解决CUDA out of memory.
- 项目场景
- 原因分析&解决方案
- ① GPU空间没有释放
- 解决一 换GPU
- 解决二 杀掉进程
- ② 更换GPU后仍未解决
- 法一:调小batch_size
- 法二:定时清内存
- 法三(常用方法):设置测试&验证不计算参数梯度
- 法四(使用的别人的代码时):将”pin_memory”: True改为False
项目场景
跑bert-seq2seq的代码时,出现报错
RuntimeError: CUDA out of memory. Tried to allocate 870.00 MiB (GPU 2; 23.70 GiB total capacity; 19.18 GiB already allocated; 323.81 MiB free; 21.70 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
运行时错误:CUDA内存不足。试图分配870.00 MiB (GPU 2;23.70 GiB总容量;19.18 GiB已经分配;323.81 MiB空闲;如果分配的内存是>,>分配的内存尝试设置max_split_size_mb以避免碎片。请参阅文档了解内存管理和PYTORCH_CUDA_ALLOC_CONF

参考:
https://blog.csdn.net/qq_37555071/article/details/108346569
https://blog.csdn.net/xiyou__/article/details/118529350
原因分析&解决方案
① GPU空间没有释放
可能为PyTorch占用的GPU空间没有释放,导致下次运行时,出现CUDA out of memory。
命令行输入 nvidia-smi,显示GPU的使用情况,以及占用GPU的应用程序
nvidia-smi
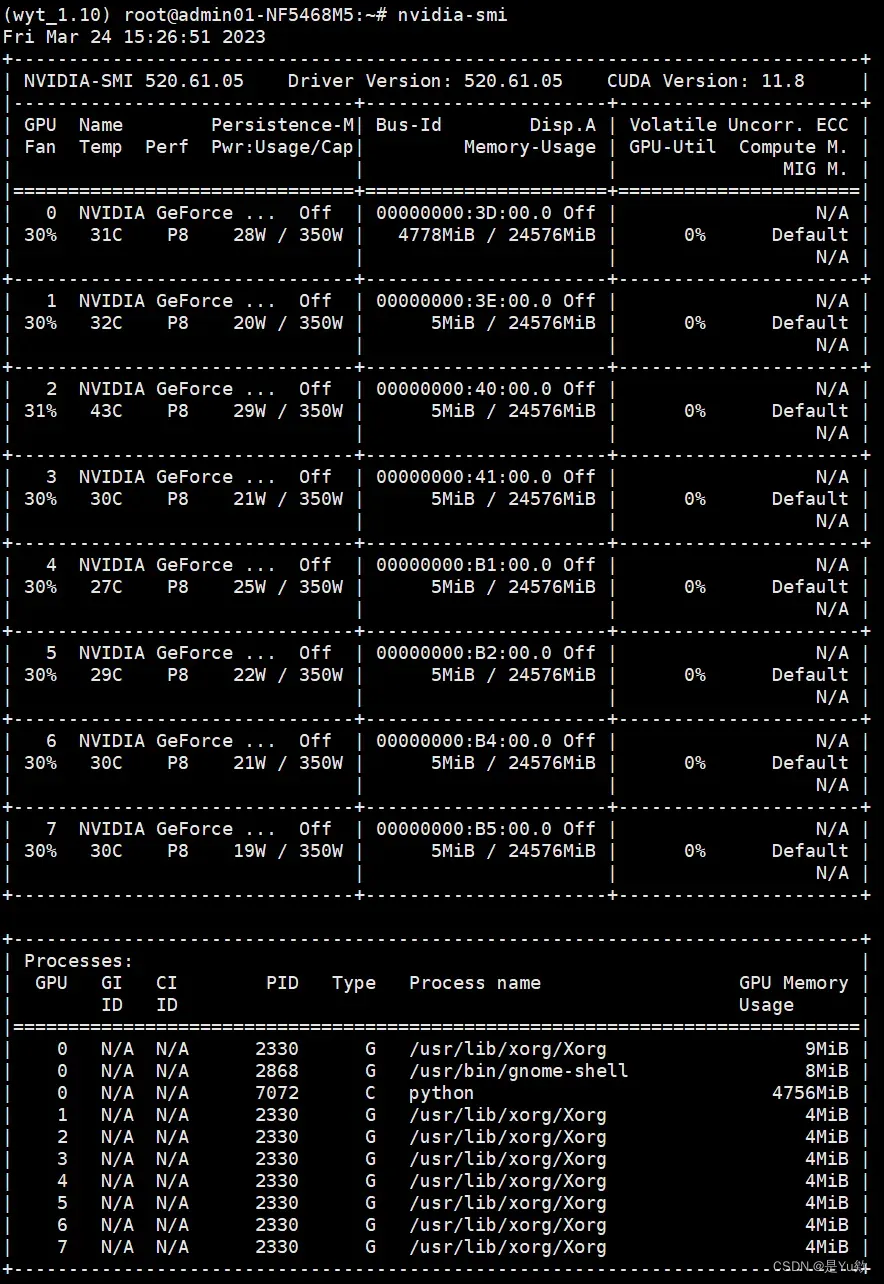
此时发现仅GPU:0有4778MIB的占用
有两种解决方案
解决一 换GPU
将代码中的默认0,换成指定2
# device = "cuda" if torch.cuda.is_available() else 'cpu'
device = torch.device('cuda:2')
解决二 杀掉进程
windows系统输入taskkill -PID 进程号 -F 结束占用的进程,比如
taskkill -PID 7072 -F
linux系统输入kill 进程号 结束占用的进程,比如
kill 7072
![]()
然后再次输入 nvidia-smi 查看GPU使用情况
② 更换GPU后仍未解决
法一:调小batch_size
设到4基本上能解决问题,如果还不行,该方法pass。
法二:定时清内存
在报错处、代码关键节点(一个epoch跑完…)插入以下代码(目的是定时清内存):
import torch, gc
gc.collect()
torch.cuda.empty_cache()
法三(常用方法):设置测试&验证不计算参数梯度
在测试阶段和验证阶段前插入代码 with torch.no_grad()(目的是该段程序不计算参数梯度),如下:
def test(model,dataloader):
model.eval()
with torch.no_grad(): ###插在此处
for batch in tqdm(dataloader):
……
法四(使用的别人的代码时):将”pin_memory”: True改为False
如果怎么修改,都会出现题中bug,甚至跑了几轮之后突然出现 cuda out of
memory,查看代码中是否存在一下代码(通常出现在main.py 或者数据加载的py文件中:
kwargs = {'num_workers': 6, 'pin_memory': True} if torch.cuda.is_available() else {}
将”pin_memory”: True改为False,具体原因原博:
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些。
主机中的内存,有两种存在方式,一是锁页,二是不锁页,锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(注:虚拟内存就是硬盘),而不锁页内存在主机内存不足时,数据会存放在虚拟内存中。显卡中的显存全部是锁页内存,当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。因为pin_memory与电脑硬件性能有关,pytorch开发者不能确保每一个炼丹玩家都有高端设备,因此pin_memory默认为False。
文章出处登录后可见!