本文会先介绍动态系统的概念,然后介绍两种简单的反馈神经网络,然后再介绍两种门控神经网络(LSTM, GRU),最后是关于反馈神经网络的应用(本次以语音识别为例)。
RNN: Recurrent neural network,一般叫它“反馈神经网络”或者“循环神经网络”。
一、动态系统
日常生活中,动态系统随处可见,蝴蝶扇动翅膀,它的翅膀是随着时间变化的,人走路、内燃机工作、股票等等,都是随着时间变化的。我们把这些系统成为动态系统。

我们最后要讲的语音识别就是使用RNN来建模一个动态系统的典型的例子。
1.1 反馈连接
1.1.1 前馈网络
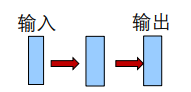
我们前面所学的CNN、MLP等,都是像上面一样有一个输入输出层,中间有n个隐含层。这个网络训练好以后,它的信息的流向是从输入层到输出层,中间没有其它流向,这样的网络我们叫它前馈网络。
1.1.2 反馈网络
层间反馈
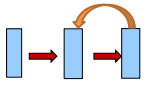
对应的,反馈网络,信息有反向流动。比如有一个从输出层到隐含层的反向连接:输入->隐含->输出->隐含->输出->隐含->输出->… (循环、反馈神经网络名字的由来)
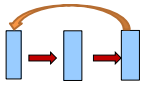
或者是:输入->隐含->输出->输入->隐含->输出->…
层内反馈
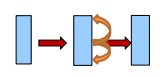
另一种反馈连接是在层内部的连接,因为一个层内部它有很多个神经元,假如我们让这些神经元互连,那么它也会在这一层的内部进行不停地循环,也就是每个时刻这100个神经元的状态都可能是不同的。
- 前馈网络
- 无反馈
- 反馈网络
- 层间反馈: 从输出层到输入层, 或者从隐藏层到输入层
- 层内反馈
反馈连接的存在导致神经元的状态 (以及输出)将随时间变化
1.2 RNNs是动态系统

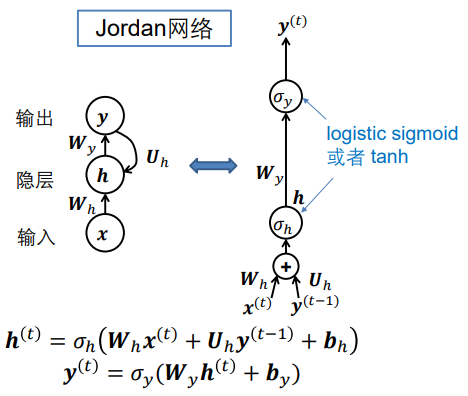
如上是Jordan网络和Elman网络,及其动态方程,h(t)表示第t时刻的h,它由当前时刻的输入x(t)和上一时刻的输出y(t-1) 或 上次隐含层的输出h(t-1)决定。
1.2.1 使用RNN对动态系统建模
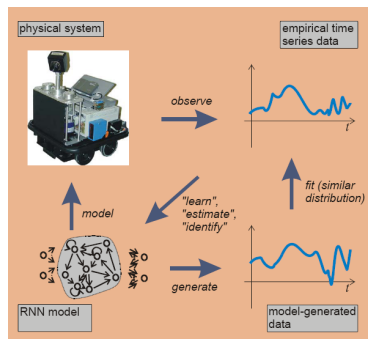
比如我们有一个动态系统,该动态系统性质复杂,我们没有办法对这个系统进行一个精确的建模,但是我们能有测量这个系统的输入和输出随时间变化的一个曲线。
为了对这个动态系统进行建模,我们可以构建一个RNN模型,调整RNN里面的参数,使得这个RNN的输入和输出的关系与该物理系统是一样的。通过数据的拟合来调整神经网络的参数,使得RNN输入与输出的关系能够很好地匹配上这个物理系统。
为什么可行?
- RNN中的隐藏状态
对之前的事件有记忆,即前一时刻影响后一时刻:h(t+1), h(t)
期望隐藏状态能捕获对象系统中过去的信息或时间依赖性
这种记忆类似于动物的短期记忆
- 给定很多系统的输入输出对,存在有效的算法来学习RNN的参数
通过时间反向传播 (BPTT)
1.2.2 解释大脑如何工作*
- 用一个已存储的模式的部分信息或近似信息来恢复该模式的整体信息

说人话就是上面两张图片是同一个人,我们认识左边这张图片以后,即便是这个人戴上墨镜,我们依然也认得他。
这个过程我们认为是动态系统演化的过程。
Hopfield网络
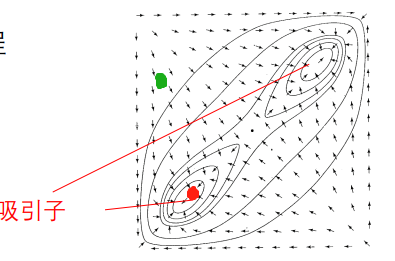
我们把这个动态系统简化为一个二维的,图片中的红点表示上面左边完整的人物图片,绿点表示该人戴了墨镜不完整的信息,上面这些箭头表示它在平面上随时间演化的过程。
因为我们大脑里存在大量的反馈链接,我们可以把大脑看作一个反馈神经网络,一个动态系统。当我们看到戴墨镜的他后,大脑的绿点就开始沿着箭头演化,逐渐收敛到红点,于是我们认出了这个人。收敛到的位置我们成为:吸引子
- 这可能是大脑中的动态过程
1.3 RNN的历史

二、简单RNNs
2.1 Jordan网络

2.2 Elman网络

上面两种RNN网络结构已经讲过,这里来讲一下:通过时间反向传播(BPTT)
我们在学习全连接或者CNN时接触到了反向传播算法,我们用它来更新权重参数。在这里,RNN使用BPTT来更新参数。
2.3 通过时间反向传播(BPTT)
将网络的时间操作展开为前馈网络,该网络在每个时间步长都会增加一层。
因为该网络和时间有关,如 ,我们可以将公式展开,这样不同时刻(t-1, t, t+1, t+2…)的公式(权重参数)就像是不同层的隐含层一样,可以用来计算了。
我们假设只有两个神经元:
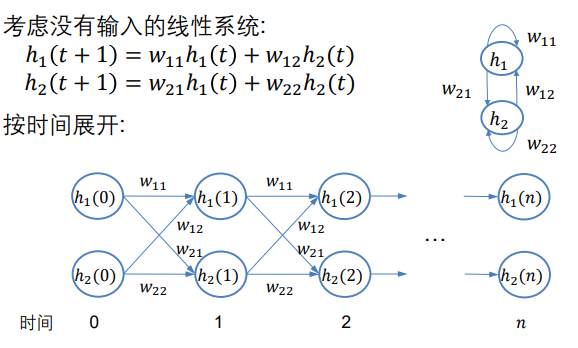
展开以后,不就是一个前馈网络了吗?此时,就没有任何的反馈链接了。
这样我们就可用BP算法去优化、学习这个前馈网络的参数了。(不是优化这里展开后的网络的w11,w12,他们展开后是不变的,我们优化的是全部展开后,整个RNN变为一个更长的前馈神经网络,我们更新的是每一部分的W11,W12…。)
注:当然这也和我们所学的前馈网络不太一样,一个是神经元的个数没发生变化,另一个是权值W11 W12…没有发生变化,我们变化的是神经元的状态h11 h12…。所以我们可以从上图看到,W后面没有括号t,且展开时W11, W12…并没有发生变化。
2.3.1 展开Elman网络
接下来我们就要根据上面所说的,把一个RNN网络按时间展开成一个前馈网络了。
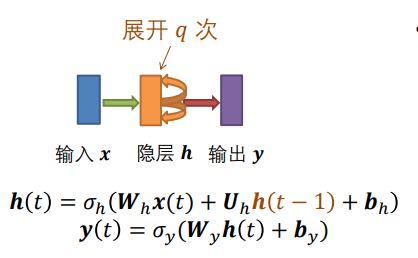
神经网络的展开方式和任务有关,任务设定不同,返回神经网络的展开也不同。
情况 1:
- 𝒙 仅出现在第一层
- 标签 𝒓 只出现在最后一层
- Recursive NN做图像分类 就是这样的工作形式
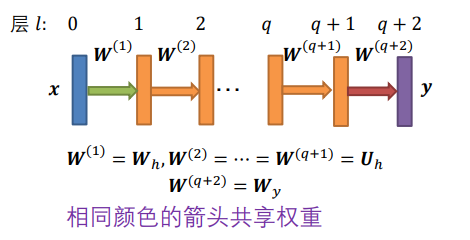
如上图,原本的隐层h内部进行时间循环,我们这里展开成前馈网络,即上图的多个橙色层,它们的权重W都是一样的,原因上面也说了,变化的只是状态h,因此展开时W已经定下来了,和t有关的只是h。
情况 2:
- 𝒙 是固定的但出现在所有层中
- 标签 𝒓 只出现在最后一层
- 例如图像分类 (Liang, Hu, CVPR 2015)
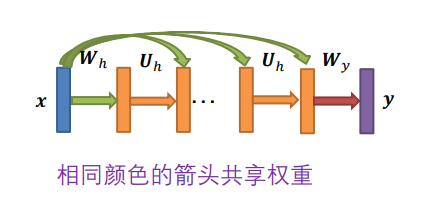
和上面情况1的区别在于,展开的每次都要把x作为输入给到隐层单元。绿色、橙色箭头权值共享。
图像分类:每次隐层的节点都能同时接收到上一时刻的输出和初始图像作为输入,把信息做一次前馈计算,输出到下一层。
其实上面两种情况都不太常见,常见的是下面这两个例子。
情况 3:
- 𝒙 随时间变化
- 标签 𝒓 只出现在最后一层
- 例如,句子分类
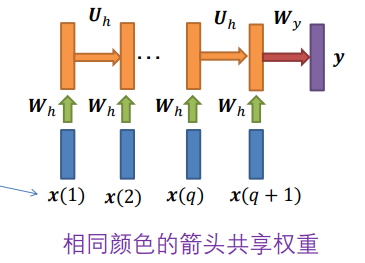
每个时间都会有不同的x给到这个系统,所以在展开的时候,除了接收上一时刻的输出,还要接收一个随时间变化的输入x。
句子分类:根据不同的词(输入x),最后得出结论是正面的还是负面的(输出y)
情况 4:
- 𝒙 随时间变化
- 标签 𝒓 在所有层都出现
- 例如,语音识别
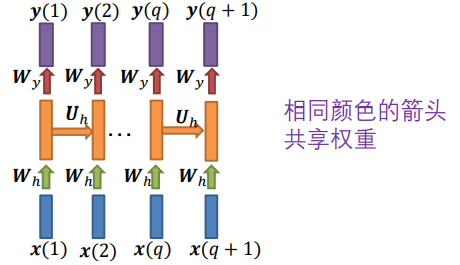
即在每一时刻多了y的输出。
语音识别:比如I like deep learning 这句话,不同时刻的输入会有该时刻的输出。
至于其它情况,具体情况具体分析啦。
2.4 新的图示表示
我们用一种新的图示来表示Elman网络和Jordan网络及其展开。
2.4.1 Elman网络
- 用圆圈来表示向量 (一个圆表示一层,即用圈代替前面的矩形)
- 将时间步长作为上标
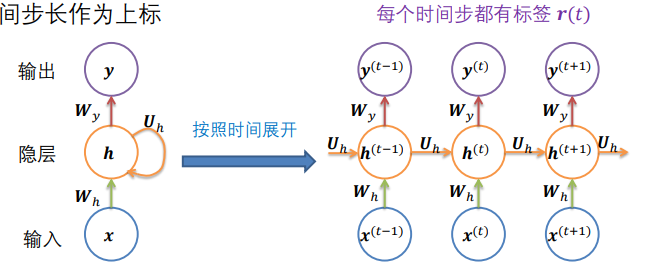
- 前向传播运行时间是 𝑂(𝑞) 并且无法减少(展开q次)
- 等效于图灵机
这种展开就是上面的情况4,比如语音识别。
2.4.2 Jordan网络
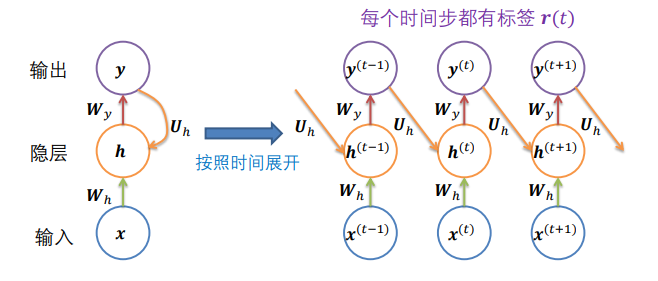
它的功能不那么强大,无法模拟通用图灵机
2.5 强制教学(Teacher forcing)
某些网络(例如Jordan网络) 具有从一个时间步的输出到下一个时间步的计算值的连接,那么应该在下一时间步中输入什么来表示输出?
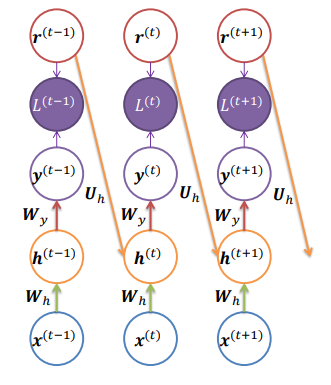
上图,r为标签,我们是将r连接给下一层时刻呢还是把y给它。刚开始训练的时候,y可能不太对,这样不太好训练,所以不如把r连给它,这个想法称为强制教学。
强制教学(Teacher forcing): 训练过程中,使用参考信号(期望的标签r)
好处:所有时间步都可解耦,因此训练可以并行化。因为使用标签r作为下一个的输入,此时和时间没有关系了,不需要等待。
训练时可以有r,但是在测试时,不存在参考信号,因此我们必须使用网络在时间 𝑡 时的输出y。(这样训练和测试的时候,网络结构不同,就会带来一些问题,比如训练的时候,没见过错误的信号,测试的时候就胡乱瞎输出了)
网络在训练过程中得到的输入类型可能与测试时得到的输入类型完全不同。
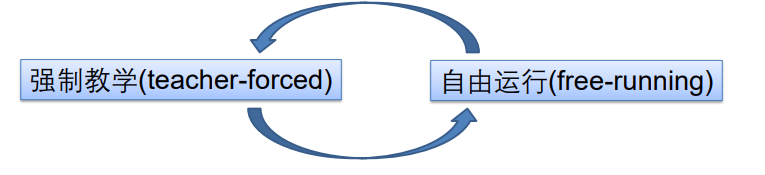
因此在训练的时候,我们可以一会使用强制教学,一会让它自用运行(即接收y),这样既能加快训练速度,又能让网络看到一些错误的信号。
2.6 双向RNN
- 在很多应用中,当前时间步的预测可能依赖于整个输入的序列(过去和未来)
人话:我们上面所讲的当前时刻的输出依赖于上一时刻(过去),但其实在很多应用中,它可能还依赖于未来。
Bank is the side of a river.
Bank provides various financial services.
第一个句子中的Bank是河岸的意思,第二个句子中的Bank是银行的意思。但是当你只读到第一个单词的时候,不知道这里的Bank是河岸还是银行,因此也要依赖于“未来”。
- 双向 RNNs将一个随时间向前移动的RNN与另一个随时间向后移动的RNN组合在一起
- 每个时间段的整个网络的输出都会收到两个RNN的输入,前后文同时判断Bank的含义。
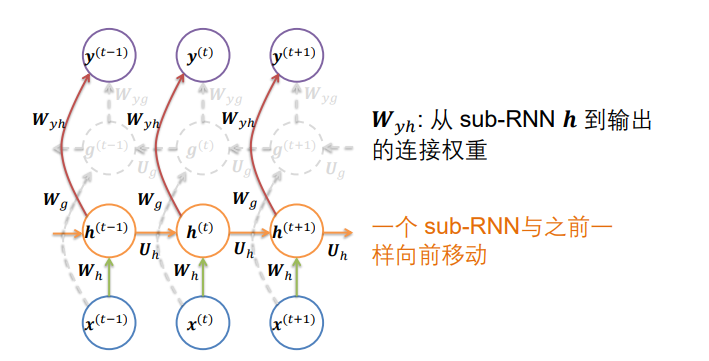
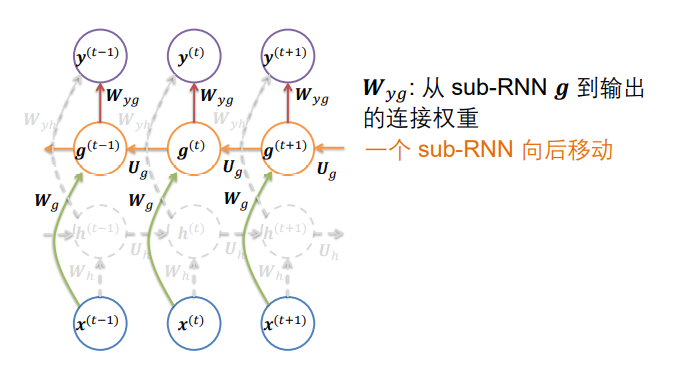
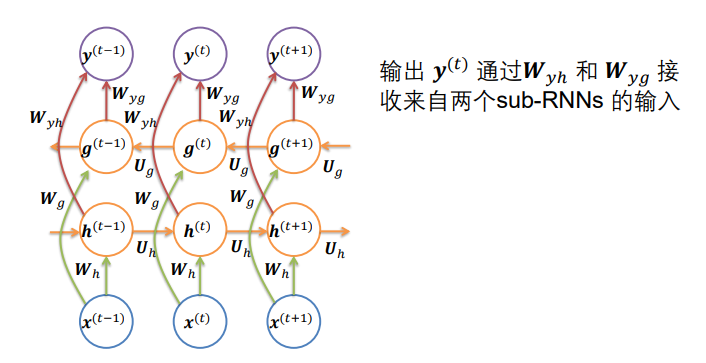
同时接收一个从左向右的RNN和一个从右向左的RNN作为输入得到输出。
2.7 深度RNNs
我们上面举的例子包括拆分Elman网络时,隐含层只有一层,即便展开参数也都是共享的。实际上它可以有很多层。
我们有多种构建RNNs的方式,层间、层内、层间+层内…
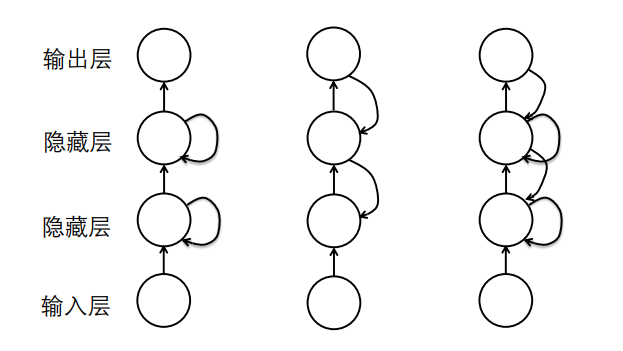
2.8 思考
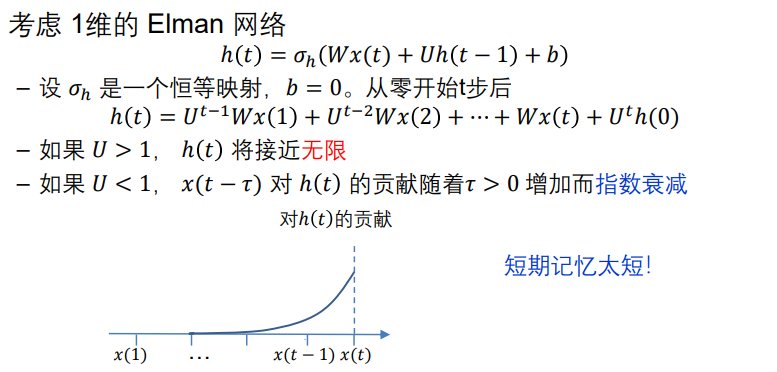
从上图可以看到,这里的h(t)虽然可以记忆一些东西,但随着时间延申,之前的记忆指数衰减!
- 该结论可以推广到多维Elman网络,需要一些关于U的假设,例如,U是对称的
- 在Jordan网络上可以得出相同的结论,将 𝒚(𝑡) 表示为𝒚(0) 和 𝒙 1 , … , 𝒙(𝑡)的函数
三、门控RNNs
为了解决记忆太短的问题,人们提出了门控RNNs。
3.1 长短时记忆 (LSTM) 单元
可以视为Jordan网络和Elman网络的组合。将两个网络的特点组合一下,即可得到LSTM。
- 输出连接到输入
- 自循环用于捕获有关过去的信息
重画 Jordan 网络:用圆圈表示操作 ,变量在箭头上指示 ,忽略偏置 𝒃
第一步:添加一个自循环(添加Elman特点)

这一步可能有些小白看不懂,上面说了,是Jordan和Elman的组合,组合自然就是把他俩加起来了哈哈,红色的部分还是层内(Elman)自循环,整体外部是层间自循环(Jordan)。
至于为什么不用h来自反馈而引入一个c去记忆呢,其实用h自反馈这种思想将在下面GRU提到,这里我们先使用c。
第二步:添加三个门(函数,输出在0-1之间,0关闭,1完全打开,之间就是半开半闭)
此时虽然Jordan和Elman都组合了起来,但并没有改变短记忆的特点,因此我们添加三个门来控制信息流。

- 遗忘门f 控制上一时刻记忆c(t-1)有多少传到当前时刻c(t),(f是0的话就全忘了,1的话就全记住,即f越小,忘的就越快。)
- 输入门i 控制当前输入h(t)有多少要放到记忆c(t)里面。
- 输出门o 影响下一个时刻输入进去给h信息的多少
这些门由什么决定呢?

我们根据x(t)和y(t-1)得到的结果,进行非线性变换映射到0-1之间。有时也可以由c(t),c(t-1)决定。
术语

3.1.1 思考
1. LSTM能否保留比Elman网络更长的短期记忆?
当然可以
2. 为什么
假设三个门的值均为1(当然门的值是变化的由x(t)和y(t-1)决定),我们从公式中可以看出每次一循环的信息都被保留下来了,我们当时用c模拟Elman网络自循环,c(t) = c(t-1)+h(t) 这样c不断累加,就能不断存贮之前的信息。
3. 永远保持 𝑡 = 𝑛 时获得的记忆 𝒄 (𝑛) 的理想情况是什么?
原因见2
3.1.2 LSTM优点
与简单的RNNs相比,门控机制使模型能够将记忆保留更长的时间
“Long short-term memory network”
门控机制已广泛用于深度学习模型中,不仅在RNN中,而且在CNN中
- Highway Network (Srivastava et al., ICML 2015 Deep Learning workshop)
- SEnet (Hu et al., CVPR 2018) – SKnet (Li et al., CVPR 2019 )
- 注意力机制(前馈模型没有记忆)
3.2 门控循环单元(GRU)
在Elman网络中,𝒉 用于捕获历史信息
在没有门的LSTM单元中,为此引入了一个新的c
那么为什么不直接使用h?
这是GRU的第一个想法
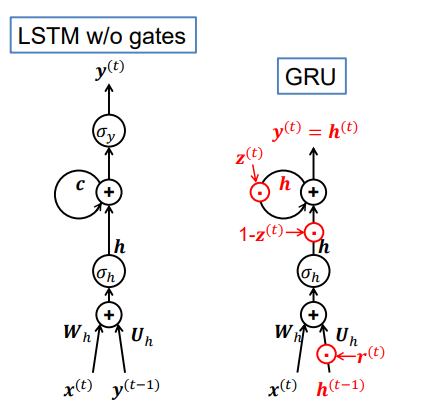
其中 z也是个门,且
即在LSTM中去掉了c,用h自己和自己求和(前一时刻+后一时刻)。
我们也看到了上图其实不止在c处发生了变化,这里就要引入GRU的第二个和第三想法。
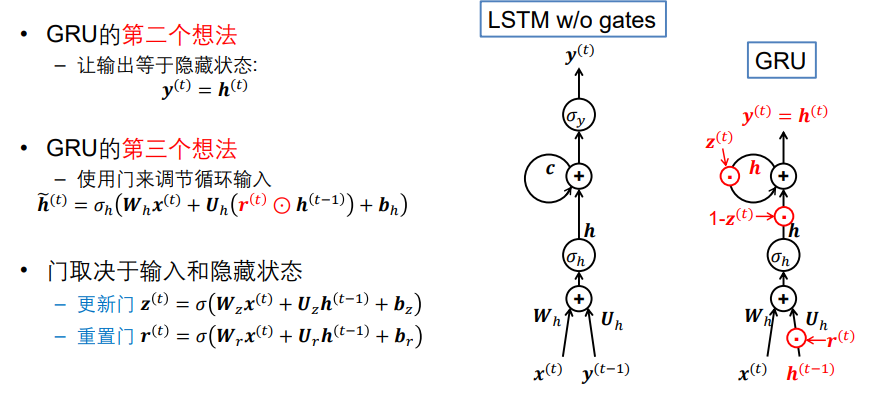
- 更新门z 用来控制h自反馈,此消彼长。
- 重置门r 调节输入
由x(t)和h(t-1)决定。
GRU

3.3 LSTM和GRU哪一个更优?
- LSTM 和 GRU 在许多任务上表现相似
- LSTM和GRU还有许多其他变体,但是它们在所有任务中都无法明显击败这两个标准模型(Greff et al., TNNLS 2017)
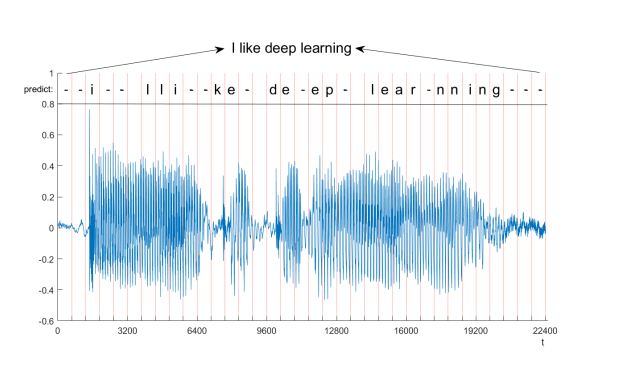
四、语音识别
根据上面所学知识,比如动态系统、展开Elman网络时的不同情况、双向RNNs,我们可以来了解一下语音识别。
语音识别和自然语音他们都有一个共同特点:序列数据,所以很适合用反馈神经网络进行建模。
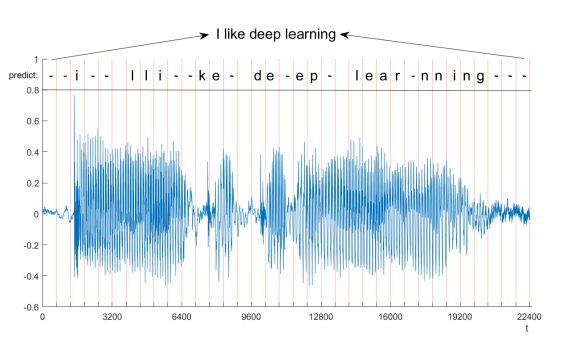
如上图,输入是一个随时间变化的WAV格式的信号, 输出则是上方对应的因素,比如I like …,
– 表示当时没有一个对应的因素,因为人说话时同一个因素有的人发音长有的人发音短,中间拉声的时间可能会不一样。
4.1 语音识别常用模型
4.1.1 基本流程
RNN设置
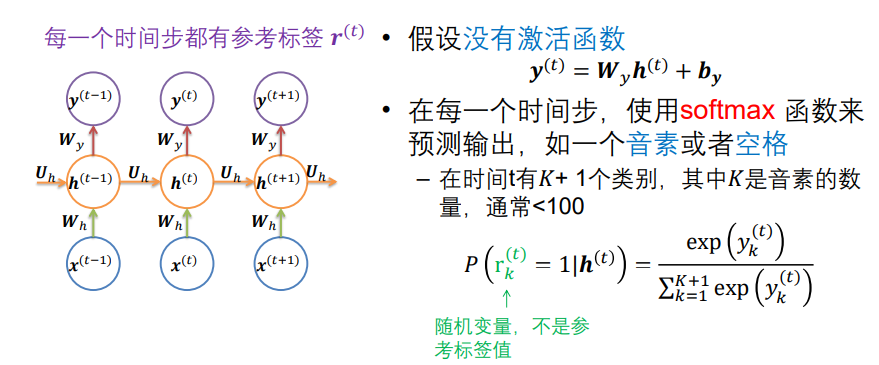
这是一个Elman网络的展开方式,对应上面我所写的情况4,(LSTM和GRU也可以做类似的展开,毕竟都是反馈神经网络。)
目标函数


4.1.2 使用双向LSTM进行语音识别
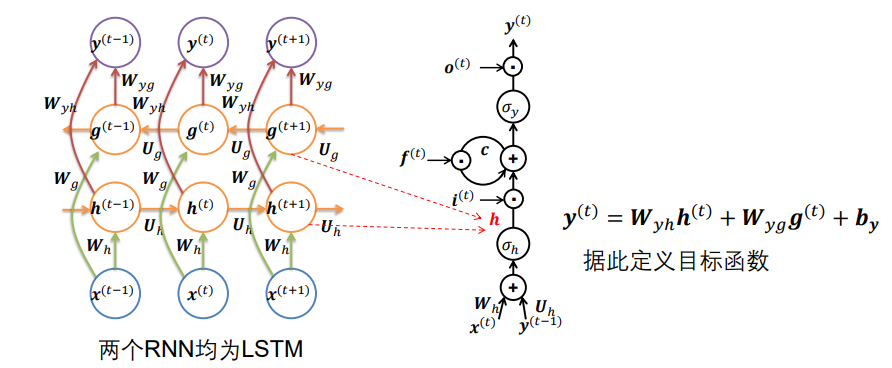
与上面所讲的双向RNN一样,这里的RNN是LSTM,其上一时刻的两个不同方向的输出作为这一时刻的输入。
注:这里的双向LSTM的g或者h可以是右侧的h或者c。
4.1.3 深度 RNN – 百度的 Deep Speech 2
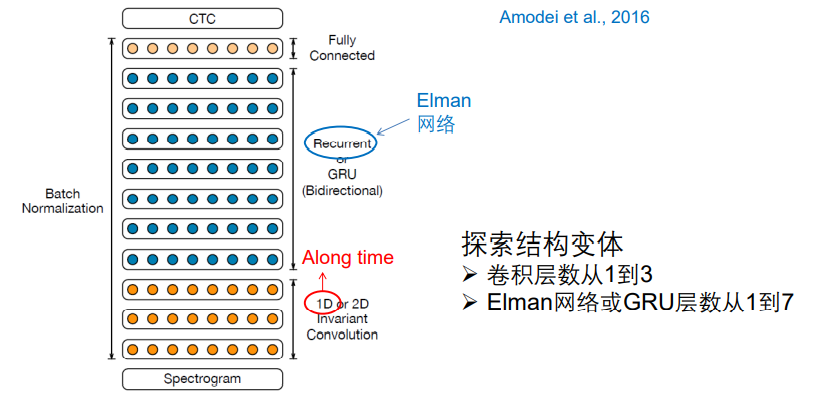
卷积后接RNN
4.2 数据预处理
通常模型的输入不是原始的wav信号,而是频谱信号
- (Graves et al., 2013)使用基于傅立叶变换的滤波器组对音频数据进行编码,该滤波器组以mel等级分布,拥有40个系数(加上能量),再加上它们的第 一和第二时间导数。
- 因此,每个输入向量的大小为123。
- 对数据进行归一化,以使在整个训练集上输入向量的每个元素有零均值和 单位方差。
4.3 基准数据集
基准数据集
- TIMIT, 较小
- Switchborad, 260 小时
- LibriSpeech, 1000 小时
- CHiME, 有各种环境噪音
许多基准数据集仅用于测试,您需要使用自己的训练集
- Deep speech 2 ,英语系统接受了11,940个小时的英语语音训练,而 普通话(Mandarin)系统则接受了9,400个小时的训练。数据合成被用来 进一步扩充数据。
研究人员倾向于开源他们的模型,但不开源训练集 ,这使得评估不同模型变得困难。
五、主要文献与延伸阅读
- Goodfellow, Bengio and Courville, 2016 Deep Learning, MIT Press, Chapters 10
- Understanding LSTM networks http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- Sutskever, Fernandez, Gomez, Schmidhuber (2006) Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks ICML
- Graves, Mohamed, Hinton (2013) Speech recognition with deep recurrent neural networks IEEE ICASSP
- Amodei, Ananthanarayanan, Anubhai et al. (2016) DeepSpeech2: End-to-End Speech Recognition in English and Mandarin ICML
- Greff, Srivastava, Koutník, Steunebrink, Schmidhuber (2017) LSTM: a search space odyssey IEEE Trans. on Neural Networks and Learning Systems
- Liang, Hu (2015) Recurrent convolutional neural network for object recognition CVPR
文章出处登录后可见!