目录
全局比对算法(Needleman-Wunsch)
原理
其实这个跟数据结构学过的最短路径问题很像,核心思想就是依次寻求重复子问题的最优子结构。Needleman-Wunsch算法是一种全局联配算法,从整体上分析两个序列的关系,即考虑序列总长的整体比较,用类似于使整体相似最大化的方式,对序列进行联配。两个不等长度序列的联配分析必须考虑在一个序列中一些碱基的删除,即在另一序列做空位(Gap)处理。
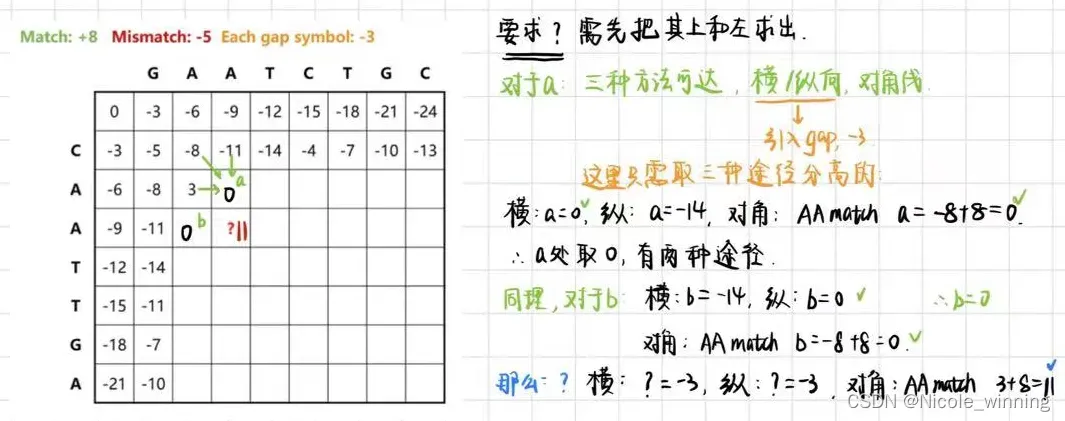
R代码实现
#全局比对(Needleman-Wunsch)
# 定义匹配、不匹配、gap的分数
library(stringr)
match_score <- 9 #匹配得分
mismatch_score <- -6 #不匹配得分
gap_penalty <- -2 #gap罚分
distance <- c(1,2,4) #记录数据来源方向,分别代表对角、从上到下和从左到右
# 两个DNA序列
seq1 <- c("AACGTACTCAAGTCT")
seq2 <- c("TCGTACTCTAACGAT")
# 创建一个二维矩阵来保存比对得分
n <- nchar(seq1)
m <- nchar(seq2)
seq1_n <- strsplit(seq1, "")[[1]]
seq2_n <- strsplit(seq2, "")[[1]]
score_matrix <- matrix(0, n + 1, m + 1, dimnames = list(c("0", seq1_n), c("0", seq2_n))) #创建一个得分矩阵,初始化全为0
route <- matrix(0, nrow = n+1, ncol = m+1, dimnames = list(c("0", seq1_n), c("0", seq2_n))) #创建一个路径矩阵,初始化全为0
# 初始化得分矩阵(第一行和第一列,依次加gap罚分)
for (i in 2:(n + 1)) {
score_matrix[i, 1] <- (i-1)*gap_penalty
route[i, 1] <- distance[2] #记录方向为从上到下
}
for (j in 2:(m + 1)) {
score_matrix[1, j] <- (j-1)*gap_penalty
route[1, j] <- distance[3] #记录方向为从左到右
}
# 计算得分矩阵
for (i in 2:(n + 1)) {
for (j in 2:(m + 1)) {
match_value <- ifelse(substr(seq1, i - 1, i - 1) == substr(seq2, j - 1, j - 1), match_score, mismatch_score)
scores <- c(score_matrix[i - 1, j - 1] + match_value, #走对角匹配
score_matrix[i - 1, j] + gap_penalty, #从上到下引入空缺
score_matrix[i, j - 1] + gap_penalty) #从左到右引入空缺
score_matrix[i, j] <- max(scores) #取三种路径最大值
index <- which(scores == max(scores)) #看三种路径哪个值最大,存储这个方向来源
for(z in index){
route[i, j] <- route[i, j] + distance[z] #把得到最大值的方向来源加和作为路径值
}
}
}
result <- list(score_matrix,route) #返回一个列表,包含得分矩阵和路径矩阵
#绘制得分矩阵retype
library(pheatmap)
pheatmap(score_matrix,
color = colorRampPalette(c("lightpink", "red","purple"))(256),
display_numbers = score_matrix,
number_color = "white",
cluster_rows = FALSE,
cluster_cols = FALSE,
show_rownames = TRUE,
show_colnames = TRUE,
fontsize = 13,
legend = TRUE,
fontsize_number = 13)
#回溯算法
back_route <- function(route){
seq1 <- rownames(route)
seq2 <- colnames(route)
path <- list(0)
#从最右下角的值开始回溯
path <- back_location(seq1, seq2, route, length(seq1), length(seq2), path)
path[[1]] <- NULL
return(path)
}
#x和y记录当前位置
back_location <- function(seq1, seq2, route, x, y, path){
#回溯的一种匹配模式,将其加入path
if(x == 1 & y == 1){
#匹配到左上角
seq1 <- str_c(c( seq1[2:length(seq1)]), collapse = "")
seq2 <- str_c(c( seq2[2:length(seq2)]), collapse = "")
path[[length(lengths(path))+1]] <- rbind(seq1, seq2)
}
else{
#来源有对角,可能是对角(1),对角+上(3),对角+左(5),对角只用考虑是否匹配,不引入空缺
if(route[x, y] == 1 || route[x, y] == 3 || route[x, y] == 5){
seq_m1 <- seq1
seq_m2 <- seq2
path <- back_location(seq_m1, seq_m2, route, x - 1, y - 1, path)
}
#来源有上方,可能是只有上方来的(2),或者上+对角(3),或者上+左(6)
if(route[x, y] == 2 || route[x, y] == 3 || route[x, y] == 6){
seq_m1 <- seq1
seq_m2 <- seq2
#在seq2的y+1位置插入“-”
for(i in length(seq_m2):min((y+1), length(seq_m2))){
seq_m2[i+1] <- seq_m2[i] #没有走对角,引入空缺,故下那个碱基仍然是该行碱基
}
seq_m2[y+1] <- "-" #由于是从上到下来源,所以第二列序列引入空缺
path <- back_location(seq_m1, seq_m2, route, x - 1, y, path)
}
#来源有左方,同理,可能是左方(4),左+对角(5)、左+上(6)
if(route[x, y] == 4 || route[x, y] == 5 || route[x, y] == 6){
seq_m1 <- seq1
seq_m2 <- seq2
#在seq1的x+1位置插入“-”
for(i in length(seq_m1):min((x+1), length(seq_m1))){
seq_m1[i+1] <- seq_m1[i]
}
seq_m1[x+1] <- "-"
path <- back_location(seq_m1, seq_m2, route, x, y - 1, path)
}
}
#因为用了递归的方式,所以path更新后要传给上一层
return(path)
}
p <- back_route(result[[2]]) #result[[2]]是list的第二个数据,即路径得分
print(p)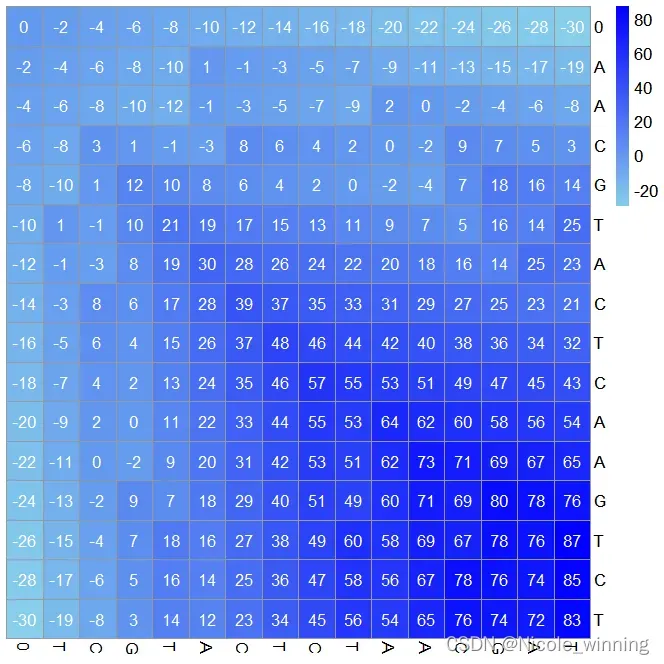
上图为全局比对的得分矩阵热图,可以看到右下角分数为83,即全局比对最优结果为83分,下面看看回溯结果。一共有15个最优比对结果。


局部比对算法(Smith-Waterman)
原理
史密斯-沃特曼算法(Smith-Waterman algorithm)是一种进行局部序列比对(相对于全局比对)的算法,用于找出两个核苷酸序列或蛋白质序列之间的相似区域。该算法的目的不是进行全序列的比对,而是找出两个序列中具有高相似度的片段。
该算法由坦普尔·史密斯(Temple F. Smith)和迈克尔·沃特曼(Michael S. Waterman)于1981年提出。Smith-Waterman算法是Needleman-Wunsch算法的一个变体,二者都是动态规划算法。这一算法的优势在于可以在给定的打分方法下找出两个序列的最优的局部比对(打分方法使用了置换矩阵和空位罚分)。该算法和Needleman-Wunsch算法的主要区别在于该算法不存在负分(负分被替换为零),因此局部比对成为可能。回溯从分数最高的矩阵元素开始,直到遇到分数为零的元素停止。分数最高的局部比对结果在此过程中产生。在实际运用中,人们通常使用该算法的优化版本。创建初始矩阵时初始化其首行和首列均为0。
R代码实现
##局部比对(Smith-Waterman)
# 定义匹配、不匹配、gap的分数
library(stringr)
match_score <- 9 #匹配得分
mismatch_score <- -6 #不匹配得分
gap_penalty <- -2 #gap罚分
# 两个DNA序列
seq1 <- c("AACGTACTCAAGTCT")
seq2 <- c("TCGTACTCTAACGAT")
# 创建一个二维矩阵来保存比对得分
n <- nchar(seq1) #字符串长度
m <- nchar(seq2)
seq1_n <- strsplit(seq1, "")[[1]] #得到单个碱基(character)
seq2_n <- strsplit(seq2, "")[[1]]
score_matrix <- matrix(0, n + 1, m + 1, dimnames = list(c("0", seq1_n), c("0", seq2_n))) #创建一个得分矩阵,初始化全为0
#计算得分矩阵
for (i in 2:(n + 1)) {
for (j in 2:(m + 1)) {
match_value <- ifelse(substr(seq1, i - 1, i - 1) == substr(seq2, j - 1, j - 1), match_score, mismatch_score)
scores <- c(score_matrix[i - 1, j - 1] + match_value, #走对角匹配
score_matrix[i - 1, j] + gap_penalty, #从上到下引入空缺
score_matrix[i, j - 1] + gap_penalty, #从左到右引入空缺
0) #还有一种0
score_matrix[i, j] <- max(scores) #取四种路径最大值
}
}
#绘制得分矩阵热图
library(pheatmap)
pheatmap(score_matrix,
color = colorRampPalette(c("lightpink", "red","purple"))(256),
display_numbers = score_matrix,
number_color = "white",
cluster_rows = FALSE,
cluster_cols = FALSE,
show_rownames = TRUE,
show_colnames = TRUE,
fontsize = 13,
legend = TRUE,
fontsize_number = 13)
# 回溯过程,递归
max_score <- max(score_matrix) #找到得分矩阵最大值位置
max_indices <- which(score_matrix == max_score, arr.ind = TRUE)
backtrack <- function(score_matrix, max_indices) {
nrow <- nrow(score_matrix)
ncol <- ncol(score_matrix)
current <- max_indices #定义当前位置
aligned_seq1 <- "" #定义两个空串
aligned_seq2 <- "" #定义两个空串
while (score_matrix[current[1], current[2]] != 0) {
move <- choose_move(score_matrix, current[1], current[2])
#从对角来
if (move == "diagonal") {
aligned_seq1 <- paste(seq1_n[current[1] - 1], aligned_seq1, sep = "")
aligned_seq2 <- paste(seq2_n[current[2] - 1], aligned_seq2, sep = "")
current <- c(current[1] - 1, current[2] - 1)
}
#从上到下
else if (move == "up") {
aligned_seq1 <- paste(seq1_n[current[1] - 1], aligned_seq1, sep = "")
aligned_seq2 <- paste("-", aligned_seq2, sep = "")
current <- c(current[1] - 1, current[2])
}
#从左到右
else {
aligned_seq1 <- paste("-", aligned_seq1, sep = "")
aligned_seq2 <- paste(seq2_n[current[2] - 1], aligned_seq2, sep = "")
current <- c(current[1], current[2] - 1)
}
}
return(list(aligned_seq1, aligned_seq2))
}
# 选择移动方向
choose_move <- function(score_matrix, i, j) {
if (score_matrix[i, j] == (score_matrix[i - 1, j - 1] + match_score) && seq1_n[i - 1] == seq2_n[j - 1]) {
return("diagonal") #这里需要注意,回溯对角来源时要看是否匹配,否则返回结果除首尾匹配中间的碱基是平移的,即中间错配
} else if (score_matrix[i, j] == (score_matrix[i - 1, j - 1] + mismatch_score) && seq1_n[i - 1] != seq2_n[j - 1]) {
return("diagonal") #不匹配也可能从对角来
} else if (score_matrix[i, j] == (score_matrix[i - 1, j] + gap_penalty)) {
return("up")
} else {
return("left")
}
}
# 调用回溯函数
result <- backtrack(score_matrix, max_indices)
aligned_seq1 <- result[[1]]
aligned_seq2 <- result[[2]]
# 输出比对结果
print(aligned_seq1)
print(aligned_seq2)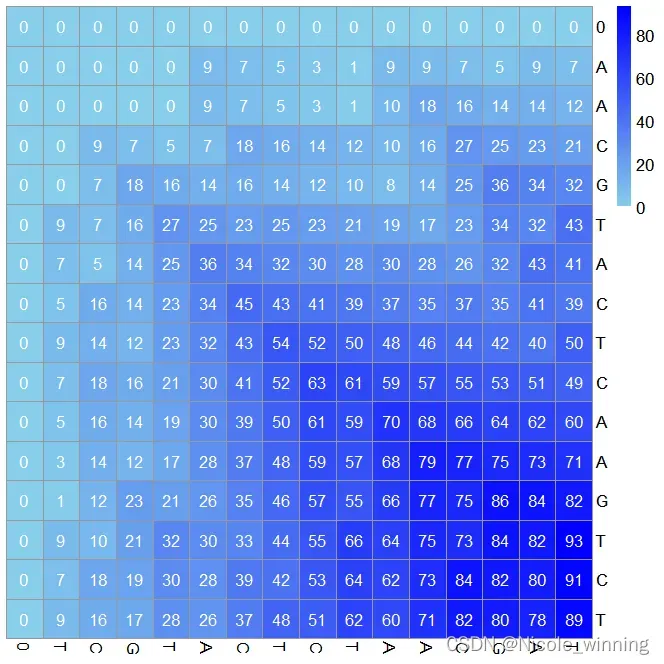
上图为局部比对的得分矩阵热图,可以看到得分最大值为93,即局部比对最优结果为93分,下面看看回溯结果。

除此之外,R自带函数也可以比对,调用也很容易,更改type=”global”或者”local”即可实现全局和局部比对,代码如下:
install.packages("Biostrings") #安装R包,它提供了用于序列操作、比对、模式匹配、转录组分析等功能的工具集合。
library(Biostrings) #加载R包
seq1 <- DNAString("AACGTACTCAAGTCT") #输入DNA序列
seq2 <- DNAString("TCGTACTCTAACGAT") #输入DNA序列
#设置参数,匹配得分9分,不匹配得分-6分
mat <- nucleotideSubstitutionMatrix(match = 9, mismatch = -6, baseOnly = TRUE)
View(mat) #查看碱基匹配矩阵
#执行全局序列比对
Alignment <- pairwiseAlignment(seq1, seq2, substitutionMatrix = mat,gapOpening = 0, gapExtension = -2, type = “global”)
Alignment比对结果如下,不同的是,回溯结果都只输出一个。


总结
全局比对和局部比对的显著区别是局部比对的得分矩阵中的分值均≥0,即在考虑打分方式时,局部比对要多考虑一种。在初始化得分矩阵的第一行和第一列时,两者有不同。对于全局比对,需要依次加上gap罚分值,而对于局部比对,则只需要都初始化为0。全局比对和局部比对的核心思想是依次寻求重复子问题的最优子结构,通过序列比对,可以发现序列之间的相似性,也可以判别序列之间的同源性,推断序列之间的进化关系,辨别序列之间的差别,寻找遗传变异。
文章出处登录后可见!