摘要
跨图像和文本模态的跨模态检索由于其固有的模糊性而成为一项具有挑战性的任务:图像通常表现出各种情况,并且字幕可以与不同的图像相结合。基于集合的嵌入已经被研究作为这个问题的解决方案。它试图将样本编码为一组不同的嵌入向量,这些嵌入向量捕获样本的不同语义。本文提出了一种新的基于集合的嵌入方法,该方法在两个方面与以往的工作有所不同。首先,我们提出了一种新的相似性函数,称为光滑切角相似性,该函数旨在减轻现有相似性函数对基于集嵌入的副作用。其次,我们提出了一个新的集合预测模块来生成一组嵌入向量,该向量通过槽注意机制有效地捕捉输入的不同语义。我们的方法在不同视觉主干的COCO和Flickr30K数据集上进行了评估,其中它优于现有的方法,包括在推理时需要更大计算量的方法。

图1:在跨模态检索任务中介绍了模糊性问题的一个例子;相互对应的图像区域和单词以相同的颜色突出显示。这个例子表明,单个图像可以与多个异构字幕相耦合
简介
为了解决先前工作的上述局限性,我们提出了一种新的基于集合的跨模态检索嵌入方法。所提出的方法与以往的工作主要有两个方面的不同。首先,我们为集合设计了一个方差相似函数,称为平滑切角相似性,用于我们模型的训练和评估。特别地,我们基于平滑切角相似性的损失解决了现有相似性函数的两个局限性,即稀疏监督和集合重叠。其次,我们提出了一个模型,该模型具有一个新颖的受槽注意力激励的集合预测模块[34]。在提出的模块中,称为元素槽的可学习嵌入相互竞争,以聚合输入数据,同时通过渐进更新将其转换为嵌入集。因此,我们的模型成功地捕捉到了输入的不同语义,嵌入集的元素之间几乎没有冗余。对所提出的方法进行了评估,并将其与先前在两个真实的跨模态检索基准点COCO[33]和Flickr30K[43]上的工作进行了比较,在大多数情况下,该方法都优于先前的技术状态。
总之,我们的贡献有三个方面,如下所示:
- 我们通过提出一种新的集合相似性函数,称为平滑切角相似性,来解决以前基于集合的嵌入方法的问题。
- 我们引入了一种基于槽注意力的集合预测模型,其中嵌入集合的元素迭代地相互配合以聚合输入数据,这可以在不重复的情况下捕获输入的语义模糊性。
- 我们的模型在COCO和Flickr30K数据集上实现了最先进的性能。
相关工作
槽点注意力:最近,槽点注意力[34]被提出用于学习以对象为中心的表示,这特别有利于需要感知对象性的任务,如对象发现和集合属性预测。槽是从随机分布中采样的嵌入向量,它们相互竞争以解释迭代方式的输入。这种注意力机制使最终输出能够对出现在输入中的异构语义进行编码,而无需任何明确的监督。为了产生具有足够集内方差的信息嵌入集,我们的集预测模块采用了槽保持机制。然而,槽注意力发现单个物体的能力仅在合成数据集上得到验证[29],并且已知在真实世界的图像上失败[4]。
为了解决这一问题,我们对体系结构进行了三次修改:(1)对初始元素槽使用可学习嵌入,而不是随机向量,(2)用残差和代替GRU[8],以及(3)在最终元素槽中添加全局特征。我们将在第3.2节中详细说明这些差异。如果没有它们,我们观察到损失不会收敛,因此训练失败。
提出的方法
本节首先介绍了整个模型架构,并详细阐述了提出的集合预测模块。然后,我们将介绍平滑-切角相似度,并说明它与现有集合相似度函数的不同之处。最后,我们将详细介绍模型的训练和推理。
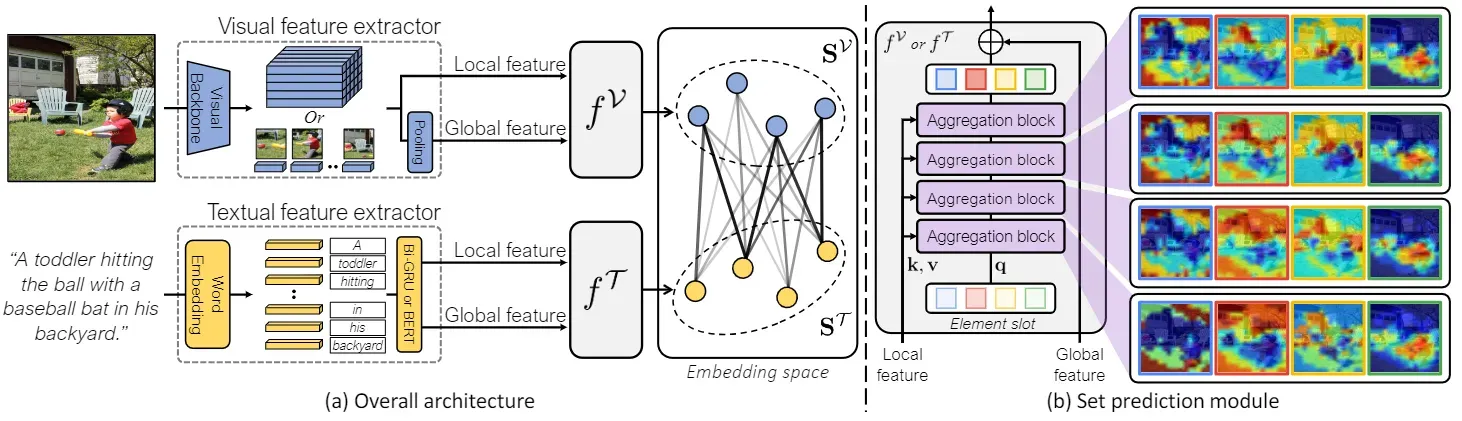
图2:我们的模型概述。(a) 我们模型的总体框架。该模型由三部分组成:视觉特征提取器、文本特征提取器和集合预测模块fV和 fT。首先,每个模态的特征提取器从输入样本中提取局部和全局特征。然后,将特征馈送到集合预测模块以产生嵌入集合SV和ST。使用我们的平滑切角相似性损失训练模型。(b) 我们的集合预测模块的细节和每次迭代的槽产生的注意力图。集合预测模块由多个共享权重的聚合块组成。请注意,fV和 fT具有相同的模型体系结构。
整体模型架构
我们方法的整体框架如图 2 所示。我们的模型架构包括一个视觉特征提取器、一个文本特征提取器以及每个模态的集合预测模块:fV和 fT。特征提取器有两个分支,分别计算输入样本的局部特征和全局特征。提取的特征将作为集合预测模块的输入,每个模块都会融合局部特征和全局特征,以编码一个嵌入集合。对于视觉和文本特征提取器,我们沿用了以往工作中的常规设置 [10, 28, 47]。
视觉特征提取器: 我们考虑了两种不同类型的视觉特征提取器,以便与前人的研究成果进行公平比较。一种采用扁平化卷积特征图作为局部特征,并将其平均集合特征作为全局特征。另一种则使用预训练目标检测器的 ROI 特征作为局部特征,并将其最大集合特征作为全局特征。在上述任何一种情况下,局部特征和全局特征分别用 ψV (x) ∈ RN×D 和 φV (x) ∈ RD 表示,其中 x 为输入图像。
文本特征提取器: 对于文本特征,我们也采用了两种不同类型的提取器:bi-GRU [8] 和 BERT [13]。使用 bi-GRU 时,对于 L 个单词的输入标题 y,我们将每个单词的 GloVe [42] 字嵌入作为局部特征 ψT (y) ∈ RL×300。然后,我们在 ψT (y) 的顶部应用具有 D 维隐藏状态的 bi-GRU。最后一个隐藏状态被用作全局特征 φT (y) ∈ RD。同样,在使用 BERT 时,BERT 的输出隐藏状态及其最大池化特征分别用作 ψT (y) ∈ RL×D 和 φT (y) ∈ RD。
集合预测模块
嵌入集合的元素应编码输入数据中出现的各种语义。否则,它将退化为一个变化很小的集合,无法处理输入数据的模糊性。受槽注意[34]的启发,我们引入了一个聚合块,其中的元素槽相互竞争,以聚合输入数据。通过聚合块的多次迭代,槽会逐步更新,以捕捉输入的各种语义,然后将槽与全局特征融合,作为输出嵌入集的元素。通过这种方式,提出的模块可以生成一个嵌入集,其元素编码的语义大不相同,同时保留了输入数据的全局上下文。在本节中,我们仅介绍视觉集合预测模块 fV的工作原理;fT与 fV具有相同的模型架构和工作方式。
如图 2(b) 所示,提出的集合预测模块由多个聚合块组成,这些聚合块共享权重。

平滑切角相似性
我们提出平滑切角相似性是为了解决现有基于集合的嵌入方法的缺点。在介绍平滑切角相似性之前,我们首先回顾一下 PVSE [47] 和 PCME [10] 中使用的相似性函数。图 3 展示了使用这些集合相似性函数训练的嵌入空间。c(x, y) 和 d(x, y) 分别表示向量 x 和 y 之间的余弦相似度和ℓ2 归一化欧氏距离。
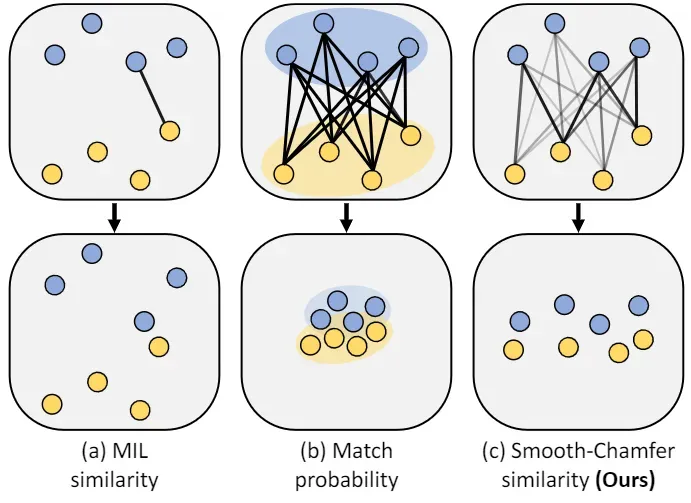
图3。我们的相似函数和现有的用于嵌入集合的相似函数之间的比较。给出了优化每个相似函数前后的嵌入空间的说明。所提出的两个集合是匹配的对,因此进行了优化以最大化它们的相似性。线条表示相似函数所考虑的关联,其中它们的强度表示赋予每个关联的权重。
PVSE 在训练和推理过程中采用了多实例学习(MIL)框架 [15]。它的相似性函数(我们称之为 MIL 相似性)为 sMIL(S1, S2) = maxx∈S1,y∈S2 c(x,y)。MIL 相似性只考虑最近的一对元素,如图 3(a) 所示。虽然这种行为简化了相似性测量,但 MIL 相似性存在稀疏监督问题。换句话说,大多数元素都没有作为最近的一对元素进行采样,因此仍未经过训练。
另一方面,PCME 使用匹配概率 (MP) 作为相似性函数,其定义为 sMP(S1, S2) = P x∈S1,y∈S2 σ(αd(x, y) + β),其中 α 和 β 是可学习的参数,σ 是 sigmoid 函数。MP 取元素间每对距离的平均值。虽然 MP 解决了稀疏监督问题,但也带来了集合折叠问题。如图 3(b)所示,直接优化 MP 会导致嵌入集坍塌,因为嵌入集中的元素会相互拉扯,而不考虑它们之间的相对距离。
为了缓解这一问题,MP 需要专门的损失函数[10, 40],这使得 MP 与其他损失函数或框架不兼容。上述问题源于相似性函数关联集合元素的方式。与这些相似性函数不同的是,我们的平滑切角相似性函数对每一对可能的元素都赋予了不同的权重,如图 3(c)所示。 平滑切角相似度的公式为

LSE 表示 Log-Sum-Exp,是最大值函数的平滑近似值。由于 LSE 的特性,平滑切角相似性可以将一个集合中的元素软分配给另一个集合中的元素,其中一对元素的权重由它们的相对接近程度决定。因此,平滑切角相似性可以提供像 MP 一样的密集监督,但没有折叠问题。用 max 函数代替 LSE 后,我们可以考虑平滑切角相似性的非平滑版本,我们称之为切角相似性。切角相似性通过将 S1 中的单个元素分配给其在 S2 中的近邻,反之亦然,从而解决了集合折叠的问题。然而,与平滑切角相似性不同的是,它不能提供像 MP 那样密集的监督,因为大多数关联都没有考虑在内。平滑切角相似性的行为可以通过其相对于 c(x,y)的梯度清楚地表现出来,其梯度为
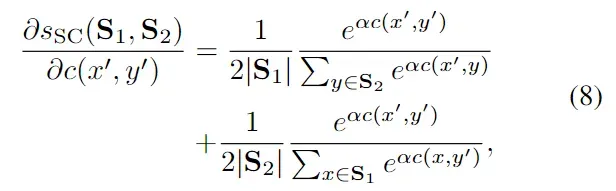
其中 x′ 和 y′ 分别是 S1 和 S2 的元素。可以看出,梯度是两个相对相似性得分之和,这表明当 x′ 和 y′ 相近时,c(x′,y′)的梯度会得到强调。利用基于相对邻近度的加权方案,我们可以在训练过程中给予更密集的监督,同时保留足够的集内方差。
训练和推理
训练: 我们的模型使用文献[47]中提出的目标函数进行训练,其中包括三重损失、多样性正则和最大平均差异(MMD)[20]正则。根据之前的工作[17, 47, 51],我们采用了带有硬负挖掘的三重损失。
推理:我们预先为数据库中的每个样本计算大小为 K 的嵌入集。然后,利用平滑切角相似度,通过嵌入集上的最近邻搜索,检索出与查询最相关的样本。
实验
数据集和评估指标
我们在 COCO [33] 和 Flickr30K [43] 数据集上验证了我们方法的有效性。在这两个数据集中,我们都采用了 [30] 提出的拆分方法。
实现细节
特征提取器: 对于视觉特征提取器,卷积视觉特征是通过对 CNN 的最后一个特征图进行 1 × 1 卷积而获得的。我们按照文献[28]的方法,将从 Faster R-CNN[44] 中预先提取的特征[1]输入带有残差连接的 2 层 MLP,从而获得 ROI 视觉特征。在每个模型中,我们将 D 设为 1024,K 设为 4。
设置预测模块: 使用卷积视觉特征时,Dh 设为 1024,否则设为 2048。相似性和损失函数: 对于 smooth-Chamfer 相似性,我们将缩放参数 α 设为 16。在 Ltri 中,我们对卷积视觉特征使用 0.1 的边距δ,对 ROI 视觉特征使用 0.2 的边距δ。我们将 0.1 和 0.01 的系数分别乘以 Ldiv 和 Lmmd。
训练: 使用 AdamW 优化器[36]对模型进行训练。我们用 200 张图片及其所有标题构建输入批次。当使用 ROI 视觉特征时,模型的初始学习率为 1e-3,用余弦退火法[35]训练 80 个 epochs。对于采用卷积视觉特征的模型,我们沿用了之前工作中的训练设置[28, 47],这将在补充材料中详细讨论。
与其他方法的比较
在 COCO 和 Flickr30K 上的结果分别汇总于表 1 和表 2。为了与之前的工作进行公平比较,我们的方法在三种不同的视觉提取器下进行了评估: 在 ImageNet [11] 上预先训练的 ResNet-152 [22]、由 Faster RCNN [44] 预先提取的 ROI 特征 [1],以及在 Instagram [37] 数据集上预训练的 ResNeXt-101 [52]。ResNet-152 和 ResNeXt-101 的输入图像分辨率分别设置为 224 × 224 和 512 × 512,沿用了之前的研究成果[28, 47]。对于文本特征提取器,我们使用 bi-GRU 或 BERT。集合结果是通过平均使用不同随机种子训练的两个模型的相似性得分得到的。
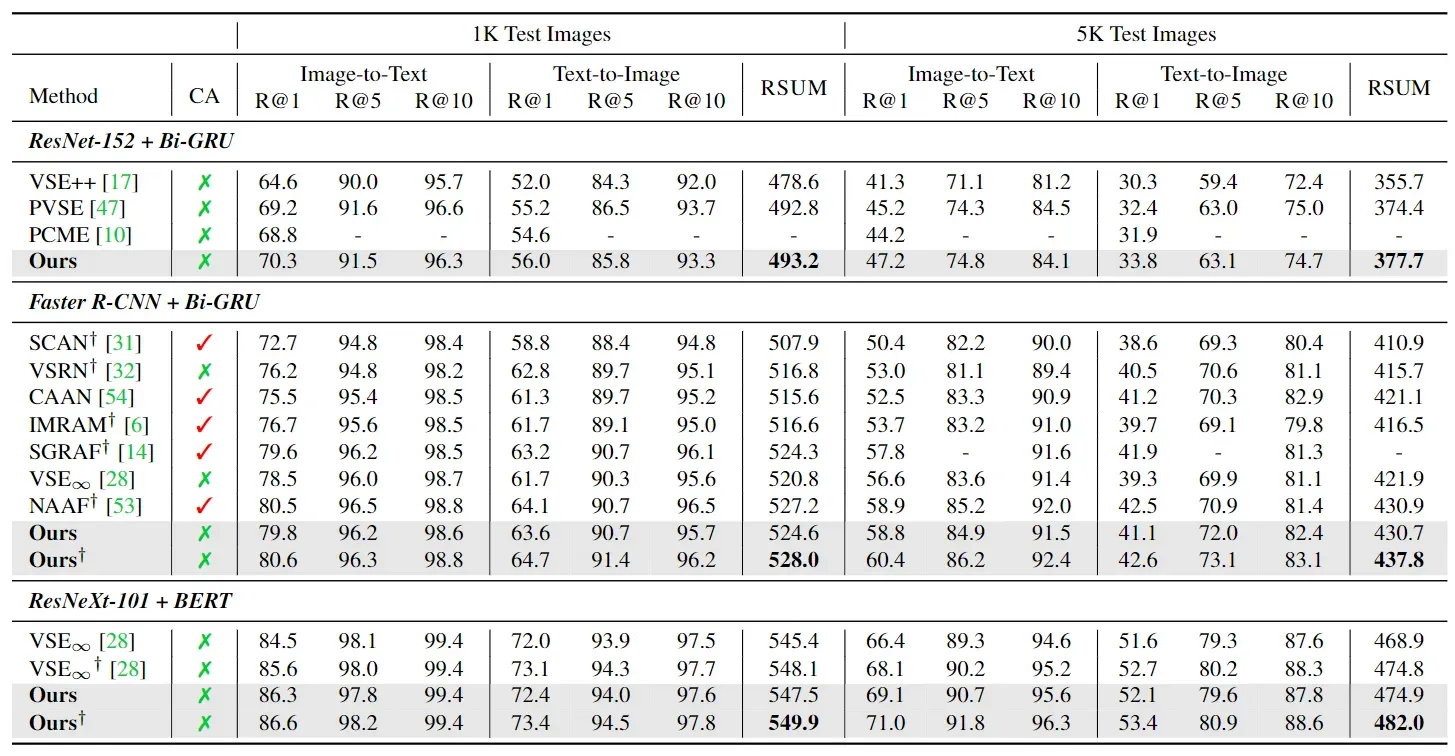
表 1. COCO 数据集上的 Recall@K (%) 和 RSUM。表中列出了 1K 测试环境(5 倍测试数据集的平均值)和 5K 测试环境的评估结果。最佳 RSUM 分数以粗体标出。CA 和 † 分别表示使用交叉注意模型和两个假设的集合模型。
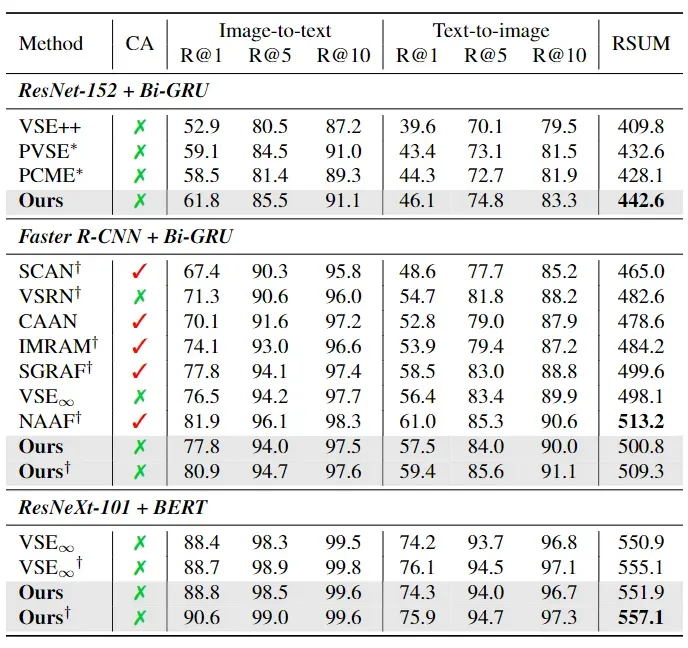
表 2. Flickr30K 数据集上的 Recall@K(%) 和 RSUM。CA、† 和 * 分别表示使用交叉注意的模型、两个假设的集合模型和我们重现的模型。
除了带有 ROI 视觉特征的 Flickr30K 外,我们的方法在每种情况下的 RSUM 都优于之前的方法。即使在这种情况下,我们的方法也取得了第二名的好成绩。需要注意的是,NAAF 目前在这种情况下是最好的,但它在推理时需要的计算量比我们的方法多两个数量级,因为它依赖于交叉注意,这将在下一节中说明。我们与 ResNeXt-101 和 BERT 的集合明显优于所有现有记录,在 COCO 5K 和 Flickr30K 上分别将之前的最佳 RSUM 提高了 7.2%p 和 2.0%p。与 PVSE 和 PCME 的比较证明了我们基于集合的嵌入框架的优越性。我们的模型在任何情况下都优于它们。具体来说,与 PVSE 相比,我们的模型在 COCO 5K 和 Flickr30K 上的 RSUM 分别提高了 3.3%p 和 10.0%p。此外,我们的方法比涉及交叉注意力网络的模型 [6, 14, 31]显示出更好的结果,因为交叉注意力网络需要大量的计算。最后我们要强调的是,我们使用单一模型的方法往往优于之前使用集合模型的方法[6, 14, 31, 32]。
计算成本分析
为了证明我们的模型在评估时间内的效率,我们测量了计算图像和缩略图之间的相似度得分所需的 FLOP。 我们的方法需要 16.4K FLOPs,而 SCAN [31](一种具有代表性的交叉关注方法)需要 1.24M FLOPs。 这一结果表明,我们的方法比 SCAN 所需的浮点运算少 80 倍,因为交叉关注需要对每次查询的图像或字幕表示进行重新处理。此外,值得注意的是,我们的方法在 RSUM 方面优于 SCAN,具体见表 1 和 2
关注度分析
在图 4 中,我们直观地展示了来自 fV中最后一个聚合块的关注度。 每个注意力用于编码图像嵌入集的单个元素。 对于每个元素,其在嵌入空间中最接近的标题都会被预先发送到一起。 由于采用了插槽注意力,集合预测模块可以生成异构注意力图,这些注意力图聚焦于单个对象或上下文,从而可以检索到不同的标题。 特别是在右上方,元素与描述不同语义(头盔、儿童、公园和自行车)的标题相匹配。有趣的是,我们观察到其中一个元素插槽在其他插槽捕捉到独特语义后,会关注被遗漏的区域,这对于检索相关但高度抽象的字幕来说是完全收费的。

图 4. 对于图像嵌入集的每个元素,我们都会展示其注意力图谱以及在嵌入空间中与该元素最接近的标题。匹配的标题用绿色表示。与注意力图谱相对应的实体以下划线表示。
消融研究
我们进行了消融研究,以调查所提出的相似性函数和集合预测模块的贡献。
在所有消融实验中,我们都使用了采用 ROI 视觉特征的模型。
设置相似性函数的重要性: 在表 3 左侧,我们消融了提出的相似性函数,并用 MP、MIL 和倒角相似性函数取而代之。结果表明,在相同的集合预测架构下,使用平滑切角相似性训练的模型超过了使用 MIL 或 MP 相似性训练的模型。虽然 切角相似性通过解决集合折叠问题提高了性能,但平滑切角相似性通过在训练过程中提供密集监督进一步提高了性能。
集合预测模块的重要性: 我们还删除了提出的集合预测模块,并用 PIE-Net 代替,PIE-Net 是之前基于集合的嵌入方法 PVSE 和 PCME 的基准集合预测架构。表 3 左侧的结果表明,我们的集合预测模块效果显著。
集合折叠验证: 在表 3 右侧,我们报告了嵌入集的平均循环方差。形式上,嵌入集 S 的循环方差表示为 1-∥P x∈S x/|S|∥2。如前所述,结果表明,使用 PIE-Net 或 MP 会导致集合崩溃。此外,我们还报告了将聚合块替换为transformer时的结果。这种变体的线性方差降低了 13%,但由于不能保证元素间的不纠缠,因此性能较差。
超参数的影响
在表 4 中,我们报告了在改变嵌入集的基数 K、迭代总数 T 和缩放参数 α 时模型的 RSUM。结果表明,当 K > 3、T > 2 和 α > 4 时,模型的 RSUM 一直很高。具体来说,我们注意到,当 K = 1 时,也就是使用单一嵌入向量时,模型的准确度明显低于其他模型。这表明,嵌入集可以通过解决语义模糊问题实现更准确的检索。如图 2 所示,当 T = 1 时,我们观察到准确率大幅下降,这说明多个聚合块进行的渐进式细化有助于元素槽聚合语义实体。
嵌入集元素分析
为了进一步分析嵌入集元素,我们在评估模型时只使用其中一个元素。假设 S(i) 是由第 i 个元素槽生成的 S 元素。表 5 总结了在评估过程中删除 SV 和 ST 元素时,模型在 RSUM 方面的准确性。结果表明,只使用其中一个元素会降低精度。具体来说,与使用其他元素相比,在评估过程中仅使用 SV (2) 会导致精确度大大降低。为了检验 SV (2) 是否只是一个妨碍最终性能的噪声元素,我们还报告了只删除 SV (2) 时的 RSUM。然而,有趣的是,与使用完整的嵌入集相比,我们仍然观察到了精度的下降。虽然其中一个元素经常会检索到不匹配的样本,但结果表明,在评估过程中同时使用这两个元素有助于模型找到准确的匹配样本。我们假设 SV (2) 是为捕捉高度模糊的语义而训练的。因此,在评估过程中单独使用它们会导致检索的准确性降低,而同时使用它们时,则会通过成功表现模糊的情况和上下文来提高性能。在图 4 中也可以观察到类似的趋势,其中一个插槽经常编码的元素位于嵌入空间中相关但高度模糊的标题附近。
结论
我们提出了用于跨模态检索的新型集合嵌入框架,它由集合预测模块和平滑切角相似性组成。提出的集合预测模块能输出成功捕捉模糊性的嵌入集合,而平滑切角相似性能成功解决现有相似性函数的不良影响。因此,在 COCO 和 Flickr30K 数据集上,我们的模型超越了之前的大多数方法,包括计算成本较高的方法。今后,我们将针对不同的模态和任务扩展我们的模型。
实现细节请看附录
文章出处登录后可见!