1 intro
使用LMM生成活动轨迹的开创性工作
1.1 生成活动轨迹的意义
- 理解活动模式(mobility pattern)——>能够灵活模拟城市移动性
- 尽管个体活动轨迹数据由于通信技术的进步而丰富,但其实际使用往往受到隐私顾虑的限制
- ——>生成的数据可以提供一种可行的替代方案,提供了效用和隐私之间的平衡
1.2 之前生成活动轨迹的方法的不足
- 之前有很多数据驱动的基于学习的方法
- 生成的数据仅从数据分布的角度而非语义上模仿真实世界的数据,使它们在模拟或解释新颖或未预见到的具有显著不同分布的场景(例如,大流行疾病)的活动中效果较差
1.3 本文思路
- 使用大模型生成活动轨迹
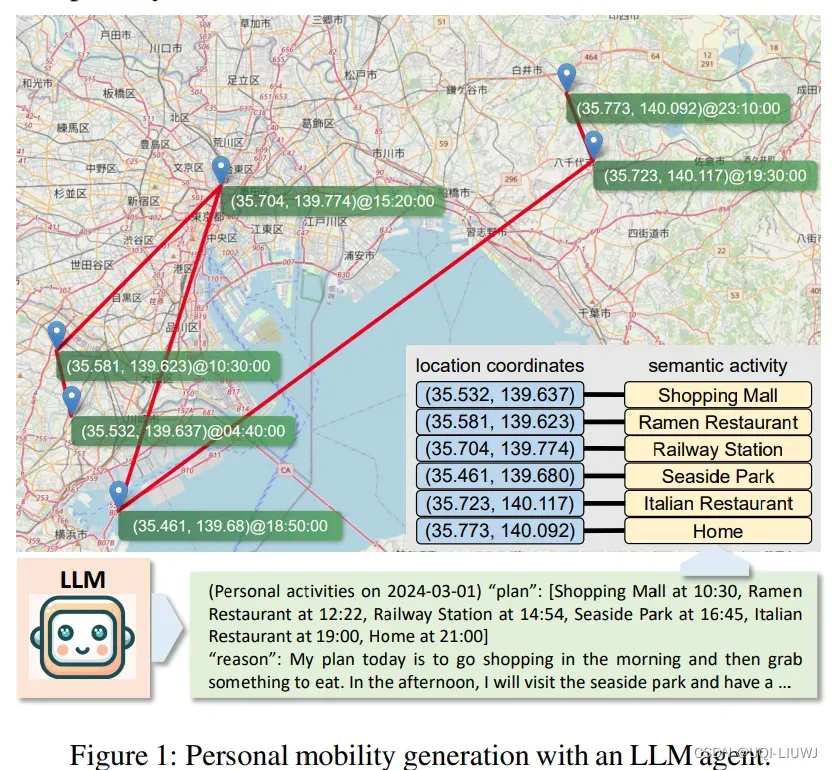
这个图没有说清楚,我个人的感觉是,LLM得到plan和reason的部分,然后根据plan里面的semantic activity(POI),对应到location coordinate上
1.3.1 大模型相比于之前模型的优势
- 语义可解释性
- 与之前主要依赖于结构化数据(基于GPS坐标的轨迹数据)不同,LLMs在解释语义数据(例如,活动轨迹数据)方面展现出了专长
- ——>可以将多样化数据源纳入生成过程
- ——>增强了模型理解和与复杂、真实世界场景以更细腻和有效的方式互动的能力
- 与之前主要依赖于结构化数据(基于GPS坐标的轨迹数据)不同,LLMs在解释语义数据(例如,活动轨迹数据)方面展现出了专长
- 模型通用性
- 之前的模型在未见场景下的生成能力有限
- LLMs在处理未见任务上显示出了显著的通用性,尤其是基于可用信息进行推理和决策的能力
1.3.2 挑战与解决方法
- RQ 1: LLM如何有效地与关于日常个人活动的富语义数据对齐?
- RQ 2: 使用LLM实现可靠且有意义的活动生成的有效策略是什么?
- RQ 3: LLM在增强城市移动性方面的潜在应用是什么?
1.3.3 论文的两阶段
- 自洽活动模式识别
- 提取并评估历史数据和语义分析中的活动模式
- 使用LLM代理生成多样化和个性化的活动场景
- 动机驱动的活动生成
- 开发了两种可解释的检索增强策略
- 结合第一阶段识别的模式,指导LLM代理总结出动机,如不断变化的兴趣或情境需求
- 开发了两种可解释的检索增强策略
2 问题表述
- 研究城市背景下,个体每日活动轨迹的生成,每个轨迹代表一个人一整天的活动
- 每个个体的活动表示为一个时间有序的地点选择序列{(l0, t0),(l1, t1), …, (ln, tn)}
- (l, t)表示个体在时间t的位置l
- 每个个体的活动表示为一个时间有序的地点选择序列{(l0, t0),(l1, t1), …, (ln, tn)}
3 方法
论文提出了LLMob
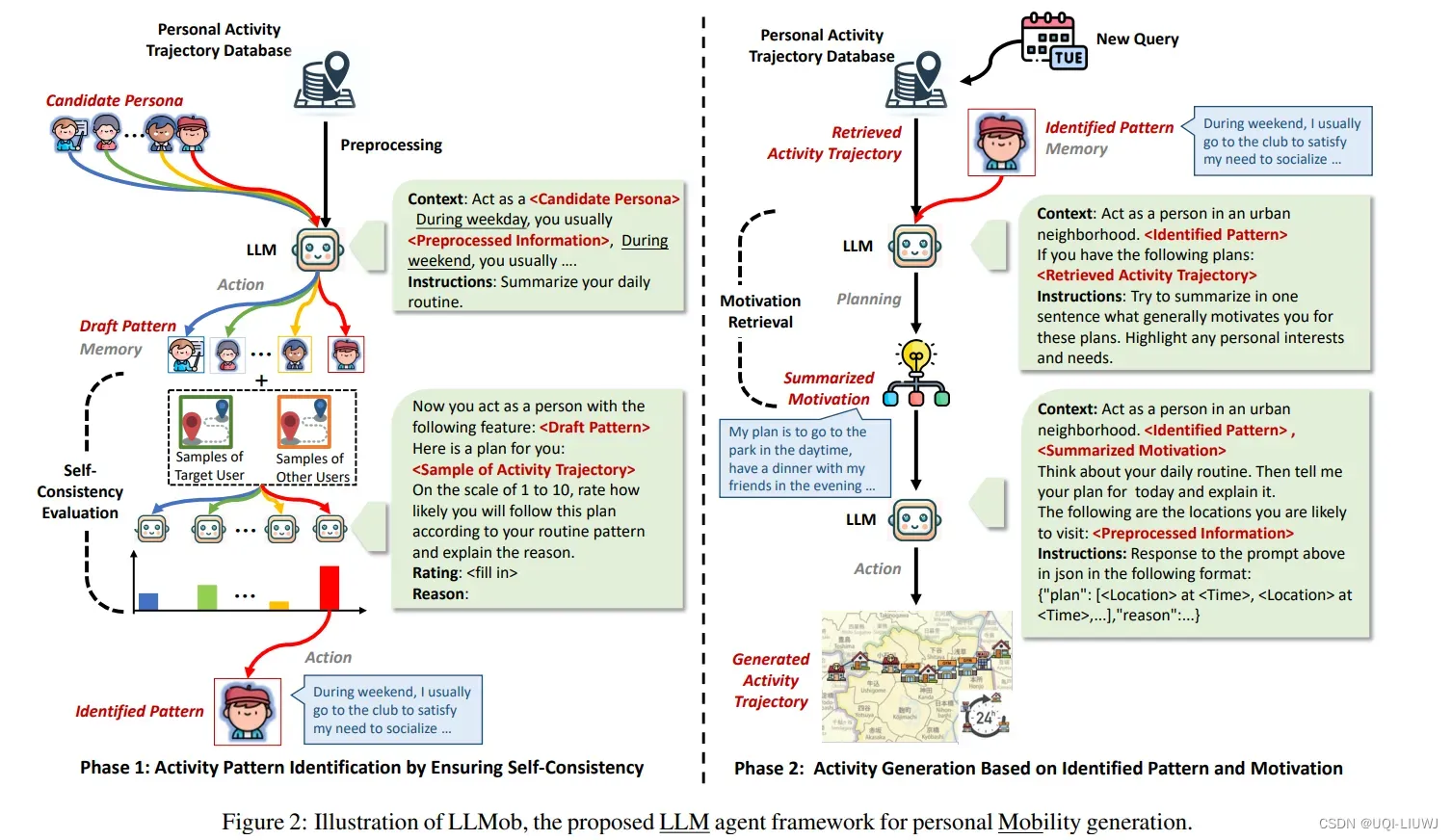
3.0 LLMob的假设
- LLMob基于一个假设,即个体的活动主要受到两个主要因素的影响:
- 习惯性活动模式
- 典型的移动行为和偏好
- 常规的旅行和地点选择
- 当前动机
- 个体在任何给定时刻决策的动态和情境因素
- 捕捉和预测移动性模式的短期变化
- 习惯性活动模式
3.1 LLMob三部分
- 环境
- 环境包含从现实世界数据中收集的信息,代理通过识别习惯性活动模式和生成轨迹来行动
- 记忆
- 需要提示给LLM以引发下一步行动的过去行动
- 在LLMob中,记忆指的是代理输出的活动模式
- 规划
- 制定计划或反思过去的行动以处理复杂任务
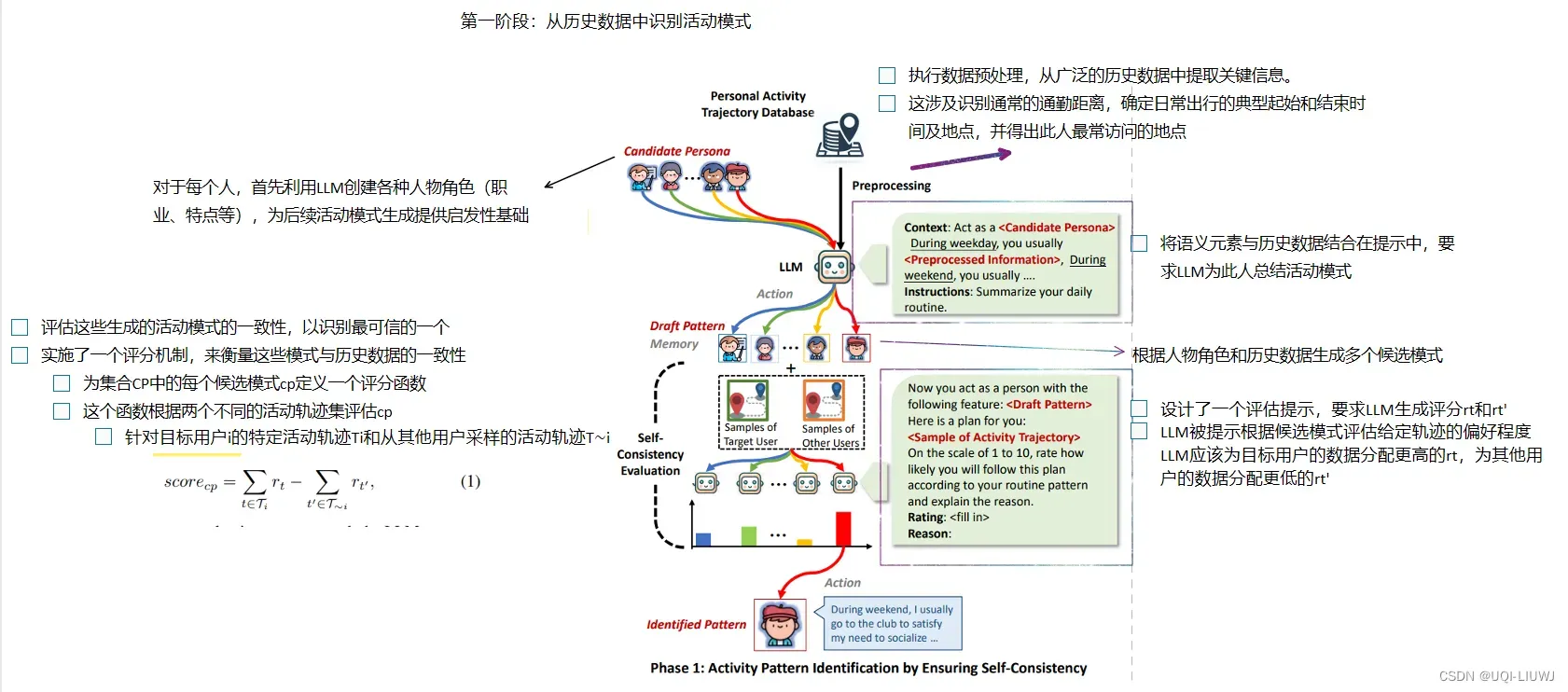
3.2 第一阶段——从历史数据中识别活动模式


3.3 第二阶段——动机的检索 & 动机和活动模式的整合
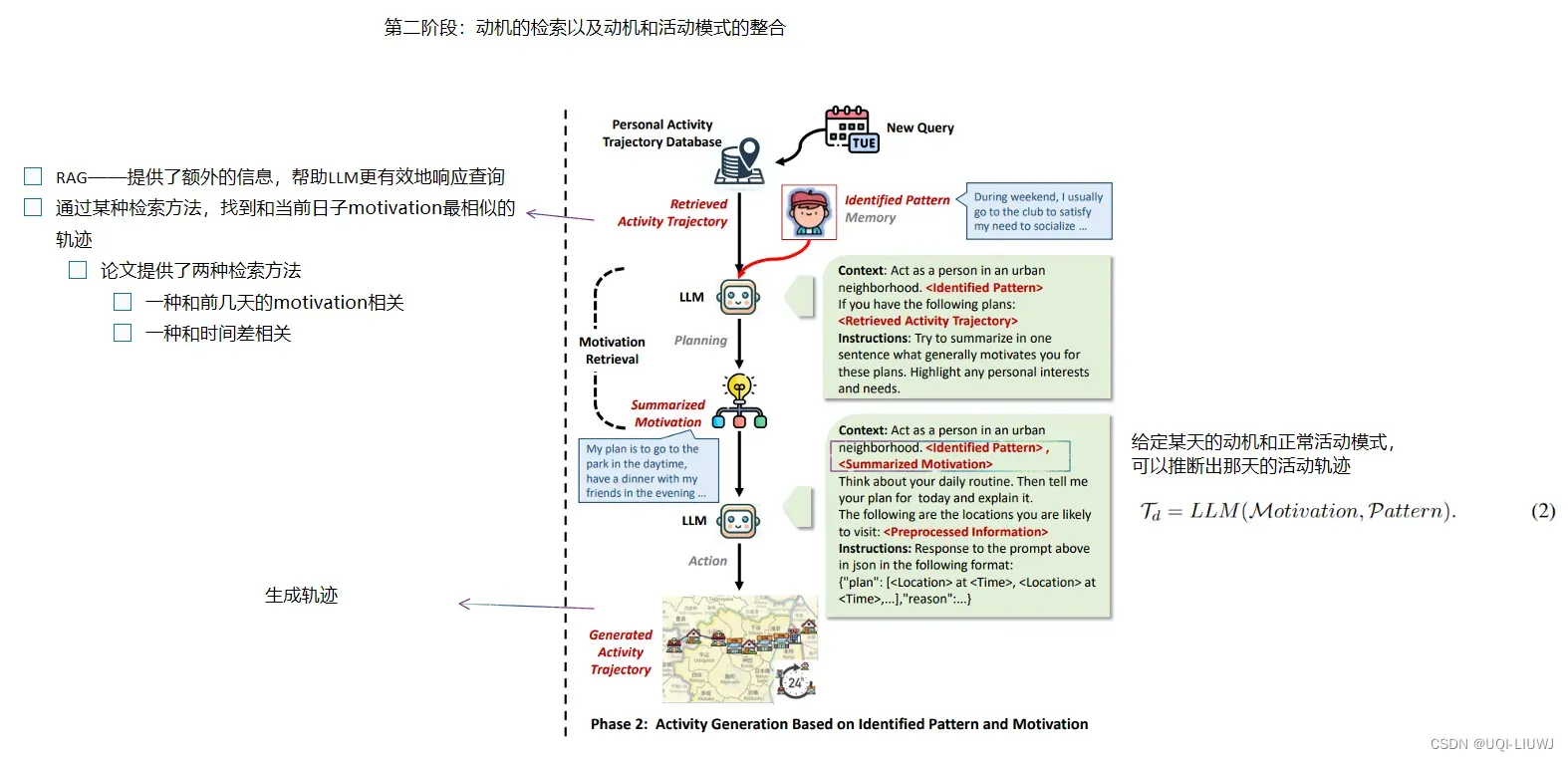

3.4 两种RAG的检索
3.4.1 基于进化的动机检索
- 即个体在任何给定日子的动机受到其在前几天的兴趣和优先级的影响
- 新的动机通常是从现有动机中演化而来
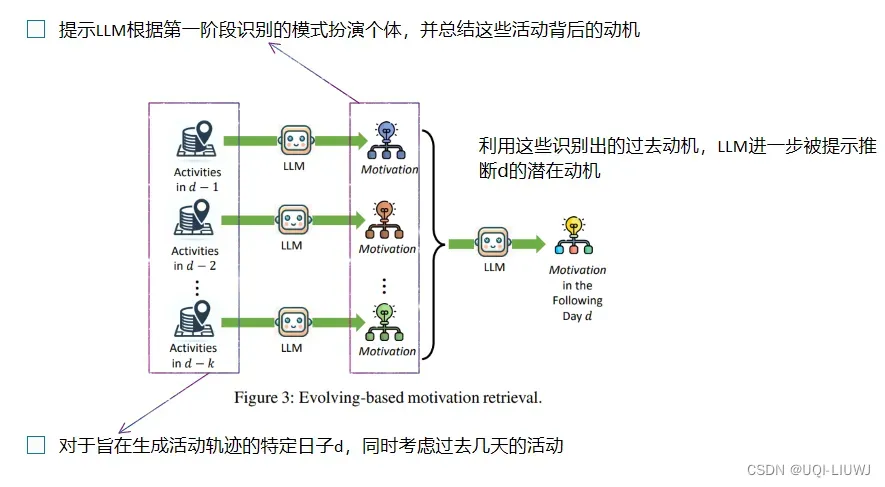

3.4.2 基于学习的动机检索
- 假设个体倾向于在其日常活动中建立例行公事,即使具体地点可能有所不同,但也由一致的动机指导
- 例如,如果有人在工作日的早晨经常访问汉堡店,这种行为可能表明了对快速早餐的动机
- 对于计划活动的每个新日期,唯一可用的信息是日期本身
- 首先制定过去日期dp和当前日期dc之间的相对时间特征
- 这个特征捕获了各种方面,如这两个日期之间的间隔以及它们是否属于同一个月
- 训练一个分数估计器
来评估任意两个日期之间的相似性
- 由于缺乏监督信号,论文采用对比学习来训练fθ
- 对于用户的每个轨迹扫描她的其他轨迹,并根据预定义的相似性分数识别相似(正面)和不相似(负面)的日期
- 对于每个日期d,根据相似性分数生成一个正面对(d, d+)和k个负面对(d, d-1),…,(d, d-k)并计算zd,d+,zd,d-1,…,zd,d-k
- 将正面和负面对输入fθ(·)形成:
- 采用InfoNCE作为对比损失函数:
- 对于用户的每个轨迹扫描她的其他轨迹,并根据预定义的相似性分数识别相似(正面)和不相似(负面)的日期
- 由于缺乏监督信号,论文采用对比学习来训练fθ
- 首先制定过去日期dp和当前日期dc之间的相对时间特征
- ——>能够检索最相似的历史数据,从而让LLM生成那个时期流行的动机摘要
- ——>推断出与查询日期相关的动机,为LLM生成新的活动轨迹提供基础

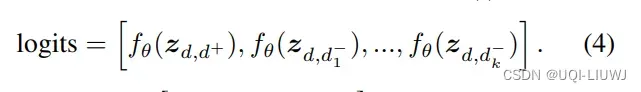
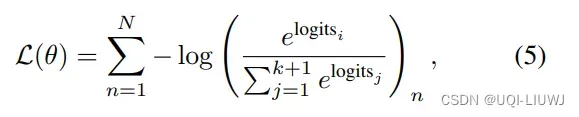
4 实验
4.1 数据集
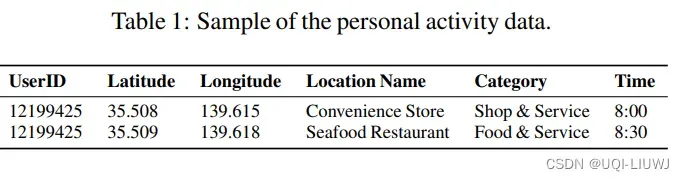
- 在东京的个人活动轨迹数据集上调查并验证LLMob。
- 这个数据集通过Twitter API和Foursquare API获得,覆盖从2019年1月到2022年12月的数据。
- 这个数据集的时间框架富有洞察力,因为它捕捉了COVID-19大流行之前的典型日常生活(即,正常时期)以及大流行期间的变化(即,异常时期)。
- 随机选择了100名用户,根据可用轨迹的数量,以10分钟间隔模拟他们的个人活动轨迹。\
- 利用Foursquare中的类别分类来确定每个地点的活动类别。
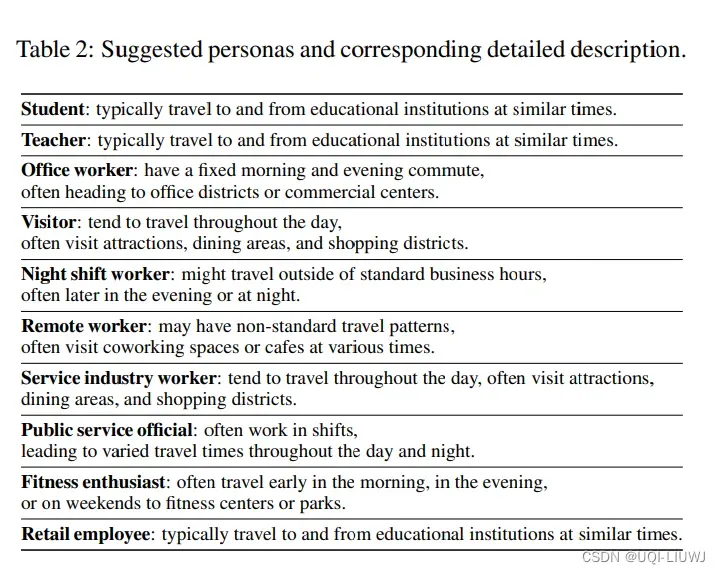
- 使用10个候选人物角色作为后续模式生成的先验
4.2 指标
- 步长距离(SD)——轨迹上两个连续位置之间的距离
- 步长间隔(SI)——轨迹上两个连续位置之间的时间间隔
- ST-ACT——每条轨迹的空间-时间活动分布
- ST-LOC——每条轨迹内访问地点的空间-时间分布,包括地理坐标和时间戳
- 琴声-香农散度(JSD)——量化生成轨迹与实际轨迹之间的差异。较低的JSD更受青睐。
4.3 方法
- 采用GPT-3.5-Turbo-0613作为LLM核心
- 使用“LLMob-L”来表示整合了基于学习的动机检索方案的框架
- 用“LLMob-E”来代表采用基于进化的动机检索方案
- ablation study中的P和M分别是pattern和motivation
4.4 结果
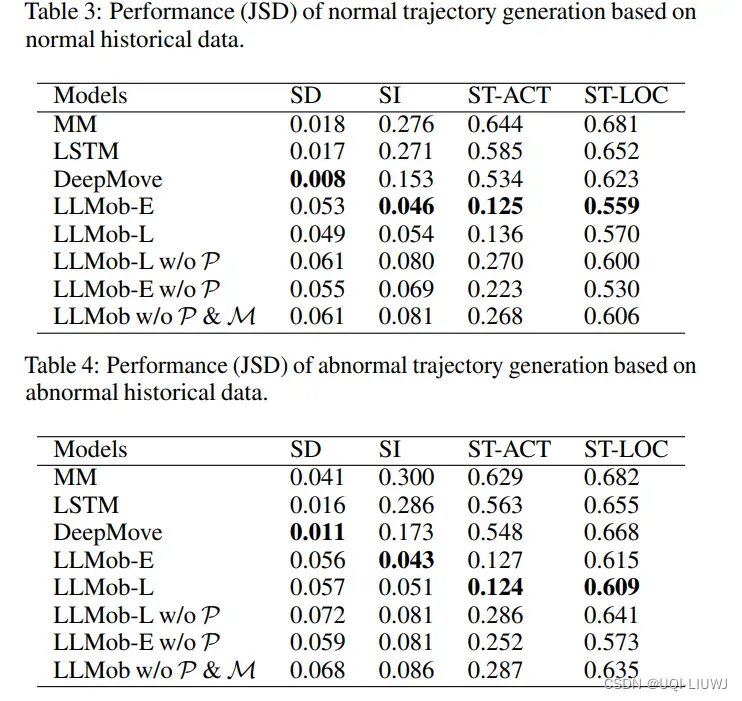
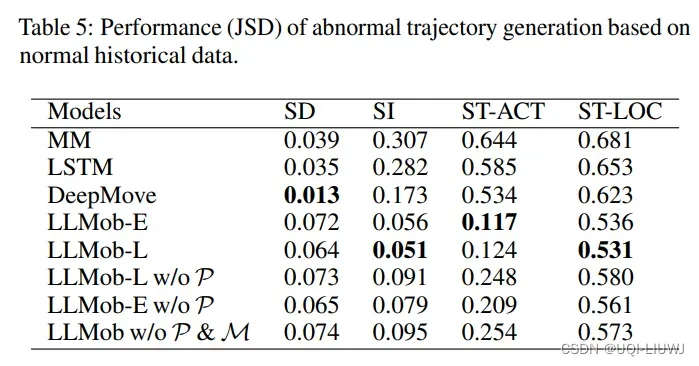
4.4.1 正常情况/非正常情况下生成轨迹的结果比较
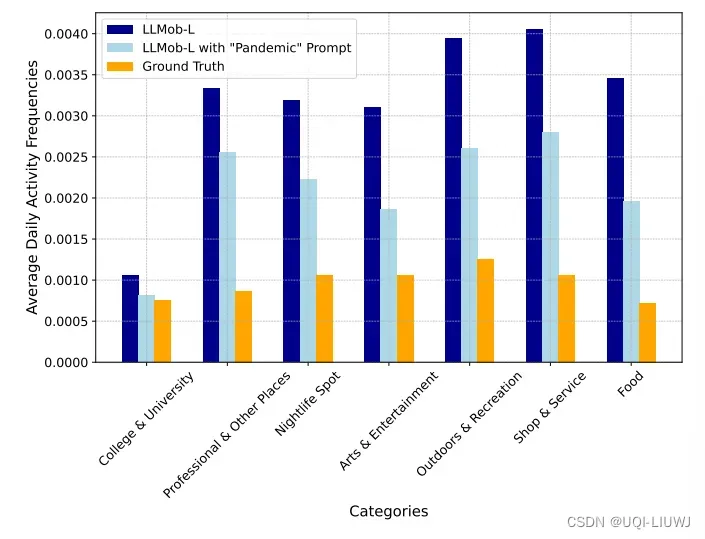
4.4.2 是否带“pandemic” prompt对于结果的影响

版权声明:本文为博主作者:UQI-LIUWJ原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40206371/article/details/136479425