YOLOX的简述
一、 原因
1. 背景
工业的缺陷检测是计算机视觉中不可缺少的一环之一,在实际的工程项目中具有广泛的应用价值。
YOLOX是目前较为新颖的算法之一,其丰富的权重模型,优秀的实时检测速度,以及精准的检测性能,独特的解耦头处理方式,使其在YOLO系列算法中脱颖而出。
2. 概念
YOLOX依据YOLOv3和YOLOv5,使用了CSPNet,SiLU激活函数以及PANet,并遵循缩放规则设计了YOLOX-S/M/L/X等四种模型。
此次以YOLOX-S模型为介绍,YOLOX-S模型参数量少,对实时性要求较高,适配度更优,与YOLOX-Nano等模型相比,YOLOX-S模型保有一定的模型体量,具有较高的检测精确率。
二、 算法介绍
2.1 YOLOX算法结构图:
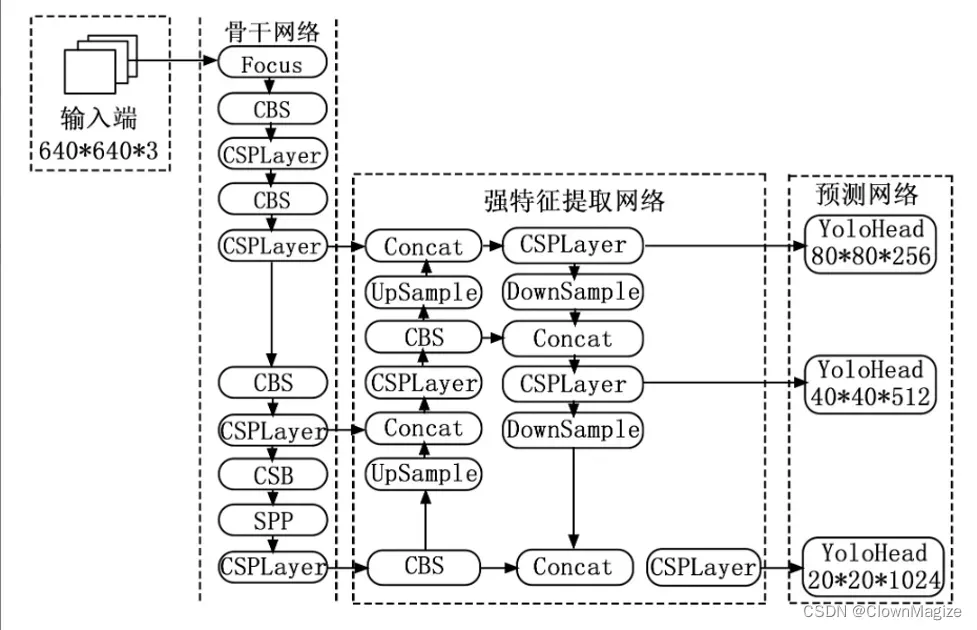
2.2 算法独特点
解耦头: YOLOX的解耦头(Decoupled head)与以往的YOLO不同,它包含一个1*1的卷积层以调整通道数量,之后是两个并行分支,每个分支上包含两个卷积层,两条分支分别用于分类和回归任务,计算重叠度分支被添加在回归分支上。
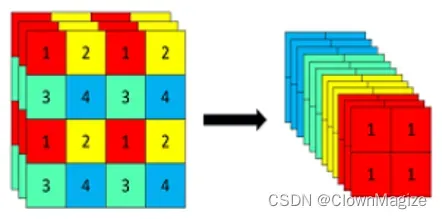
2.3 Focus网络结构
YOLOX使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道。
2.4 FPN,PAN
FPN可以被称作YoloX的强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合目的是结合不同尺度的特征信息。
在FPN部分,已经获得的有效特征层被用于继续提取特征。
YOLOX网络的颈部还在FPN层后面增加了一个与FPN相对的结构,即包含两个PAN结构的自下而上的特征金字塔。
FPN自上而下,将浅层特征与上采样后的上层特征信息进行传递融合,而PAN自下而上,将下采样后的小尺寸特征图像与大尺寸特征图像进行融合,并成对组合,对不同的检测层进行两次参数融合。
2.5 BaseConv
BaseConv是YOLOX网络中的基本卷积,它包括Conv、BN、SiLu,卷积操作在网络中主要负责特征提取,是模型最重要的操作之一。
BN让每层的输出和下层的输入数据分布尽量保持一致,模型在训练的时候更加稳定。激活函数为网络提供了非线性变化的能力,实现深度模型中层次化逐级抽象特征的能力。

使用了SiLU激活函数, SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数
激活函数是连续,且可导的,其目标是将神经网络非线性化。
激活函数为有下界无上界,其下界避免了网络训练时因梯度为零导致的收敛缓慢,同时有利于网络参数的正则化。
由于激活函数本身是非线性的,所以在神经网络中引入激活函数可以使神经网络任意逼近非线性函数,从而可以增强深度神经网络的表达能力。
2.6 SPP
SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。
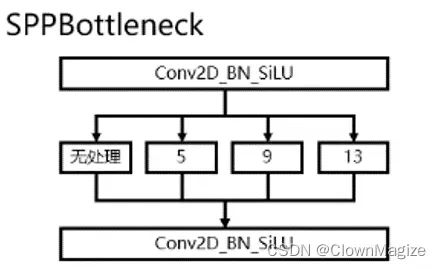
感受野(Receptive Field)是指特征图上的某个点能看到的输入图像的区域,即特征图上的点是由输入图像中感受野大小区域的计算得到的 神经元感受野的值越大表示其能接触到的原始图像范围就越大,它可能蕴含的更为全局
空间金字塔池化层(Spatial Pyramid Pooling)主要解决了输入图片大小不统一的问题,通过三种不同的池化操作融合多重感受野。
2.7 CSPDarknet

YoloX所使用的主干特征提取网络为CSPDarknet,它具有以下特点:
1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;
残差边部分不做任何处理,直接将主干的输入与输出结合。
2、整个YoloX的主干部分都由残差卷积构成:
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。
其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题
2.8 YOlO Head
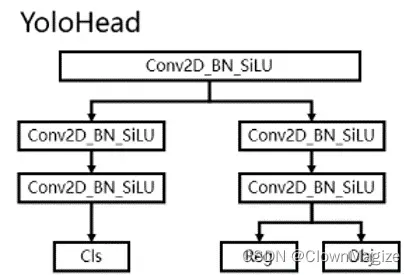
Yolo Head通过CSPDarknet和FPN,可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。
Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。利用FPN特征金字塔,我们可以获得三个加强特征,这三个加强特征的shape分别为(20,20,1024)、(40,40,512)、(80,80,256),然后我们利用这三个shape的特征层传入Yolo Head获得预测结果。
三、预测曲线
3.1 曲线
得到最终的预测结果后还要进行得分筛选与非极大抑制筛选,得分筛选就是筛选出得分满足confidence置信度的预测框,非极大抑制就是筛选出一定区域内属于同一种类得分最大的框。
得分筛选与非极大抑制筛选后的结果就可以用于绘制预测框,未经过抑制的会出现多重框。
经过训练后可产生Precision与Pecall图:
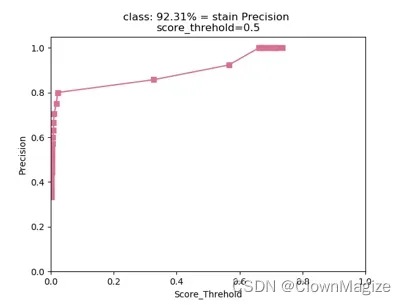
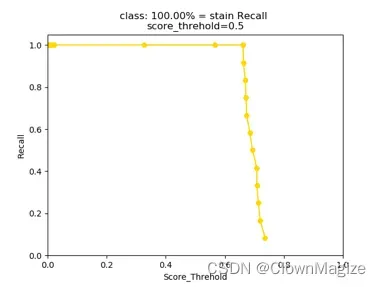

TP— 本来是正样本,检测为正样本(真阳性)。
TN—本来是负样本,检测为负样本
FP—预测错了,本来是负样本,检测为正样本。
FN— 预测为 N(负例), 预测错了,本来是正样本,检测为负样本。
文章出处登录后可见!