目录
一、介绍
超分辨率(Super-Resolution)指通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像过程。通俗的说就是在保持原图像清晰度不变的前提下,将图像放大。使用深度学习模型进行超分已经是比较常用的手段,而且深度学习模型又一个好处,可以在数据增强的时候对数据进行退化处理,在超分的时候也可以做去模糊、去噪、去划痕等操作。
深度学习超分模型有几个里程碑:SRCNN > SRGAN > ESRGAN > Real-ESRGAN,SRCNN 和SRGAN 有些古老了,现在基本用不上, Real-ESRGAN是在ESRGAN的基础上做的升级,于是我们主要介绍Real-ESRGAN,用ESRGAN作为补充。
ESRGAN 论文地址:http://arxiv.org/abs/1609.04802
Real-ESRGAN论文地址: https://arxiv.org/abs/2107.10833v2
代码地址:GitHub – oaifaye/dcm-denoise-SR
二、重点创新
1.ESRGAN
(1)提出新的backbone:RRDB(Residual in Residual Dense Block)。这里的Dense指的不是全连接而是卷积层中有着密集的残差链接,这样做的好处是可以获得更深入、更复杂的结构,网络容量也变得更高。
(2)删除BN层。作者发现,BN 层在网络比较深,而且在 GAN 框架下进行训练的时候,更会产生伪影降低了训练的稳定性和一致性。此外,去掉 BN 层也能提高模型的泛化能力,减少计算复杂度和内存占用。
(3)网络插值(Network Interpolation),或者叫残差缩放。即将残差信息乘以一个 0 到 1 之间的数(通过实验最终确定0.2),这样可以使训练更稳定,在保持纹理的同时的减少伪影。
(4)使用相对论RaGAN改进了判别器,它学习判断“一幅图像是否比另一幅图像更真实”,而不是“一幅图像是真实的还是假的”。论文给出的图很形象了。backbone用的VGG,这一点在Real-ESRGAN中被替换。而且在Real-ESRGAN中并没有使用RaGAN的判别器…
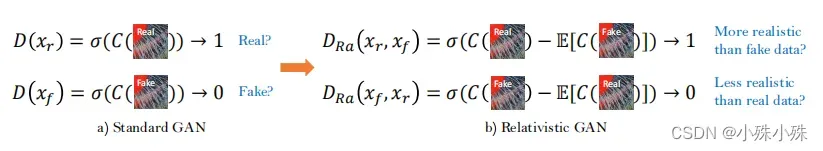
2.Real-ESRGAN
Real-ESRGAN的优化是在ESRGAN的基础上做的,主要内容如下:
(1)给出了一个数据高阶退化过程。即拼接几个典型退化过程来建模(其中还包括sinc filter),从而获得更加接近现实的低质图像。最终作者采用了一个二阶退化过程,以求在简单性和有效性之间取得良好的平衡。这很重要,我们后面重点介绍。
(2)判别器用U-Net代替VGG。Real-ESRGAN中的鉴别器对复杂的训练输出需要更大的鉴别能力,它还需要为局部纹理产生精确的梯度反馈,而不是只区分全局样式。因此使用更加强大的U-Net作为判别器。输出每个像素的真实度值,并可以向生成器提供详细的每像素反馈,增强了图像对细节上的对抗学习。判别器我们下面也会重点介绍。
(3)引入谱归一化(Spectral Normalization)以稳定由于复杂数据集和U-Net判别器带来的训练不稳定情况。
三、生成器结构
1.整体结构
我们以batch_size=1,输入64×64的4x超分为例,生成器整体结构如下:
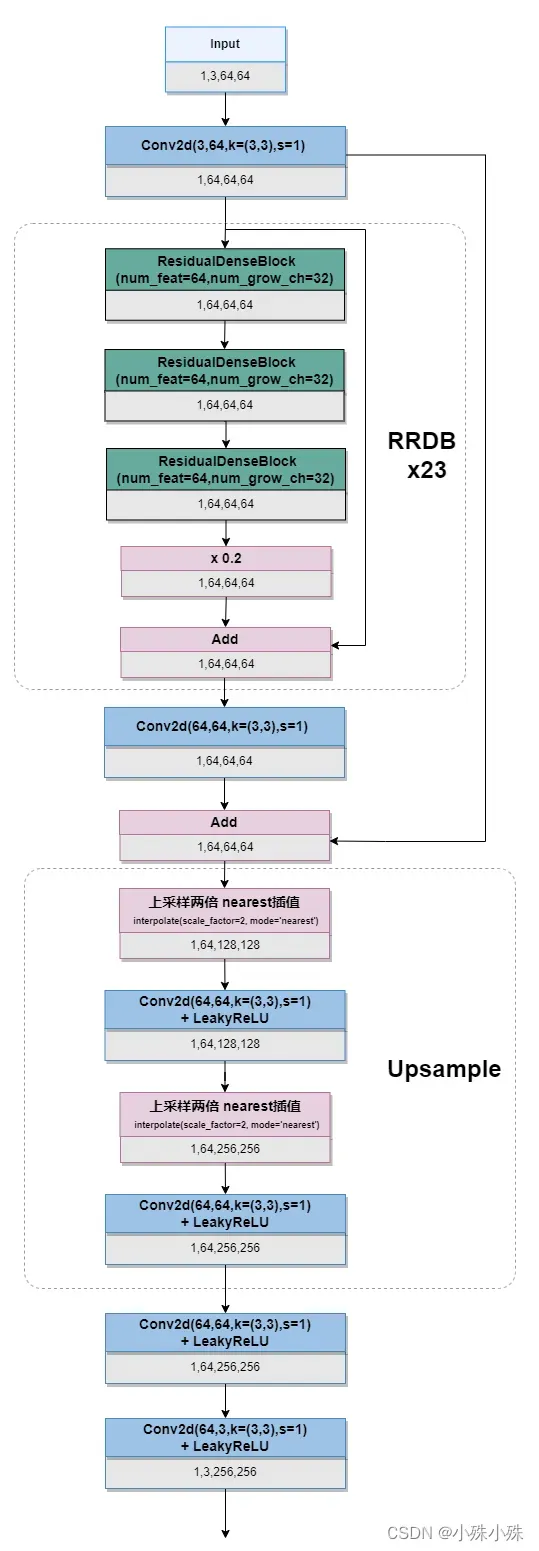
可以看到整体模型结构并不复杂,大体是一个序贯的结构,数据经过了23个RRDB模块,每个RDDB块由3个ResidualDenseBlock组成,输入和输出形状一样;然后进行两次Unsample,Unsample采用nearest插值,每次Unsample之后会有卷积层来细化插值细节;最后通道数变成3输出。
其实生成器的大体机构和SRGAN是一致的,但是将Unsample前的16个残差块换成了23个RRDB模块,这极大的提升了特征提取能力,这也是为什么SRGAN能很好的还原图片细节的原因。每个RDDB块由3个ResidualDenseBlock组成,在底部做Add之前,使用了前面提到的网络插值,即输出乘以0.2再和输出相加,这提高了训练的稳定性。
代码实现:
# 位置 basicsr/archs/rrdbnet_arch.py
class RRDBNet(nn.Module):
"""Networks consisting of Residual in Residual Dense Block, which is used
in ESRGAN.
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks.
We extend ESRGAN for scale x2 and scale x1.
Note: This is one option for scale 1, scale 2 in RRDBNet.
We first employ the pixel-unshuffle (an inverse operation of pixelshuffle to reduce the spatial size
and enlarge the channel size before feeding inputs into the main ESRGAN architecture.
Args:
num_in_ch (int): Channel number of inputs.
num_out_ch (int): Channel number of outputs.
num_feat (int): Channel number of intermediate features.
Default: 64
num_block (int): Block number in the trunk network. Defaults: 23
num_grow_ch (int): Channels for each growth. Default: 32.
"""
def __init__(self, num_in_ch, num_out_ch, scale=4, num_feat=64, num_block=23, num_grow_ch=32):
super(RRDBNet, self).__init__()
self.scale = scale
if scale == 2:
num_in_ch = num_in_ch * 4
elif scale == 1:
num_in_ch = num_in_ch * 16
self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
self.body = make_layer(RRDB, num_block, num_feat=num_feat, num_grow_ch=num_grow_ch)
self.conv_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
# upsample
self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
def forward(self, x):
if self.scale == 2:
feat = pixel_unshuffle(x, scale=2)
elif self.scale == 1:
feat = pixel_unshuffle(x, scale=4)
else:
feat = x
feat = self.conv_first(feat)
# 23个RRDB
body_feat = self.conv_body(self.body(feat))
feat = feat + body_feat
# upsample
feat = self.lrelu(self.conv_up1(F.interpolate(feat, scale_factor=2, mode='nearest')))
feat = self.lrelu(self.conv_up2(F.interpolate(feat, scale_factor=2, mode='nearest')))
out = self.conv_last(self.lrelu(self.conv_hr(feat)))
return out2.RRDB结构
Real-ESRGAN核心是RRDB,特点是密集的残差链接,同时残差边两端以Concat的方式相连,结构图如下:
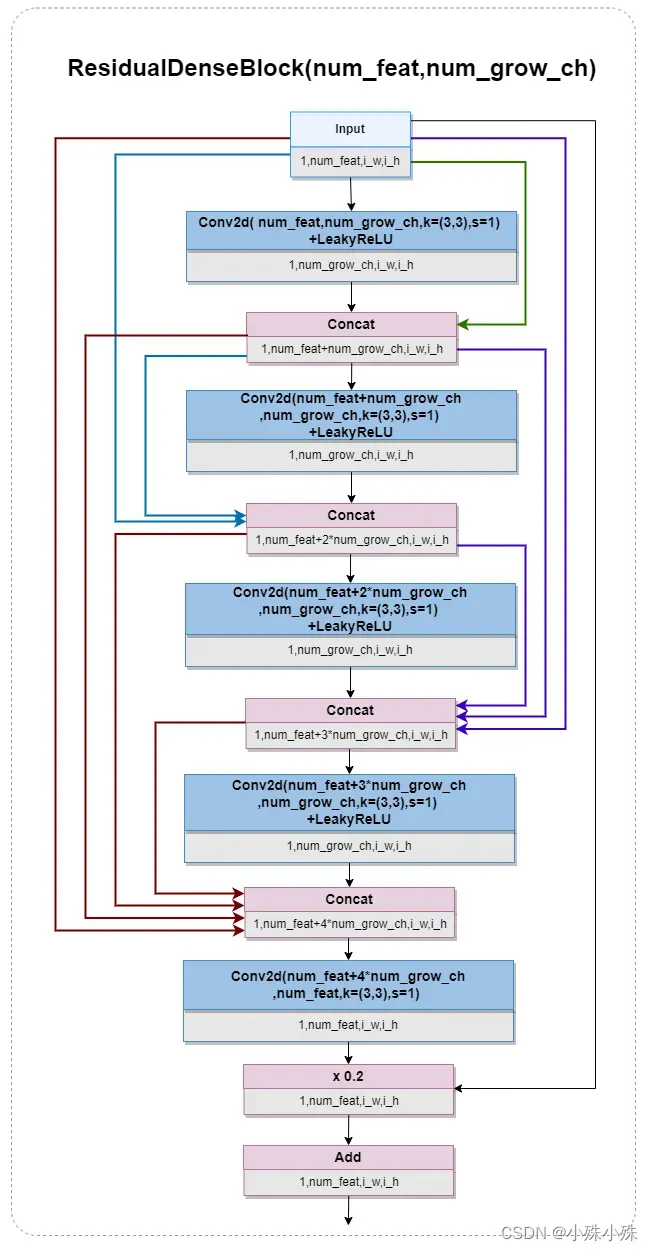
是不是很dense,看上去热闹,其实是有规律,也就是每个卷积激活层的输出会作为下面所有节点的输入。因为有4个concat操作,每个Concat节点的度(出度+入度)都是4。
代码实现:
# 位置 basicsr/archs/rrdbnet_arch.py
class ResidualDenseBlock(nn.Module):
"""Residual Dense Block.
Used in RRDB block in ESRGAN.
Args:
num_feat (int): Channel number of intermediate features.
num_grow_ch (int): Channels for each growth.
"""
def __init__(self, num_feat=64, num_grow_ch=32):
super(ResidualDenseBlock, self).__init__()
self.conv1 = nn.Conv2d(num_feat, num_grow_ch, 3, 1, 1)
self.conv2 = nn.Conv2d(num_feat + num_grow_ch, num_grow_ch, 3, 1, 1)
self.conv3 = nn.Conv2d(num_feat + 2 * num_grow_ch, num_grow_ch, 3, 1, 1)
self.conv4 = nn.Conv2d(num_feat + 3 * num_grow_ch, num_grow_ch, 3, 1, 1)
self.conv5 = nn.Conv2d(num_feat + 4 * num_grow_ch, num_feat, 3, 1, 1)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# initialization
default_init_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
# Empirically, we use 0.2 to scale the residual for better performance
return x5 * 0.2 + x
class RRDB(nn.Module):
"""Residual in Residual Dense Block.
Used in RRDB-Net in ESRGAN.
Args:
num_feat (int): Channel number of intermediate features.
num_grow_ch (int): Channels for each growth.
"""
def __init__(self, num_feat, num_grow_ch=32):
super(RRDB, self).__init__()
self.rdb1 = ResidualDenseBlock(num_feat, num_grow_ch)
self.rdb2 = ResidualDenseBlock(num_feat, num_grow_ch)
self.rdb3 = ResidualDenseBlock(num_feat, num_grow_ch)
def forward(self, x):
out = self.rdb1(x)
out = self.rdb2(out)
out = self.rdb3(out)
# Empirically, we use 0.2 to scale the residual for better performance
return out * 0.2 + x四、判别器结构
判别器使用带有谱归一化的U-Net,结构如下:
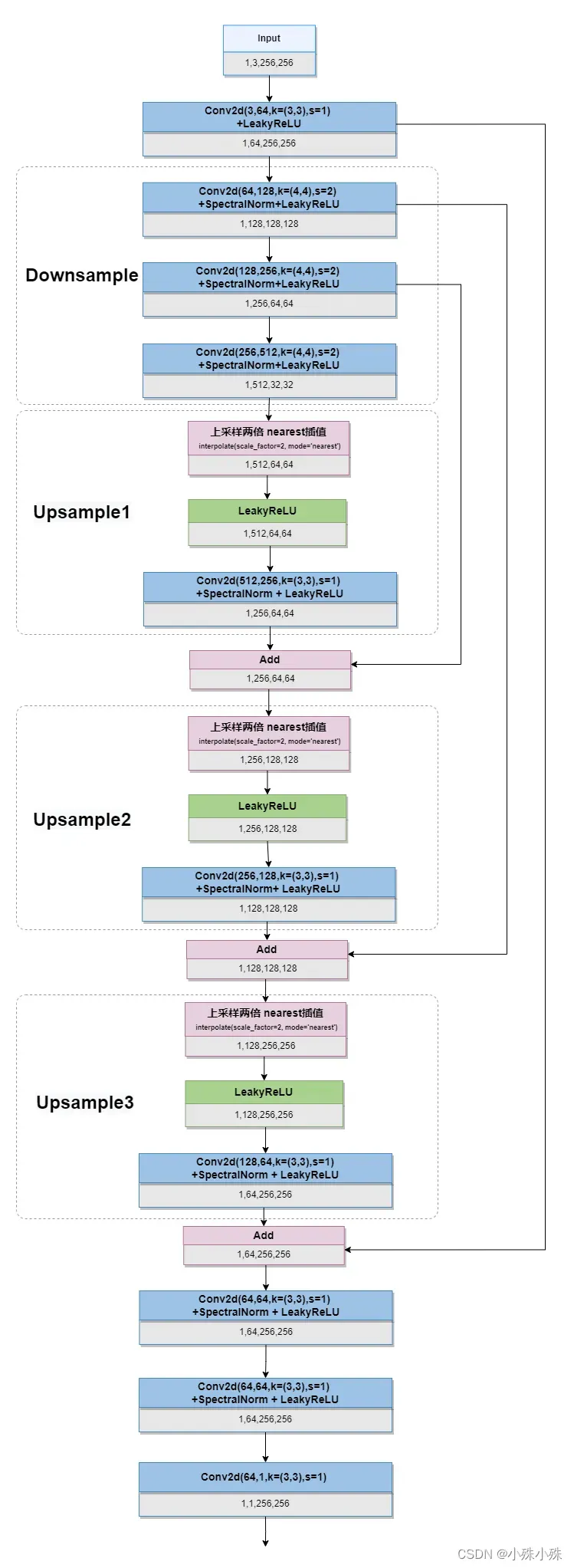
判别器分三部分:
Downsample:三层带有谱归一化的卷积层,每层通道翻倍,宽高减半。
Unsample:使用nearest插值做上采样,三层带有谱归一化的卷积层,每层通道减半,宽高翻倍,同时与Downsample有残差边相连。
输出层:两层有谱归一化的卷积、一层卷积输出层。
五、高阶退化模型
高阶退化模型(High-order Degradation Model)是Real-ESRGAN最重要的创新点。经典的退化模型不能模拟一些复杂的退化问题,特别是未知的噪声和复杂的伪影,这是因为合成的低分辨率图像与现实的退化图像仍然有很大的差距。因此,Real-ESRGAN将经典的退化模型扩展到高阶过程,以模拟更实际的退化。
所谓高阶退化模型通俗的说就是将经典退化算法排列组合,本文将退化算法分为Blur、Resize、Noise、JPEG Compression四类,如下图:
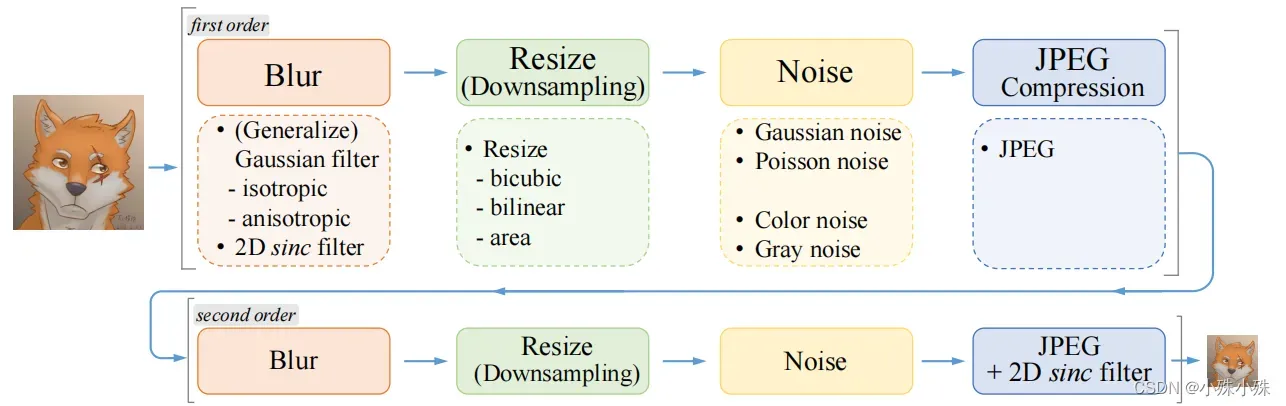
从代码中可以看出,整个退化模型循环两遍上面四种退化过程,每个过程随机选一种算法,步骤如下:
1.1 Blur:概率选择使用sinc filter还是其他模糊算法(iso/aniso/generalized_iso/generalized_aniso/plateau_iso/plateau_aniso),sinc filter概率默认10%。sinc filter是为了模拟振铃伪影(ring artifacts)和过冲伪影(overshoot artifacts),两种伪影长这个样子:

1.2 Resize:随机放大或缩小,插值方式area/bilinear/bicubic选一个;
1.3 Noise:噪声分布随机选择gaussian/poisson;噪声形式随机选择color/gray,color噪声就是三通道数值不一样(默认概率60%),gray噪声三通道数值一样(默认概率40%);
1.4 JPEG compression:JPEG压缩,默认质量30-950;
2.1 Blur:默认80%概率执行,同1.1;
2.2 Resize:同1.2;
2.3 Noise:同1.3;
2.4 JPEG compression:这一步比较特殊,有两个组合可选[resize back + sinc filter] + JPEG compression /
JPEG compression + [resize back + sinc filter], 其中resize back是吧突变resize成gt_size
随机各种退化核的代码在realesrgan_dataset.py中,代码如下:
# 位置 realesrgan/data/realesrgan_dataset.py
......
# ------------------------ 随机生成第一步的各种退化核 ------------------------ #
kernel_size = random.choice(self.kernel_range)
# 概率选择使用sinc filter还是其他模糊算法,sinc filter概率默认10%
if np.random.uniform() < self.opt['sinc_prob']:
# this sinc filter setting is for kernels ranging from [7, 21]
if kernel_size < 13:
omega_c = np.random.uniform(np.pi / 3, np.pi)
else:
omega_c = np.random.uniform(np.pi / 5, np.pi)
kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
else:
# blur
kernel = random_mixed_kernels(
self.kernel_list,
self.kernel_prob,
kernel_size,
self.blur_sigma,
self.blur_sigma, [-math.pi, math.pi],
self.betag_range,
self.betap_range,
noise_range=None)
# pad kernel
pad_size = (21 - kernel_size) // 2
kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
# ------------------------ 随机生成第一步的各种退化核 ------------------------ #
kernel_size = random.choice(self.kernel_range)
if np.random.uniform() < self.opt['sinc_prob2']:
if kernel_size < 13:
omega_c = np.random.uniform(np.pi / 3, np.pi)
else:
omega_c = np.random.uniform(np.pi / 5, np.pi)
kernel2 = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
else:
kernel2 = random_mixed_kernels(
self.kernel_list2,
self.kernel_prob2,
kernel_size,
self.blur_sigma2,
self.blur_sigma2, [-math.pi, math.pi],
self.betag_range2,
self.betap_range2,
noise_range=None)
# pad kernel
pad_size = (21 - kernel_size) // 2
kernel2 = np.pad(kernel2, ((pad_size, pad_size), (pad_size, pad_size)))
# ------------------------------------- 随机最后一部中的 sinc kernel ------------------------------------- #
if np.random.uniform() < self.opt['final_sinc_prob']:
kernel_size = random.choice(self.kernel_range)
omega_c = np.random.uniform(np.pi / 3, np.pi)
sinc_kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=21)
sinc_kernel = torch.FloatTensor(sinc_kernel)
else:
sinc_kernel = self.pulse_tensor
......执行退化流程大代码:
# realesrgan/models/realesrgan_model.py
......
# ----------------------- The first degradation process ----------------------- #
# 1.1 执行blur
out = filter2D(self.gt_usm, self.kernel1)
# 1.2 执行random resize
updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
if updown_type == 'up':
scale = np.random.uniform(1, self.opt['resize_range'][1])
elif updown_type == 'down':
scale = np.random.uniform(self.opt['resize_range'][0], 1)
else:
scale = 1
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, scale_factor=scale, mode=mode)
# 1.3 执行add noise
gray_noise_prob = self.opt['gray_noise_prob']
if np.random.uniform() < self.opt['gaussian_noise_prob']:
out = random_add_gaussian_noise_pt(
out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
else:
out = random_add_poisson_noise_pt(
out,
scale_range=self.opt['poisson_scale_range'],
gray_prob=gray_noise_prob,
clip=True,
rounds=False)
# 1.4 执行JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
out = self.jpeger(out, quality=jpeg_p)
# ----------------------- The second degradation process ----------------------- #
# 2.1 blur
if np.random.uniform() < self.opt['second_blur_prob']:
out = filter2D(out, self.kernel2)
# 2.2 random resize
updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
if updown_type == 'up':
scale = np.random.uniform(1, self.opt['resize_range2'][1])
elif updown_type == 'down':
scale = np.random.uniform(self.opt['resize_range2'][0], 1)
else:
scale = 1
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(
out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
# 2.3 add noise
gray_noise_prob = self.opt['gray_noise_prob2']
if np.random.uniform() < self.opt['gaussian_noise_prob2']:
out = random_add_gaussian_noise_pt(
out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
else:
out = random_add_poisson_noise_pt(
out,
scale_range=self.opt['poisson_scale_range2'],
gray_prob=gray_noise_prob,
clip=True,
rounds=False)
# 2.4 执行JPEG compression和收尾操作
# 我们还需要将图像调整到所需的大小。我们将[size back + sinc filter]组合在一起操作。
# 有两个选项可选:
# 1. [resize back + sinc filter] + JPEG compression
# 2. JPEG compression + [resize back + sinc filter]
# 根据经验,我们发现组合(sinc + JPEG + Resize)会引入扭曲的线条。
if np.random.uniform() < 0.5:
# resize back + the final sinc filter
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
out = filter2D(out, self.sinc_kernel)
# JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
out = torch.clamp(out, 0, 1)
out = self.jpeger(out, quality=jpeg_p)
else:
# JPEG compression
jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
out = torch.clamp(out, 0, 1)
out = self.jpeger(out, quality=jpeg_p)
# resize back + the final sinc filter
mode = random.choice(['area', 'bilinear', 'bicubic'])
out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
out = filter2D(out, self.sinc_kernel)
......六、损失函数
先说明一下数学符号:
:输入
:VGG19模型
:ground truth
:生成模型
:判别模型
:真实的label,就是一个全是1的矩阵
:G模型生成的假的label,就是一个全是0的矩阵
1.生成模型损失函数
生成模型损失函数:
默认0.1,
默认1
:感知损失,将gt和生成模型的输出分别送入预训练VGG19,取conv1_2(bx64x256x256)、conv2_2(bx128,128×128)、conv3_4(bx256x64x64)、conv4_4(bx512x32x32)、conv5_4(bx512x16x16)层的数据,然后计算L1loss,公式如下:
:GANLoss,将生成模型的输出送入判别模型(U-Net),将结果(bx1x256x256)和babel(全是1)计算二进制交叉熵损失(BCELoss),公式如下:
:gt和生成模型的输出直接计算L1loss,公式如下:
代码实现:
# 位置 realesrgan/models/realesrgan_model.py
# pixel loss
if self.cri_pix:
l_g_pix = self.cri_pix(self.output, l1_gt)
l_g_total += l_g_pix
loss_dict['l_g_pix'] = l_g_pix
# perceptual loss
if self.cri_perceptual:
l_g_percep, l_g_style = self.cri_perceptual(self.output, percep_gt)
if l_g_percep is not None:
l_g_total += l_g_percep
loss_dict['l_g_percep'] = l_g_percep
if l_g_style is not None:
l_g_total += l_g_style
loss_dict['l_g_style'] = l_g_style
# gan loss
fake_g_pred = self.net_d(self.output)
l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
l_g_total += l_g_gan
loss_dict['l_g_gan'] = l_g_gan
l_g_total.backward()
self.optimizer_g.step()2.判别模型损失函数
Real-ESRGAN的判别模型优化分两步:
(1)优化判别真的能力,即构造一个全是1的,然后计算
和
的BECLoss,公式如下:
(2)优化判别假的能力,即构造一个全是0的,然后计算
和
的BECLoss,公式如下:
代码实现:
# 位置 realesrgan/models/realesrgan_model.py
self.optimizer_d.zero_grad()
# real
real_d_pred = self.net_d(gan_gt)
l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
loss_dict['l_d_real'] = l_d_real
loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
l_d_real.backward()
# fake
fake_d_pred = self.net_d(self.output.detach().clone()) # clone for pt1.9
l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
loss_dict['l_d_fake'] = l_d_fake
loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
l_d_fake.backward()
self.optimizer_d.step()Real-ESRGAN就介绍到这里,还有很多关于Real-ESRGAN实现的细节,很快会再更一期,关注不迷路!!!
文章出处登录后可见!