“ Meta 开源 LLAMA2 后,国内出现了不少以此为基座模型训练的中文模型,这次我们来看看其中一个不错的中文模型:Chinese-LLaMA-Alpaca-2 。”

01
—
目前在开源大模型中,比较有名的是Meta的LLAMA模型系列和清华的ChatGLM模型。
特别是在中文领域上,ChatGLM模型经过中文问答和对话的优化,更加符合中文使用者的偏好回答。
我对ChatGLM比较关注,出来的时候就开始体验和尝试本地部署,之前有几篇关于ChatGLM的文章。
ChatGLM 更新:LongBench—评测长文本理解能力的数据集,支持 32k 上下文的 ChatGLM2-6B-32K
快捷部署清华大模型 ChatGLM2-6B,一键搞定 HuggingFace Space 空间
自从Meta于7月19日凌晨开源了Llama2,并且可免费商用后,国内也开始了基于Llama2的中文大模型训练,并推出了相应的中文模型。
今天推荐朋友们看看其中一个比较好的中文模型: Chinese-LLaMA-Alpaca-2,它Llama-2的基础上扩充并优化了中文词表,使用了大规模中文数据进行增量预训练,进一步提升了中文基础语义和指令理解能力。
目前已开源的模型:Chinese-LLaMA-2(7B/13B), Chinese-Alpaca-2(7B/13B)。开源地址:
https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
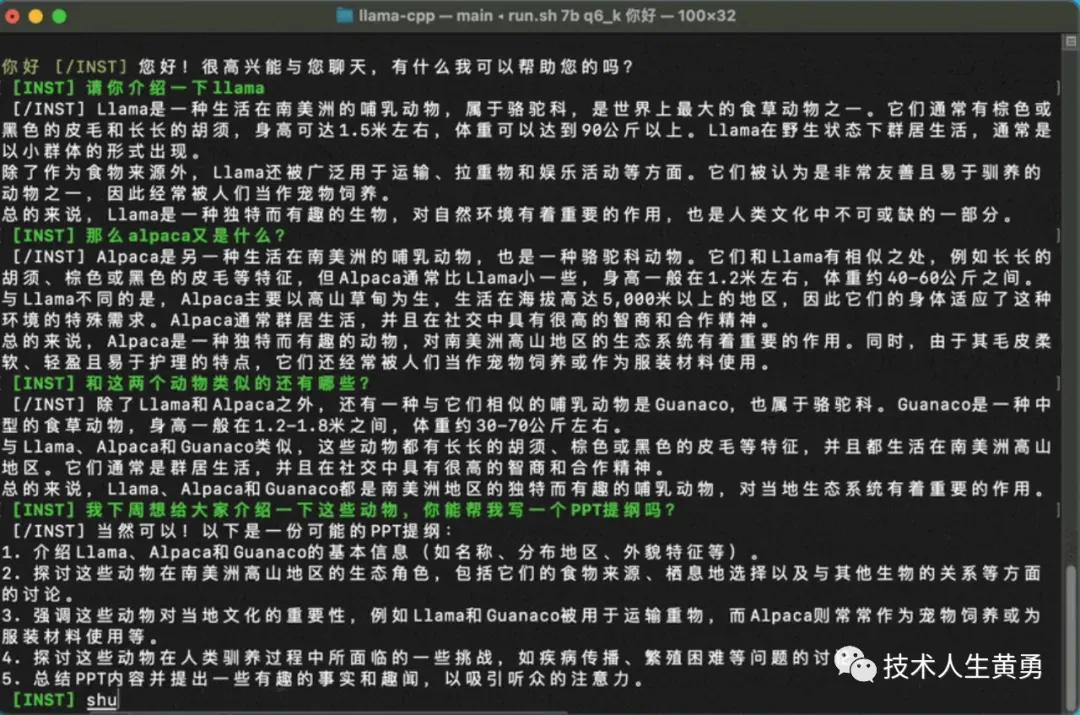
看一下它的对话效果。
模型特点
优化的中文词表
在二期中,团队以一期中文字词(LLaMA:49953,Alpaca:49954)基础上的重新设计了新词表(大小:55296),进一步提升了中文字词的覆盖程度,同时统一了LLaMA/Alpaca的词表,避免了因混用词表带来的问题,以期进一步提升模型对中文文本的编解码效率
基于FlashAttention-2的高效注意力
FlashAttention-2是高效注意力机制的一种实现,相比其一代技术具有更快的速度和更优化的显存占用
当上下文长度更长时,为了避免显存爆炸式的增长,使用此类高效注意力技术尤为重要
所有模型均使用了FlashAttention-2技术进行训练
基于NTK的自适应上下文扩展技术
在一期项目中,团队实现了基于NTK的上下文扩展技术,可在不继续训练模型的情况下支持更长的上下文
在上述基础上,团队进一步设计了方便的自适应经验公式,无需针对不同的上下文长度设置相应超参
本项目模型原生支持4K上下文,利用上述技术可扩展至12K,并最高支持扩展至18K+(精度有一定损失)
模型在原版Llama-2的基础上扩充并优化了中文词表,使用了大规模中文数据进行增量预训练,进一步提升了中文基础语义和指令理解能力,相比一代相关模型获得了显著性能提升。相关模型支持FlashAttention-2训练,支持4K上下文并可通过NTK方法最高扩展至18K+。
(NTK代表”Neural Tangents Kernel”,是一种用于分析神经网络行为的工具,特别是在深度学习中的无穷窄网络架构。NTK分析的主要目标是了解神经网络在训练过程中的动态行为,尤其是在网络权重随机初始化的情况下,网络的输出如何随着训练数据的变化而变化。
NTK分析的核心思想是,通过使用网络的初始权重和激活函数,可以近似网络在训练过程中的行为。这种近似可以将神经网络视为一个线性的无穷窄网络,这种网络在训练过程中不会发生非线性变化。这种近似使得可以通过分析线性核函数的性质来研究网络的行为,从而更好地理解网络的一些特性,如收敛性、泛化能力等。
NTK分析在一些领域中具有应用,比如帮助理解神经网络在训练早期的行为,从而指导训练策略的设计;还可以用于研究网络架构的影响、初始化方法的选择等。然而,需要注意的是,NTK分析是一种近似方法,在某些情况下可能与真实的神经网络行为存在一些差异。)
简化的中英双语系统提示语
在一期项目中,中文Alpaca系列模型使用了Stanford Alpaca的指令模板和系统提示语
初步实验发现,Llama-2-Chat系列模型的默认系统提示语未能带来统计显著的性能提升,且其内容过于冗长
本项目中的Alpaca-2系列模型简化了系统提示语,同时遵循Llama-2-Chat指令模板,以便更好地适配相关生态
(Stanford Alpaca是一个大型中文预训练语言模型,其指令模版(Prompt Template)指的是该模型训练过程中使用的一种指令学习机制。
具体来说,Stanford Alpaca的训练采用了以下方法:
人工构建了大量的中英文指令对,如”翻译成中文” – “Translate into Chinese”。
在模型预训练时,同时输入这些指令和对应的训练文本,让模型学习执行特定指令的能力。
在微调或使用阶段,可以用这些预定义的指令提示模型执行相应的语言任务,如翻译、摘要等。
用户也可以自定义新的指令模版,扩展模型的能力。
通过这种指令学习机制,Stanford Alpaca可以更好地理解人类的意图,执行符合指令的语言处理任务,提高了模型的适用性和可控性。预定义的指令模版起到了领域自适应的作用。)
模型选择指引
下面是中文LLaMA-2和Alpaca-2模型的基本对比以及建议使用场景。
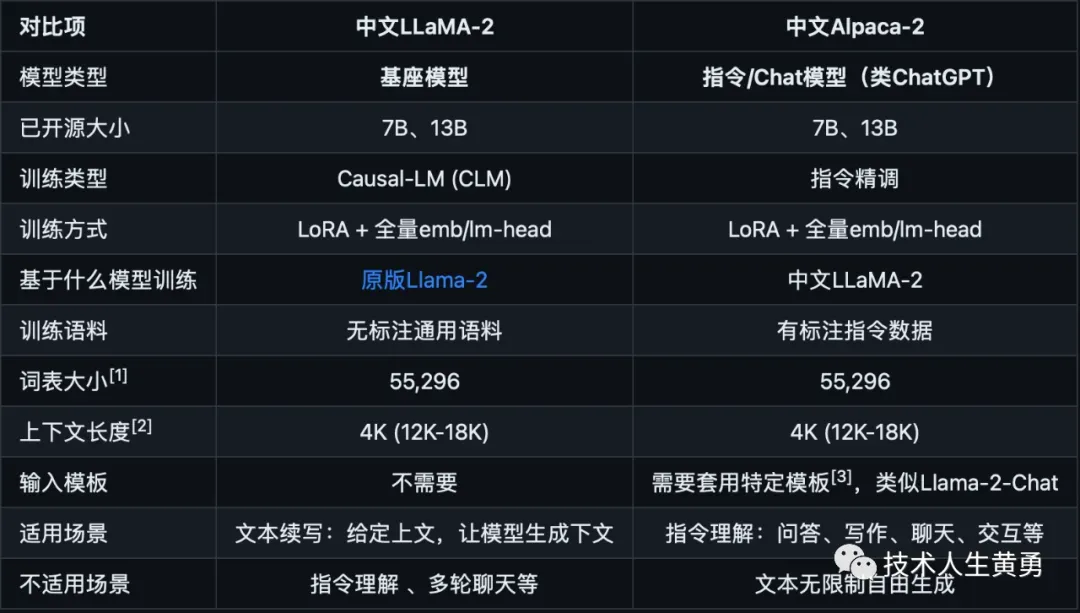
从上表看,如果以大模型为核心做应用,最好选择Alpaca-2。比如和模型聊天交互,如果想从一个基座模型,训练一个垂直行业类的模型,选择LLaMA-2比较合适。
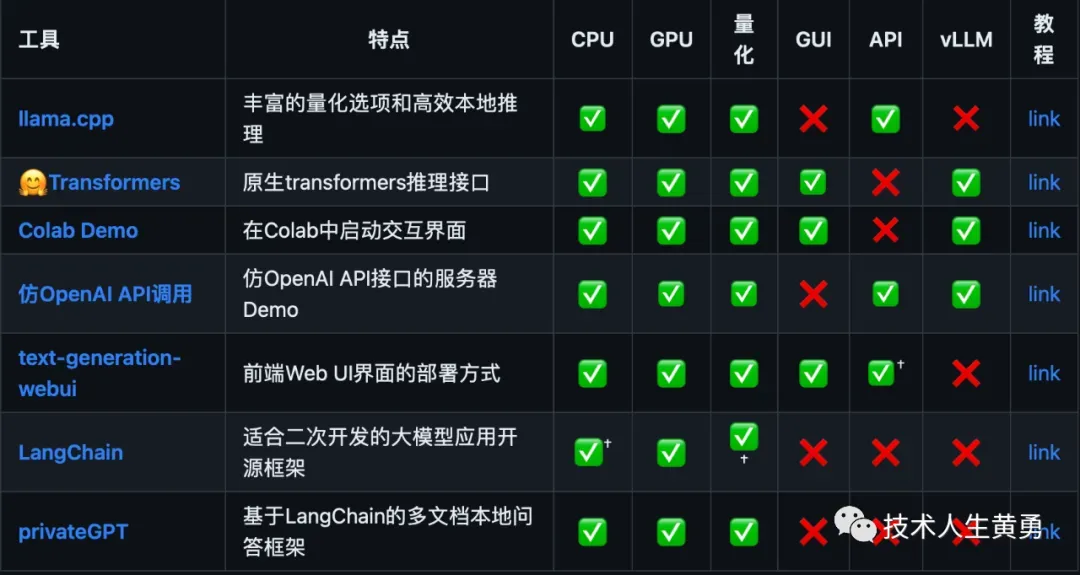
推理与部署
模型主要支持以下量化、推理和部署方式,具体内容请参考官网的对应教程。
C-Eval评测
一个全面的中文基础模型评估套件,其中验证集包含1.3K个选择题,测试集包含12.3K个选择题,涵盖52个学科,题目类型为选择题。实验结果以“zero-shot / 5-shot”进行呈现。
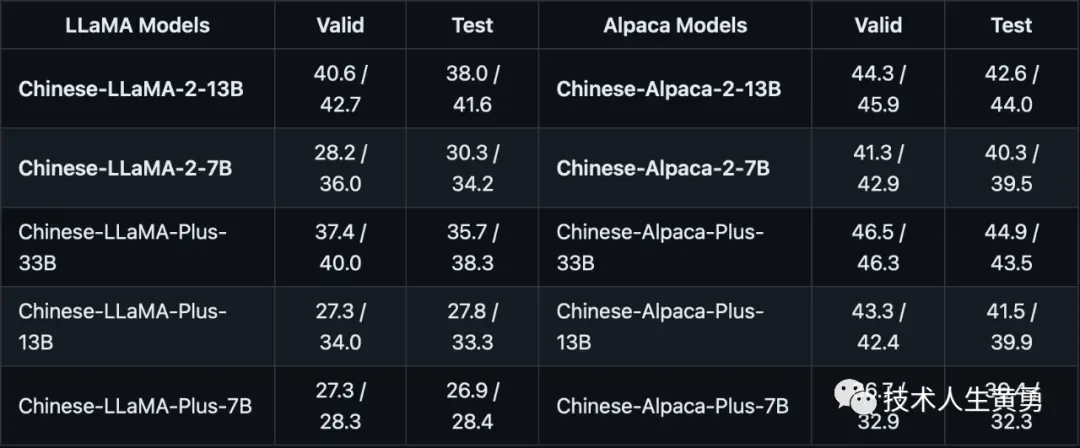
CMMLU评测
综合性中文评测数据集,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题,共计11.5K个测试样例,题目类型为选择题。
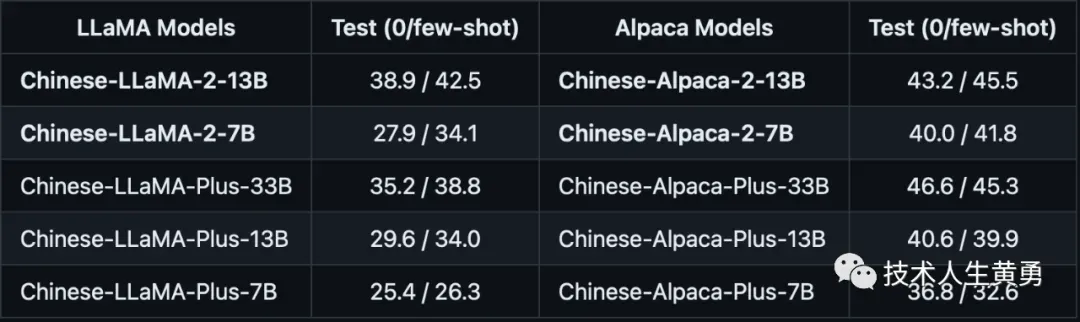
感兴趣的朋友,可以去官网下载模型,本地或者云平台运行一下,体验对话效果,和指令执行的效果。
如果自己有开发基于大模型的应用,可以在此基础上,增加对这个中文模型的调用支持。
阅读推荐:
LLama2详细解读 | Meta开源之光LLama2是如何追上ChatGPT的?
免费!深夜福利|英伟达推出NGC目录 – GPU加速的AI模型和SDK:Llama 2和SDXL
ChatGPT 的“自定义”功能对免费用户开放,在问题信息不足情况下还会反问来获取必要信息
Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本
AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被”提示攻击”攻陷!
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。
文章出处登录后可见!