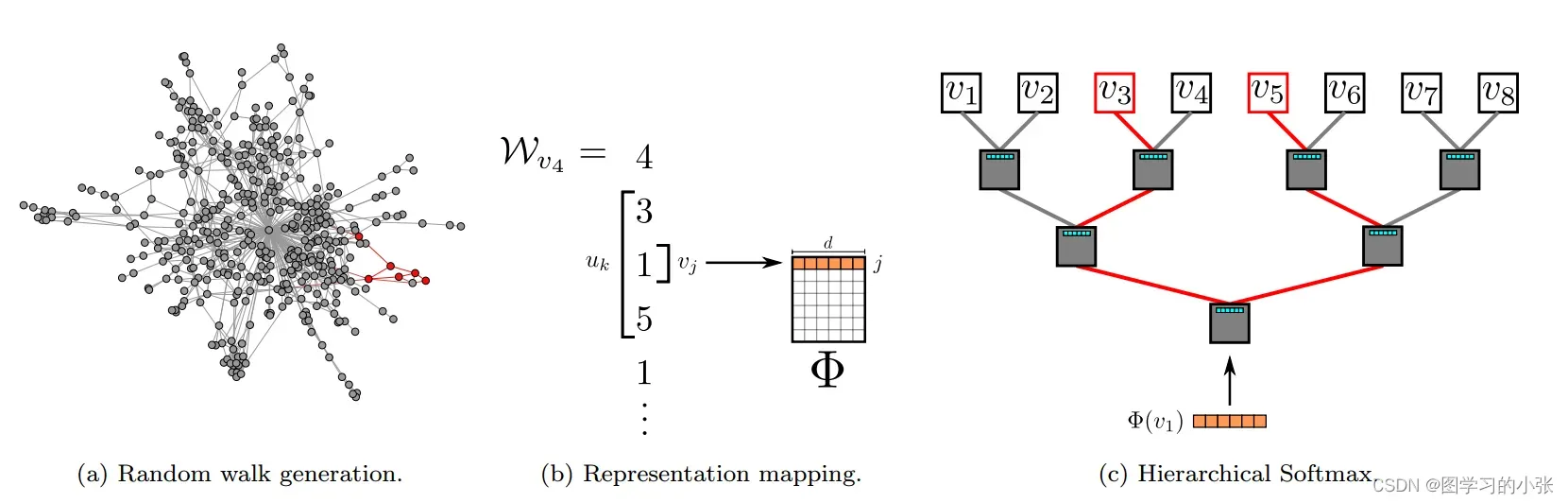
首先,图8(a)表示从图中随机游走采样出一个节点序列(红色标注);然后生成图8(b)所示的映射关系,表示4号节点,输入中心节点(
)来预测上文和下文的节点,每侧窗口宽度w=1,通过查表得到中心节点
映射对应的表示
;最后,将该中心词的向量输入到分层Softmax中(图8(c)),由于
和
都是标签,两条路径回各自计算损失函数,再各自优化更新,这里存在两套权重,分别是:N个节点的D维向量,N-1个逻辑回归(每个有D个权重),这两套权重会被同时优化。
时间复杂度分析
假设图结点数为N,连边数为M。DeepWalk主要包括随机游走采序列和Skip-Gram模型训练两部分。随机游走采序列用Alias Sampling方法来做离散概率分布采样可以实现O(1)采样时间复杂度,预处理时间复杂度为O(M)(m个数离散分布预处理复杂度为O(m),每个结点复杂度正比于该结点连边数,所有结点连边数共M)。假设游走长度为T,每个结点游走序列条数为L,则采样所有序列复杂度O(M)+O(N*T*L)。
接下来就是对所有的NL条序列用Skip-Gram模型来优化。假设窗口大小为K,滑动步长为1,则每条序列可以构造O((T-K+1)(K-1))=O(TK)个共现对,N*L条序列则为,O(N*L*T*K)个共现对,对每个共现对,中心结点预测上下文结点,用层次Softmax来优化的复杂度是O(log N)。假设迭代E个epoch,则总优化时间复杂度为: O(E* NLTK * log N)。
总时间复杂度:O(M) + O(NTL) + O(E * NLTK * log N)。L,T,K,E 通常都是比较小的常数。因此,可以认为时间复杂度为,O(M)+O(N)+O(N log N)。
此外,DeepWalk优化的时候可以并行,因此实际上速度还是很快的。
DeepWalk的改进算法(Node2vec)
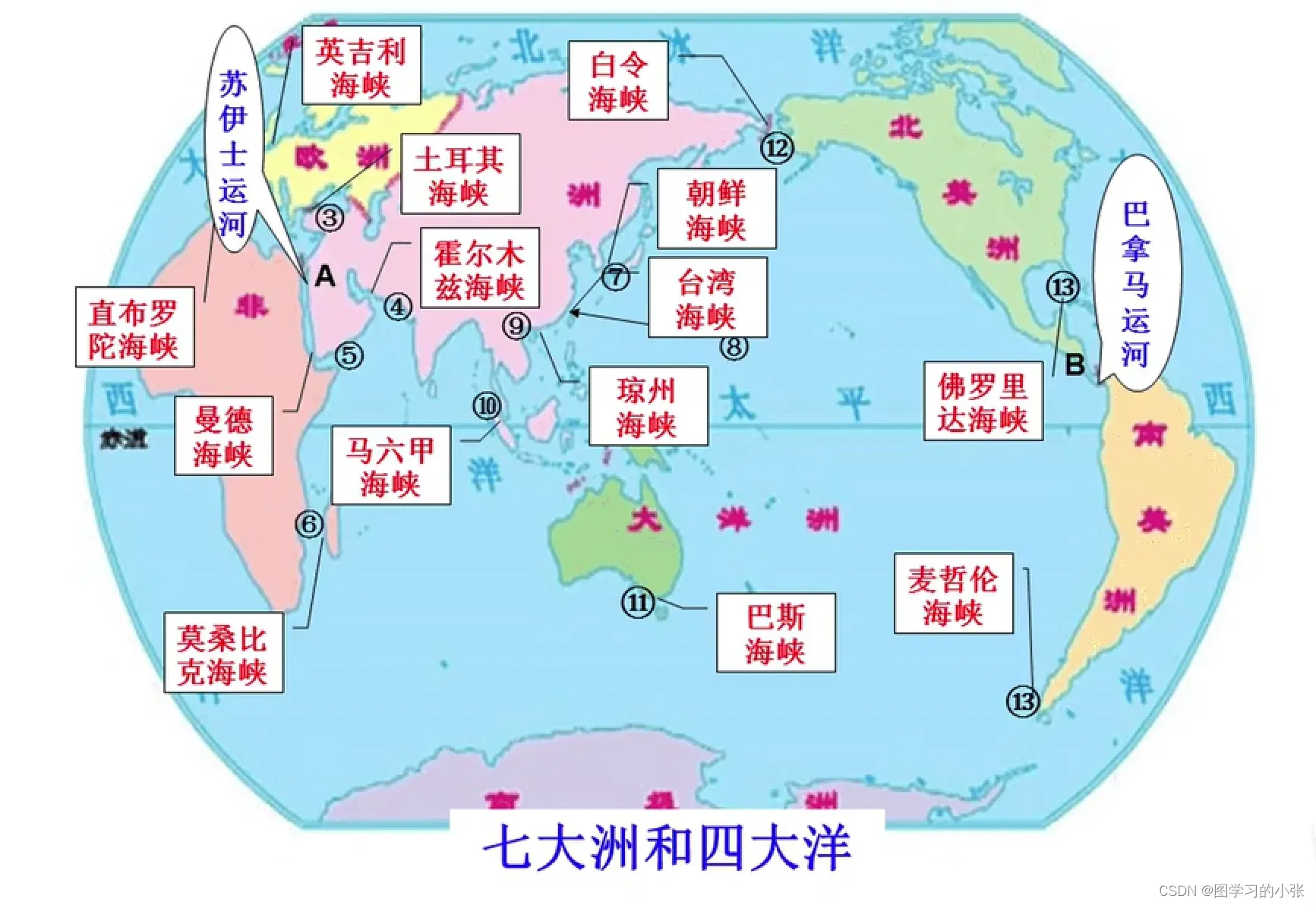
思考一下DeepWalk的特点:用在图数据上的完全随机游走,训练节点嵌入向量。那它有什么缺点呢?这样的嵌入表示仅能反映相邻结点的社群相似信息,无法反映节点的功能角色相似信息。举一个例子:对于一张世界地图如图9,苏伊士运河分开了非洲和亚洲,巴拿马运河分开了北美洲和南美洲,都属于大陆的分界线和交通要道。那他们应该是很相似的。但是他们的距离很远,如果把世界地图当作一张图,用DeepWalk生成这两个节点的嵌入表示,由于DeepWalk只能捕捉原图中相邻的节点信息,那它就无法把苏伊士运河和巴拿马运河在嵌入空间中嵌入到相近的位置。推广到其他任务上,对于图中距离很远,但是在结构、功能等相似的节点,无法捕捉这种相似性。
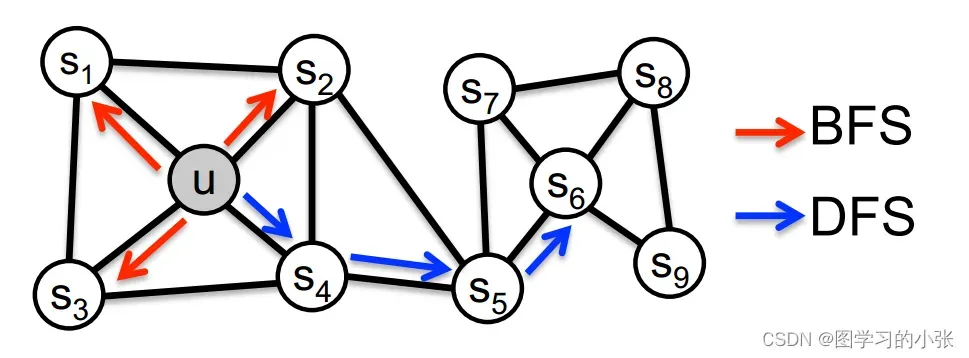
那这两种搜索策略分别对生成的嵌入表示造成了什么样的影响呢?一般来说,网络中节点上的预测任务经常依据两种相似性:同质性和结构等效。在同质性假设下,高度互联且属于相似网络集群或社区的节点应该紧密嵌入在一起(如图10中的节点
这两种相似性并不是不能共存的,在现实世界中,网络通常可以表现出这两种情况,其中一些节点表现出同质性,而另一些则反映结构等效。因此,Node2vec认为我们的算法应该足够灵活,要兼顾考虑到这两种情况,它提出通过设置两个权重p,q对搜索策略进行调节,更偏向DFS或是BFS。
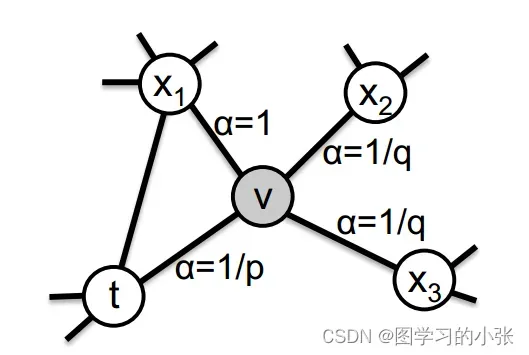
Deepwalk使用的是一阶随机游走的方式,所谓一阶随机游走,就是在随机游走序列时对下一个节点的选择只取决于当前节点,对于当前节点相连的所有节点,随机选择一个作为随机游走的下一个节点,而Node2vec是一种二阶随机游走,对下一个到达节点的选择不止取决于当前节点,还取决于当前节点的上一个节点,Node2vec设置了两个参数p,q来指导下一个节点的选择,其具体原理如图11所示。
文章出处登录后可见!