Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery
论文地址
代码地址
一、总体介绍
1.摘要
地理空间目标分割是一项特殊的语义分割任务,在高空间分辨率(HSR)遥感图像中,总是面临着较大的尺度变化、较大的背景类内方差和前景-背景不平衡。然而,一般的语义分割方法主要关注自然场景中的尺度变化,而没有充分考虑到大面积地球观测场景中经常出现的另外两个问题。本文认为这些问题是由于缺乏前景建模,并从基于关系和基于优化的前景建模的角度提出了一个前景感知关系网络(FarSeg),以缓解上述两个问题。从关系的角度来看,FarSeg通过学习前景-场景关系所关联的前景相关上下文,增强了对前景特征的识别能力。同时,从优化的角度出发,提出了一种前景感知优化方法,重点研究了平衡优化训练过程中的前景样本和背景的难样本。利用大规模数据集获得的实验结果表明,该方法优于现有的通用语义分割方法,并在速度和准确性之间实现了更好的权衡。
2.引言
与自然场景相比,HSR遥感图像的地理空间目标分割更具挑战性。至少有三个原因:
- 物体在HSR遥感图像中总是有更大尺度的变化。这就导致了多尺度问题,使得定位和识别物体很困难。
- HSR遥感图像的背景要复杂得多,由于类内方差较大,会导致严重的误报。
- 前景比例比在自然场景影像中小得多,导致了前景背景的不平衡,如图1所示。
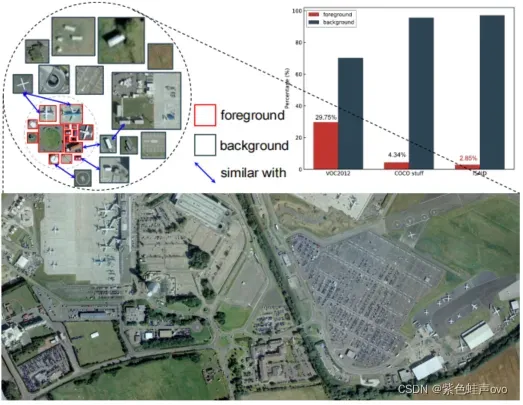
图1.HSR遥感图像中目标分割的主要挑战。(1)更大尺度的变化。(2)前景-背景失衡。(3)背景的类内方差。
本文提出了一种前景感知关系网络(FarSeg)来解决上述两个问题,利用明确的前景建模在HSR遥感图像中进行更鲁棒的目标分割。文中探讨了明确的前景建模的两个视角:基于关系的前景建模和基于优化的前景建模,并进一步在FarSeg中提出了两个模块:前景-场景关系模块和前景感知优化。前景-场景关系模块学习场景与前景之间的共生关系,将与前景相关的上下文关联起来,从而增强前景特征,从而减少误报。前景感知优化通过抑制大量简单的背景例子,将模型集中在前景上,以缓解前景-背景不平衡问题。
主要贡献如下:
- 提出了一种用于HSR遥感图像地理空间对象分割的前景感知关系网络(FarSeg)。
- 为了继承多尺度上下文建模和学习地理空间场景表示,FarSeg构建了基于特征金字塔网络(FPN)的前景分支,并在共享主干网络上建立场景嵌入分支,即多分支编码器。
- 为了抑制误报,F-S关系模块利用了地理空间场景与地理空间对象之间的共生关系,将与前景相关的上下文关联起来,增强了对前景特征的识别能力。同时,没有任何贡献的背景被这种共生关系所抑制,从而抑制了误报。
- 为了缓解前景-背景之间的不平衡,提出了F-A优化方法,将网络逐步集中在难样本上,从而降低许多简单样本对梯度的贡献,为前景-背景平衡训练。
3.前景感知关系网络 (Foreground-Aware Relation Network)
为了明确HSR遥感图像中目标分割的前景建模,我们提出了一个前景感知关系网络(FarSeg),如图2所示。所提出的FarSeg由特征金字塔网络(FPN)、前景场景(F-S)关系模块、轻量级解码器和前景感知(F-A)优化组成。FPN负责多尺度的目标分割。在F-S关系模块中,我们首先将假报警问题表述为前景中缺乏识别信息的问题,然后引入潜在场景语义和F-S关系来提高前景特征的识别能力。轻量级解码器的设计旨在恢复语义特征的空间分辨率。为了使网络在训练过程中关注前景,提出了F-A优化方法来缓解前景-背景不平衡问题。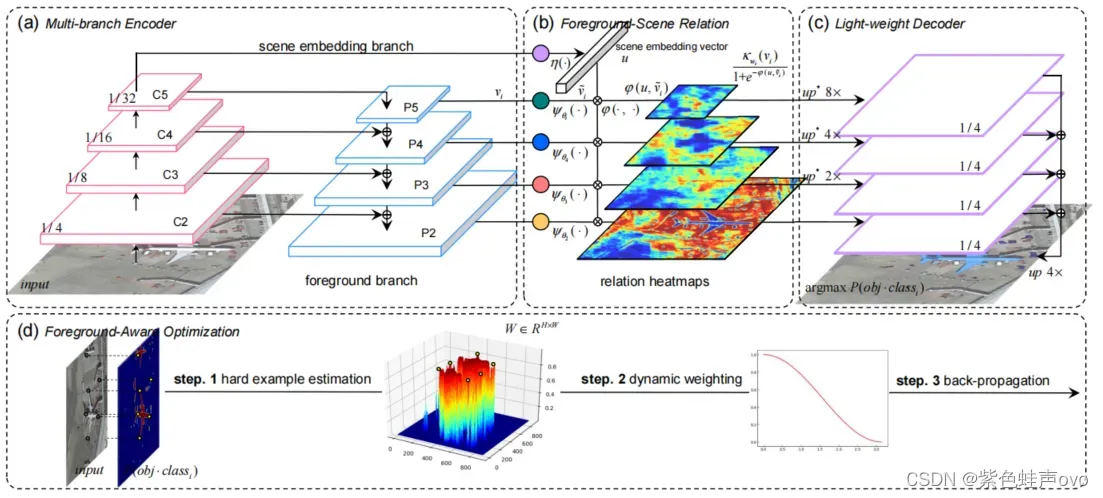 图2.FarSeg框架。(a)多分支编码器,用于多尺度目标分割。(b)前景-场景关系模块。©轻型解码器。(d)前景感知优化。黄点表示难样本在原始图像、概率图和预测曲面中的相对位置。
图2.FarSeg框架。(a)多分支编码器,用于多尺度目标分割。(b)前景-场景关系模块。©轻型解码器。(d)前景感知优化。黄点表示难样本在原始图像、概率图和预测曲面中的相对位置。
3.1 多路径编码(Multi-Branch Encoder)
多分支编码器由前景分支和场景嵌入分支组成。如图2(a)所示,这些分支都建立在一个主干网络之上。在该方法中,选择ResNets作为基本特征提取的主干网络。表示从ResNets中提取的特征映射集,其中特征映射
相对于输入图像具有
个像素的输出步幅。与最初的FPN相似,自上而下的路径和横向连接被用于生成相同数量的通道
的金字塔特征图
。公式如下:
其中,表示由可学习的1×1卷积层实现的横向连接,
表示尺度因子为2的最近邻上采样。通过这种由上而下的路径和横向连接,可以利用浅层的高空间细节和深层的强语义来增强特征图,有助于恢复对象的细节和多尺度上下文建模。除了金字塔形特征图
外,在
上还附加了一个额外的分支,通过全局上下文聚合生成一个地理空间场景特征
。为简单起见,我们使用全局平均池化作为聚合函数。
用于模拟地理空间场景与前景之间的关系,如第3.2节所示。
3.2.前景-场景关系模块(Foreground-Scene Relation Module)
HSR遥感图像的背景要复杂得多。这意味着背景中存在较大的类内方差,导致误警问题。为了解决这一问题,提出了前景场景(F-S)关系模块,通过关联与地理空间场景相关的上下文来提高前景特征的识别能力。其主要思想如图3所示。F-S关系模块首先明确地建模前景与地理空间场景之间的关系,并利用潜在的地理空间场景将前景与相关上下文关联起来。然后利用该关系来增强输入特征图,以增加前景特征与背景特征之间的视差,从而提高前景特征的分辨能力。
如图2(b)所示,对于金字塔形特征图,F-S关系模块将生成一个新的特征图
。通过对
进行重新编码,然后使用关系映射
对其进行重新加权,得到了特征映射
。关系映射
是地理空间场景表示与前景表示之间的相似性矩阵。为了将这两个特征表示对齐成一个共享的流形
,需要分别学习地理空间场景和前景的两个投影函数。
是特征图
由尺度感知投影函数
转换得到的,如公式2所示。
其中,为
的可学习参数。采用了一种简单的
形式,由1×1卷积层实现,然后按批归一化和ReLU的顺序实现。为了计算关系映射
,需要一个一维场景嵌入向量
来与前景进行交互共享流形中的特征映射{v_i}。在
上应用
计算场景嵌入向量
。
其中,为地理空间场景表示的投影函数,由一个可学习的1×1卷积层实现,输出通道为
。每个金字塔的场景嵌入向量
都是共享的,因为潜在的地理空间场景语义是跨越所有金字塔的尺度不变的。因此,关系映射
可以自然地得到。
其中表示相似的估计函数,为了简单和高效的计算复杂度,它采用点内积实现。对于每个金字塔层,关系建模的过程细节如图4所示,关系增强的前背景特征图
的计算方法如下:
其中,是具有输入特征映射vi的可学习参数
的编码器。该编码器的设计是为了引入一个额外的非线性单元,以避免特征退化,因为加权操作是一个线性函数。因此,我们采用该编码器的简单形式,通过1×1卷积层实现,然后批归一化和ReLU实现高效的参数和计算。5用于对重新编码的特征映射进行加权,这是使用基于一个简单的自门控机制的
的归一化关系映射。
3.3轻量级解码器(Light-weight decoder)
轻量级解码器以轻量级方式从F-S关系模块中恢复关系增强语义特征映射的空间分辨率。轻量级解码器的详细体系结构如图5所示。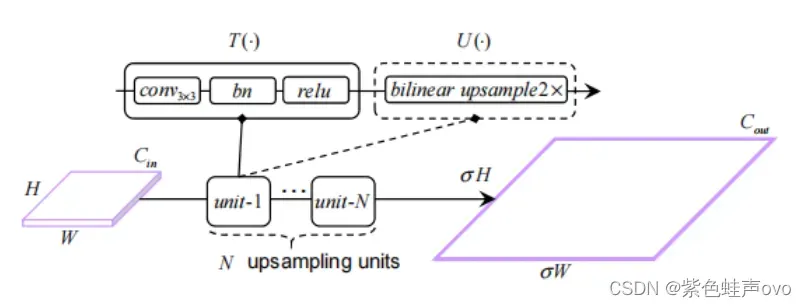
图5.针对每个金字塔级别的轻量级解码器的抽象体系结构。
给定来自关系模块的金字塔特征映射
,通过轻量级解码器计算上采样特征映射
。轻量级的解码器由许多上采样单元堆叠起来。上采样单元由一个通道转换
和一个可选的
上采样操作
组成,如果比例因子为
,则只包括
。因此,金字塔级i的轻量级解码器可以简单地表述为:
其中,为上采样单位数,
。
由
卷积层实现,然后是批处理归一化和
。
是比例因子为2的双线性上采样。总上采样尺度
等于
,因为输出步幅为4。为了聚合每个金字塔的上采样特征图,采用点平均运算和1×1卷积层进行计算和参数效率。采用4×双线性上采样,得到与输入图像大小相同的最终类概率图。
3.4。前景感知优化 (Foreground-Aware Optimization)
前景-背景不平衡问题通常会导致背景在训练过程中主导梯度。然而,在背景样本中,只有难样本部分对于训练后期的优化是有价值的,难样本比简单样本要少得多。在此基础上,提出了前景感知优化,使网络关注前景和难样本进行平衡优化。前景感知优化包括三个步骤:难样本估计、动态加权和反向传播,如图2(d).所示。
难样本估计。这一步用于获得反映实例的困难程度的权重,以调整像素级损失的分布。样本更难了,意味着权重更大。受的激励,采用
作为权重来估计困难的例子,其中
是网络的预测概率,
是聚焦因子。该公式用于目标检测,但对于前景-背景不平衡的像素级任务,我们只期望调整损失分布而不改变和,以避免梯度消失。因此,我们推广它的对象分割HSR遥感图像通过引入一个归一化常数Z保证
,其中
表示第
个像素的交叉熵损失。对于每个像素的损失,它的权重为
。
动态加权。硬例估计依赖于模型的判别。然而,在训练的初始阶段是不自信的,也会造成难例估计不自信。如果使用这种不自信难例权值,模型训练将是不稳定的,影响收敛性能。为了解决这一问题,我们提出了一种基于退火函数的动态加权策略。我们设计了三个退火函数作为候选项,如表1所示。给定交叉熵损失,动态加权损失表示为:

实验
实验部分对基于方法添加F-S模块、在不同尺度金字塔层进行场景嵌入、F-S关系模块的视觉解释以及对前景感知优化中的归一化和退火优化进行了消融实验,实验结果详实,具有说服力。同时论文还说明了该模型在效率性能上的优势。
二、方法分析与总结
核心代码
class SceneRelation(nn.Module):
def __init__(self,in_channels,channel_list,out_channels,scale_aware_proj=True):
super(SceneRelation, self).__init__()
self.scale_aware_proj = scale_aware_proj
if scale_aware_proj:
self.scene_encoder = nn.ModuleList(
[nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.ReLU(True),
nn.Conv2d(out_channels, out_channels, 1),
) for _ in range(len(channel_list))]
)
else:
# 2mlp
self.scene_encoder = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1),
nn.ReLU(True),
nn.Conv2d(out_channels, out_channels, 1),
)
self.content_encoders = nn.ModuleList()
self.feature_reencoders = nn.ModuleList()
for c in channel_list:
self.content_encoders.append(
nn.Sequential(
nn.Conv2d(c, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU(True)
)
)
self.feature_reencoders.append(
nn.Sequential(
nn.Conv2d(c, out_channels, 1),
nn.BatchNorm2d(out_channels),
nn.ReLU(True)
)
)
self.normalizer = nn.Sigmoid()
def forward(self, scene_feature, features: list):
content_feats = [c_en(p_feat) for c_en, p_feat in zip(self.content_encoders, features)]
if self.scale_aware_proj:
scene_feats = [op(scene_feature) for op in self.scene_encoder]
relations = [self.normalizer((sf * cf).sum(dim=1, keepdim=True)) for sf, cf in
zip(scene_feats, content_feats)]
else:
scene_feat = self.scene_encoder(scene_feature)
relations = [self.normalizer((scene_feat * cf).sum(dim=1, keepdim=True)) for cf in content_feats]
p_feats = [op(p_feat) for op, p_feat in zip(self.feature_reencoders, features)]
refined_feats = [r * p for r, p in zip(relations, p_feats)]
return refined_feats
编码过程为常用的特征金字塔结构,论文作者采用了循环的方式来定义模型,代码显得十分整洁。重点在于F-S关系的构建,通过特征金字塔得到scene features和content features(为一列表)。在关系模块中,如果考虑尺度,则需要先对scene features在每个尺度上编码再和content features进行作用,否则只获取最后的scene features进行关系建模。关系模块中最重要的一点,也是论文思想精髓所在,就是content features总是和潜在的场景有关,如飞机场这一场景总是和飞机与其周围的机场设施相关,但是也包含了大量背景信息。
代码中在不同尺度上将scene features 和content feature 做一个类似注意力的操作,以此作为权重对特征金字塔的特征进行加权(注意这里使用投影函数即1*1卷积核对齐了通道)。经过批归一化和ReLU激活,特征图关系值会分布在之间, 而sigmoid函数是一个增函数,将
之间的值映射到了
之间,即将正关系进行了增强,得到增强后的特征图。个人感觉这是论文的一大精髓所在,看起来还是十分简单的,但是思路确实清晰,这就是idea啊!注意到场景特征
是由特征金字塔的最后一层特征经过一次全局平均池化得到的,论文中没有提到,读者需要阅读代码明确这一步。
class FarSeg(CVModule):
def __init__(self, config):
super(FarSeg, self).__init__(config)
self.register_buffer('buffer_step', torch.zeros((), dtype=torch.float32))
self.en = resnet.ResNetEncoder(self.config.resnet_encoder)
self.fpn = fpn.FPN(**self.config.fpn)
self.decoder = AssymetricDecoder(**self.config.decoder)
self.cls_pred_conv = nn.Conv2d(self.config.decoder.out_channels, self.config.num_classes, 1)
self.upsample4x_op = nn.UpsamplingBilinear2d(scale_factor=4)
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
if 'scene_relation' in self.config:
print('scene_relation: on')
self.gap = scm.GlobalAvgPool2D()
self.sr = SceneRelation(**self.config.scene_relation)
if 'softmax_focalloss' in self.config:
print('loss type: softmax_focalloss')
if 'cosineannealing_softmax_focalloss' in self.config:
print('loss type: cosineannealing_softmax_focalloss')
if 'annealing_softmax_focalloss' in self.config:
print('loss type: {}'.format(self.config.annealing_softmax_focalloss.annealing_type))
def forward(self, x, y=None):
feat_list = self.en(x)
fpn_feat_list = self.fpn(feat_list)
if 'scene_relation' in self.config:
c5 = feat_list[-1]
c6 = self.gap(c5)
refined_fpn_feat_list = self.sr(c6, fpn_feat_list)
else:
refined_fpn_feat_list = fpn_feat_list
final_feat = self.decoder(refined_fpn_feat_list)
cls_pred = self.cls_pred_conv(final_feat)
cls_pred = self.upsample4x_op(cls_pred)
整体上模型确实给人一种轻量的印象:代码真的很简洁!读下来让人佩服论文作者的思路,能够从一个很简单常见的问题出发,给出十分简洁明了的解决办法,最后代码还这么easy易读,科研动力立马上来了有木有!另外,论文作者还进行了难例估计和退火优化,代码在损失函数部分,就不在这里叙述了。感兴趣的读者可以继续深入学习!欢迎大家批评指正~!
文章出处登录后可见!