这是一篇效果极好的像素级跟踪的文章, 发表在ICCV2023, 可以非常好的应对遮挡等情形, 其根本的方法在于将2D点投影到一个伪3D(quasi-3D)空间, 然后再映射回去, 就可以在其他帧中得到稳定跟踪.
这篇文章的方法不是很好理解, 代码也刚开源, 做一下笔记备忘.
0. Abstract
传统的光流或者粒子视频跟踪方法都是用有限的时间窗口去解决的, 所以他们并不能很好的应对长时遮挡, 也不能保持估计的轨迹的全局连续性. 为此, 我们提出了一个完整的, 全局的连续性的运动表示方法, 叫做OmniMotion. 具体地, OmniMotion将一个视频序列表示成一个准-3D的规范量(quasi-3D canonical volume), 然后通过定义一个双射(也就是从平面空间到所谓的canonical的空间), 这样我们通过一个准3D空间, 就可以描述一个完整的运动(因为补偿了2D缺失的信息).
1. Method
由于对相关领域知识的匮乏, 先略过Introduction和Related Work部分, 先来看方法.
从整体流程上, OmniMotion将一整个视频序列作为输入, 同时还输入不太准确的带噪的运动估计(例如光流估计), 然后解出一个完整的, 全局的运动轨迹.
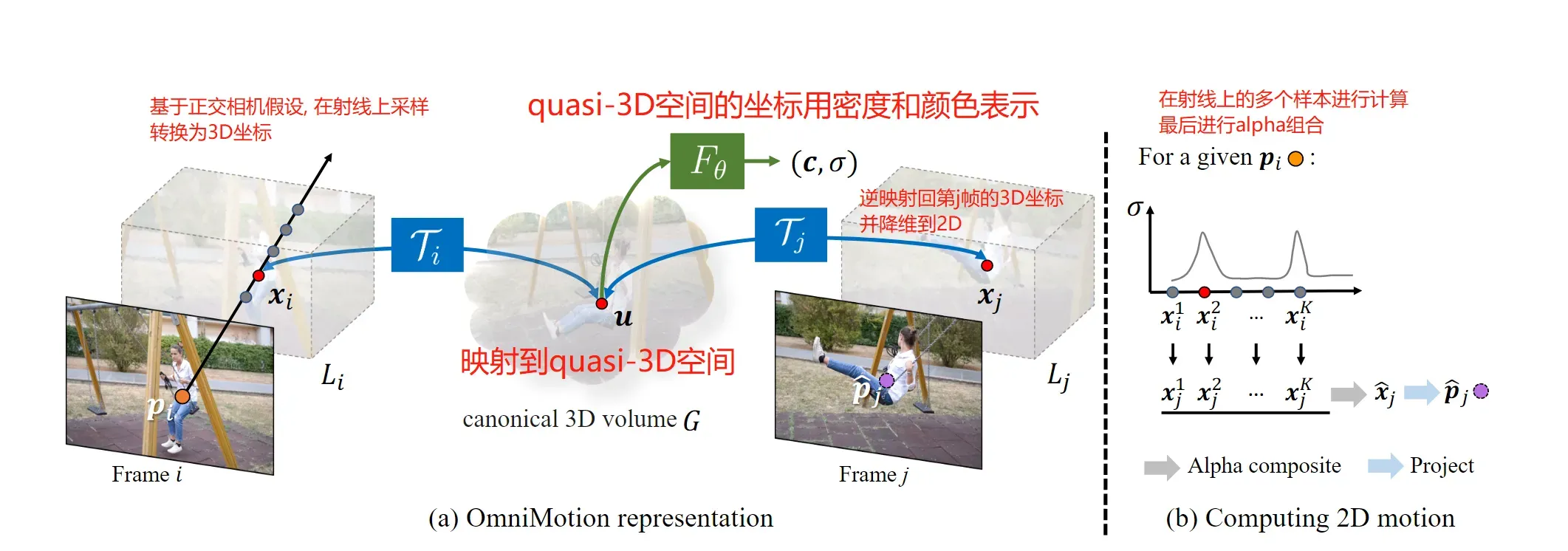
那么如何解决遮挡问题呢? 遮挡, 只是在2D的图像平面下遮挡了, 但是在3D信息中是可以恢复出来的. 为此, 我们将场景给投影到某个3D空间, 这个空间可以尽可能描述像素完整的运动. 比如说, 第帧的某个像素
, 给投影到这个3D空间变为
, 然后在第
帧我们再将这个
投射到2D平面, 就得到了对应的点
. 由于这个3D不需要真正的进行3D重建(因为真正的3D重建是需要知道相机的内参和外参, 内参包括图像中心的坐标, 相机的焦距等, 外参需要知道相机的朝向等, 是比较复杂的), 因此我们将该空间成为quasi-3D.
所以具体是如何做的呢?
1.1 规范3D量的组成
我们将前述的规范3D量记为. 和神经辐射场(NeRF)一样, 我们在
上定义了一个基于坐标的网络
, 该网络将
中的3D坐标
映射到密度
和颜色
. 其中密度可以告诉我们表面(surface)在这个3D空间中的位置, 颜色是可以在训练过程中计算光度损失(photometric loss).
1.2 3D双射
如前所述, 我们需要定义一个从本地坐标(也就是视频或图像坐标)到quasi-3D空间的一个映射, 以及逆映射, 这样我们可以再映射回别的时间索引的帧找到对应点. 然而, 实际上该工作是将本地的2D坐标给提升到3D的(后面会讲如何做的), 然后从提升后的本地3D坐标投影到quasi-3D空间. 整个映射和逆映射的过程如下:
其中是frame index, 因此, 我们定义的映射是和时间有关的. 然而, 中间产物
应该是与时间无关的.
在实现上, 映射是用可逆神经网络(INN)做的.
1.3 计算运动
流程上, 我们在2D图像上的一个像素, 我们首先将其提升到3D, 变成
. 方法是在一个射线上进行采样. 然后用上一节定义的3D双射投影到第
帧对应的3D点, 最后再降维回2D就可以了.
具体地, 由于我们已经将相机的运动包含在映射内了 , 因此我们直接将相机建模成固定的正交相机. 固定正交相机的含义是, 物体不再具有近大远小的特征. 这样一来, 我们就可以很容易的将2D坐标拓展到3D坐标. 也就是说, 既然物体的大小不再随着深度的变化而变化, 那么2D像素点
不论深度如何, 它的值(RGB)一直是一样的, 因此前述的射线可以这样定义:
因此我们在这个射线上采集个样本, 就相当于在这个固定正交相机拍摄的3D场景中进行深度采样.
然后, 这么一堆样本, 我们用映射投影到quasi-3D空间, 然后再用之前说的映射
转换成密度和颜色的量
, 即, 对于第
个样本:
随后, 我们根据第帧的这
个对应样本, 得到第
帧的估计:
以上的过程叫做alpha compositing, 是NeRF中一个常用的技巧. 意义是, 密度实际上表达了3D空间中存在物体的可能性, 就是一种对概率的衡量. 对于是否采纳第
个样本, 重要性为
,
已经解释.
的含义是在这之前的样本的联合可信程度, 也就是说, 之前有一个样本已经比较可信了, 那么这个样本就可以更少的采纳.
以上是个人理解
因此, 上面的过程总结为下图:
2. Training
这个工作是用已有的光流方法生成标签, 指导训练的. 这部分重点先记一下损失函数.
损失函数由三部分构成, 一个是位置误差, 也就是坐标误差. 一个是颜色误差, 这就是前面的作用, 还有一个是因为要保证平稳性而加入的罚项. 其中1, 3项采用1范数, 第二项采用2范数.
Flow loss:
photometric loss:
smooth loss:
意义是保证前一帧和后一帧的差距尽量小.
最终的loss是这三项的线性组合.
文章出处登录后可见!