授权声明: 本文基于九天Hector的原创课程资料创作,已获得其正式授权。
原课程出处:九天Hector的B站主页,感谢九天Hector为学习者带来的宝贵知识。
请尊重原创,转载或引用时,请标明来源。
全文共7000余字,预计阅读时间约15~30分钟 | 满满干货(附代码),建议收藏!
本文目标:理解OpenAI提供的Completions模型类,熟悉其调用方法和调参技巧,通过实现一个多轮对话的聊天机器人,提供一种基于Completions模型开发上层应用的思路。
代码下载点这里
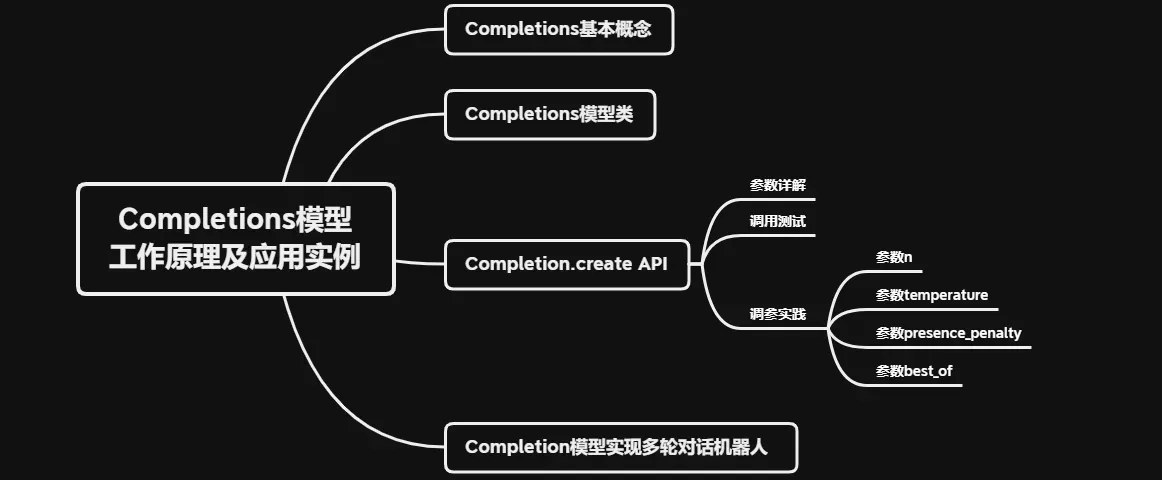
一、 Completions基本概念
对于先进的深度学习模型,它们通常通过大量的文本数据进行训练,掌握语法关系和多种表达风格。在这个基于广泛语义空间的训练过程中,这些模型不仅学习了基本的文本模式,还会经过微调,更好地适应特定的人类意图。当模型作出预测时,其本质是根据给定的输入(或称为提示)来产生对应的文本输出。通常,这样的模型的训练会分为两个主要阶段:
- 阶段一:预训练
在这个阶段,模型使用大量未标记的文本进行训练,如在线收集的书籍和文章。这一步主要是进行语言模型训练,使模型能预测给定上下文中的下一个单词,从而掌握词汇、语法和基本知识。
- 阶段二:微调
预训练完成后,模型会在特定任务的数据上进行进一步的训练。例如,对于一个问答任务,可以提供成对的问题和答案来调整模型,从而在该任务上达到更好的效果。
OpenAI公司的GPT系列模型在NLP领域中是领先的。它为开发者提供了API接口,允许开发者向模型发送文本提示,并获得模型的响应,意味着开发者可以无需自行训练和部署大型模型,而是直接利用OpenAI的服务。
所谓的“Completions”模型实际上是指OpenAI基于其GPT系列模型提供的自动文本补全能力。这种模型不仅可以自动生成和补全文本,还可以回答问题、撰写文章等。此过程,即根据提示生成相应文本的机制,被称为“Completion”。因此,能够执行此功能的模型被称为“Completion模型”。例如,经过RLHF微调后基于text-davinci-002模型的text-davinci-003,就是这样的一个Completion模型。
总的来说:Completions 是 OpenAI 提供的 API,以用来生成文本,Completions API 主要用于补全问题,用户输入一段提示文字,模型按照文字的提示给出对应的输出。
二、 Completions模型类
截至目前,OpenAI官网发布的Completions模型类如下:
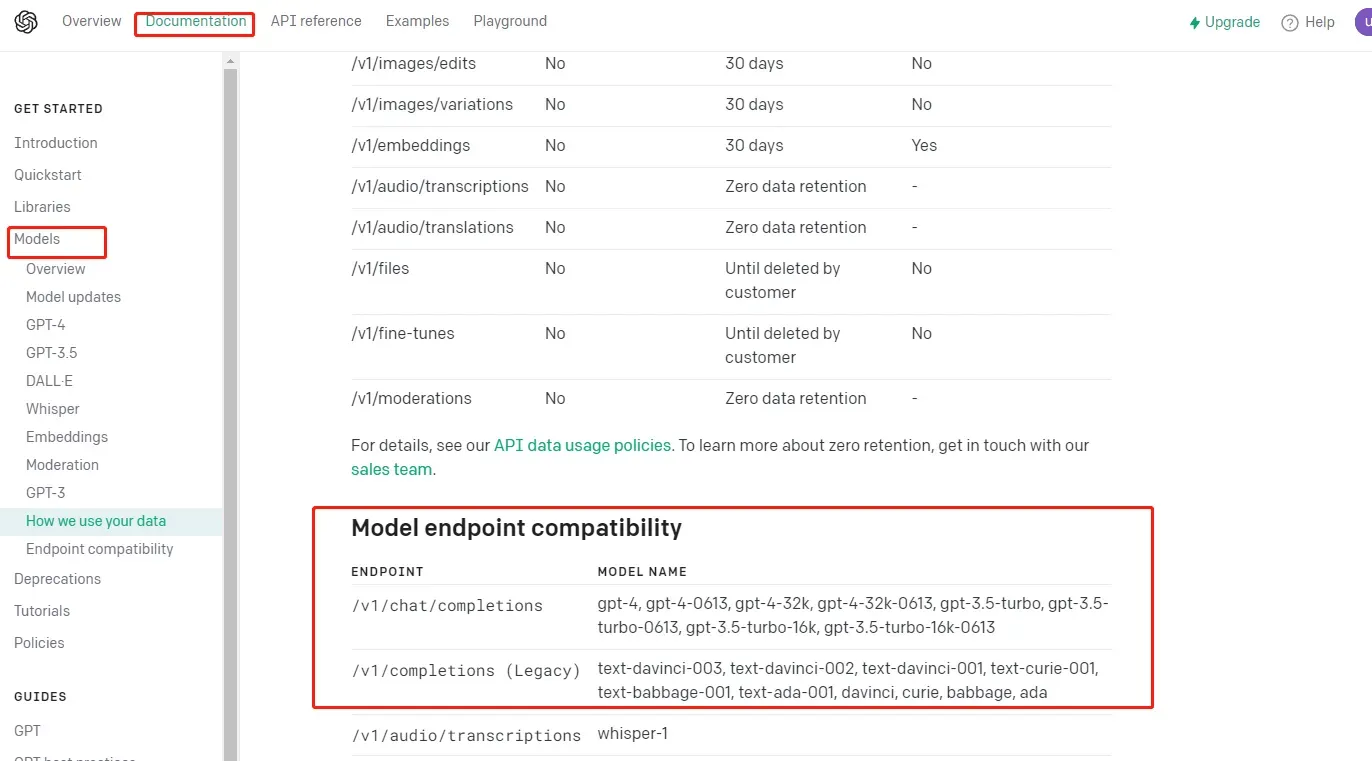
OpenAI发布的带有”text”标识的A、B、C、D四大类模型都属于Completions模型系列,即GPT-3系列模型。GPT-3.5和GPT-4则被定义为Chat Completions模型。
从功能角度来看,Completions模型具有更基础且全面的功能,而且它是唯一一个OpenAI提供微调接口的模型。相反,Chat Completions模型则是一种更专业、更先进的模型。每种模型都有其独特的应用场景。本文先主要讲解Completions模型的参数及用法。
三、 Completion.create API
3.1 参数详解
在OpenAI提供的在线大模型中,所有的Completions模型都需要通过Completion.create进行调用,并在实际调用的过程中通过超参数设置对应的调用模型及模型相关参数。
看下OpenAI官网给出的参数列表:
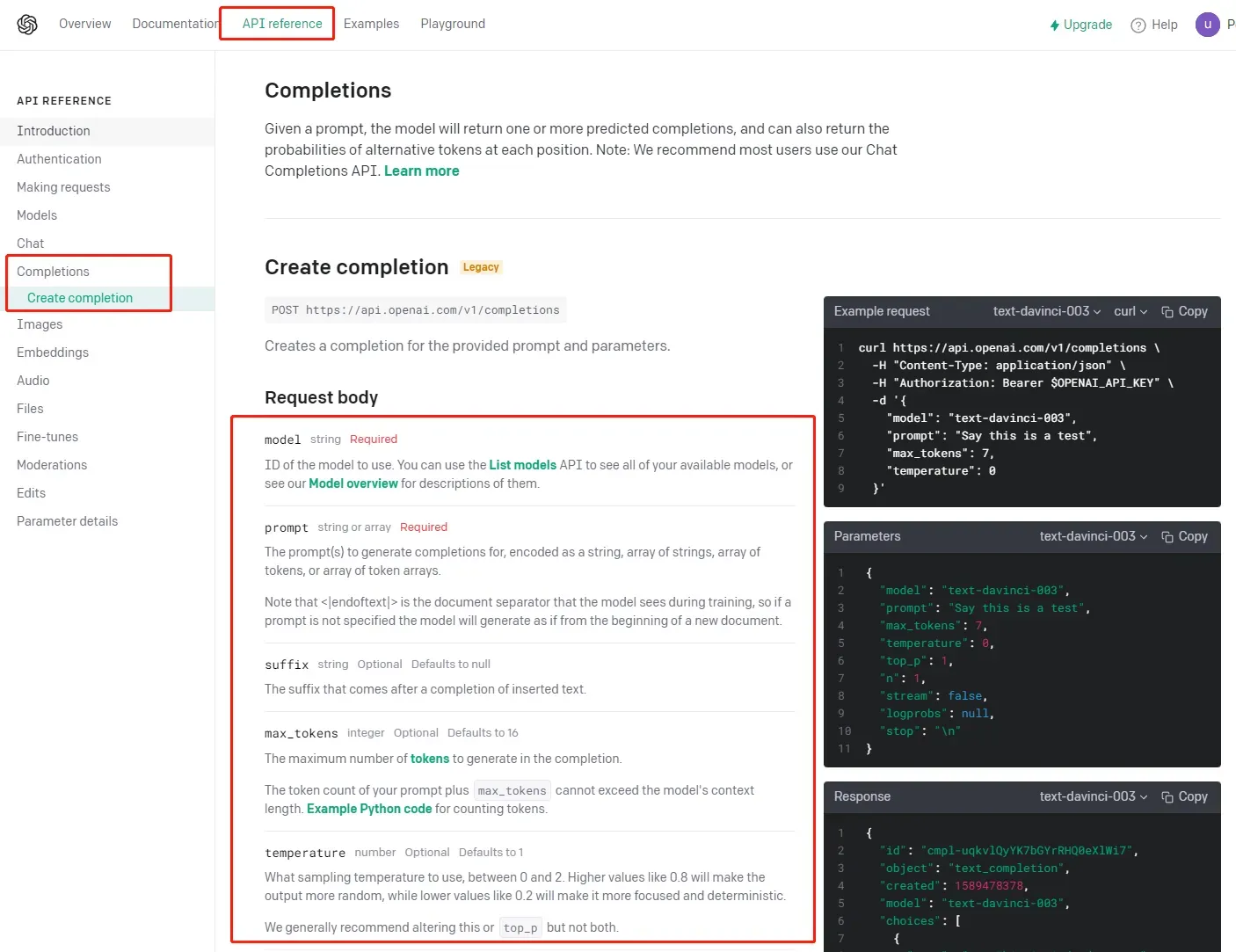
各参数解释如下:

3.2 调用测试
- Step 1:引入依赖包和加载OPENAI_API_KEY
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
- Step 2:调用测试
所有的Completions模型都需要通过Completion.create()函数进行调用,在实际调用的过程中通过超参数设置对应的调用模型及模型相关参数,测试代码如下:
response = openai.Completion.create(
model="text-davinci-003",
prompt="This is a test message"
)
输出结果如下:

如果程序不报错,基本就证明了已经正常调用了,返回结果response包含了text_completion id(completion任务编码)、模型回复结果及本轮调用的资源使用情况,从模型的回复上来看,Completions作为补全模型,会根据输入继续生成后面的内容,也就是从This is a test message – > This is a test message to test how emails work. Depending on the
最简单的调用是仅设置model和prompt参数,也就只有这两个参数是必填的,其中model表示调用的模型,而prompt则表示提示词。
- Step 3:数据操作
当得到回复后,就可以使用Python做一些基础的操作,首先response是一个OpenAIObject类型对象

- 提取response中具体返回的文本

- 提取text对象

需要强调的是:生成式大模型的输出结果往往是不确定且难以复现的。虽然理论上,当temperature设为0时,模型会在每个步骤中始终选择概率最高的下一个token,使得输出变得更加确定和一致。但实际上,由于模型内部计算的精度限制、舍入误差等因素,仍然不能保证输出结果的完全一致性。
除了temperature外,目前OpenAI并没有提供任何额外的可以用于控制结果随机性的参数。top_p尽管可以影响输出结果,但并不能完全控制模型随机性。此外,目前OpenAI的在线大模型也并没有类似机器学习领域的随机数种子的参数设置。因此,就目前的情况而言,控制大语言输出结果使其能够复现,几乎是不可能做到的。
3.3 调参实践
大语言模型是非常复杂的黑箱模型,导致很多时候参数设置导致的结果并不能完全按照理论情况来进行推演,因此需要通过大量的实践,来积累不同参数的使用经验,即掌握不同参数在实际Completion过程中对输出结果的影响。
先来试一下 尝试调整Completion.create的核心参数来观察模型输出结果变化情况
3.3.1 参数n
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3
)
- 参数n:表示一个提示返回几个Completion
当输入n=3时,就有3个completion返回,如下:

可以这样查看单独的某一个:
response["choices"][0]["text"].strip('?\n\n')
输出如下:

当n不等于1的时候,取结果就采用索引的方式,当输入n=3的时候,response[“choices”][0]就是取第一个Completion的内容,response[“choices”][1]就是取第二个Completion的内容…
将上述过程封装成一个函数,代码如下:
import openai
import json
def get_completion_response(model, prompt, n=1):
"""
使用OpenAI的API查询并获取响应。
参数:
- model (str): 要查询的模型名称,例如 "text-davinci-003"。
- prompt (str): 用于查询的提示或问题。
- n (int): 返回响应的数量,默认为1。
返回:
- str: 一个包含所有响应的JSON字符串。
示例:
result = get_completion_response("text-davinci-003", "请问什么是机器学习", 3)
print(result)
"""
# 使用OpenAI的API获得响应
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
n=n
)
# 存储处理后的响应文本
response_texts = []
# 根据n的大小,依次处理每一个响应的内容
for i in range(n):
text = response["choices"][i]["text"].strip('?\n\n')
print(f"Response {i + 1}: {text}") # 打印内容
response_texts.append(text)
# 把返回内容封装在一个Json中
response_json = json.dumps({"responses": response_texts}, ensure_ascii=False)
return response_json
测试一下函数:
# 调用函数示例
model = "text-davinci-003"
prompt = "请问什么是机器学习"
n = 3
# result = get_completion_response(model=model, prompt=prompt, n=n)
# print(result)
get_completion_response(model=model, prompt=prompt, n=n)
看下输出结果:

3.3.2 参数temperature
- temperature是非常核心且重要的参数,它用于控制模型输出结果随机性的参数。其取值范围在0-2之间,默认值为1,数值越大模型随机性越大。
先尝试设置temperature=1.5,调用代码如下:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
temperature=1.5
)
看下模型的返回结果:

其实能明显的这个 回答已经很随机了,甚至都不能连成正常的一句话。
再尝试设置一个更小的temperature取值,并观察输出结果:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
temperature=0.8
)
看下结果:

从结果上就能看出,当temperature参数数值下降时,回复会更加严谨。这很能说明temperature对文本输出结果的随机性影响非常大,所以这个参数是一定要重视的。
两条temperature参数的设置技巧可供参考,但具体如何设置,还需要根据实际情况来判断
- temperature的数值对模型结果影响极大,往往小幅的数值调整就会导致非常大的影响,因此建议的调整范围在**[0.8,1.2]**之间;
- 伴随着temperature取值逐渐增加,返回的文本也将从严谨表述逐渐变为“胡言乱语”,但temperature在某些取值时,返回的结果会呈现出具备一定“启发性”的特性,所以有时候让模型回复更发散的内容,能给我们一定的启发。
当添加上temperature参数时,函数更新如下:
import openai
import json
def get_completion_response(model, prompt, n=1, temperature=0.8):
"""
使用OpenAI的API查询并获取响应。
参数:
- model (str): 要查询的模型名称,例如 "text-davinci-003"。
- prompt (str): 用于查询的提示或问题。
- n (int): 返回响应的数量,默认为1。
- temperature (float): 用于控制输出随机性的参数,值范围为[0, 1]。较低的值会使输出更确定,而较高的值会使其更随机。
返回:
- str: 一个包含所有响应的JSON字符串。
示例:
result = get_completion_response("text-davinci-003", "请问什么是机器学习", 3, 0.8)
print(result)
"""
# 使用OpenAI的API获得响应
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
n=n,
temperature=temperature
)
# 存储处理后的响应文本
response_texts = []
# 根据n的大小,依次处理每一个响应的内容
for i in range(n):
text = response["choices"][i]["text"].strip('?\n\n')
print(f"Response {i+1}: {text}") # 打印内容
response_texts.append(text)
# 把返回内容封装在一个Json中
response_json = json.dumps({"responses": response_texts}, ensure_ascii=False)
return response_json
测试一下:
# 调用函数示例
model = "text-davinci-003"
prompt = "请问什么是机器学习"
n = 3
temperature = 0.8
# result = get_completion_response(model=model, prompt=prompt, n=n)
# print(result)
get_completion_response(model=model, prompt=prompt, n=n, temperature=temperature)
看下模型输出:

3.3.3 参数presence_penalty
- 参数presence_penalty制返回语句的精炼程度
简单点理解:temperature越大,就越胡说八道,presence_penalty越小,就越啰嗦,presence_penalty参数在[-2,2]中取值,数值越大,返回结果越精炼,数值越小,返回结果越啰嗦。
仍然还是以“请问什么是机器学习”作为提示,观察presence_penalty取值不同时的输出结果,当取较大的值的时候,
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
presence_penalty=2
)
看下模型的返回结果:

此时的输出结果是非常精炼的。而如果设置presence_penalty为-2:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
presence_penalty=-2
)
看下模型的返回结果:

确实是磨叽了一下,文本较短还看的不是那么明显,当输出长了以后,是非常直观的。
经长期测试及看了其他开发者的经验后,我个人建议在实际调用大模型进行Completion时,presence_penalty参数和temperature参数搭配进行使用,往往能达到非常好的效果。一般来说,如果希望模型更加具有创造力,则会增加temperature取值,并且适当降低presence_penalty取值,比如可以这样做:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
presence_penalty=-0.8,
temperature=1.2
)
结果如下:

反之,如果希望结果更加精准,尝试适当降低temperature,同时增加presence_penalty取值:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
n=3,
presence_penalty=2,
temperature=0.8
)
结果如下:

**这也就是经常会看到一些大语言模型具备三种不同的模式,分别为精确模式、平衡模式和创造力模式,其功能的实现都是通过大模型的参数调整来完成的,而支持这些不同模式功能实现的最基础的两个参数就是presence_penalty参数和temperature参数。**所以你现在知道,New bing的三种模式是怎么来的了吗?
再更新一下函数,加入presence_penalty参数,代码如下:
import openai
import json
def get_completion_response(model, prompt, n=1, temperature=0.8, presence_penalty=2.0):
"""
使用OpenAI的API查询并获取响应。
参数:
- model (str): 要查询的模型名称,例如 "text-davinci-003"。
- prompt (str): 用于查询的提示或问题。
- n (int): 返回响应的数量,默认为1。
- temperature (float): 用于控制输出随机性的参数,值范围为[0, 1]。较低的值会使输出更确定,而较高的值会使其更随机。
- presence_penalty (float): 用于增加或减少新内容出现在输出中的惩罚。
返回:
- str: 一个包含所有响应的JSON字符串。
示例:
result = get_completion_response("text-davinci-003", "请问什么是机器学习", 3, 0.8, 2)
print(result)
"""
# 使用OpenAI的API获得响应
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
n=n,
temperature=temperature,
presence_penalty=presence_penalty
)
# 存储处理后的响应文本
response_texts = []
# 根据n的大小,依次处理每一个响应的内容
for i in range(n):
text = response["choices"][i]["text"].strip('?\n\n')
print(f"Response {i+1}: {text}") # 打印内容
response_texts.append(text)
# 把返回内容封装在一个Json中
response_json = json.dumps({"responses": response_texts}, ensure_ascii=False)
return response_json
测试一下函数功能:
# 调用函数示例
model = "text-davinci-003"
prompt = "请问什么是机器学习"
n = 3
temperature = 0.8
presence_penalty = 2.0
# result = get_completion_response(model=model, prompt=prompt, n=n)
# print(result)
get_completion_response(model=model, prompt=prompt, n=n, temperature=temperature, presence_penalty=presence_penalty)
看下模型输出:

3.3 4 参数best_of
- 参数best_of:让模型预测多组结果,并择优进行输出。
比如:如果设置best_of=5,则代表总共创建5个备选文本,再从中选取概率最大(得分最高)的一组进行输出:
response = openai.Completion.create(
model="text-davinci-003",
prompt="请问什么是机器学习",
max_tokens=1000,
presence_penalty=-1,
temperature=1.2,
best_of=5
)
模型的输出结果如下:

这个参数显而易见的效果是随着best_of值增加,最终的输出结果质量也会随之提升,毕竟是多个答案选择最优的嘛,但是同时会消耗大量Token配额以及每分钟调用次数配额,看情况用吧。
有一个参数搭配是:同时使用best_of和n,如best_of=2、n=2时,就会发出四次请求,最终返回两个结果。
best_of是自动筛选最优结果,参数n可以支持手动筛选最佳结果
所以进一步更新封装的函数:
import openai
import json
def get_completion_response(model, prompt, n=1, temperature=0.8, presence_penalty=2.0, best_of=1):
"""
使用OpenAI的API查询并获取响应。
参数:
- model (str): 要查询的模型名称,例如 "text-davinci-003"。
- prompt (str): 用于查询的提示或问题。
- n (int): 返回响应的数量,默认为1。
- temperature (float): 用于控制输出随机性的参数,值范围为[0, 1]。较低的值会使输出更确定,而较高的值会使其更随机。
- presence_penalty (float): 用于增加或减少新内容出现在输出中的惩罚。
- best_of (int): 用于指定多少次尝试中选择最佳输出。
返回:
- str: 一个包含所有响应的JSON字符串。
示例:
result = get_completion_response("text-davinci-003", "请问什么是机器学习", 3, 0.8, 2, 5)
print(result)
"""
# 使用OpenAI的API获得响应
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
n=n,
temperature=temperature,
presence_penalty=presence_penalty,
best_of=best_of
)
# 存储处理后的响应文本
response_texts = []
# 根据n的大小,依次处理每一个响应的内容
for i in range(n):
text = response["choices"][i]["text"].strip('?\n\n')
print(f"Response {i+1}: {text}") # 打印内容
response_texts.append(text)
# 把返回内容封装在一个Json中
response_json = json.dumps({"responses": response_texts}, ensure_ascii=False)
return response_json
最终测试一下:
# 调用函数示例
model = "text-davinci-003"
prompt = "请问什么是机器学习"
n = 3
temperature = 0.8
presence_penalty = 2.0
best_of = 3
# result = get_completion_response(model=model, prompt=prompt, n=n)
# print(result)
get_completion_response(model=model, prompt=prompt, n=n, temperature=temperature, presence_penalty=presence_penalty, best_of=best_of)
看下模型的输出:

ok,没问题,大家可以自行尝试更多的参数,丰富这个函数,便于以后使用。
四、使用Completion模型实现多轮对话机器人
经过上述内容对Completion模型API的深入了解和掌握,其实已经具备使用Completion.create()函数开发高级应用的能力。本文展示一下如何开发一个多轮对话的聊天机器人示例,并通过调整不同的参数来适应多种使用场景。这仅为一种可能的应用思路,供大家参考和启发。
首先,一个聊天机器人的业务流程应该是这样的:
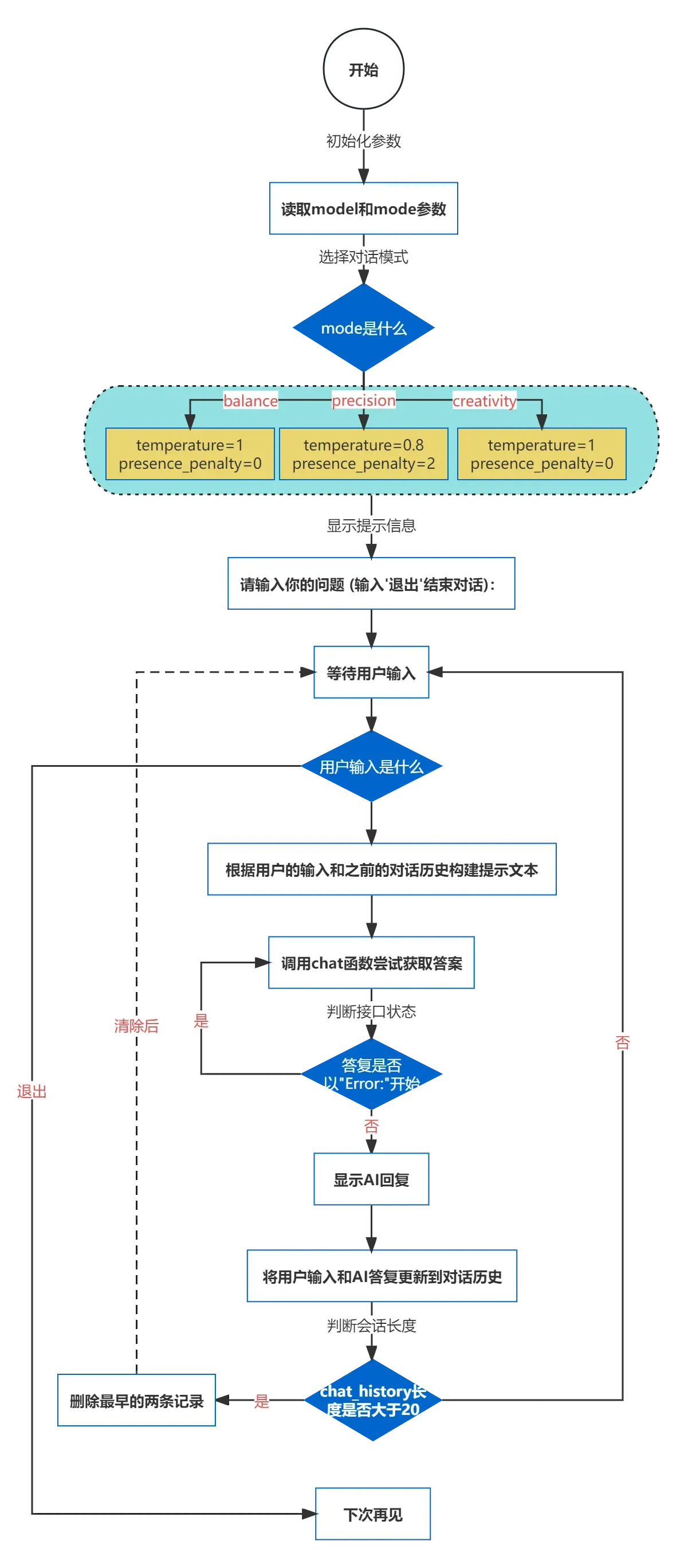
为实现这个流程,可以一步一步的来进行项目拆解。
- Step 1:构建聊天功能函数
要构建聊天机器人,核心是要具备向openai.Completion.create()发送请求并获取答案的基本功能。在实现核心功能后,加入了一些优化,如下
- 参数化:
当前,model, temperature, 和 presence_penalty是外部变量。为了使函数更具有通用性和自足性,建议将它们设置为函数的参数。
- 错误处理:
为了更好地了解发生了什么错误,可以考虑返回更具体的错误信息。例如:return f"Error: {str(exc)}"。
- 结果处理:
直接返回answer可能包含了额外的空格、换行符等。要根据情况确保返回的文本格式整洁。
- 添加日志:
在函数内部,添加一些日志来记录关键步骤或捕获的错误,这样在开发和调试过程中会更方便。所以最终的对话函数如下:
def chat(prompt, model="text-davinci-003", temperature=1.0, presence_penalty=0.0):
"""
Send a chat prompt to the OpenAI API and get the answer.
:param prompt: The chat prompt.
:param model: The model to be used.
:param temperature: Sampling temperature.
:param presence_penalty: Presence penalty value.
:return: The AI's response or error message.
"""
try:
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
temperature=temperature,
presence_penalty=presence_penalty,
stop=[" Human:", " AI:"]
)
answer = response["choices"][0]["text"].strip()
return answer
except Exception as exc:
error_message = f"Error: {str(exc)}"
print(error_message) # This is a simple logging, consider using a logging library in real applications.
return error_message
- Step 2:设置三种对话模式
上面文章也提到过,类似于New bing的对话模型其原理就是通过预设不同的temperature参数和presence_penalty参数组合来实现的,可以这样来实现:
# 三种模式对应的参数,依次为平衡模式、精确模式、创造力模式
if mode == 'balance':
temperature = 1
presence_penalty = 0
elif mode == 'precision':
temperature = 0.8
presence_penalty = 2
elif mode == 'creativity':
temperature = 1.2
presence_penalty = -1
else:
raise ValueError("Invalid mode. Choose from 'balance', 'precision', or 'creativity'.")
简单理解:temperature越大,就越胡说八道,presence_penalty越小,就越啰嗦
- Step 3:构建多轮对话逻辑
要实现多轮对话,其核心就是要让本轮对话的大模型具备上下文记忆能力,思路就是将本轮human提出的question和前几轮human提出的question+对应的AI question拼接到一起,共同输入到大模型中,代码实现的过程如下:
# 存储对话记录
chat_history = []
# 执行多轮对话
while True:
# 启动对话框
user_input = input("Human: ")
# 输入"退出"结束对话
if user_input == "退出":
break
# 将之前的对话和当前的用户输入组合为新的提示
chat_prompt = "\n".join(chat_history + ["Human: " + user_input])
# 使用chat函数获取回答
ai_response = chat(chat_prompt, temperature, presence_penalty)
# 如果回答是错误消息,则尝试再次调用chat函数
while ai_response.startswith("Error:"):
print("请求失败,正在重试...")
ai_response = chat(chat_prompt, temperature, presence_penalty)
# 输出机器人的回答
print(f"AI: {ai_response}")
# 更新聊天记录
chat_history.extend(["Human: " + user_input, "AI: " + ai_response])
# 保留最多10轮对话
if len(chat_history) > 20: # 因为每轮对话有2条记录:一条Human,一条AI
chat_history = chat_history[2:]
可以在指定位置添加打印语句来查看每一轮的Prompt输出情况,如下:
# ... [前面的代码不变]
# 将之前的对话和当前的用户输入组合为新的提示
chat_prompt = "\n".join(chat_history + ["Human: " + user_input])
# 打印chat_prompt以查看每轮的模型输入
print("\n当前的chat_prompt:\n", chat_prompt, "\n")
# ... [前面的代码不变]
# 更新聊天记录
chat_history.extend(["Human: " + user_input, "AI: " + ai_response])
# 打印chat_history以查看当前的对话历史
print("\n当前的chat_history:\n", chat_history, "\n")
测试一下:
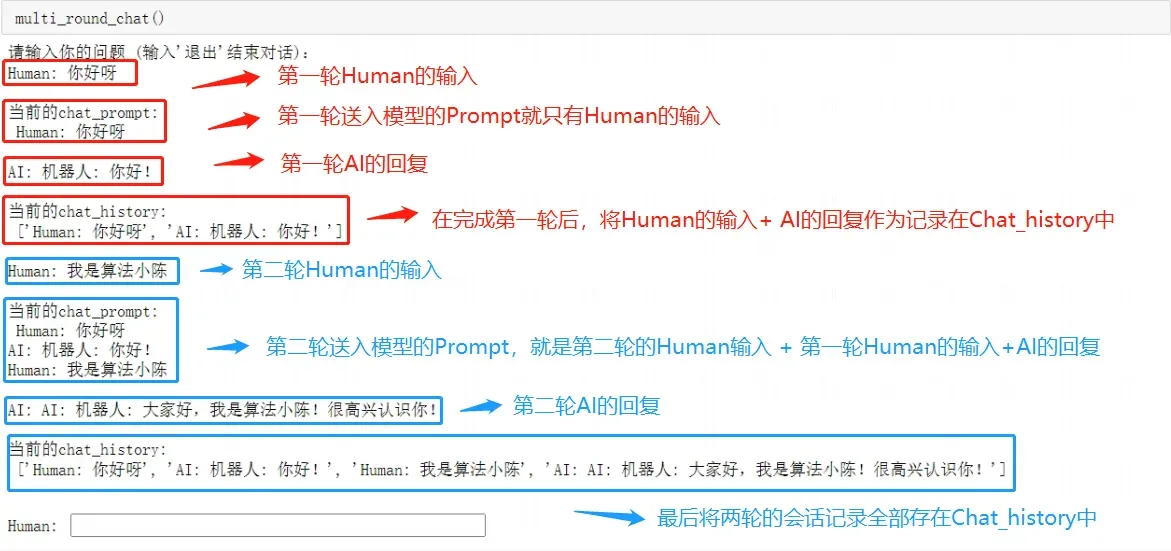
通过这种方式,使得模型存在上下文记忆能力,但需要注意的是:每轮对话有2条记录:一条Human,一条AI,所以当你想保留10条最近的会话信息的话,chat_history的长度限制要写成 >20.
- Step 4:完整函数
def multi_round_chat(model='text-davinci-003', mode='balance'):
"""
基于Completion.create函数的多轮对话机器人
:param model: The model to be used.
:param mode: The chat mode, which can be 'balance', 'precision', or 'creativity'.
"""
def chat(prompt, temperature=1.0, presence_penalty=0.0):
"""
对话函数
Send a chat prompt to the OpenAI API and get the answer.
:param prompt: The chat prompt.
:param temperature: Sampling temperature.
:param presence_penalty: Presence penalty value.
:return: The AI's response or error message.
"""
try:
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=1000,
temperature=temperature,
presence_penalty=presence_penalty,
stop=[" Human:", " AI:"]
)
answer = response["choices"][0]["text"].strip()
return answer
except Exception as exc:
error_message = f"Error: {str(exc)}"
print(error_message) # This is simple logging. In real applications, consider using a logging library.
return error_message
# 设置三种对话模式的参数
if mode == 'balance':
temperature = 1
presence_penalty = 0
elif mode == 'precision':
temperature = 0.8
presence_penalty = 2
elif mode == 'creativity':
temperature = 1.2
presence_penalty = -1
else:
raise ValueError("Invalid mode. Choose from 'balance', 'precision', or 'creativity'.")
# 启动对话框
print("请输入你的问题 (输入'退出'结束对话):")
# 存储对话记录
chat_history = []
# 执行多轮对话
while True:
# 启动对话框
user_input = input("Human: ")
# 输入"退出"结束对话
if user_input == "退出":
break
# 将之前的对话和当前的用户输入组合为新的提示
chat_prompt = "\n".join(chat_history + ["Human: " + user_input])
# 打印chat_prompt以查看每轮的模型输入
print("\n当前的chat_prompt:\n", chat_prompt, "\n")
# 使用chat函数获取回答
ai_response = chat(chat_prompt, temperature, presence_penalty)
# 如果回答是错误消息,则尝试再次调用chat函数
while ai_response.startswith("Error:"):
print("请求失败,正在重试...")
ai_response = chat(chat_prompt, temperature, presence_penalty)
# 输出机器人的回答
print(f"AI: {ai_response}")
# 更新聊天记录
chat_history.extend(["Human: " + user_input, "AI: " + ai_response])
# 打印chat_history以查看当前的对话历史
print("\n当前的chat_history:\n", chat_history, "\n")
# 保留最多10轮对话
if len(chat_history) > 20: # 因为每轮对话有2条记录:一条Human,一条AI
chat_history = chat_history[2:]
print("下次再见!")
最后测试一下:

两个细节:
- input 1是:“你好,你知道什么是机器学习吗”,在末尾会出现一个问号(?),这是因为目前使用的是text-davinci-003,它是补全模型啊!
- input 2 直接输入了“具体点应该如何学习呢?”,因为加了问号(?),是一个完整的输入,所以并没有补全,这就验证了细节1中的问题,同时,并没有提到机器学习相关的内容,但是模型的回复是“如何学习机器学习”相关的内容,这也验证了模型具备上下文记忆的能力。
五、总结
本文详细阐述了OpenAI的Completions与Chat Completions模型的基本概念与模型类。接着,对Completion.create API进行了深度解析,包括参数详解、代码测试以及参数调参实践,特别是对n、temperature、presence_penalty、best_of等参数的详细讲解。最后,以Completion.create函数为基础,实现了一个多轮对话机器人,展现了AI对话系统的灵活性。掌握这些知识,对优化AI对话系统具有重要的指导意义。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!
文章出处登录后可见!