一、贝叶斯决策论
贝叶斯决策论是概率框架下实施决策的基本方法。对分类任务来说,在所有相关概率都已知的理想情形下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记。
贝叶斯公式:
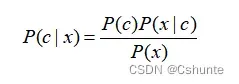
其中,P(c)是类”先验”概率;P(x|c)是样本x相对于类标记c的类条件概率,或称为”似然”(likelihood);P(x)是用于归一化的“证据”因子。对给定样本x,证据因子P(x)与类标记无关,因此估计P(c|x)的问题就转化为如何基于训练数据D来估计先验P(c)和似然P(x|c)。
类先验概率P(c)表达了样本空间种各类样本所占的比例,根据大数定律,当训练集包含充足的独立同分布样本时,P(c)可通过各类样本出现的频率来进行估计。
对类条件概率P(x|c)来说,由于它涉及关于x所有属性的联合概率,直接根据样本出现的频率来估计将会遇到严重的困难。因为在现实应用中,很多样本取值在训练集中根本没有出现,直接用频率来估计P(x|c)显然不可行,可以用极大似然估计来解决问题。
二、朴素贝叶斯分类器
不难发现,基于贝叶斯公式来估计后验概率P(c|x)的主要困难在于:类条件概率P(x|c)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。(基于有限训练样本直接估计联合概率,在计算上将会遭遇组合爆炸问题,在数据上将会遭遇样本稀疏问题;属性数越多,问题越严重)为了避开这个障碍,朴素贝叶斯分类器(naive Bayes classifier)采用了“属性条件独立性假设”:对已知类别,假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。
基于属性条件独立性假设,贝叶斯公式可以重写为:
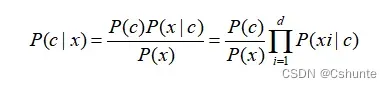
其中d为属性数目,xi为x在第i个属性上的取值。
由于对所有类别来说P(x)相同,因此贝叶斯判定准则有:
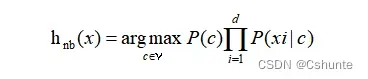
这就是朴素贝叶斯分类器的表达式。
显然,朴素贝叶斯分类器的训练过程就是基于训练集D来估计类先验概率P(c),并为每个属性估计条件概率P(xi|c)。
令Dc表示训练集D种第c类样本组成的集合,若有充足的独立同分布样本,则可以容易的估计出类先验概率:
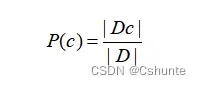
对离散属性而言,令Dc,xi表示Dc种在第i个属性上取值为xi的样本组成的集合,则条件概率P(xi|c)可估计为:
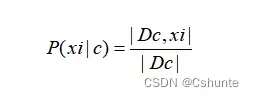
对连续属性可考虑概率密度函数,假定p(xi|c)~N(μc,i,σc,i²),其中μc,i和σc,i²分别是第c类样本在第i个属性上取值的均值和方差。则有:
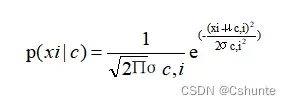
需注意,若某个属性值在训练集中没有与某个类同时出现过,则直接基于条件概率P(xi|c)进行概率估计,再根据贝叶斯判定准则进行判别将出现问题。例如在训练集中出现某个属性值没有与某个类同时出现的时候,由贝叶斯判定准则种连乘式计算出的概率值为零。因此,无论该样本的其他属性是什么,分类的结果都不受影响。这显然不太合理。
为了避免其他属性携带的信息被训练集中未出现的属性值“抹去”,在估计概率值时通常要进行“平滑”(smoothing),常用拉普拉斯修正(Laplacian correction)。具体来说,令N表示训练集D中可能的类别数,Ni表示第i个属性可能的取值数,则类先验概率和条件概率可以修正为:
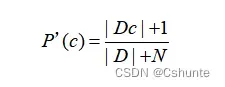
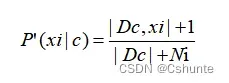
注意:拉普拉斯修正实质上假设了属性值与类别均匀分布,这是在朴素贝叶斯学习过程中额外引入的关于数据的先验。
显然,拉普拉斯修正避免了因训练集样本不充分而导致概率估值为零的问题。并且在训练集变大时,修正过程所引入的先验的影响也会逐渐变得可忽略,使得估值渐趋向于实际概率值。
在现实任务中朴素贝叶斯分类器有多种使用方式。例如,若任务对预测速度要求较高,则对给定训练集,可将朴素贝叶斯分类器涉及的所有概率估值事先计算好存储起来,这样在进行预测时只需“查表”即可进行判别;若任务数据更替频繁,则可采用“懒惰学习”(lazy learning)方式,先不进行任何训练,待收到预测请求时再根据当前数据集进行概率估值;若数据不断增加,则可在现有估值基础上,仅对新增样本的属性值所涉及的概率估值进行计数修正即可实现增量学习。
三、拓展-半朴素贝叶斯分类器
为了降低贝叶斯公式种估计后验概率P(c|x)的困难,朴素贝叶斯分类器采用了属性条件独立性假设,但在现实任务中这个假设往往很难成立。于是人们尝试对属性条件独立性假设进行一定程度的放宽,由此产生了一类称为“半朴素贝叶斯分类器”的学习方法。
半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息,从而既不需进行完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。“独依赖估计”(One-Dependent Estimator,简称ODE)是半朴素贝叶斯分类器最常用的一种策略。顾名思义,所谓“独依赖”就是假设每个属性在类别之外最多仅依赖于一个其他属性。
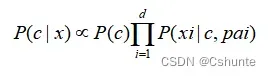
其中pai是属性xi所依赖的属性,称为xi的父属性。此时,对每个属性xi,若其父属性pai已知,则可采用拉普拉斯修正后的类条件概率的方法来估计概率值P(xi|c,pai)。
于是,不同的方法产生不同的独依赖分类器。下面简单举例两个独依赖分类器:
①SPODE(Super-Parent ODE)
假设所有属性都依赖于同一个属性,称为“超父”,然后通过交叉验证等模型选择方法来确定超父属性。
②AODE(Average One-Dependent Estimator)
AODE是一种基于集成学习机制、更为强大的独依赖分类器。与SPODE通过模型选择确定超父属性不同。AODE尝试将每个属性座位超父来构建SPODE,然后将那些具有足够训练数据支撑的SPODE集成起来作为最终结果。
总结:
既然将属性条件独立性假设放松为独依赖假设可能获得泛化性能的提升,那么,能否通过考虑属性间的高阶依赖来进一步提升泛化性能呢?也就是说,将属性pai替换为包含k个属性的集合pai,从而将ODE扩展为kDE。需注意的是,随着k的增加,准确估计概率P(xi|y,pai)所需的训练样本数量将以指数级增加。因此若训练数据非常充分,泛化性能有可能提升;但在有限样本条件下,则又陷入高阶联合概率的泥潭。
参考周志华《机器学习》
文章出处登录后可见!