点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
目前3D目标检测领域方案主要包括基于单目、双目、激光雷达点云、多模态数据融合等方式,本文主要介绍基于激光雷达雷达点云、多模态数据的相关算法,下面展开讨论下~
3D检测任务介绍
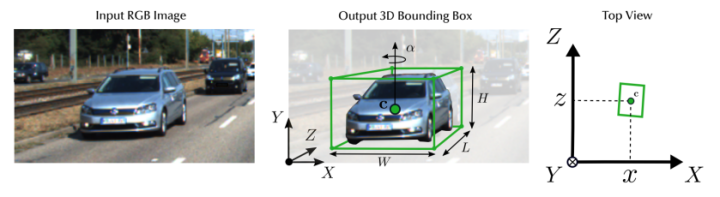
3D检测任务一般通过图像、点云等输入数据,预测目标相比于相机或lidar坐标系的[x,y,z]、[h,w,l],[θ,φ,ψ](中心坐标,box长宽高信息,相对于xyz轴的旋转角度)。
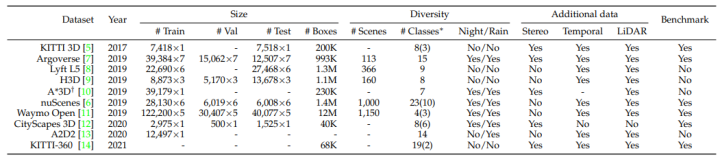
3D检测相关数据集
下面汇总了领域常用的3D检测数据集,共计11种:
KITTI-3D: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
Argoverse:https://www.argoverse.org/data.html#download-link
Lyft L5:https://level-5.global/download/
H3D:https://usa.honda-ri.com//H3D
A*3D:https://github.com/I2RDL2/ASTAR-3D
nuScenes:https://www.nuscenes.org/nuscenes#download
Waymo Open:https://waymo.com/open/download/
CityScapes-3D:https://www.cityscapes-dataset.com/downloads/
A2D2:https://www.a2d2.audi/a2d2/en/download.html
KITTI-360:http://www.cvlibs.net/datasets/kitti-360/download.php
Rope3D:https://thudair.baai.ac.cn/rope
3D检测在数据格式上的分类
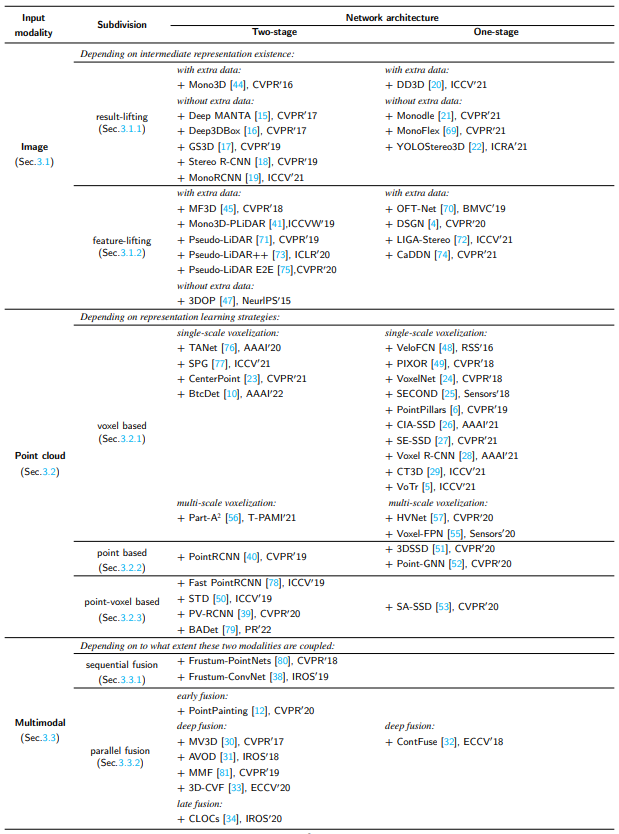
基于激光雷达点云
基于point
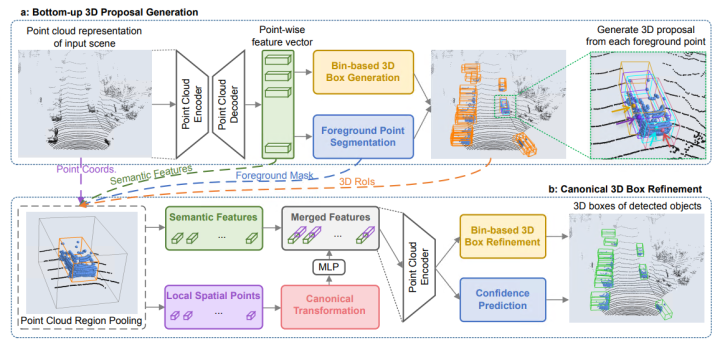
PointRCNN
基于Point系列的3D点云检测器一般逐点检测采样,PointRCNN是领域中比较经典的一篇文章,基于原始密集点云数据直接进行特征提取和RPN操作。论文使用PointNet++网络实现前景与背景分割,主要分为两个阶段。第一阶段生成一大堆很冗余的bounding box。首先,对点云语义分割,对每个点的到一个预测label,比如现在:对所有判断是“车”的点(也叫做前景点),赋予label=1,其他点(也叫做背景点),赋予label=0。然后,用所有前景点生成bounding box,一个前景点对应一个bounding box,但是必须要保证语义分割结果的准确。作者使用了一些去除冗余的方法,继续减少bounding box的数目,这一阶段结束的时候只留下300个bounding box。第二阶段继续优化上一阶段生成的bounding box。首先,对前一阶段生成的bounding box做旋转平移,把这些bounding box转换到自己的正规划坐标系下(canonical coordinates)。然后通过点云池化等操作的到每个bounding box的特征,再结合第一阶段的到的特征,进行bounding box的修正和置信度的打分,从而的到最终的bounding box。网络结构如下所示(结果也是当年的SOTA!):
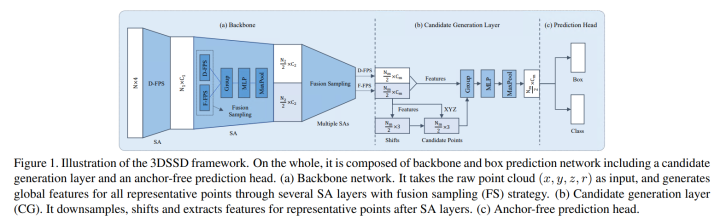
3DSSD
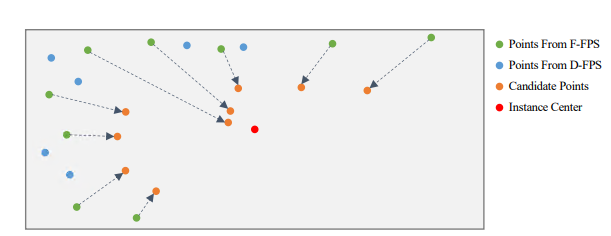
3DSSD作者提出像PointRCNN这种基于原始点云的二阶段3D检测方法,在第一阶段往往利用Set Abstraction层(SA)进行不断的下采样、分组与特征提取,然后利用Feature Propagation层(FP)对SA的输出进行不断上采样与特征传播。利用语义分割获得了前景点后,这些方法以每个前景点为中心进行3D检测框的提议(第一阶段的粗提议)。粗提议结束后,对这些粗提议检测框内部点进行特征提取与处理,微调检测框,获得更精确的检测框(第二阶段的精炼过程)。然而上述的二阶段方法中的FP层和精炼过程在模型前向推理过程中往往会消耗一半以上的时间。那简单地将这些模块删除后(只剩下SA层),然后基于SA提取的特征直接进行单阶段提议是否可行?事实证明有人确实这么做了,但是该简单直接的方法造成了检测精度降低了不少。可能的原因有:现有一些方法在SA层的下采样步骤中用到了D-FPS方法(基于距离的最远点采样法)。该采样方法的特点是:以空间距离最大为原则,不断迭代采样场景的点云,采样后的点云基本覆盖了整个场景(避免了随机采样对密度较高点云簇的青睐)。因为场景中背景点数量偏多,且有些较远目标中的前景点较少,这样的采样方式几乎会过滤掉距离较远的物体的所有前景点。前景点都过滤完了,检测精度自然不会高到哪儿去。因此,作者希望有一个采样方式使得采样的点(记做representative points)既能铺满整个采样空间,又能尽可能地包含更多的前景点,也就是论文中的F-FPS。3DSSD,在精度和效率之间实现了良好的平衡,比前期基于点的检测算法速度提升近1倍,也超越了当时的单阶段所有基于voxel的方法!
文章出处登录后可见!