😊数据结构与算法——图
- 🚀前言
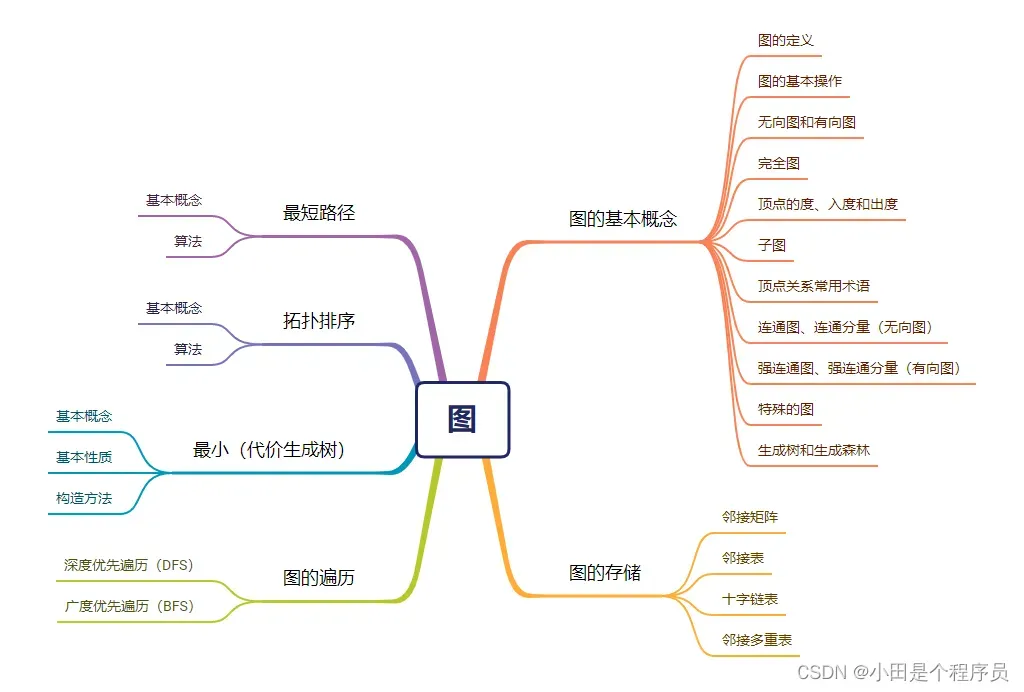
- 🚀图的基本概念
- 🚢图的定义
- 🚢图的基本操作
- 🚢无向图和有向图
- 🚢完全图
- 🚢顶点的度、入度和出度
- 🚢子图
- 🚢顶点关系常用术语
- 🚢边的权、带权图
- 🚢连通图、连通分量(无向图)
- 🚢强连通图、强连通分量(有向图)
- 🚢特殊的图
- 🚢生成树和生成森林
- 🚀图的存储
- 🚢邻接矩阵
- 🚢邻接表
- 🚢十字链表
- 🚢邻接多重表
- 🚀图的遍历
- 🚢深度优先遍历(DFS)
- 🚢广度优先遍历(BFS)
- 🚀最小(代价)生成树
- 🚢基本概念
- 🚢基本性质
- 🚢构造方法
- 🚀拓扑排序
- 🚢基本概念
- 🚢算法示例
- 🚀最短路径
- 🚢基本概念
- 🚢算法
- 💻总结
🚀前言
😊各位小伙伴们,本专栏新文章出炉了!!!
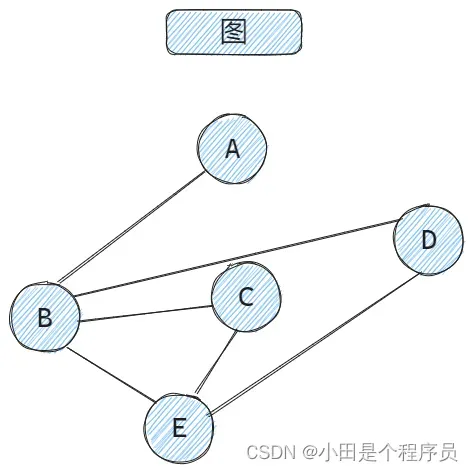
图(Graph) 🎯是一种比线性结构和树型结构更为复杂的数据结构。在线性结构中,元素之间仅有线性关系,每个元素只有一个直接前驱或直接后继;在树型结构中,数据元素之间有着明显的层次关系;而在图型结构中,结点之间的关系可以是任意的,图中任意两个数据元素之间都可能有直接关系或间接关系。
图的应用非常广泛,几乎在每个领域,都随处可见图这种数据关系的存在,例如现在人们使用的微信,微信好友之间便呈现出图的关系;又例如每个人的社交关系网,也是图型结构的体现。本篇文章将围绕图这种数据结构展开总结,归纳图的基本含义和术语,以及图所涉及的基本操作。
🚀图的基本概念
🚢图的定义
图(Graph) 是由一个顶点集和一个弧集
构成的网状数据结构,记作
。在图中,数据元素通常称作顶点(Vertex),
是顶点的有穷非空集合;
是两个顶点之间的关系的集合。
🚩注意:线性表可以为空表,树可以是空树,但图不可以为空,即
一定是非空集。
🚢图的基本操作
📌Adjacent(G,x,y): 判断图是否存在边
📌Neighbors(G,x): 列出图中与结点
邻接的边。
📌InsertVertex(G,x): 在图中插入顶点
。
📌DeleteVertex(G,x): 从图中删除顶点
。
📌AddEdge(G,x,y): 若无向边或有向边
不存在,则向图
中添加该边。
📌RemoveEdge(G,x,y): 若无向边或有向边
存在,则从图
中删除该边。
📌FirstNeighbor(G,x): 求图中顶点
的第一个邻接点,若有则返回顶点号。若
没有邻接点或图中不存在
,则返回
。
📌NextNeighbor(G,x,y): 假设图中顶点
是顶点
的一个邻接点,返回除
之外顶点
的下一个邻接点的顶点号,若
是
的最后一个邻接点,则返回
。
📌Get_edge_value(G,x,y): 获取图中边
或
对应的权值。
📌Set_edge_value(G,x,y,v): 设置图中边
或
对应的权值为
。
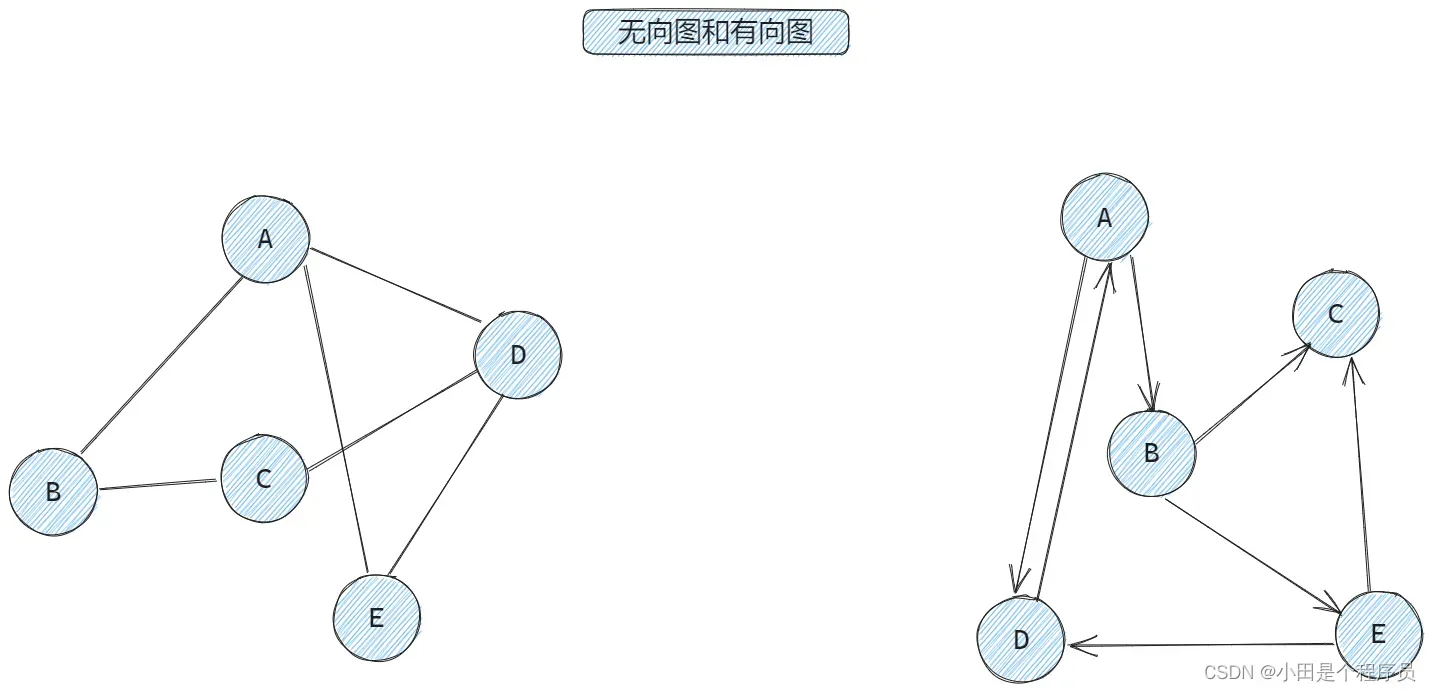
🚢无向图和有向图
在一个图中,如果任意两个顶点构成的偶对属于
是无序的,即顶点之间的连线是没有方向的,则称该图为无向图。在一个图中,如果任意两个顶点构成的偶对
属于
是有序的,即顶点之间的连线是有方向的,则称为有向图。
🚢完全图
在无向完全图中,如果任意两个顶点之间都存在边,则称该图为无向完全图
👻含有个顶点的无向完全图有
条边
🚩无向完全图是所有无向图中边数最多的图
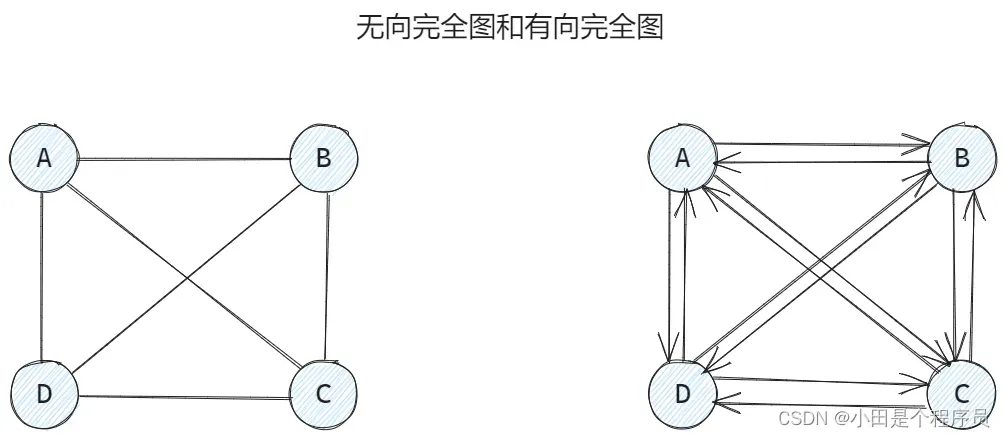
👻含有个顶点的有向完全图有
条有向边
🚩 有向完全图是所有有向图中边数最多的图
🚢顶点的度、入度和出度
在无向图中,顶点的🎯
度是指依附于该顶点的边的条数,记作
👻其中,对于无向图而言:
- 所有顶点的度之和等于边数的两倍
在有向图中,顶点的
🎯入度是指以顶点作为终点的弧的数目,记作,顶点V的🎯
出度是指以顶点为起始点的弧的数目,记作
👻其中,对于有向图而言:
- 顶点的度 = 入度 + 出度
- 所有顶点的入度之和 = 出度之和
🚢子图
对于图,若存在
’是
的子集,
是
的子集,则称图
是
的子图
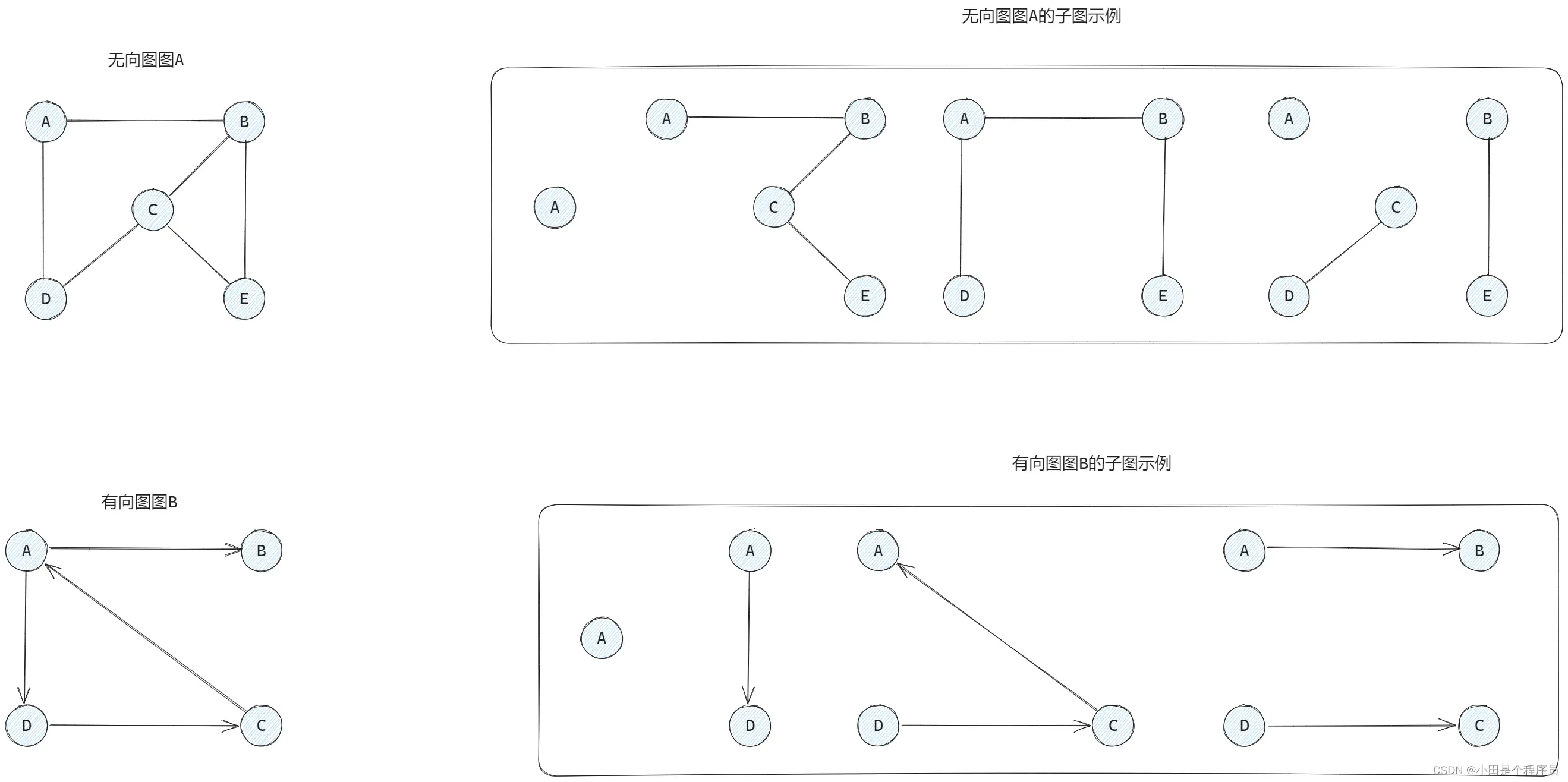
🚩注意:并非任意挑几个点、几条边都能构成子图
🚢顶点关系常用术语
📌路径——顶点到顶点
之间的一条路径为其一个顶点序列,在有向图中,路径是有向的。
📌回路——第一个顶点和最后一个顶点相同的路径称为回路或环🎯(从第一个顶点能回到本身)
📌简单路径——在路径序列中,顶点不重复出现的路径称为简单路径
📌简单回路——除第一个顶点和最后一个顶点外,其余顶点不重复出现的回路简称为简单回路
📌路径长度——路径上边的数目
📌顶点到顶点间的距离——从顶点出发到顶点
的最短路径若存在,则此路径的长度称为从顶点
到顶点
的距离,若从
到
根本不存在路径,则称该距离为无穷
在无向图中,若从顶点到顶点
有路径存在,则称顶点
和顶点
是🎯
连通的
在有向图中,若从顶点到顶点
和从顶点
到顶点
之间都有路径,则称这两个顶点是🎯
强连通的
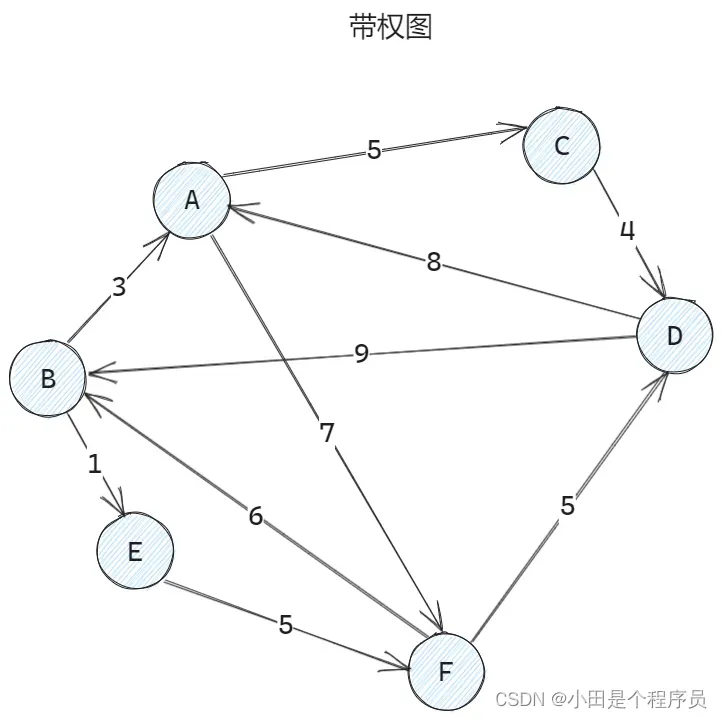
🚢边的权、带权图
📌边的权——在一个图中,每条边都可以标上具有某种含义的数值,该数值称为边的权值
📌带权图——边上带有权值的图称为带权图,也称带权网
📌带权路径长度——在一个带权图中,🎯一条路径上的所有边的权值之和,称为该路径的带权路径长度
🚢连通图、连通分量(无向图)
📌连通图: 无向图中任意两顶点都是连通的,无向图至少需要条边才能连通,至多可以有
条边
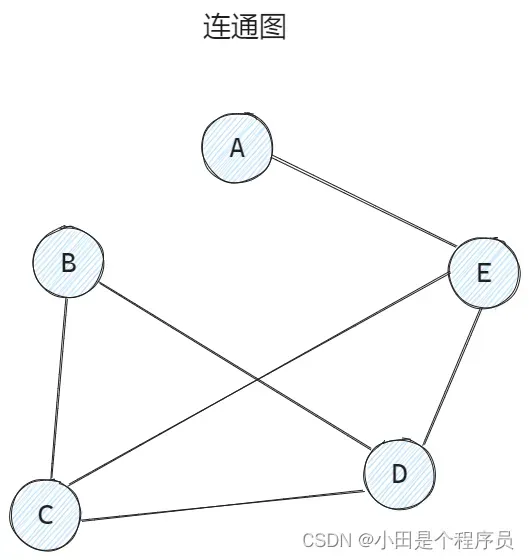
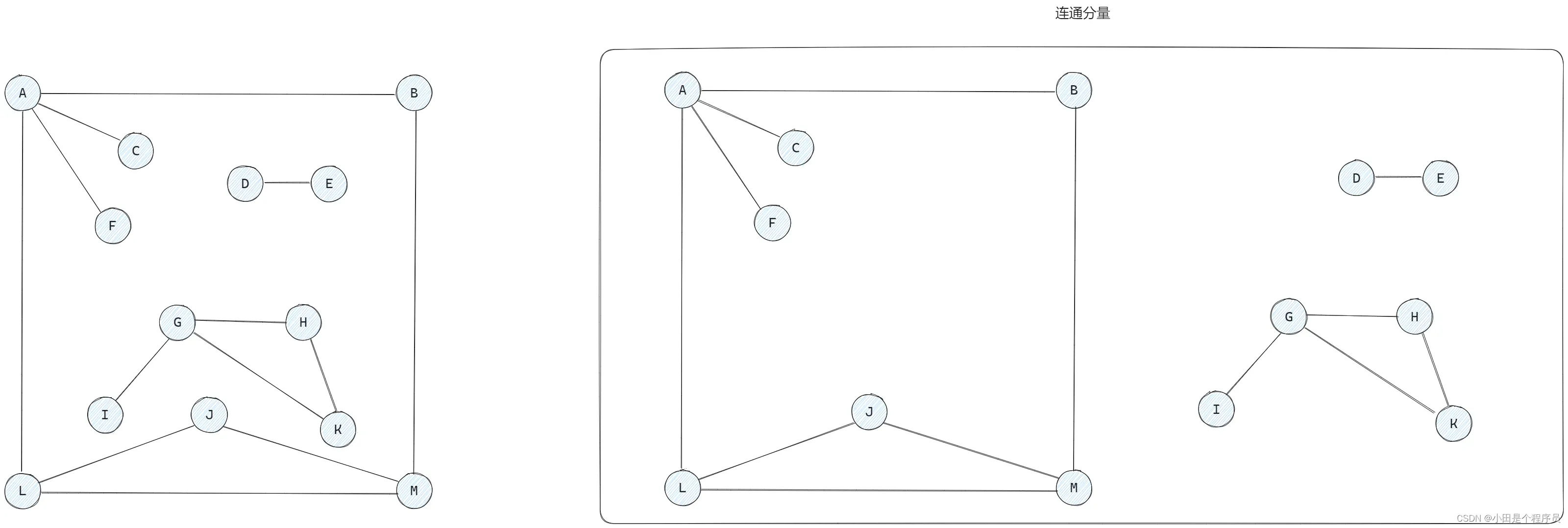
任何连通图的连通分量只有一个,即是其自身🎯(前提必须是一个连通图),非连通图有几个极大连通子图就有几个连通分量
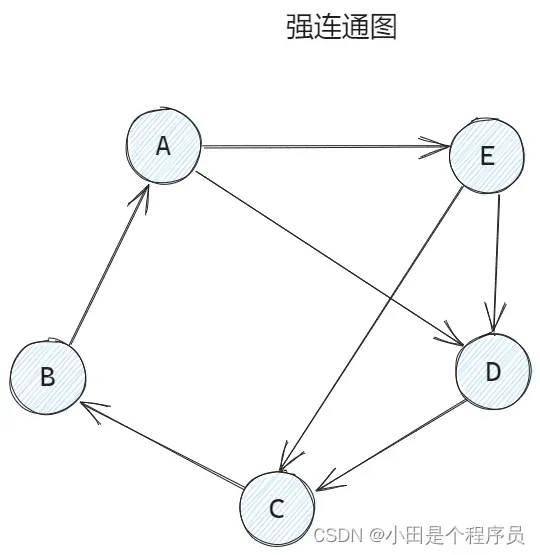
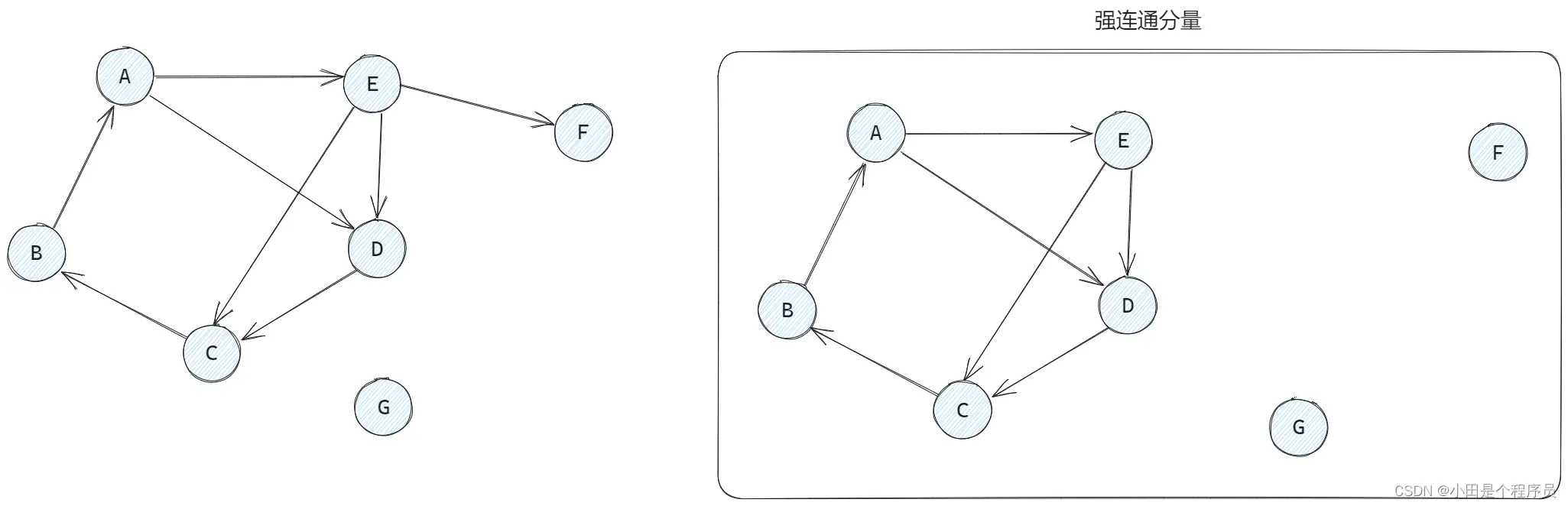
🚢强连通图、强连通分量(有向图)
📌强连通图: 任意一对顶点和
均有路径,也有
到
的路径,有向图至少需要
条边才能强连通🎯
(形成回路),至多条
🚢特殊的图
边数很少的图称之为稀疏图,反之则为稠密图
无向完全图——无向图中任意两个顶点之间都存在边
有向完全图——有向图中任意两个顶点都存在方向相反的两条边
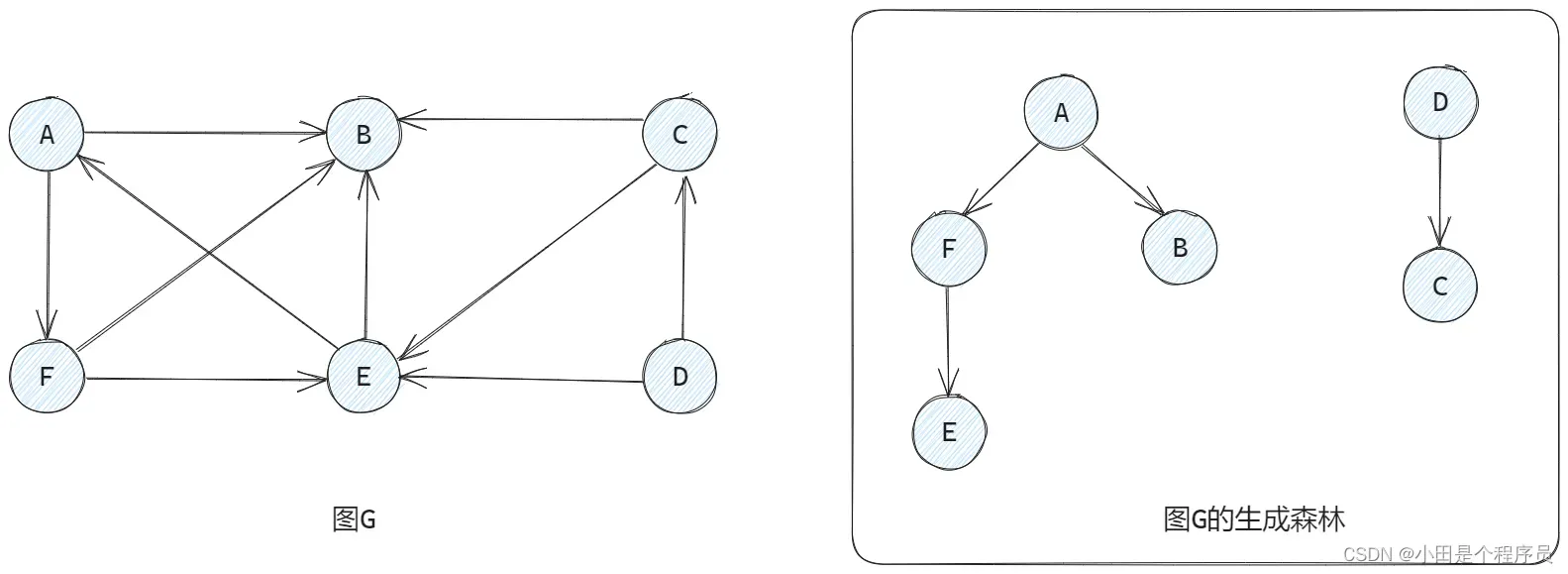
🚢生成树和生成森林
生成树是无向图的一个子图,它包含图中的所有顶点,但是只包含图中的部分边,且这些边构成一棵树。换句话说,🎯生成树用于连接图中的所有顶点,并保持图的连通性,但是没有形成循环。
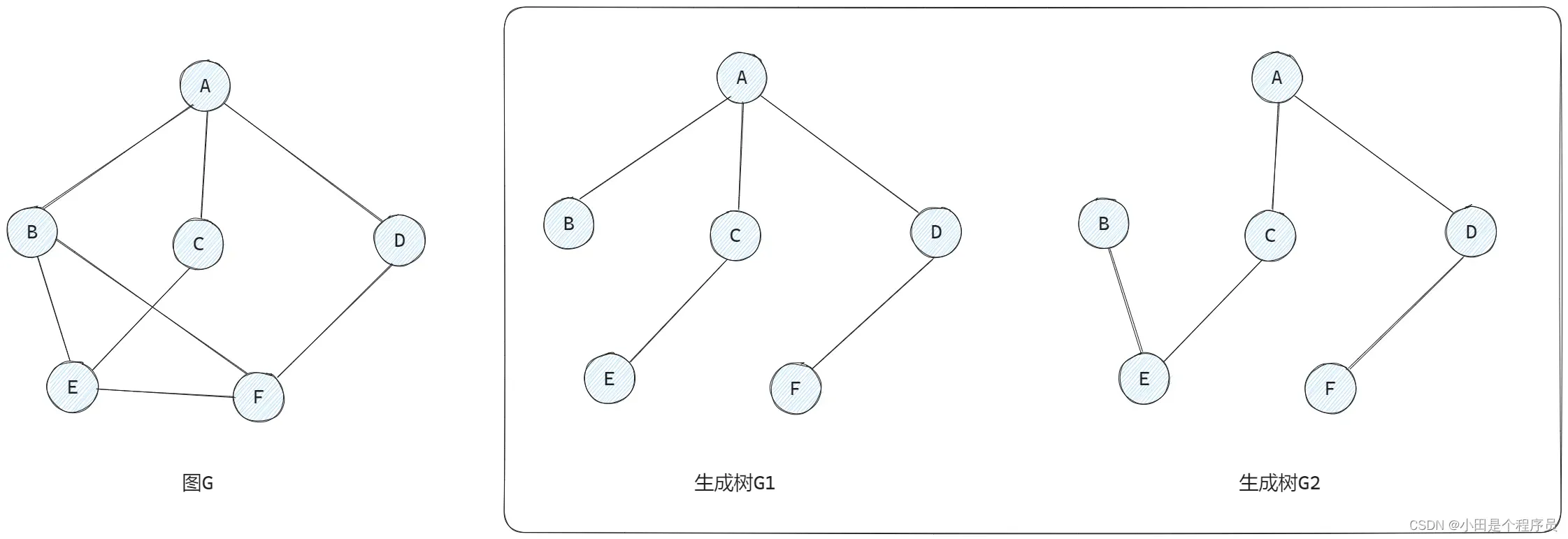
🚩生成树并不唯一
生成森林是指一个图的所有连通分量的生成树的集合。一个连通分量的生成树可以看作是该分量中的部分顶点和部分边构成的一棵树。🎯生成森林由多棵生成树组成,每棵生成树对应一个连通分量。
🚀图的存储
由于图的结构比较复杂,任意两个顶点之间都有可能存在联系,因此无法以数据元素在存储区中的物理位置来表示元素之间的关系,即图没有顺序的存储结构,但可以借助数组的数据类型表示元素之间的关系。
🚢邻接矩阵
使用一个二维数组来表示图的连接关系。 对于个顶点的无向图,使用
的矩阵,如果两个顶点
和
之间存在边,则矩阵中
和
位置的值为1,否则为0。对于有向图,
位置的值表示从顶点
指向顶点
的边。
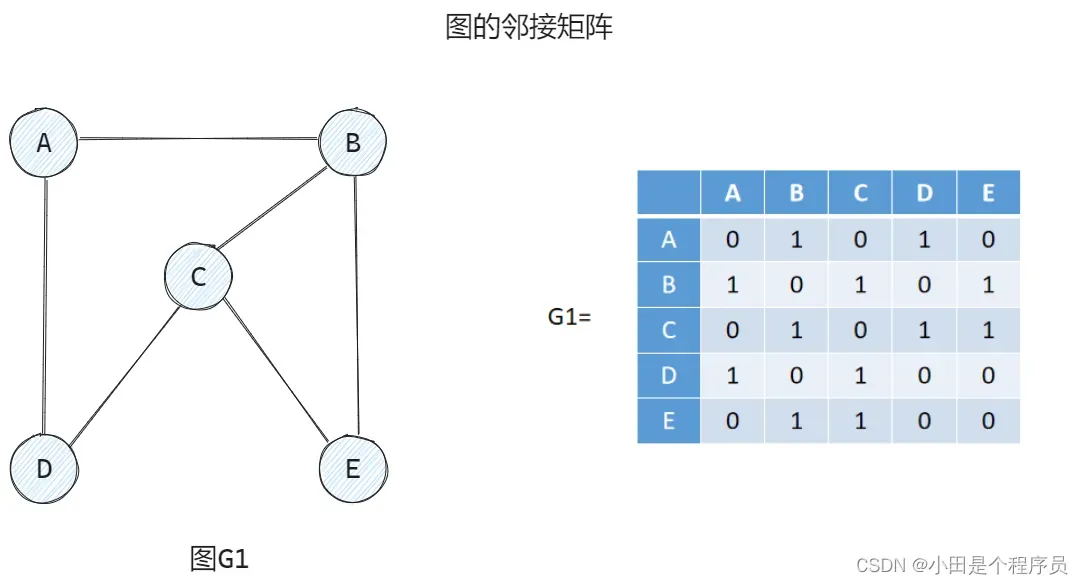
邻接矩阵的优点是查找两个顶点之间是否存在边的时间复杂度是,但对于稀疏图而言,矩阵会浪费大量的空间。
👻存储表示:
#define MAX_SIZE 100
// 邻接矩阵存储表示
typedef struct {
int vertexNum; // 图的顶点数
int edgeNum; // 图的边数
int adjacencyMatrix[MAX_SIZE][MAX_SIZE]; // 邻接矩阵
} Graph;
// 初始化图
void initGraph(Graph* graph, int vertexNum) {
graph->vertexNum = vertexNum;
graph->edgeNum = 0; // 初始时没有边
// 初始化邻接矩阵
for (int i = 0; i < vertexNum; i++) {
for (int j = 0; j < vertexNum; j++) {
graph->adjacencyMatrix[i][j] = 0; // 初始时没有边相连
}
}
}
// 添加边到图中
void addEdge(Graph* graph, int start, int end) {
if (start >= 0 && start < graph->vertexNum && end >= 0 && end < graph->vertexNum) {
graph->adjacencyMatrix[start][end] = 1; // 标记边存在
graph->adjacencyMatrix[end][start] = 1; // 无向图需要反向也标记
graph->edgeNum++; // 边数加1
}
}
// 打印邻接矩阵
void printGraph(Graph* graph) {
printf("邻接矩阵表示的图:\n");
for (int i = 0; i < graph->vertexNum; i++) {
for (int j = 0; j < graph->vertexNum; j++) {
printf("%d ", graph->adjacencyMatrix[i][j]);
}
printf("\n");
}
}
int main() {
Graph graph;
int vertexNum = 5; // 图的顶点数
initGraph(&graph, vertexNum);
// 向图中添加边
addEdge(&graph, 0, 1);
addEdge(&graph, 0, 2);
addEdge(&graph, 1, 3);
addEdge(&graph, 2, 4);
printGraph(&graph);
return 0;
}
🚩特点:
- 无向图的邻接矩阵是对称矩阵,可以压缩存储🎯
(只存储上三角区/下三角区) - 无向图的领接矩阵的第
行🎯
(或第i列)非零元素的个数正好是第 - 出现方向相反的2条弧的有向图的邻接矩阵对称
- 有向图的邻接矩阵的第i行非零元素的个数是第
,第
- 邻接矩阵便于判断两个顶点之间是否有边,不便于增加和删除顶点
- 邻接矩阵的大小只和顶点有关,与边无关
- 无向图的邻接矩阵非零元素的个数是边数的2倍,有向图的邻接矩阵的非零元素个数等于边数
个顶点,
条边的无向图中,邻接表有
个表节点
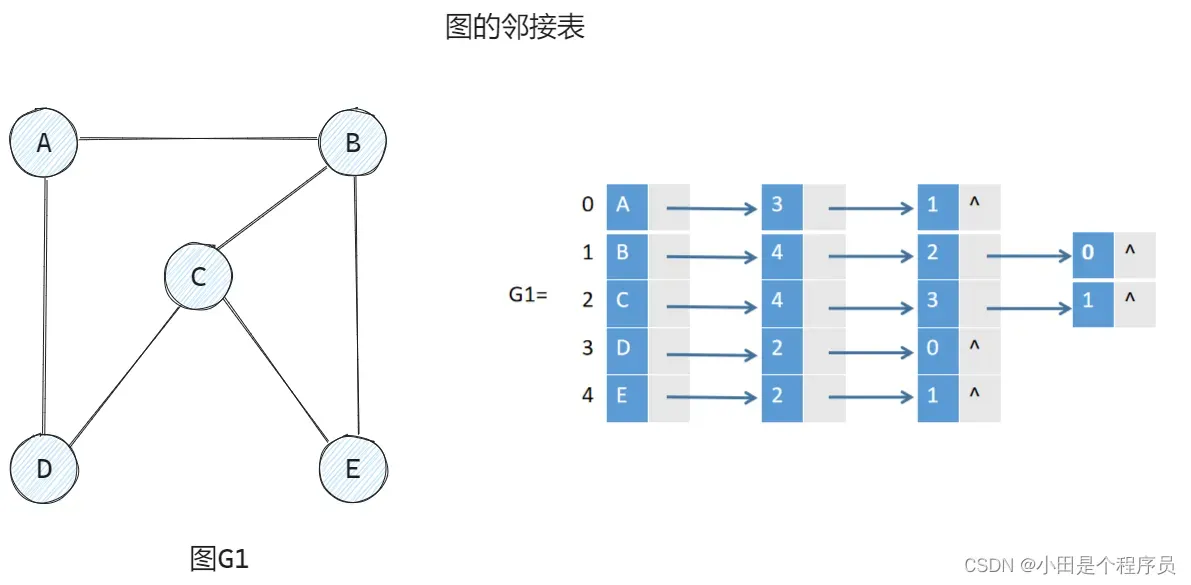
🚢邻接表
使用链表来表示图的连接关系。 对于每个顶点,使用一个链表存储与其相邻的顶点。邻接表的🎯优点是对于稀疏图,存储空间较小;同时,可以快速遍历一个顶点的邻居顶点。但查找两个顶点之间是否存在边的时间复杂度为,其中
是相邻顶点的数量。
// 邻接表中的节点
struct AdjListNode {
int dest;
struct AdjListNode* next;
};
// 邻接表
struct AdjList {
struct AdjListNode* head;
};
// 图结构
struct Graph {
int V; // 顶点数
struct AdjList* array;
};
// 创建邻接表节点
struct AdjListNode* newAdjListNode(int dest) {
struct AdjListNode* newNode = (struct AdjListNode*) malloc(sizeof(struct AdjListNode));
newNode->dest = dest;
newNode->next = NULL;
return newNode;
}
// 创建图
struct Graph* createGraph(int V) {
struct Graph* graph = (struct Graph*) malloc(sizeof(struct Graph));
graph->V = V;
graph->array = (struct AdjList*) malloc(V * sizeof(struct AdjList));
int i;
for (i = 0; i < V; ++i)
graph->array[i].head = NULL;
return graph;
}
// 添加边
void addEdge(struct Graph* graph, int src, int dest) {
struct AdjListNode* newNode = newAdjListNode(dest);
newNode->next = graph->array[src].head;
graph->array[src].head = newNode;
// 无向图的话,还需添加反向边
newNode = newAdjListNode(src);
newNode->next = graph->array[dest].head;
graph->array[dest].head = newNode;
}
// 打印图
void printGraph(struct Graph* graph) {
int v;
for (v = 0; v < graph->V; ++v) {
struct AdjListNode* pCrawl = graph->array[v].head;
printf("\n 邻接表顶点 %d\n 头 ", v);
while (pCrawl) {
printf("-> %d", pCrawl->dest);
pCrawl = pCrawl->next;
}
printf("\n");
}
}
int main() {
int V = 5;
struct Graph* graph = createGraph(V);
addEdge(graph, 0, 1);
addEdge(graph, 0, 4);
addEdge(graph, 1, 2);
addEdge(graph, 1, 3);
addEdge(graph, 1, 4);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
printGraph(graph);
return 0;
}
🚩特点:
- 在邻接表中,给定一顶点就很容易地找到它所有邻边
- 在有向图的邻接表中,求一个给定顶点的出度只需计算其邻接表中的结点个数即可,但求某顶点的入度,则需要遍历全部的邻接表🎯
(某顶点入度=该顶点在表结点出现的次数) - 图的邻接表表示并不唯一,因为各边表结点的顺序是任意的
- 邻接表便于增加和删除节点,便于统计边数
🚩注意:邻接表属于链式存储,但邻接表的表头属于顺序存储结构
🚢十字链表
用于表示有向图的存储结构。对于个顶点和
条有向边的图,使用两个链表,分别表示顶点和边。顶点链表中每个结点存储顶点的信息以及指向第一条边的指针,边链表中每个结点存储边的信息以及指向边的起点和终点的指针。
👻存储表示:
// 定义图的顶点结构
typedef struct Vertex {
int data;
struct ArcNode *firstIn; // 入边表的头指针
struct ArcNode *firstOut; // 出边表的头指针
} Vertex;
// 定义边表结点
typedef struct ArcNode {
int tail; // 弧尾
int head; // 弧头
struct ArcNode *hlink; // 指向下一个有相同头结点的边表结点
struct ArcNode *tlink; // 指向下一个有相同尾结点的边表结点
} ArcNode;
// 创建有向图的十字链表
void CreateGraph(Vertex **graph, int n, int m, int *edges) {
int i, tail, head;
ArcNode *arcNode;
// 初始化顶点数组
*graph = (Vertex*) malloc(n*sizeof(Vertex));
// 初始化顶点的入边表和出边表
for (i = 0; i < n; ++i) {
(*graph)[i].data = i;
(*graph)[i].firstIn = NULL;
(*graph)[i].firstOut = NULL;
}
// 构建边表
for (i = 0; i < m; ++i) {
tail = edges[2*i];
head = edges[2*i+1];
// 创建边表结点
arcNode = (ArcNode*) malloc(sizeof(ArcNode));
arcNode->tail = tail;
arcNode->head = head;
// 将边表结点插入到顶点的出边表中
arcNode->hlink = (*graph)[tail].firstOut;
(*graph)[tail].firstOut = arcNode;
// 将边表结点插入到顶点的入边表中
arcNode->tlink = (*graph)[head].firstIn;
(*graph)[head].firstIn = arcNode;
}
}
int main() {
int n = 4; // 顶点数
int m = 6; // 边数
int edges[12] = {0, 1, 0, 2, 1, 2, 1, 3, 2, 3, 3, 0}; // 边的起点和终点
Vertex *graph;
CreateGraph(&graph, n, m, edges);
// 输出顶点的出边表
printf("顶点的出边表:\n");
for (int i = 0; i < n; ++i) {
ArcNode *arcNode = graph[i].firstOut;
printf("%d: ", i);
while (arcNode != NULL) {
printf("%d ", arcNode->head);
arcNode = arcNode->hlink;
}
printf("\n");
}
// 输出顶点的入边表
printf("顶点的入边表:\n");
for (int i = 0; i < n; ++i) {
ArcNode *arcNode = graph[i].firstIn;
printf("%d: ", i);
while (arcNode != NULL) {
printf("%d ", arcNode->tail);
arcNode = arcNode->tlink;
}
printf("\n");
}
return 0;
}
CreateGraph 函数用于创建有向图的十字链表。首先根据顶点数量 动态分配顶点数组的内存,并初始化顶点的入边表和出边表为空。然后根据边的起点和终点数组
edges 构建边表,将边表结点插入到对应的顶点的出边表和入边表中。
🚢邻接多重表
用于表示无向图的存储结构。 与十字链表类似,使用两个链表,分别表示顶点和边。顶点链表中每个结点存储顶点的信息以及两个指针,一个指向第一个关联的边结点,另一个指向下一个顶点结点。边链表中每个结点存储边的信息,以及两个指针,一个指向边的起点顶点结点,另一个指向边的终点顶点结点。
👻存储表示:
// 边表结构体
typedef struct edgeNode {
int mark; // 边的标记
int vertex1, vertex2; // 两个顶点
struct edgeNode* next; // 指向下一条边的指针
} EdgeNode;
// 顶点表结构体
typedef struct vertexNode {
int vertex; // 顶点标号
EdgeNode* firstEdge; // 指向第一条边的指针
} VertexNode;
// 图结构体
typedef struct {
VertexNode* vertexList; // 顶点表
int vertexNum; // 顶点数
int edgeNum; // 边数
} Graph;
// 创建图
void createGraph(Graph* graph, int vertexNum) {
graph->vertexNum = vertexNum;
graph->edgeNum = 0;
graph->vertexList = (VertexNode*)malloc(vertexNum * sizeof(VertexNode));
for (int i = 0; i < vertexNum; i++) {
graph->vertexList[i].vertex = i;
graph->vertexList[i].firstEdge = NULL;
}
}
// 添加边
void addEdge(Graph* graph, int vertex1, int vertex2, int mark) {
EdgeNode* edge = (EdgeNode*)malloc(sizeof(EdgeNode));
edge->mark = mark;
edge->vertex1 = vertex1;
edge->vertex2 = vertex2;
edge->next = NULL;
// 添加到顶点1的边表
if (graph->vertexList[vertex1].firstEdge == NULL) {
graph->vertexList[vertex1].firstEdge = edge;
} else {
EdgeNode* temp = graph->vertexList[vertex1].firstEdge;
while (temp->next != NULL) {
temp = temp->next;
}
temp->next = edge;
}
// 添加到顶点2的边表
if (graph->vertexList[vertex2].firstEdge == NULL) {
graph->vertexList[vertex2].firstEdge = edge;
} else {
EdgeNode* temp = graph->vertexList[vertex2].firstEdge;
while (temp->next != NULL) {
temp = temp->next;
}
temp->next = edge;
}
graph->edgeNum++;
}
// 打印邻接多重表
void printGraph(Graph* graph) {
for (int i = 0; i < graph->vertexNum; i++) {
printf("顶点 %d:", graph->vertexList[i].vertex);
EdgeNode* temp = graph->vertexList[i].firstEdge;
while (temp != NULL) {
printf("(%d, %d) ", temp->vertex1, temp->vertex2);
temp = temp->next;
}
printf("\n");
}
}
// 主函数
int main() {
Graph graph;
int vertexNum, edgeNum;
int vertex1, vertex2, mark;
printf("输入顶点数和边数:");
scanf("%d %d", &vertexNum, &edgeNum);
createGraph(&graph, vertexNum);
printf("输入每条边的顶点和标记:\n");
for (int i = 0; i < edgeNum; i++) {
scanf("%d %d %d", &vertex1, &vertex2, &mark);
addEdge(&graph, vertex1, vertex2, mark);
}
printf("\n邻接多重表:\n");
printGraph(&graph);
return 0;
}
除了以上几种基本的存储结构,还有一些其他的变种存储结构,如压缩邻接矩阵、邻接多重矩阵等,具体选择合适的存储结构取决于图的特点和应用场景。
🚀图的遍历
在图中,从某一顶点出发访问图中其余顶点,🎯且使得每一个顶点仅被访问一次,这个过程就叫图的遍历(Traversing Graph),图的遍历算法是求解图的连通性问题、拓扑排序和求解关键路径等算法的基础。
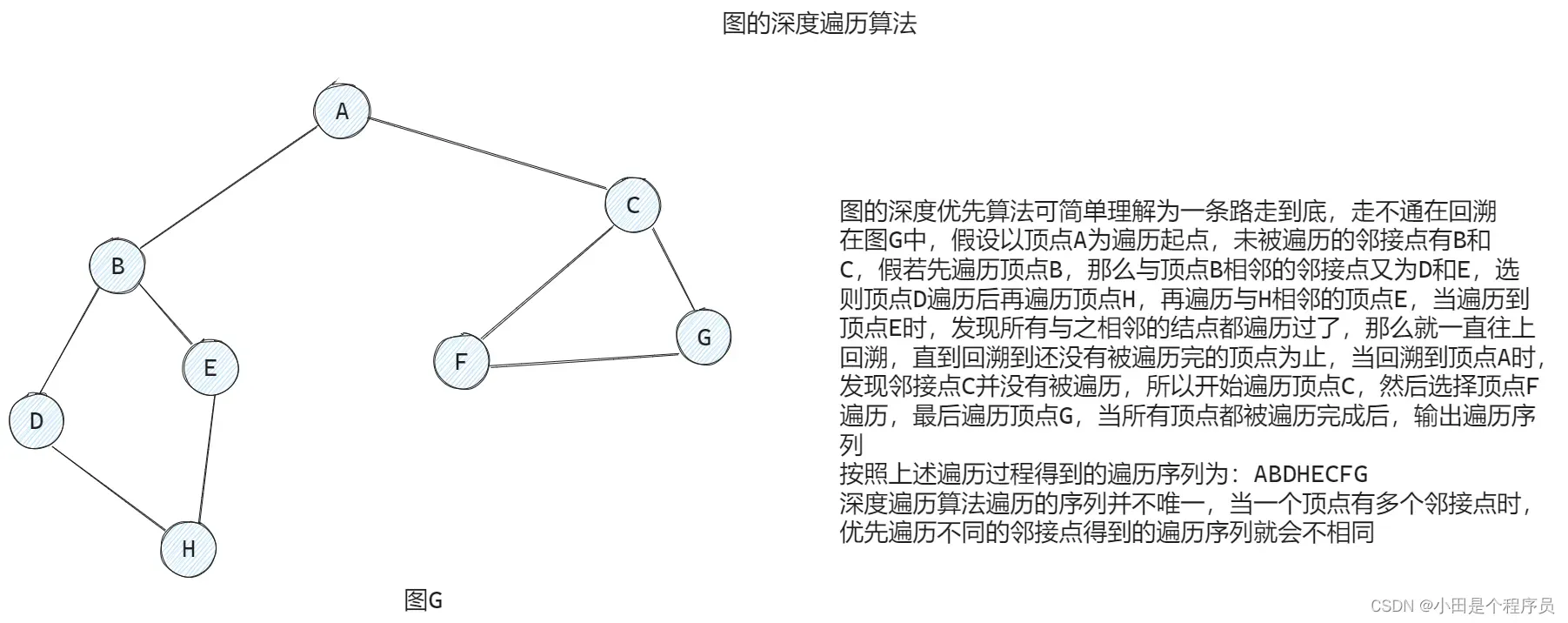
🚢深度优先遍历(DFS)
深度优先遍历(Depth First Search) 类似于🎯树的先序遍历算法,是树的先序遍历算法的推广。
深度优先遍历是一种先深度后广度的遍历方式。它从图的某个顶点开始,沿着一条路径遍历到底,然后回溯返回到上一个结点,继续遍历其他的分支。这个过程一直进行,直到所有顶点都被访问到。
#define MAX_VERTEX_NUM 100
typedef int VertexType; // 顶点数据类型
typedef struct ArcNode {
int adjvex; // 弧指向的顶点的位置
struct ArcNode *nextarc; // 下一条弧的指针
} ArcNode;
typedef struct VNode {
VertexType data; // 顶点数据
ArcNode *firstarc; // 首条弧的指针
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct {
AdjList vertices; // 顶点数组
int vexnum, arcnum; // 图的顶点数和弧数
} ALGraph;
// 深度优先搜索
void DFS(ALGraph *G, int v, int visited[]) {
printf("%d ", v); // 输出访问的顶点
visited[v] = 1; // 将顶点标记为已访问
// 遍历与顶点 v 相邻的顶点
ArcNode *p = G->vertices[v].firstarc;
while (p != NULL) {
int w = p->adjvex; // 与顶点 v 相邻的顶点 w
if (!visited[w]) {
DFS(G, w, visited); // 递归访问顶点 w
}
p = p->nextarc;
}
}
int main() {
ALGraph G;
// 读入图的顶点数和弧数
printf("Enter the number of vertices: ");
scanf("%d", &G.vexnum);
printf("Enter the number of arcs: ");
scanf("%d", &G.arcnum);
// 读入顶点数据
for (int i = 0; i < G.vexnum; i++) {
printf("Enter vertex data #%d: ", i);
scanf("%d", &G.vertices[i].data);
G.vertices[i].firstarc = NULL;
}
// 读入弧数据
for (int i = 0; i < G.arcnum; i++) {
int v, w;
printf("Enter the arc #%d (v w): ", i);
scanf("%d %d", &v, &w);
ArcNode *p = (ArcNode *)malloc(sizeof(ArcNode));
p->adjvex = w;
p->nextarc = G.vertices[v].firstarc;
G.vertices[v].firstarc = p;
}
// 初始化访问标记数组
int visited[G.vexnum];
for (int i = 0; i < G.vexnum; i++) {
visited[i] = 0;
}
// 从第一个顶点开始进行深度优先搜索
printf("DFS traversal result: ");
DFS(&G, 0, visited);
printf("\n");
return 0;
}
在上面的代码中,我们首先输入图的顶点数和弧数,并逐个输入顶点的数据和弧的两个顶点。然后,我们以第一个顶点作为起始点,调用深度优先搜索函数来遍历图中的所有顶点。在深度优先搜索函数中,我们用递归的方式遍历与某个顶点相邻的顶点,并将访问过的顶点标记为已访问。最终,输出深度优先搜索的结果。
🚢广度优先遍历(BFS)
广度优先遍历(Breadth First Search) 类似于树的层次遍历算法。
广度优先遍历是一种先广度后深度的遍历方式。它从图的某个顶点开始,首先访问该顶点,然后逐层访问其邻居结点,再逐层访问邻居的邻居结点,直到所有顶点都被访问到。
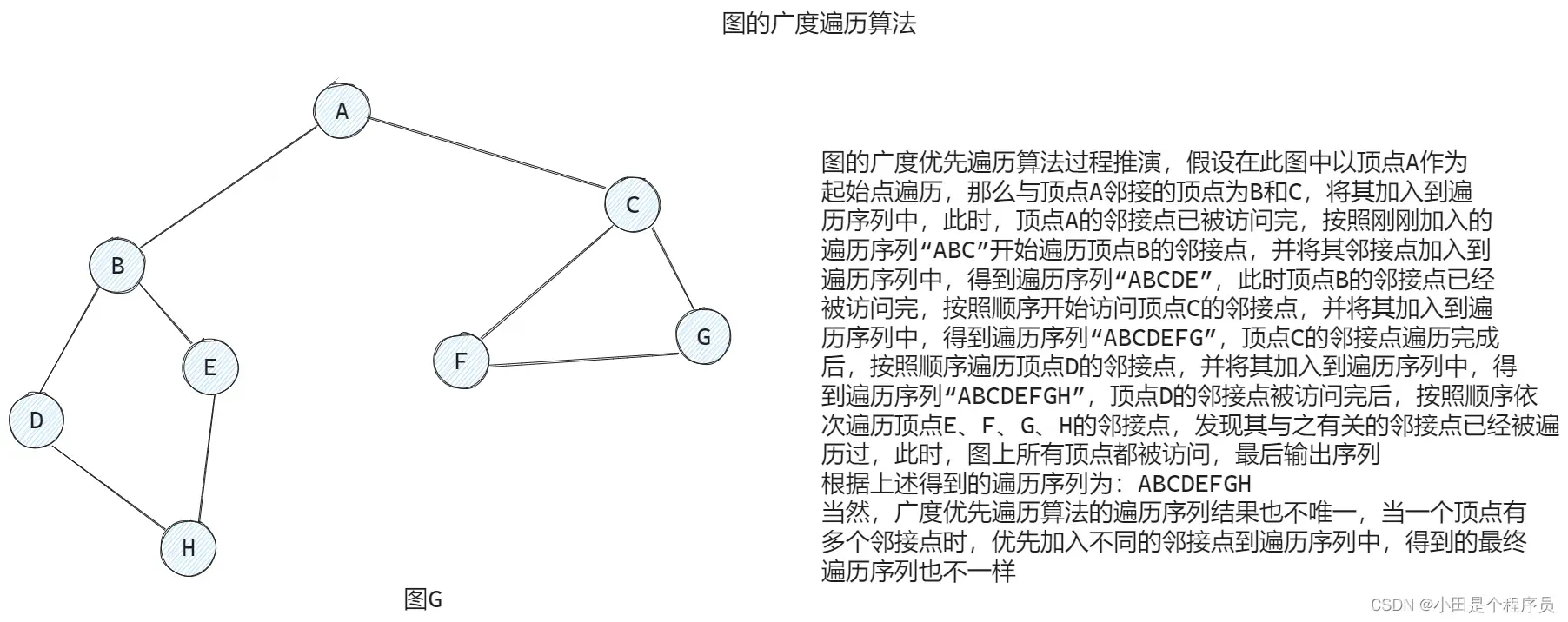
#define MAX_VERTEX_NUM 100
typedef int VertexType; // 顶点数据类型
typedef struct ArcNode {
int adjvex; // 弧指向的顶点的位置
struct ArcNode *nextarc; // 下一条弧的指针
} ArcNode;
typedef struct VNode {
VertexType data; // 顶点数据
ArcNode *firstarc; // 首条弧的指针
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct {
AdjList vertices; // 顶点数组
int vexnum, arcnum; // 图的顶点数和弧数
} ALGraph;
// 广度优先搜索
void BFS(ALGraph *G, int v, int visited[]) {
int queue[MAX_VERTEX_NUM];
int front = 0, rear = 0;
printf("%d ", v); // 输出访问的顶点
visited[v] = 1; // 将顶点标记为已访问
queue[rear++] = v; // 入队
while (front < rear) {
int w = queue[front++]; // 出队
// 遍历与顶点 w 相邻的顶点
ArcNode *p = G->vertices[w].firstarc;
while (p != NULL) {
int u = p->adjvex; // 与顶点 w 相邻的顶点 u
if (!visited[u]) {
printf("%d ", u); // 输出访问的顶点
visited[u] = 1; // 将顶点标记为已访问
queue[rear++] = u; // 入队
}
p = p->nextarc;
}
}
}
int main() {
ALGraph G;
// 读入图的顶点数和弧数
printf("Enter the number of vertices: ");
scanf("%d", &G.vexnum);
printf("Enter the number of arcs: ");
scanf("%d", &G.arcnum);
// 读入顶点数据
for (int i = 0; i < G.vexnum; i++) {
printf("Enter vertex data #%d: ", i);
scanf("%d", &G.vertices[i].data);
G.vertices[i].firstarc = NULL;
}
// 读入弧数据
for (int i = 0; i < G.arcnum; i++) {
int v, w;
printf("Enter the arc #%d (v w): ", i);
scanf("%d %d", &v, &w);
ArcNode *p = (ArcNode *)malloc(sizeof(ArcNode));
p->adjvex = w;
p->nextarc = G.vertices[v].firstarc;
G.vertices[v].firstarc = p;
}
// 初始化访问标记数组
int visited[G.vexnum];
for (int i = 0; i < G.vexnum; i++) {
visited[i] = 0;
}
// 从第一个顶点开始进行广度优先搜索
printf("BFS traversal result: ");
BFS(&G, 0, visited);
printf("\n");
return 0;
}
在上面的代码中,我们首先输入图的顶点数和弧数,并逐个输入顶点的数据和弧的两个顶点。然后,我们以第一个顶点作为起始点,调用广度优先搜索函数来遍历图中的所有顶点。在广度优先搜索函数中,我们使用队列来保存待访问的顶点,并按照先进先出的顺序进行访问。具体的实现是通过一个队列,将起始顶点入队,并标记为已访问;然后反复出队一个顶点,访问与之相邻且未访问过的顶点,将这些顶点入队,并标记为已访问。最终,输出广度优先搜索的结果。
🚀最小(代价)生成树
🚢基本概念
最小生成树 (Minimum Spanning Tree, MST) 是图中的一个重要概念,用于找到图中连接所有顶点的一棵树,同时保证树的边权值之和最小。
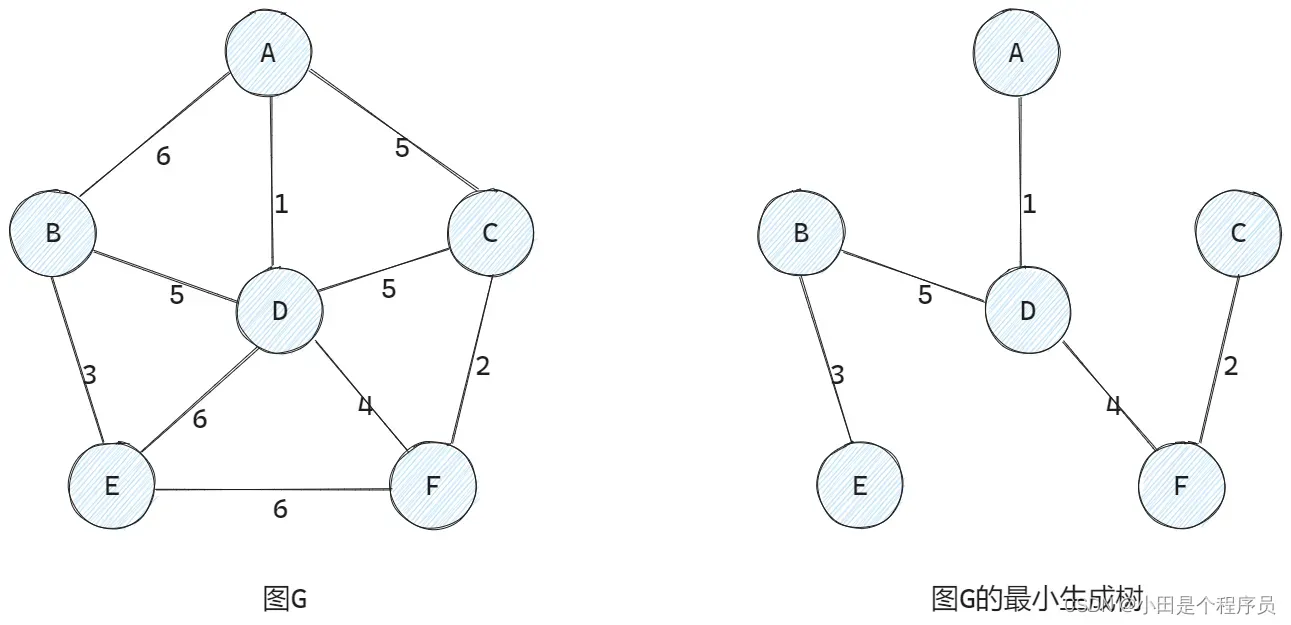
🚢基本性质
✨最小生成树不是唯一的,即最小生成树的树形不唯一,可能有多个最小生成树
✨最小生成树的边的权值之和总是最小的,并且是唯一的
✨最小生成树的边数为顶点数减1
🚢构造方法
👻Kruskal(克鲁斯卡尔)算法(从边出发)
- 将图中的所有边按照权值从小到大进行排序。
- 初始化一个空的最小生成树,然后依次选择排序后的边,若该边的两个顶点不在同一个连通分量中,则将该边加入最小生成树中,并将两个顶点合并为一个连通分量。
- 重复步骤2,直到最小生成树中包含了图中的所有顶点。
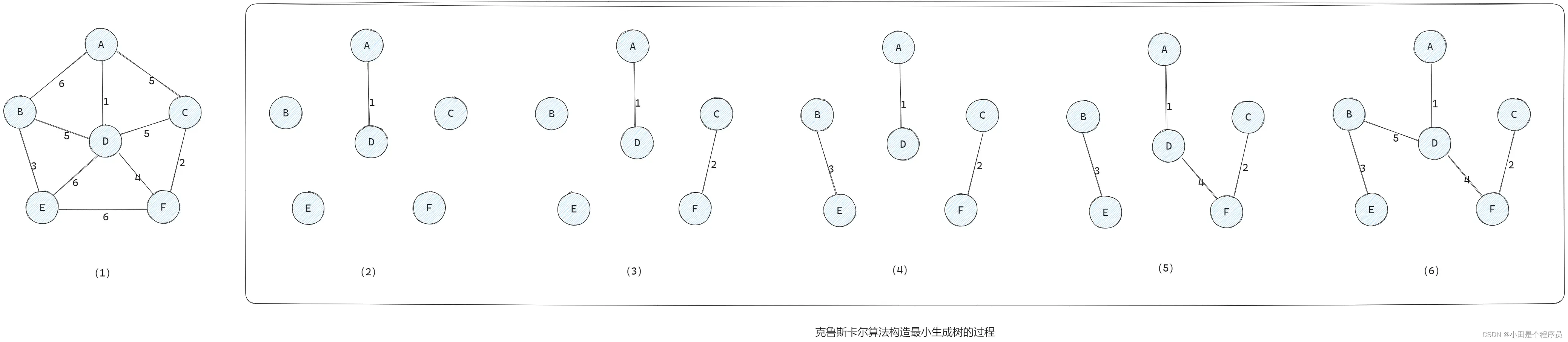
🚩适用于稠密图
👻Prim(普利姆)算法(从顶点出发)
- 初始化一个空的最小生成树,并选择一个起始顶点。
- 标记起始顶点为已访问,并将与之相邻的边加入边集合。
- 从边集合中选择权值最小的边,并将它的另一个顶点加入最小生成树,并将该边从边集合中删除。
- 重复步骤3,直到最小生成树包含了图中的所有顶点。
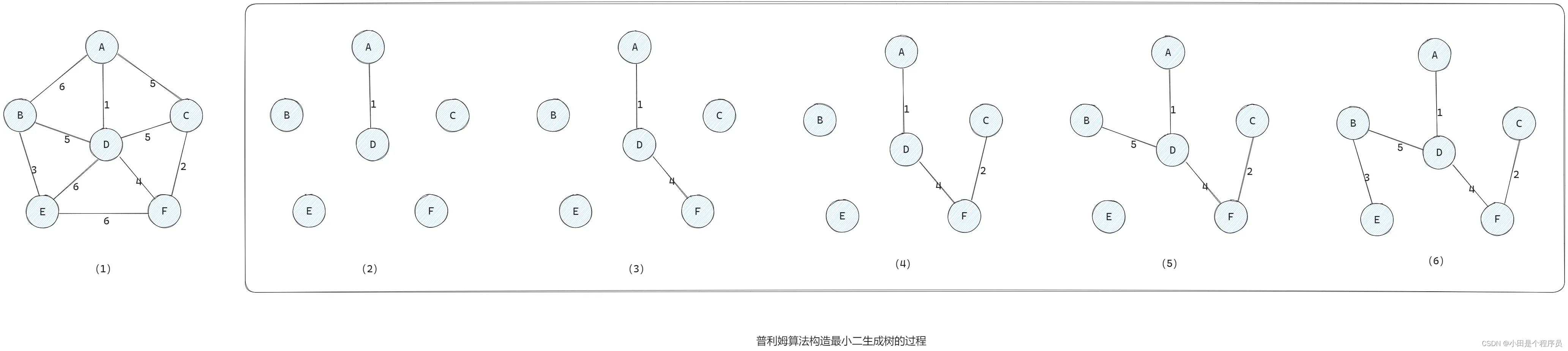
🚩适用于稀疏图
🚩注意:最小生成树的生成过程中,不能出现回路
🚀拓扑排序
🚢基本概念
拓扑排序是一种对有向无环图(DAG)的节点进行排序的算法,拓扑排序的基本思想是从图的一个顶点开始,不断选择入度为0的节点,并移除与之相关的边。🎯简单理解就是每次删除入度为0的顶点并输出。
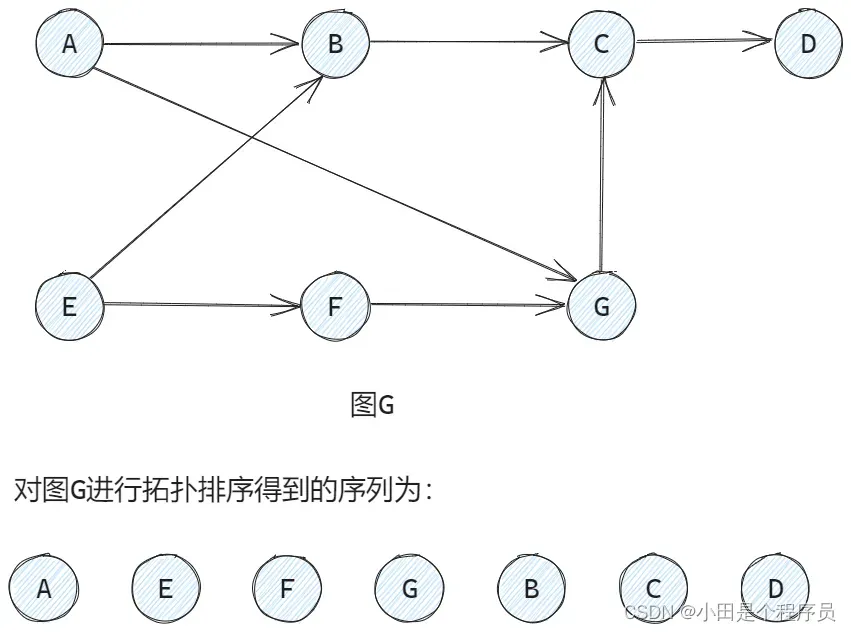
🚢算法示例
#define MAX_VERTEX_NUM 100
typedef int VertexType; // 顶点数据类型
typedef struct ArcNode {
int adjvex; // 弧指向的顶点的位置
struct ArcNode *nextarc; // 下一条弧的指针
} ArcNode;
typedef struct VNode {
VertexType data; // 顶点数据
ArcNode *firstarc; // 首条弧的指针
} VNode, AdjList[MAX_VERTEX_NUM];
typedef struct {
AdjList vertices; // 顶点数组
int vexnum, arcnum; // 图的顶点数和弧数
} ALGraph;
// 对图的邻接多重表进行拓扑排序
int TopologicalSort(ALGraph *G) {
int indegree[G->vexnum]; // 顶点的入度数组
int result[G->vexnum]; // 拓扑排序结果数组
int stack[G->vexnum]; // 存放入度为0的顶点的栈
int top = -1; // 栈顶指针
int count = 0; // 统计拓扑排序的顶点个数
// 初始化入度为0的顶点栈
for (int i = 0; i < G->vexnum; i++) {
indegree[i] = 0;
}
// 统计各顶点的入度
for (int i = 0; i < G->vexnum; i++) {
ArcNode *p = G->vertices[i].firstarc;
while (p != NULL) {
indegree[p->adjvex]++;
p = p->nextarc;
}
}
// 将入度为0的顶点入栈
for (int i = 0; i < G->vexnum; i++) {
if (indegree[i] == 0) {
stack[++top] = i;
}
}
while (top != -1) {
int v = stack[top--]; // 弹出栈顶的顶点
result[count++] = v; // 将顶点压入结果数组
// 删除顶点 v 及其关联的边
ArcNode *p = G->vertices[v].firstarc;
while (p != NULL) {
int w = p->adjvex; // 与顶点 v 相邻的顶点 w
if (--indegree[w] == 0) {
stack[++top] = w; // 若顶点 w 的入度减为0,则入栈
}
p = p->nextarc;
}
}
if (count < G->vexnum) {
return -1; // 图中存在环
}
// 输出拓扑排序的结果
printf("Topological sort result: ");
for (int i = 0; i < G->vexnum; i++) {
printf("%d ", result[i]);
}
printf("\n");
return 0;
}
int main() {
ALGraph G;
// 读入图的顶点数和弧数
printf("Enter the number of vertices: ");
scanf("%d", &G.vexnum);
printf("Enter the number of arcs: ");
scanf("%d", &G.arcnum);
// 读入顶点数据
for (int i = 0; i < G.vexnum; i++) {
printf("Enter vertex data #%d: ", i);
scanf("%d", &G.vertices[i].data);
G.vertices[i].firstarc = NULL;
}
// 读入弧数据
for (int i = 0; i < G.arcnum; i++) {
int v, w;
printf("Enter the arc #%d (v w): ", i);
scanf("%d %d", &v, &w);
ArcNode *p = (ArcNode *)malloc(sizeof(ArcNode));
p->adjvex = w;
p->nextarc = G.vertices[v].firstarc;
G.vertices[v].firstarc = p;
}
// 进行拓扑排序
int result = TopologicalSort(&G);
if (result == -1) {
printf("The graph contains a cycle.\n");
}
return 0;
}
这段代码使用邻接多重表表示图,并实现了拓扑排序的算法。首先,我们需要指定图的顶点数和弧数,然后逐个输入顶点的数据和弧的两个顶点。最终,算法会输出拓扑排序的结果,如果图中存在环,则输出相应的提示信息。
🚩注意:
如果图中存在环路,则无法进行拓扑排序,因为无法确定环中顶点的顺序关系。
拓扑排序的结果不一定是唯一的,而且不能得到有序序列。
🚀最短路径
🚢基本概念
图的最短路径问题是指在图中寻找两个顶点之间的最短路径,即图中经过的边的权重总和最小的路径。
最短路径问题可以通过多种算法来解决,主要是两种常用的算法:Dijkstra(迪杰斯特拉)算法和Floyd(弗洛伊德)算法。
🚢算法
👻Dijkstra(迪杰斯特拉)算法(求一个顶点到其他各顶点的最短路径)
Dijkstra算法用于解决单源最短路径问题,即从一个顶点出发,找到到达其他所有顶点的最短路径。算法的基本思想是通过逐步扩展已找到最短路径的顶点集合来逐渐确定从起点到其他顶点的最短路径。
🎯具体步骤如下:
✨初始化:将起点的最短距离设为0,其他顶点的最短距离设为无穷大。
✨选择当前距离起点最短的顶点作为已确定最短路径的顶点。
✨更新其他顶点的最短距离:对于与当前顶点相邻的顶点,更新到达这些顶点的路径长度(若经过当前顶点得到的新路径更短)。
✨重复(2)和(3)直到所有顶点都被确定最短路径或者不存在从起点到剩余顶点的路径。
🚩Dijkstra算法的时间复杂度依赖于图的顶点数和边数,通常为O(V2),其中
👻Floyd(弗洛伊德)算法(求每对顶点之间的最短路径)
Floyd算法用于解决全源最短路径问题,即找到任意两个顶点之间的最短路径。算法的基本思想是通过动态规划的方式不断更新所有顶点对之间的最短路径。
🎯具体步骤如下:
✨初始化:将所有顶点对之间的最短路径设为无穷大,但对角线上的值设为0。
✨动态规划更新最短路径:对于每两个顶点i和j,如果存在一个中间顶点k,使得经过k的路径比直接经过j的路径更短,则更新i和j之间的最短路径为经过顶点k的路径。
✨重复(2)直到所有顶点对之间的最短路径都被确定。
Floyd算法的时间复杂度为O(V3),其中为顶点数。相对于Dijkstra算法,🎯
Floyd算法适用于具有负权边的图,并且能够返回任意两个顶点之间的最短路径。
🚩Dijkstra算法适用于单源最短路径问题,而Floyd算法适用于全源最短路径问题。
💻总结
图是一种抽象的数据结构,用于表示对象之间的关系。 它由顶点和边组成。顶点表示对象,边表示顶点之间的关系。图可以用来解决各种实际问题,例如最短路径、最小生成树、网络分析等。总的来说,图在许多领域中都有广泛的应用,其灵活性和可扩展性使其成为解决复杂问题和处理大规模数据的有力工具。图算法和图数据库的发展也为图的应用提供了更高效和更强大的解决方案。
🎨觉得不错的话记得点赞收藏呀!!🎨
😀别忘了给我关注~~😀
文章出处登录后可见!