- 💡统一使用 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 🌟本项目包含大量的改进方式,降低改进难度,改进点包含
【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数】、【NMS】、【Loss计算方式】、【自注意力机制】、【数据增强部分】、【标签分配策略】、【激活函数】等各个部分。 - 对于RepVGG 这块有疑问的,可以在评论区提出,或者私信博主的CSDN。🌟**
🔥🔥🔥YOLO系列 + Swin Transformer V2 结合应用 为 CSDN芒果汁没有芒果 首发更新博文
点Star🌟 和 Fork,第一时间获取同步更新🚀!
链接:https://github.com/iscyy/yoloair
对于这块有疑问的,可以在评论区提出,或者私信CSDN。🌟
本篇是《YOLOv5结合Swin Transformer V2结构🚀》的修改 演示
使用YOLOv5网络🚀作为示范,可以加入到 YOLOv7、YOLOX、YOLOR、YOLOv4、Scaled_YOLOv4、YOLOv3等一系列YOLO算法模块
文章目录
Swin Transformer论文

该论文作者提出了缩放 Swin Transformer 的技术 多达 30 亿个参数,使其能够使用多达 1,536 个图像进行训练1,536 分辨率。通过扩大容量和分辨率,Swin Transformer 在四个具有代表性的视觉基准上创造了新记录:ImageNet-V2 图像分类的84.0% top-1 准确率,COCO 对象检测的63.1 / 54.4 box / mask mAP,ADE20K 语义分割的59.9 mIoU,和86.8%Kinetics-400 视频动作分类的前 1 准确率。我们的技术通常适用于扩大视觉模型,但尚未像 NLP 语言模型那样被广泛探索,部分原因是在训练和应用方面存在以下困难:1)视觉模型经常面临大规模的不稳定性问题和 2)许多下游视觉任务需要高分辨率图像或窗口,目前尚不清楚如何有效地将低分辨率预训练的模型转移到更高分辨率的模型。当图像分辨率很高时,GPU 内存消耗也是一个问题。为了解决这些问题,我们提出了几种技术,并通过使用 Swin Transformer 作为案例研究来说明:1)后归一化技术和缩放余弦注意方法,以提高大型视觉模型的稳定性;2) 一种对数间隔的连续位置偏差技术,可有效地将在低分辨率图像和窗口上预训练的模型转移到其更高分辨率的对应物上。此外,我们分享了我们的关键实现细节,这些细节可以显着节省 GPU 内存消耗,从而使使用常规 GPU 训练大型视觉模型变得可行。使用这些技术和自我监督的预训练,我们成功训练了一个强大的 30 亿个 Swin Transformer 模型,并有效地将其转移到涉及高分辨率图像或窗口的各种视觉任务中,在各种的基准。代码将在 我们分享了我们的关键实现细节,这些细节可以显着节省 GPU 内存消耗,从而使使用常规 GPU 训练大型视觉模型变得可行。使用这些技术和自我监督的预训练,我们成功训练了一个强大的 30 亿个 Swin Transformer 模型,并有效地将其转移到涉及高分辨率图像或窗口的各种视觉任务中,在各种的基准。代码将在 我们分享了我们的关键实现细节,这些细节可以显着节省 GPU 内存消耗,从而使使用常规 GPU 训练大型视觉模型变得可行。使用这些技术和自我监督的预训练,我们成功训练了一个强大的 30 亿个 Swin Transformer 模型,并有效地将其转移到涉及高分辨率图像或窗口的各种视觉任务中,在各种的基准。代码将在 我们成功训练了一个强大的 30 亿个 Swin Transformer 模型,并将其有效地转移到涉及高分辨率图像或窗口的各种视觉任务中,在各种基准测试中达到了最先进的精度。代码将在 我们成功训练了一个强大的 30 亿个 Swin Transformer 模型,并将其有效地转移到涉及高分辨率图像或窗口的各种视觉任务中,在各种基准测试中达到了最先进的精度。
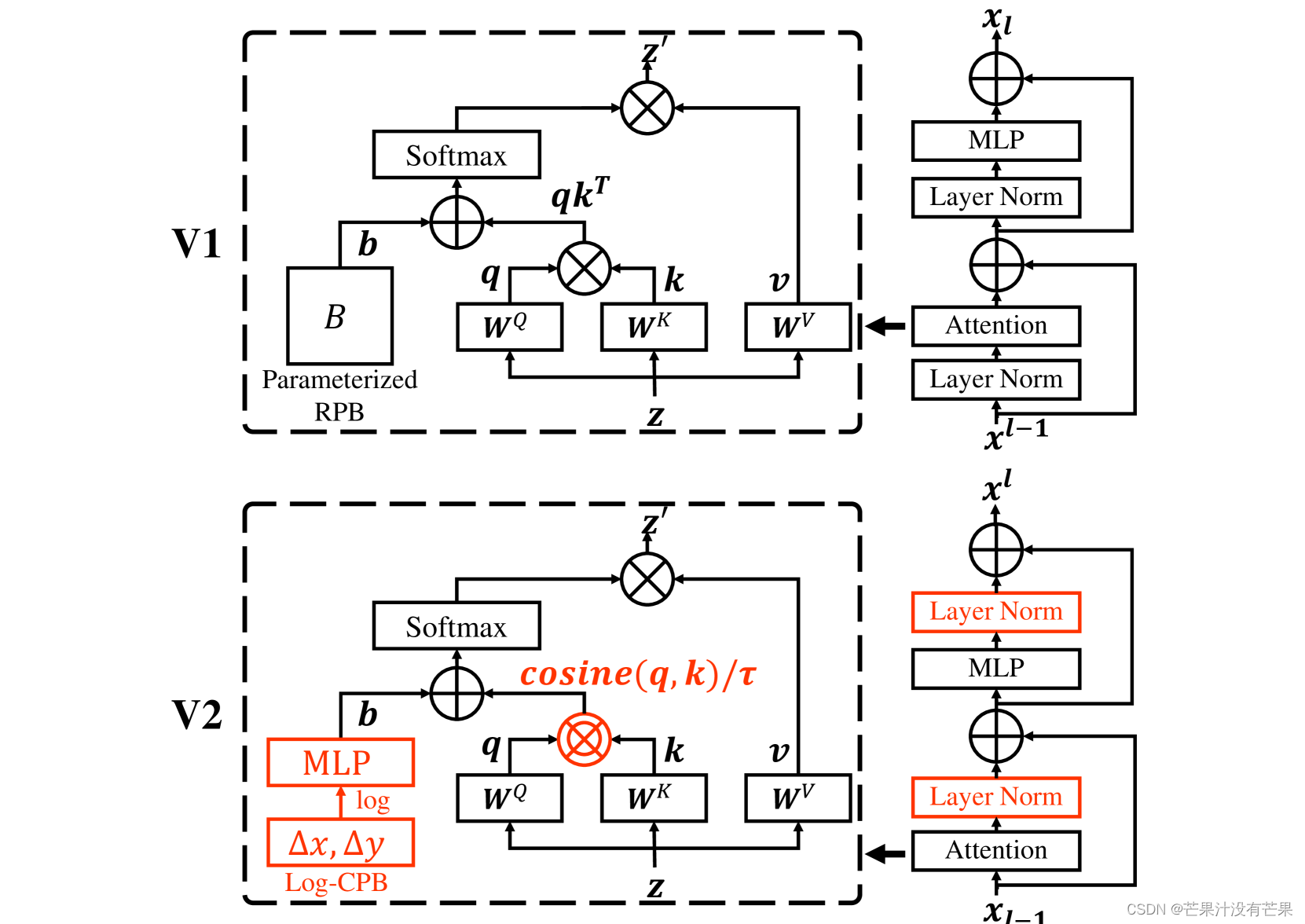
YOLOv5结合Swin Transformer-V2 演示教程
YOLOv5的yaml配置文件
首先增加以下yolov5_swin_transfomrer.yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone by yoloair
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, SwinV2_CSPB, [256, 256]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, SwinV2_CSPB, [512, 512]], # 9 <--- ST2CSPB() Transformer module
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
common.py配置
在./models/common.py文件中增加以下模块,直接复制即可
class WindowAttention_v2(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
pretrained_window_size=[0, 0]):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))), requires_grad=True)
# mlp to generate continuous relative position bias
self.cpb_mlp = nn.Sequential(nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False))
# get relative_coords_table
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(
torch.meshgrid([relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / np.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(dim))
self.v_bias = nn.Parameter(torch.zeros(dim))
else:
self.q_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale, max=torch.log(torch.tensor(1. / 0.01))).exp()
attn = attn * logit_scale
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, ' \
f'pretrained_window_size={self.pretrained_window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class Mlp_v2(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
# add 2 functions
class SwinTransformerLayer_v2(nn.Module):
def __init__(self, dim, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm, pretrained_window_size=0):
super().__init__()
self.dim = dim
#self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
#if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention_v2(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop,
pretrained_window_size=(pretrained_window_size, pretrained_window_size))
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_v2(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size!=0 or W_ % self.window_size!=0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition_v2(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse_v2(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(self.norm1(x))
# FFN
x = x + self.drop_path(self.norm2(self.mlp(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class SwinTransformer2Block(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=7):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer_v2(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x
class SwinV2_CSPB(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SwinV2_CSPB, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformer2Block(c_, c_, num_heads, n)
#self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1)
y2 = self.cv2(x1)
return self.cv3(torch.cat((y1, y2), dim=1))
yolo.py配置
不需要
训练yolov5_swin_transfomrer-V2模型
python train.py --cfg yolov5_swin_transfomrer-V2.yaml
文章出处登录后可见!