概念:
给定一个输入数据和噪声数据生成目标图像,在pix2pix中判别器的输入是生成图像和源图像,而生成器的输入是源图像和随机噪声(使生成模型具有一定的随机性),pix2pix是通过在生成器的模型层加入Dropout来引入随机噪声,但是其带来输出内容的随机性并没有很大。同时在损失函数的使用上采用的是L1正则而非CGAN使用的L2正则用来使图像更清晰。
条件生成对抗网络为基础,用于图像翻译的通用模型框架。(图像翻译:将一个物体的图像表征转化为该物体的另一个表征,即找到两不同域的对应关系,从而实现图像的跨域转化)
(条件生成对抗网络:相较于传统GAN的生成内容仅由生成器参数和噪音来决定,CGAN中向生成器和判别器添加了一个条件信息y)
模型结构
采用CNN卷积+BN+ReLU的模型结构
2.1生成器
以U-Net作为基础结构增加跳跃连接(下降通道256->64)压缩路径中每次为4*4的same卷积+BN+ReLU,根据是否降采样来控制卷积的步长。同时压缩路径和扩张路径使用的是拼接操作进行特征融合。
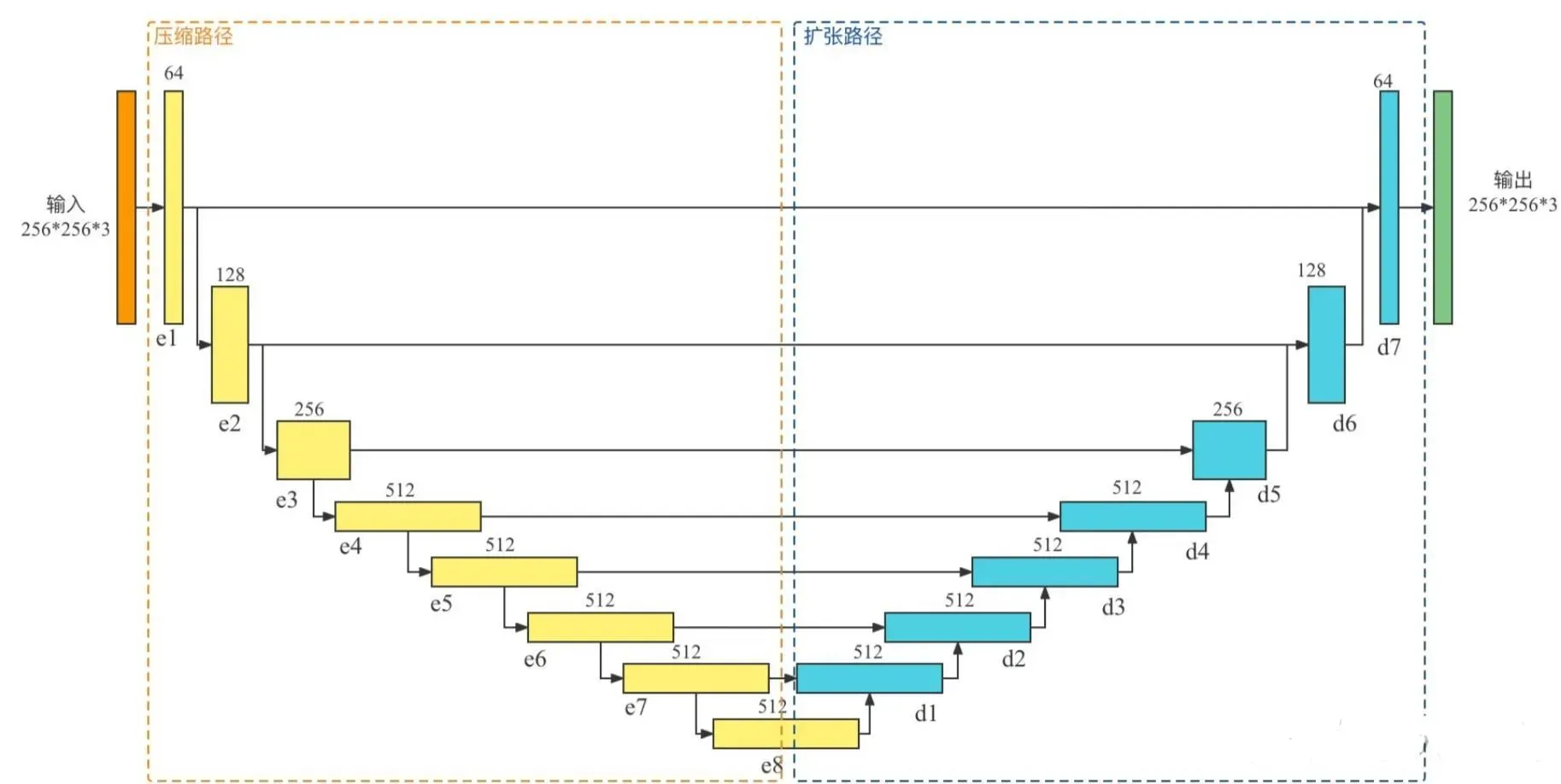
2.2判别器(PatchGAN)
传统GAN生成图像比较模糊(由于采用整图作为判别输入,pix2pix则分成N*N的Patch【大概将256的图N=7效果最好,但是N越大生成的图像质量越高1*1的被称为PixelGAN,不过一般自己调整感受野选择参数】)
缺点
训练需要大量的成对的图片集
文章出处登录后可见!
已经登录?立即刷新