文章目录
认识强化学习
- 一般我们知道 Machine learning 一般指的是传统方法(贝叶斯,决策树,逻辑回归等)模型来实现一些数据分析或者分类的任务,而深度学习则是基于深度神经网络发展出来的一系列更加强大的模型,这些模型根据功能可以分为 CNN,RNN, Transformer 等,他们往往基于大量的数据集来拟合数据的分布,从而获得非常强大的视觉或者语言能力。
- 无论是机器学习还是深度学习,都基于
Supervised learning或者Unsupervised learning又或者self-supervised learning来进行训练模型。 - 但 Reinforcement learning 则既不是监督学习也不是无监督学习,而是一种特殊的学习方式。而区别于 ML 和 DL 中常用的
label-based+ 梯度下降的训练方式。RL 倾向于一种全新的训练策略。 - 下面来看一下 RL 的核心思想:
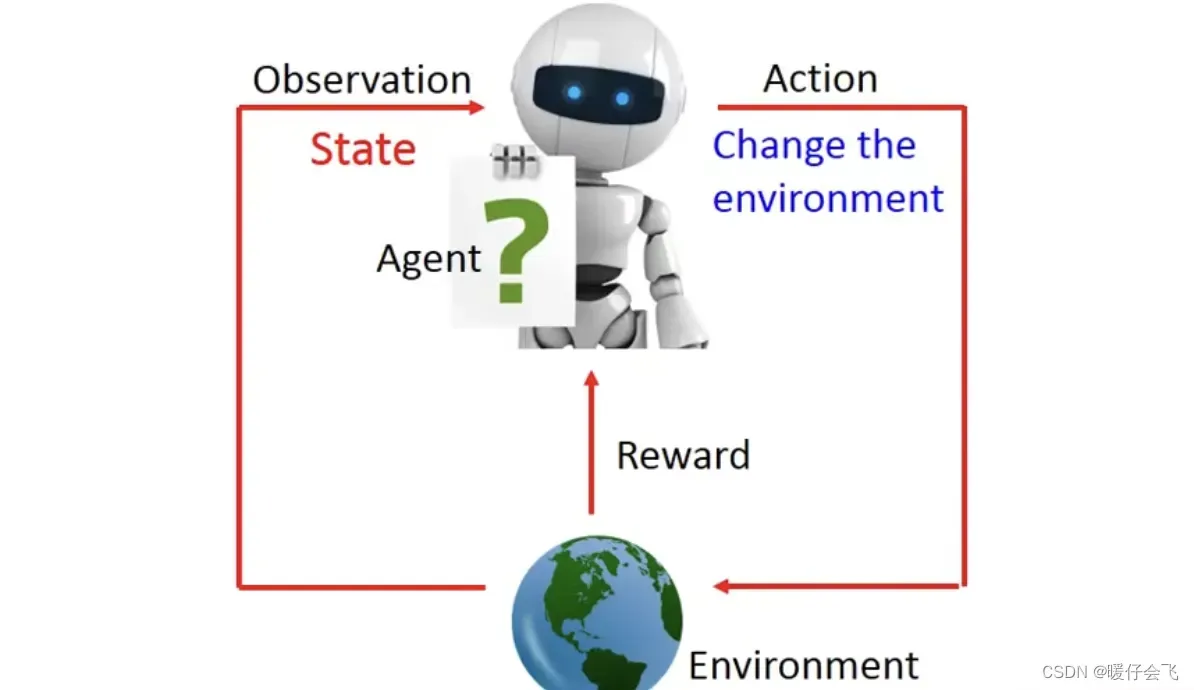
- RL 的核心构件包括:
- Agent:代理
- Environment:环境
- Agent 可以通过观察环境的状态(state)采取一个动作(action)
- 这个 action 会改变环境,从而使 agent 获得 reward 或者 penalty,从而 agent 可以不断地接收到来自环境的反馈来改进自己的行为。
- 而 RL 的目的就是学习一个 actor 函数,这个函数输入就是 environment 当前的 state,输出就是 agent 根据这个状态而采取的 action. 而这个学习的过程则是依靠 reward 进行的。理论上如果模型学的够好,actor 函数足够强大,那么 agent 根据环境可以做最正确的决策。
Sparse Reward
-
在下面的描述中,会使用以下缩写:
environment->eenvironment state->esaction->aReinforcement learning->RL
-
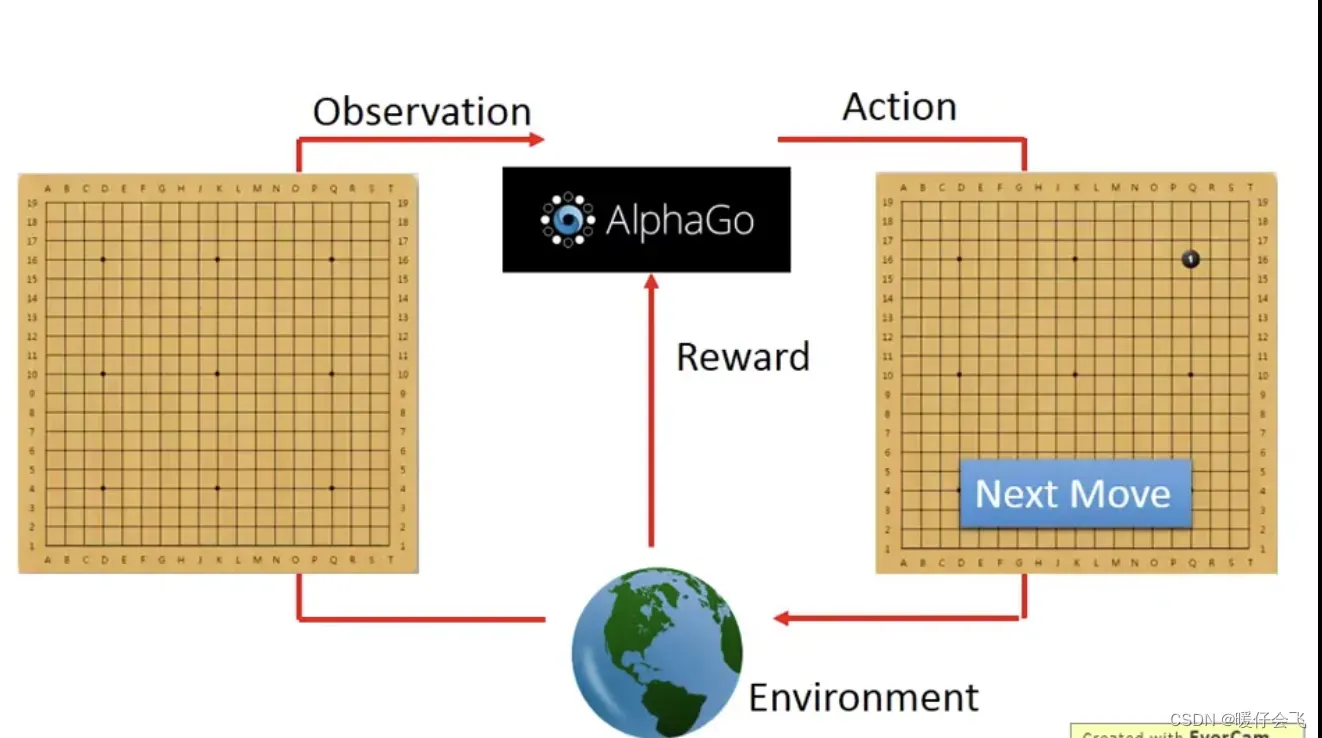
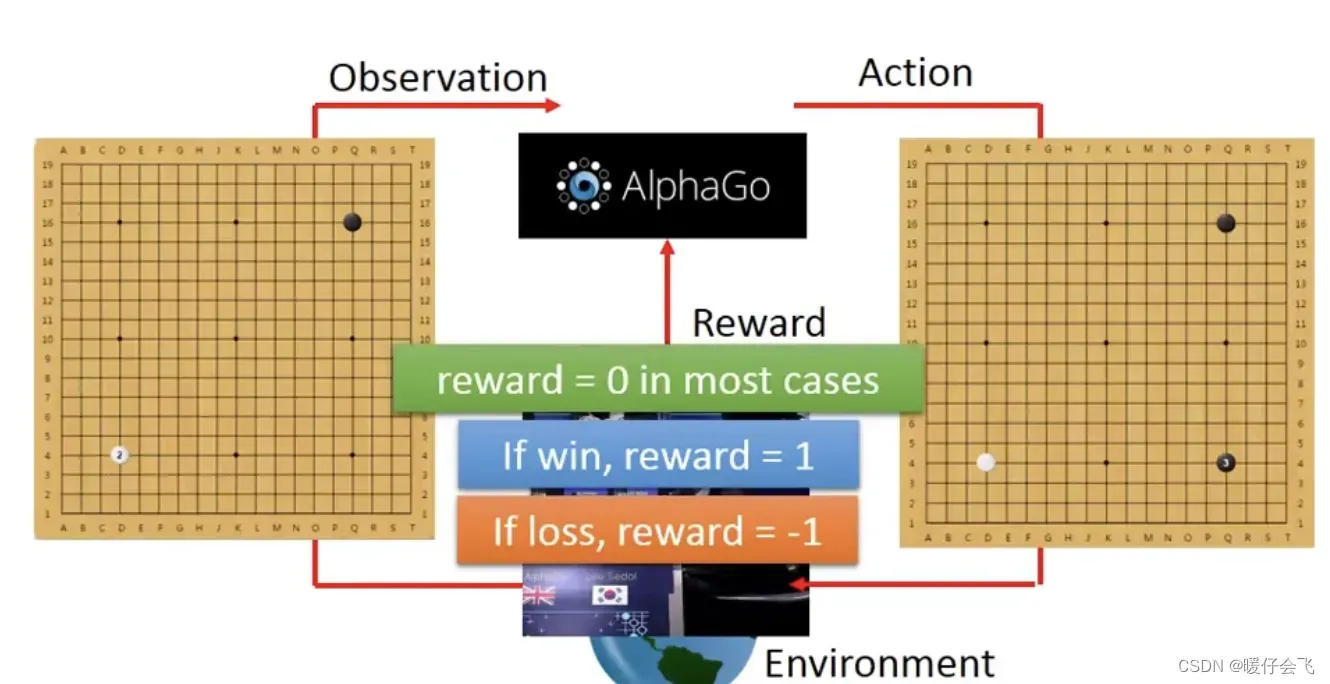
比如 alphaGo,在
时刻的 alphago 看到的
es是一个空棋盘,所以他选择a是下载某个地方一颗棋子
-
这个时候,对手就是
e,他会有所行动,也就是es发生改变:棋盘上多了一颗对方的白子
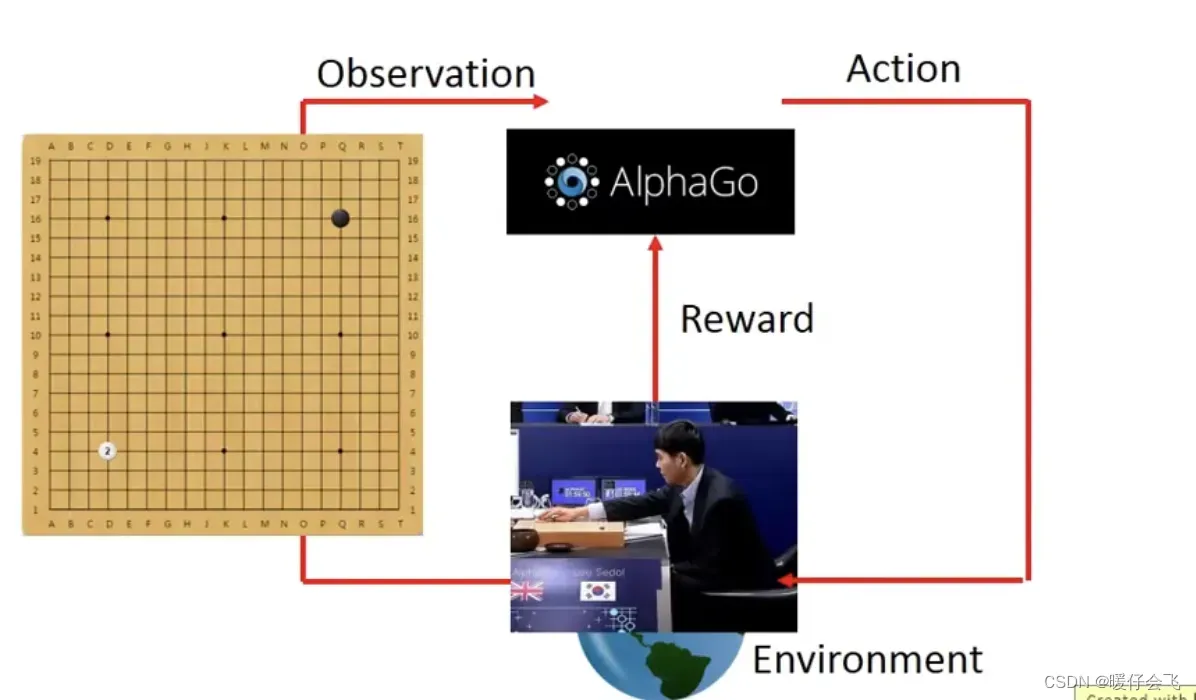
-
于是 alphago 根据当前的
es再采取新的a:下在另一个位置黑子
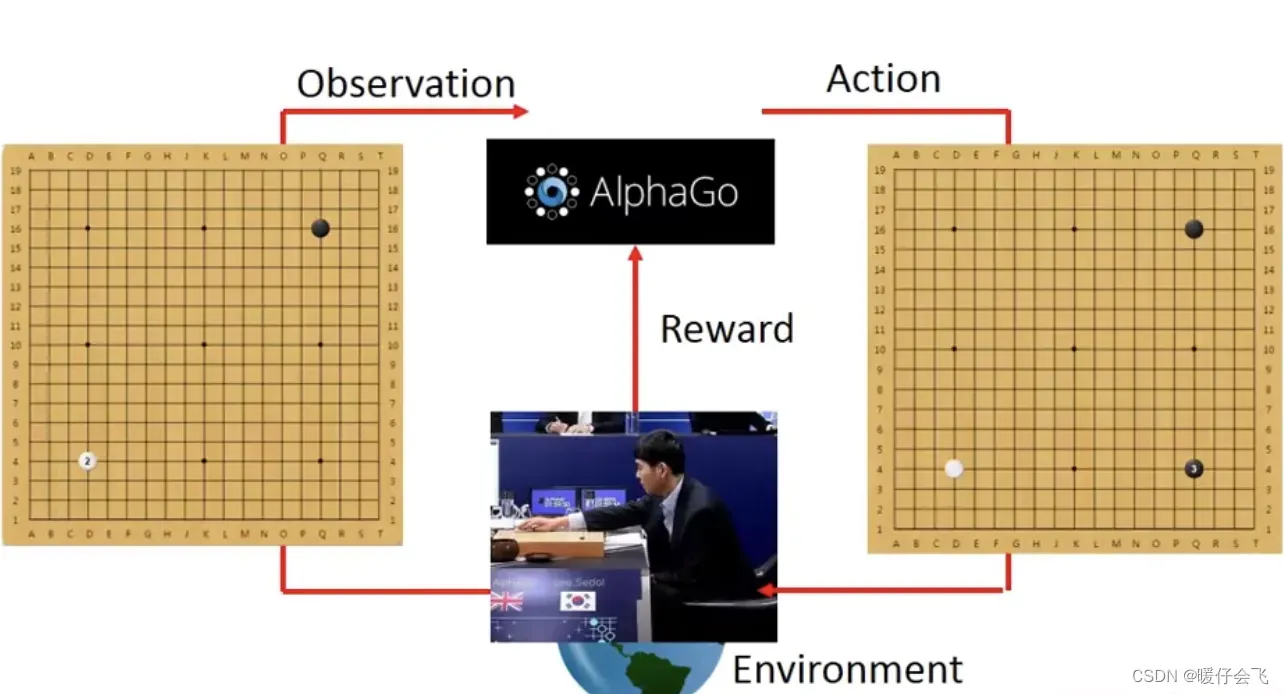
-
但是下棋这个任务非常特殊,因为如果我们把
对弈胜利的 reward=1,而对弈失败的 reward=-1 那么就会发现,只有在这个棋局的最后一个a之后才会产生 reward,其他步骤模型都没有得到任何的反馈,那么这个就非常不好,因为我们知道在我们熟知的一些监督任务中,每个 step 或者 epoch,模型都会根据当前的 loss 做梯度下降来更新参数。但是如果下棋只有最后一个步骤有 reward,那模型很难学到东西。这种困难的问题叫做sparse reward(稀疏奖励) 。这种问题在 RL 中是经常出现的。
Supervised Learning v.s. RL
- 对于监督学习来解决这个下棋问题的话,往往会采用下面的方式:

- 即,给定一个局面,然后给出下一步的正确落子方式作为
label - 但是,这种方式的问题是:下棋这种决策性的游戏根据同样的环境是没有正确答案的。比如都是同一个棋局,高手可能会故意让对方吃掉自己一部分子来换得更大的胜利,所以死板地给定下一个落子位置的方式来训练模型是很死板的
- RL 则是通过让模型和不同的 对手(
e)进行下棋,然后根据大量的训练来获得真正的下棋能力,面对不同的对手都可以随机应变。 - 在下面的文章中,会介绍 RL 为什么可以随机应变(因为 RL 中存在大量的随机性操作,这也是为什么 RL 的训练不太容易收敛,而且非常耗时)
- alphago 的训练方式是
supervised learning + RL也就是先通过监督学习获得一个能力还行但很死板的初代版本,然后让两个 alphago 互相采用 RL 的方式进行对弈(3000万盘)
- 即,给定一个局面,然后给出下一步的正确落子方式作为
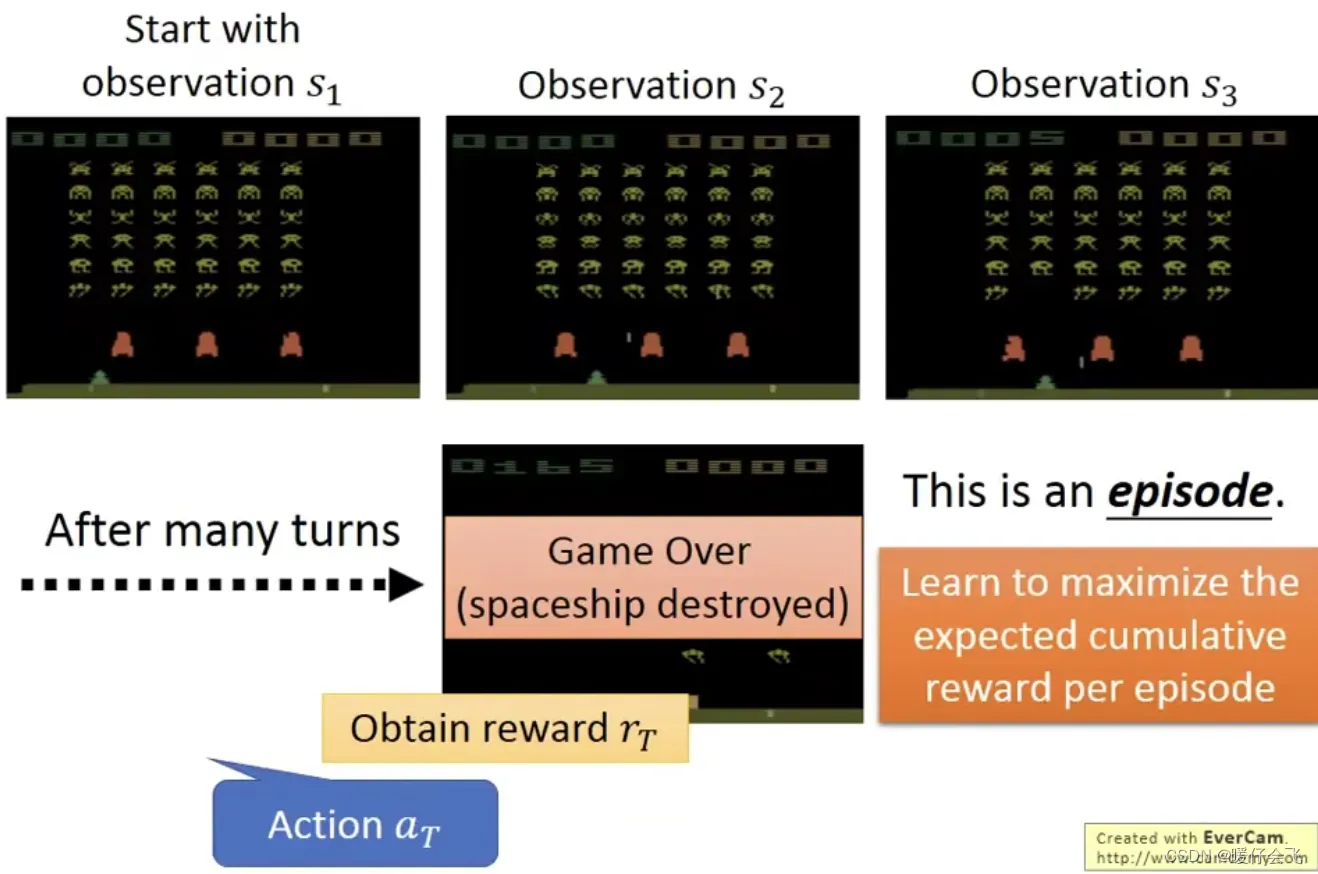
RL 玩游戏
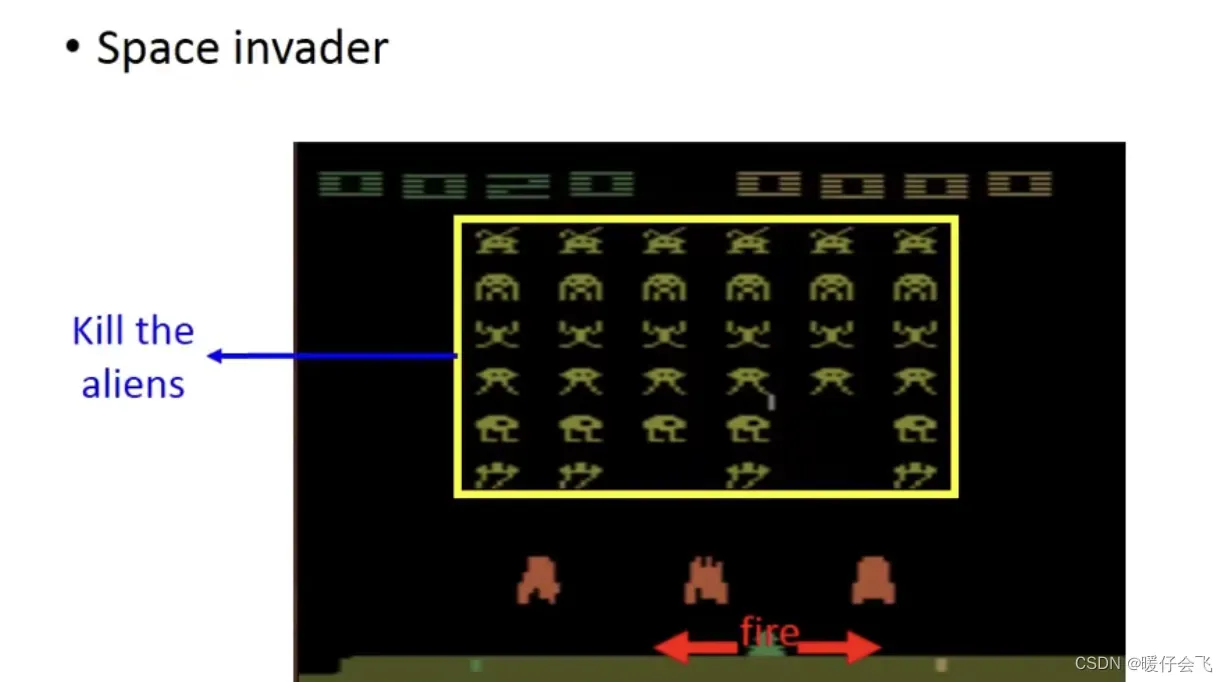
-
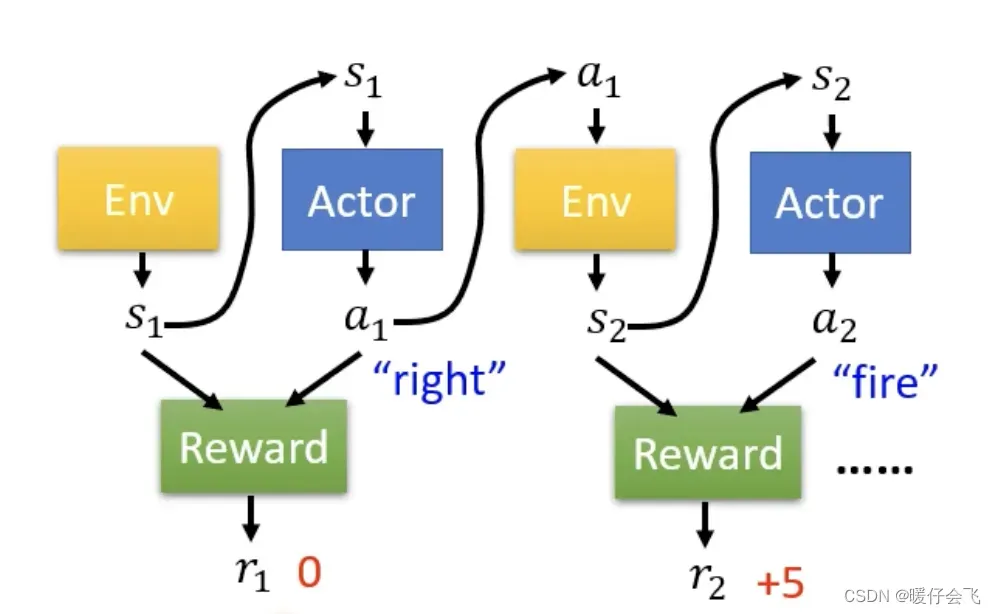
在这个游戏中, RL 负责操控最下面这个绿色的东西,他可以有三种操作
left, right, fire他的任务是负责杀死这些alien杀掉这些alien可以获得reward
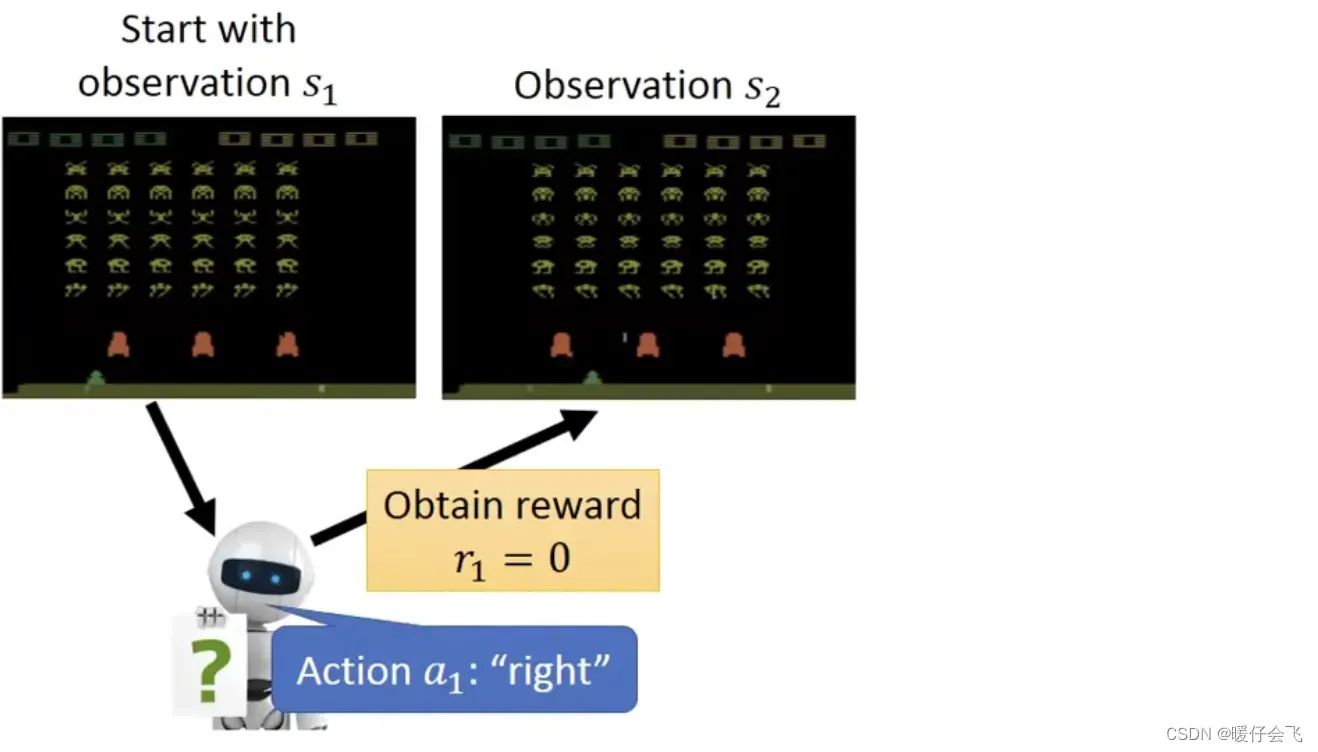
-
最开始的时候的
es是(
es也叫 observation),根据这个画面,agent 采取的动作是向右移动,因此这个步骤的
reward=0
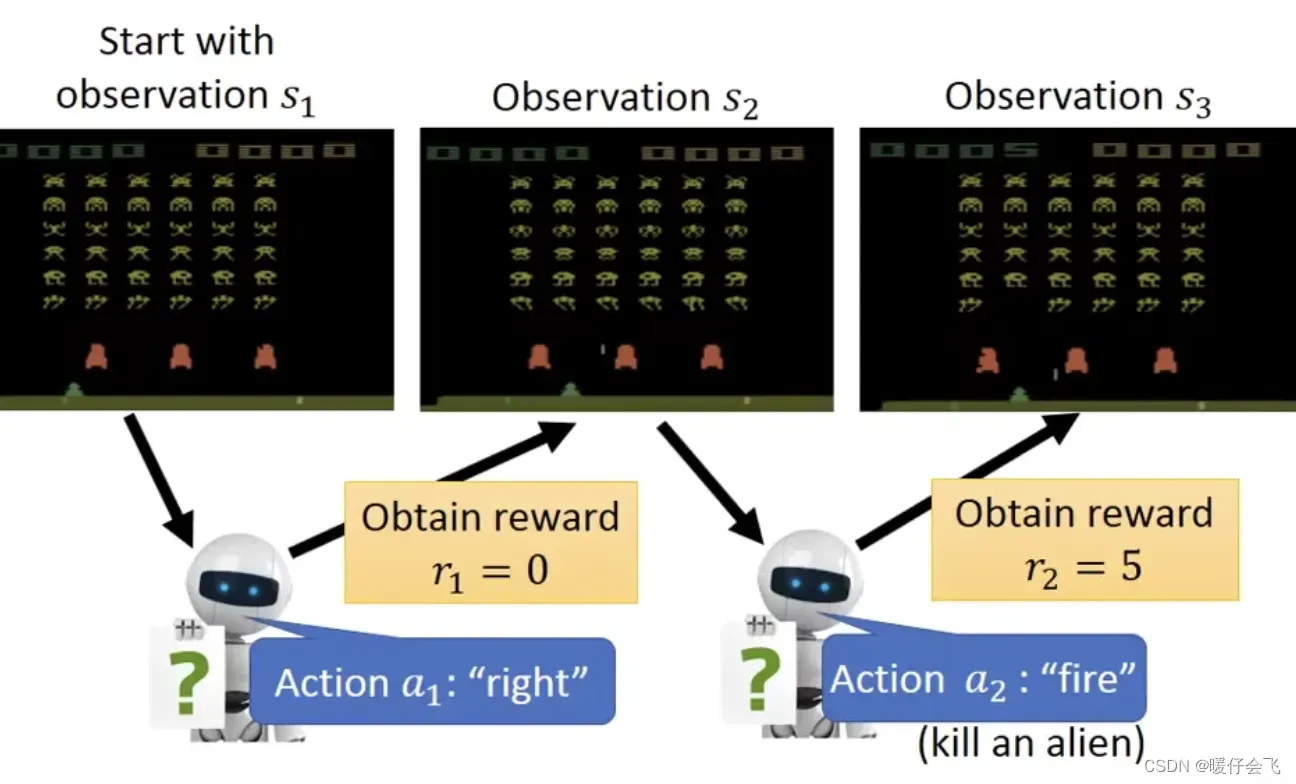
-
然后在
的时候,agent 选择
fire并且成功射杀一个 alien,从而获得了reward=5的收益
-
经过了多个回合之后,最终 agent 采取了
获得了
reward为然后游戏就结束了。
-
这一局游戏称为一个
episode,整个episode过程获得的reward的总和是我们希望 maximize 的。
-
从这个过程中我们可以总结出 RL 的难点在于:
- reward delay:左右移动不会直接产生 reward,但是移到了正确的位置开火可以得到 reward,但是这个 reward 是滞后于左右移动这个行为的。因此如果模型只是根据 reward 来学习 action 的话,很有可能就是一直站在原地开火
- agent 的行为可能产生一些类的后续影响,也就是我们希望模型具有探索精神。比如如果模型觉得 fire 可以得到 reward 而一直 fire 但是却不进行任何的左右移动,那么这个模型就不具备 explore 的能力,结果也就不会太好
Policy-based & Value-based
-
RL 的模型分成两个主要的分支:基于 policy 的方法和 基于 value 的方法;但是当前表现效果最好的 A3C 是将 value 和 policy 结合起来
-
而 critic 的方式则是充当一个 批评者,通过不断纠正 agent 的行为来获得更好的结果
Policy-based
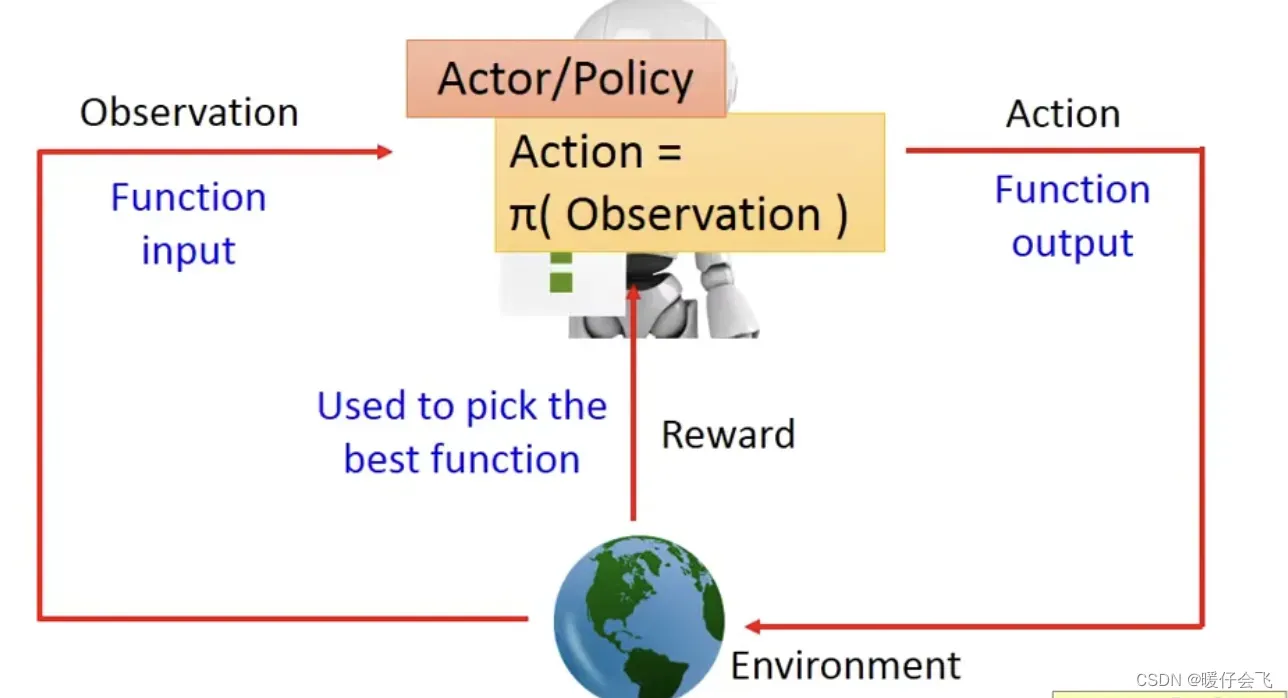
- 基于策略的方法本质上是训练一个
actor函数(也可以表示成),这个函数可以根据
es(observation)输出一个最有效的a帮助 agent 获得最大的收益;actor函数在很多地方也叫做policy
训练模型的三步骤
- 任何深度学习 / 机器学习 / 强化学习 都可以分成三个步骤:
- 定义一个目标函数
- 判断这个目标函数是否足够好
- 将目标函数优化
定义目标函数
- 第一步:定义一个函数:这里的
actor就是这个函数
衡量目标函数的好坏
- 第二步:判断这个目标函数的好坏
- 先看一下在普通的 supervised learning 中的判定一个目标函数好坏的方式:
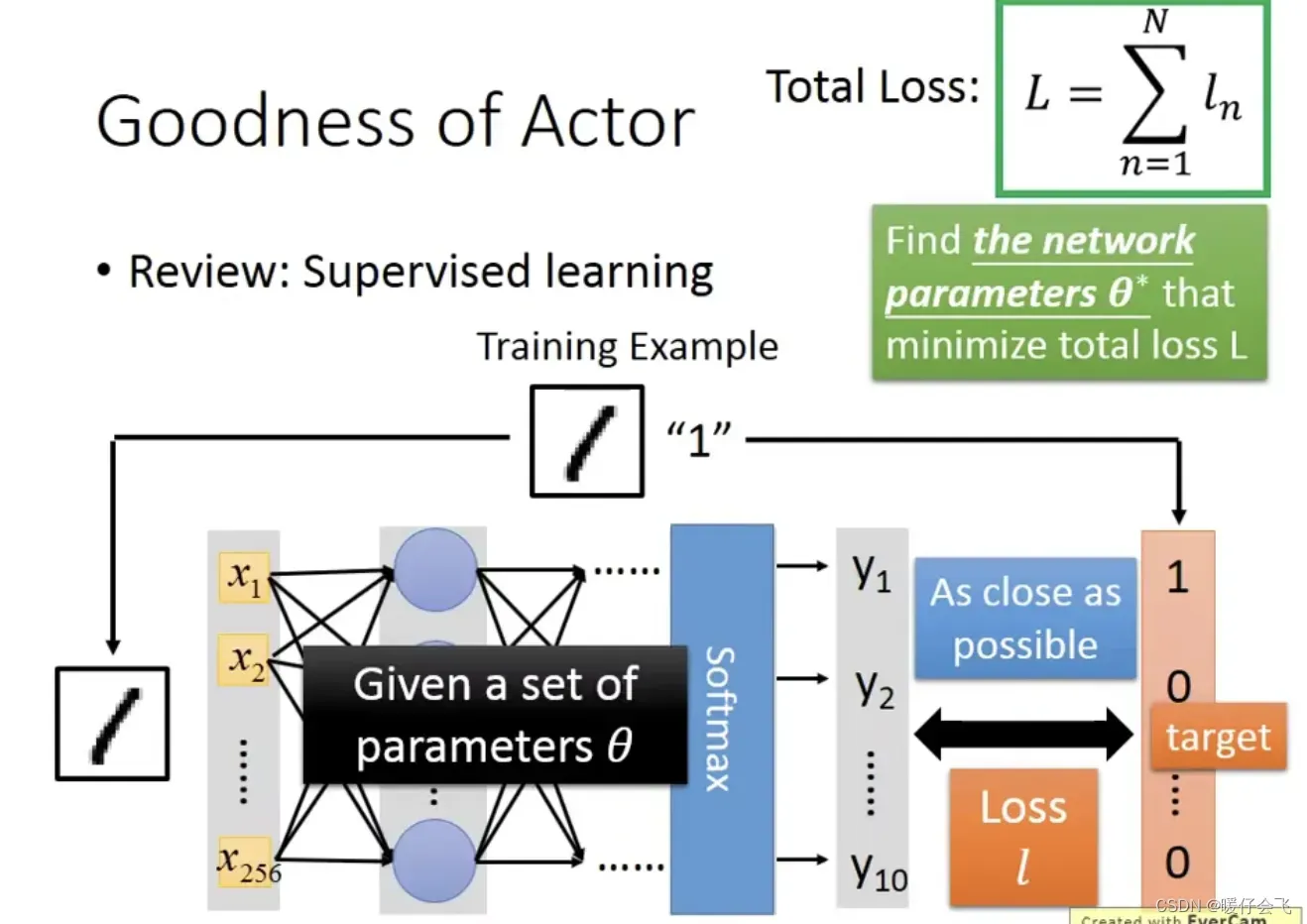
- 这个目标函数的参数我们用
表示,当一个 sample 经过目标函数得到的预测结果
predicted_label如果他和groundtruth的差距足够小,即loss(predicted_label, groundtruth)足够小,那么我们认为这个目标函数是好的 - 在 RL 中这个过程也是类似的
- 先看一下在普通的 supervised learning 中的判定一个目标函数好坏的方式:
RL 的目标函数的好坏(reward 总和的期望)

- 对于一个目标函数
和某个时刻的
observation,采取的
action可以表示为 - 而这个
造成的收益
reward表示为 - 如果在经过一整个
episode的游戏之后,整个过程的reward的总和可以表示为 - 如果
非常大,那么我们就可以认为当前的
- 但是我们在上面讨论过,当一个
输入
的分布表明
left, right, fire三种行为的概率分别为0.7,0.2,0.1那么第一次的结果可能是left这个action,但是第二次有可能是right因为虽然right的概率比left小,但是也是有概率发生的。这也就产生了一个问题,就是一次的也就是
- 因此我们的优化目标是最大化
loss值,看做是然后最小化
loss就可以得到我们想要的解。
如何求得
- 将一个
episode的过程看成一个trajectory,其中
- 如果使用一个
actor函数因为这个
- 因此我们可以表示当前
episode的reward的期望为:
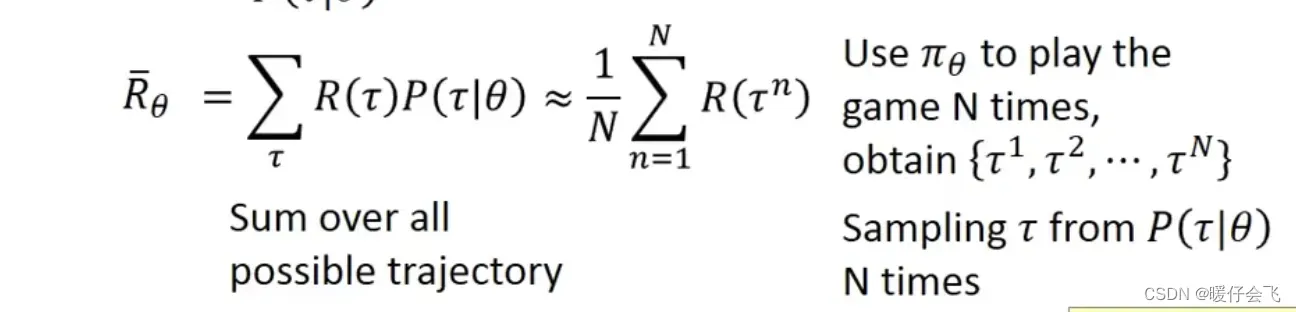
- 又因为
agent在actor函数参数不变的情况下(使用同一个次游戏,
这个过程相当于从概率分布为
- 所以上图中左边的求和公式可以近似于右边的求和公式,所以我们将使用如下公式来计算出一个
episode的reward期望值,从而衡量当前的目标函数的好坏
优化目标函数

-
因为我们要最大化
gradient asent的方法,当然也可以取负号,然后用gradient descent进行优化,都是一样的。

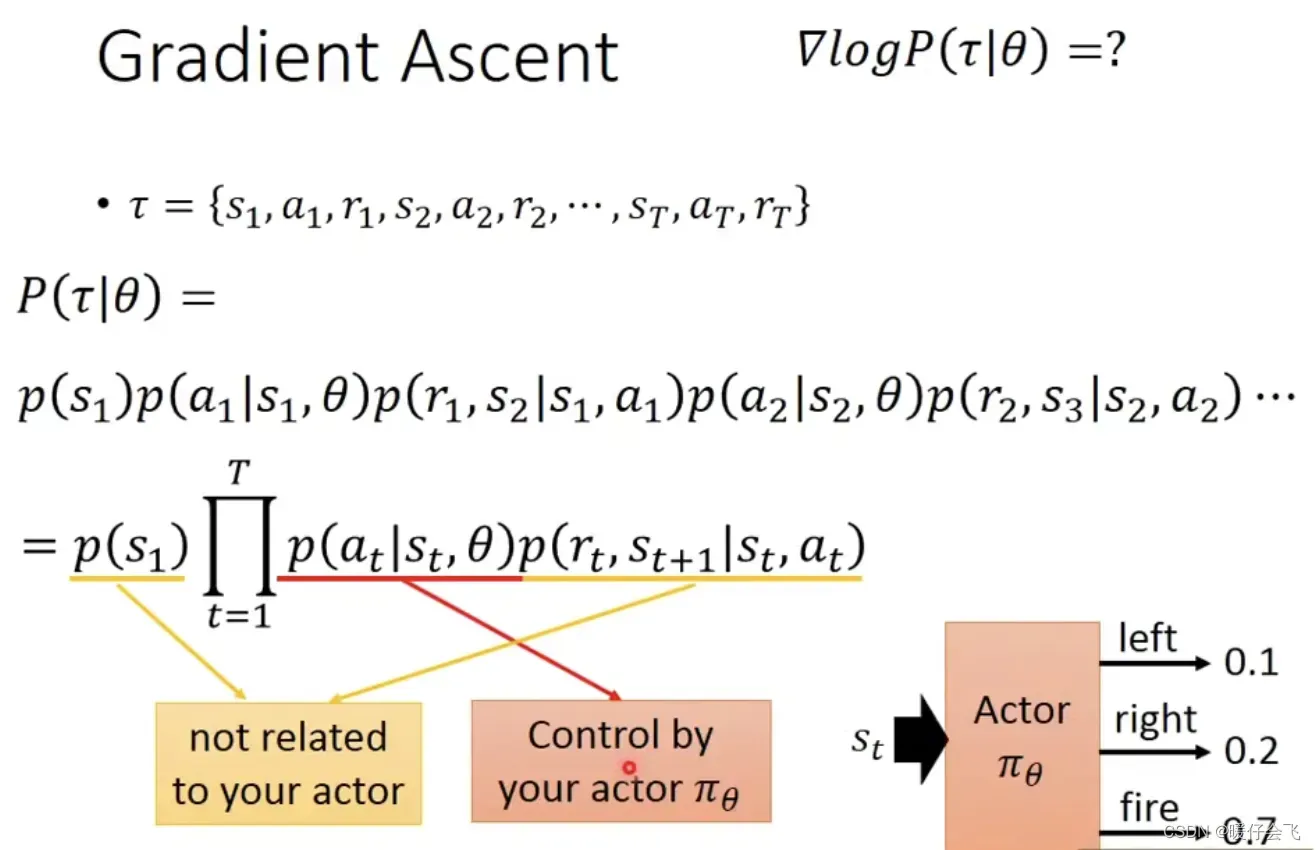
- 对于上面的公式,我们可以知道因为
与 目标函数的参数
- 根据
的微分法则,我们可以最终将公式化简成红框所在的那一行
- 然后根据我们上面近似的结果进行替换,可以得到最后一行的结果
- 又因为
- 因为
而
都有关,因此第二项是
同样的,后面的概率都是这么写出来的
- 经过最终的化简之后可以看到,只有
与

- 再化简,
运算无非是把连乘变成连加运算,然后将与
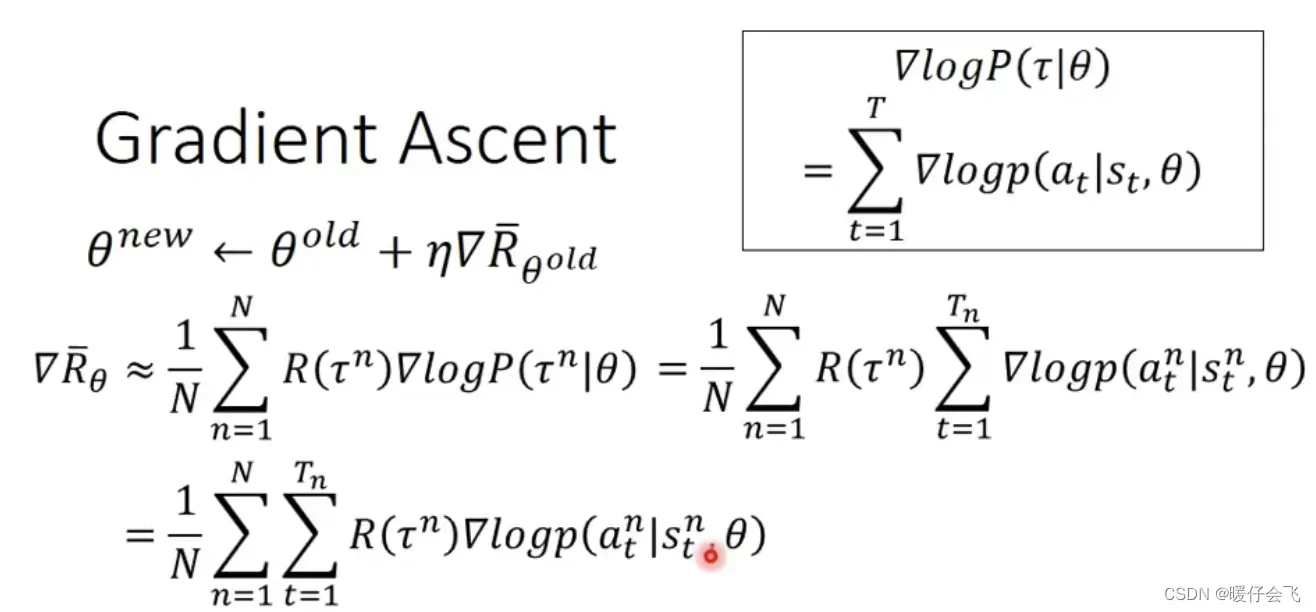
- 对于上面的公式,我们可以知道因为
-
从这个式子看,
代表的是整个 目标函数的优化方向,而根据最终的式子来看,这个公式非常直觉,因为如果把公式里面只保留最重要的部分,也就是:
-
当使用
actor函数时,当面对这个
environment state,此时如果那我们希望调整参数
的概率越大越好,当
则希望面对
时,减小
的概率。
-
可能理解起来稍微有些绕,好好想想,其实这个结论非常符合常识和直觉
-
但是这个式子仍然存在一个小问题,就是
有可能全都是正数,这可能造成一部分问题就是所有的行为
-
为了解决这个问题,人们让

-
至于这个
是怎么算出来的,我们后面再说。
Policy-based RL 的一点补充
- 参考视频:李宏毅 强化学习 (Reinforcement Learning, RL) 2021
- 我们根据上面的知识,我们试图最优化一个
episode的总的reward值。这种做法其实可以看做是 version 0 ,但这种做法存在很大的问题,下面的内容就是不同的 version 存在的问题以及如何通过下一个 version 进行修正。
Version 0
- 为了简化,我们还是用以下缩略符号来表示对应的含义:
environment->eenvironment state->esaction->aReinforcement learning->RL
- 从第一个环境状态
actor函数得到(第一个
action对应的reward),然后以此递推下去,直到这个episode结束,那么所有的reward的总和就是
- 这种做法的问题是:只有那些为
reward增大贡献的会被越来越重视。就像上图中
right这个行为本身不产生reward,fire产生reward所以如果按照version 0这个 agent 就会一直选择开火,而不移动,但我们都知道移动对于fire来说是很重要的。所以这种优化目标会让模型变得短视
Version 1
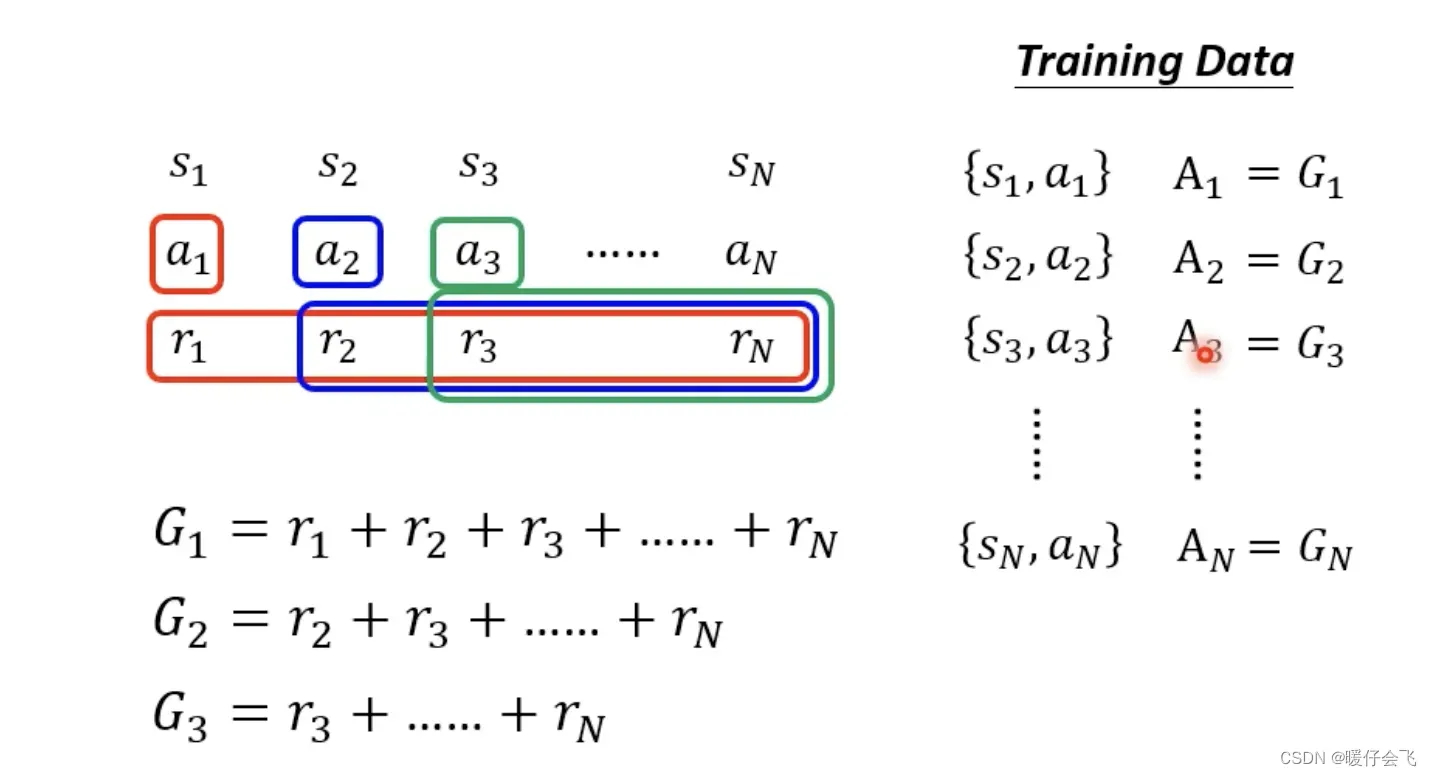
- 将从
reward相加得到reward来代替
version 0当中的 - 这样做的好处是,后面的成功也会归因到前面的步骤,从而避免优化目标函数的时候忽略了这些自身
reward比较低的action - 所以这时候的优化目标就变成了
- 但是
version 1仍然也存在问题:当整个episode步骤过于长的时候,将第reward归功于version 2采取了discount factor
Version 2
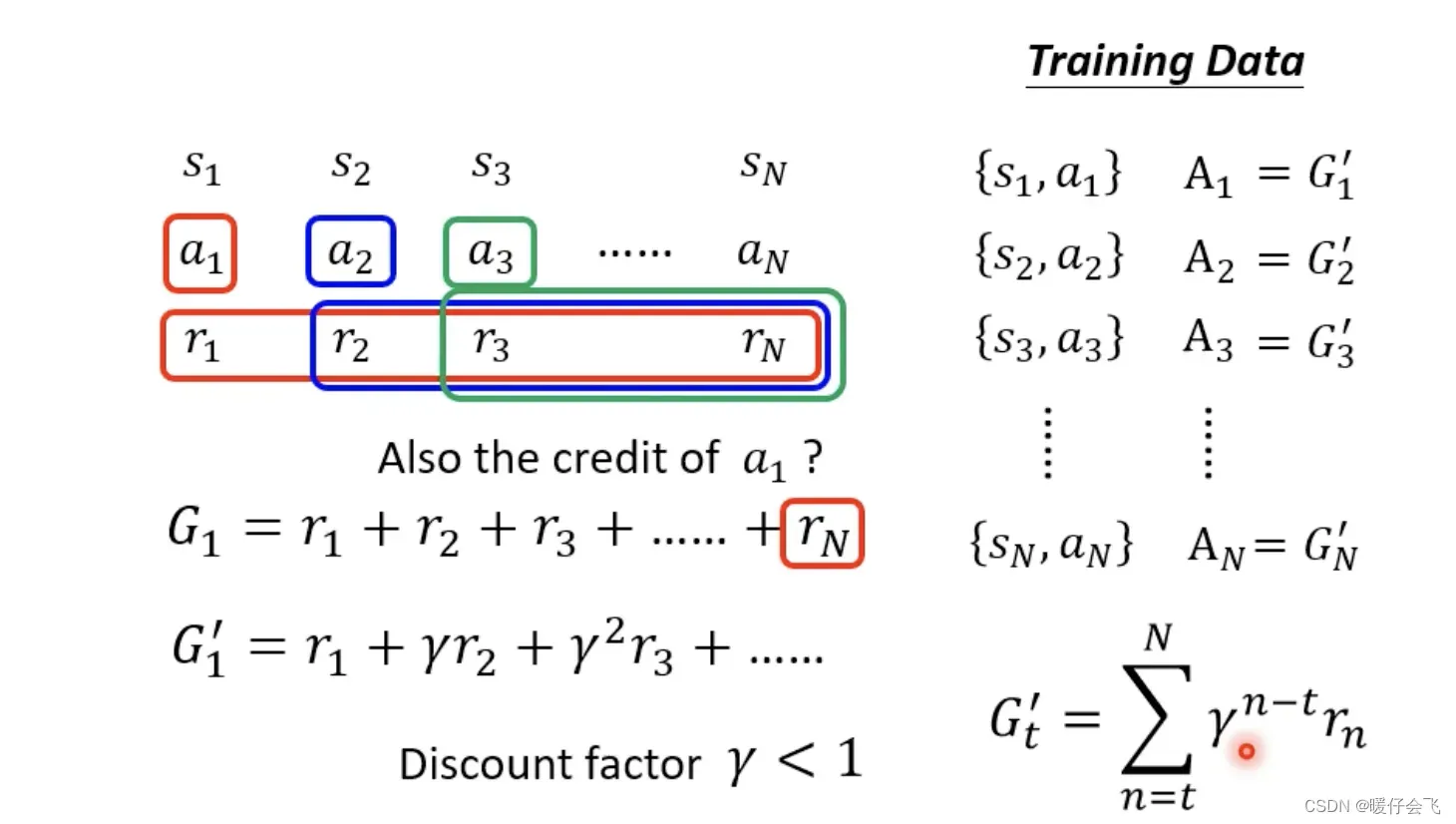
- 保留
version 1的主要思想,但是在计算的时候,对于前面的
action的reward都乘一个衰减系数,就是说:我承认前面步骤的影响,但是离我越远的
action对我的影响应该越小 - 按照这种思路,可以生成
,优化目标也就变成了:
插入一个小问题:
虽然现在的目标函数被定义的越来越完善,但是对于围棋这种只有最后才有reward而中间没有reward的操作,看起来还是束手无策啊。
- 但其实如果按照上面的目标函数去解决下围棋的这种情景,那么假设最后下棋赢了,那么就会认为所有的步骤都是
postive的,有效的,而如果输了,那么所有的步骤都是negative的- 虽然这看起来好像很离谱,但是初代的 alphago 就是这么训练的。
- 因为并不是一盘棋,是下几千万局,这个过程中有赢有输,每个
action的reward会调整很多次,所以虽然很难 train 但是还是可以 train 出来
Version 3
version 3是对version 2进一步优化,优化的方式是将每一项的变成
这个我们在上面提过。因为有些场景下,如果所有的
标准化- 如何设置
如何设置
Policy Gradient

- 首先初始化参数
- 然后按照
epoch进行循环 (),每个
epoch中执行:- 使用上一个
epoch的actor函数(参数表示为)
- 将
的数据输入
actor得到 - 接着计算出每个
action对应的reward - 根据这些
reward得到损失函数(或者优化目标) - 采用梯度下降或梯度上升来优化目标函数的参数
- 使用上一个
- 但是非常神奇的是,我们之前接触的一些项目,都是把数据在
epoch之外先整理好,但是RL训练过程中数据的收集是在epoch内部完成的,那为什么收集一次数据只能用于一个epoch迭代,而不能一直用呢?
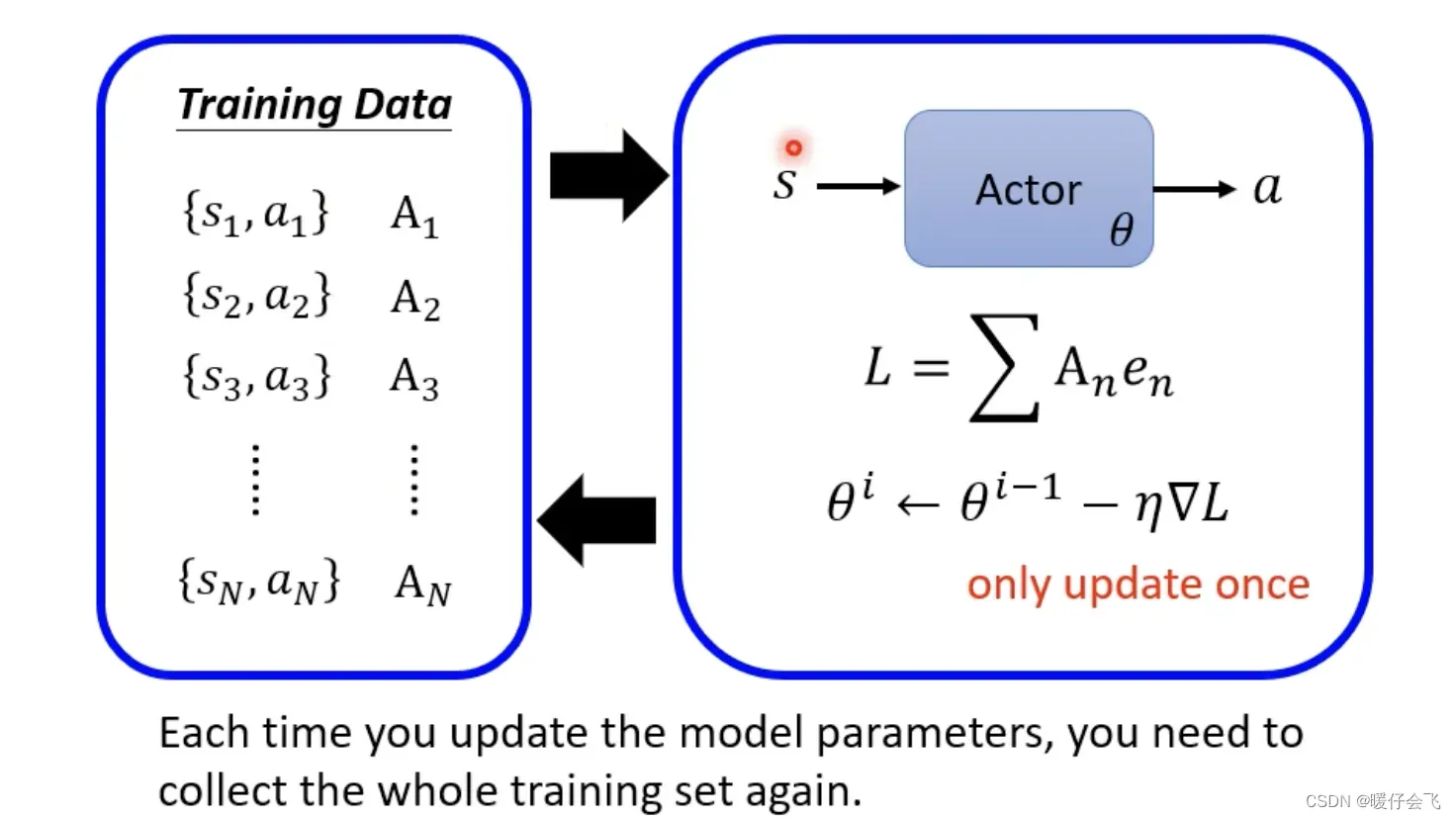
- 开始时第一个
epoch的actor参数是然后根据这个
actor产生的将
actor的参数更新成了那么这个时候根据
actor会产生和
所以需要把这些重新收集起来用于优化
。
On Policy v.s. Off Policy
- 上面提到的这些训练方法,被训练的 actor 和与环境进行交互的 actor 是同一个 actor ,这种训练的方式叫做
On Policy的方法 - 如果被训练的 actor 和与环境进行交互的 actor 不是同一个 actor 就叫做
Off Policy的方法

Value-based
- value-based 的方法是训练一个
这个东西不直接指导 agent 下一步要采取什么 action,他的作用是:给定一个当前环境的状态
,这个评估值表示的是 agent 如果继续玩下去在游戏结束的时候能够获得的预测值
- 举个具体的例子:
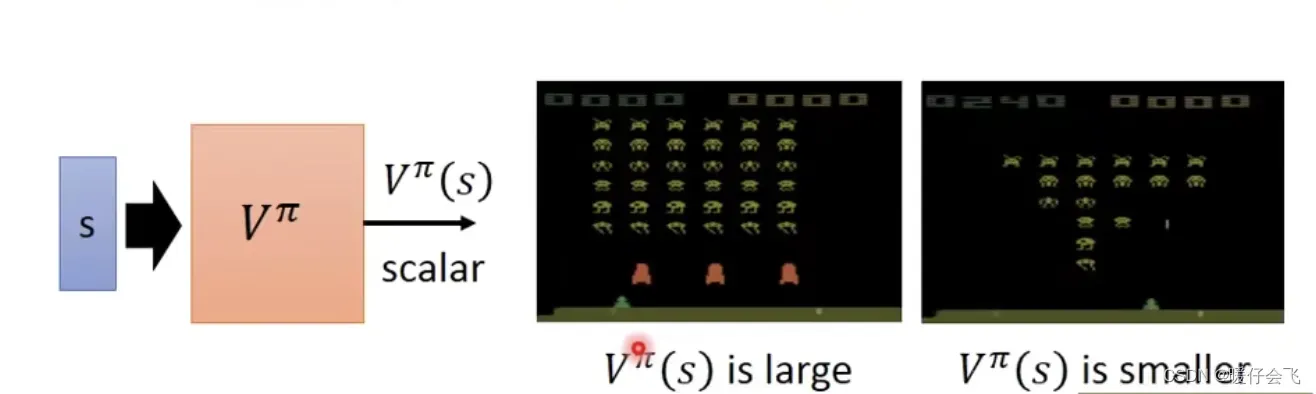
文章出处登录后可见!