前言
Vision Transformer 论文:https://arxiv.org/pdf/2010.11929.pdf
跟李沐学AI:https://www.bilibili.com/video/BV15P4y137jb?spm_id_from=333.999.0.0
Vision Transformer打破了CNN在计算机视觉领域的统治地位,仅使用一个标准的Transformer Encoder(与NLP领域中使用的Transformer相同),并在大规模数据集预训练的情况下,就能达到和CNN一样甚至更好的效果,可以说是填补了CV和NLP之间的鸿沟。
写这篇博客的目的是为了让初学者,无论是刚开始深度学习还是刚接触这个领域的人,都能更好的理解这篇论文的核心思想和实现过程,所以篇幅较长,希望大家可以耐心继续阅读,相信看完你会有收获。接下来,让我们正式进入论文的解释吧!
Vision Transformer
Architecture
这篇论文的思路其实比较简单,我们先看模型架构图: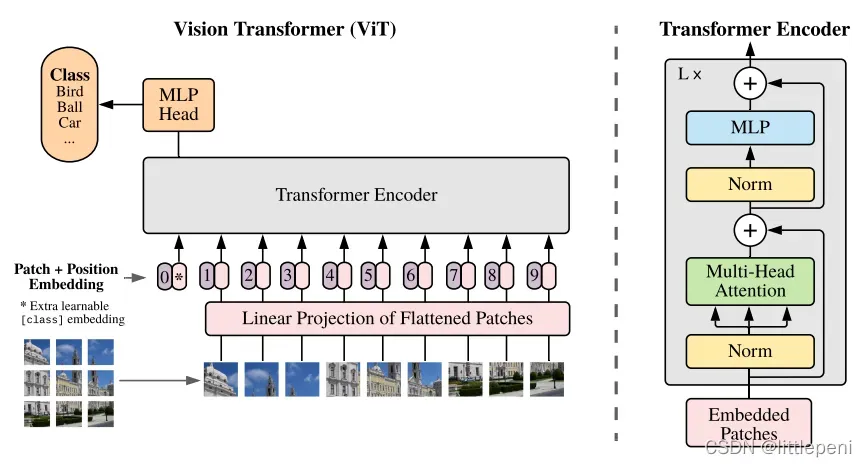
在NLP领域中的任务如机器翻译,通常是将一个句子的各个词组成一个序列输入到Linear Projection后变成一个个token,然后再输入到Transformer的各个模块,每个词是一个完整的语义信息的单位。但是图片是由一个个像素组成的,如果使用类似于NLP的方法,将像素排列成一个队列输入,对于一张224×224的常规图片,序列长度就为2242=50176,已经远远超过了Transformer可以承载的序列长度;因此,基于此问题,本文提出了一种将图片分块的策略,即将原始图像分成一个个小的patch,这里假设每个patch的大小是16×16,则patch的个数就为2242/162=196,即现在的序列长度。这样一来,序列长度就在Transformer的承载范围之内了。对于更大的图片例如312×312,可以通过改变patch的大小调整序列长度,从而使更大的图像也能够应用于Transformer中。
上面这段话即这篇论文的创新点之一,接下来详细讲解模型前向处理过程。我们已经假设了每个patch的大小是16×16=256,由于是三通道彩色图像,因此还要×3,最后的大小是768,序列长度是196。对于这样的一个序列,首先通过Linear Projection(在这里实际就是一个全连接层,输入输出维度是768×768)得到一个个token即语义特征向量,输出维度不变,仍然是196×768;对于每个像素块即patch,我们需要知道他们之间的位置关系,否则整张图片对于网络来说就仅仅是一个无序的块的序列,无法提取块之间的相关关系,因此类似于Bert中的position embedding,这里也加上了position embedding——对每个语义特征向量加上一个长度为768的位置特征向量,注意,这里是sum而不是concatenate,因此不影响维度,依旧是196×768。将这样的一个个token输入到Transformer Encoder中,会得到一个个反馈输出,模型应当使用哪个输出呢?本文同样借鉴Bert,加入了一个Extra Learnable Class Embedding,即cls字符,它的位置编码永远是0,当然在这里也实际是一个768的向量,cls字符本身的长度也是768;因为注意力机制原理是所有元素之间进行两两交互,作者相信cls字符能够包含其它所有patch的信息,因此使用cls token经过Transformer Encoder后的输出就可以了。所以,预处理后的数据维度是(196+1)×768。
因此,Transformer Encoder的输入维度就是197×768。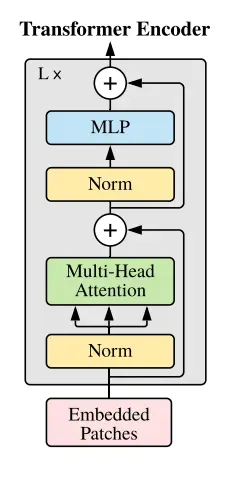
输入首先通过Layer Normalization,然后通过一个Multi-Head Attention,经过一个残差连接后,再通过Layer Normalization,最后通过一个MLP和残差连接得到输出,维度不变,依旧是197×768,因此可以有L个block叠加起来,就形成了Transformer Encoder。
Experiments
CLS Token & Global Average Pooling
我们知道,在计算机视觉的图像识别任务中,一张图片通常是经过一些卷积操作,然后通过Global Average Pooling即全局平均池化得到一个表示图像总体特征的特征向量,最后放入分类层进行分类;而对于NLP领域中的任务,通常是使用Class Token,即上文中提到的CLS。针对这两种处理方式,作者进行了消融实验,探究它们在基于Transformer的CV任务上的效果好坏。实验结果如下: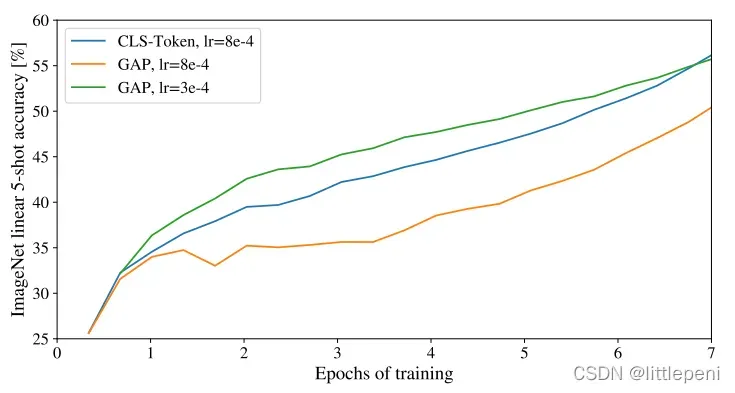
实验结果表明,无论是将Transformer Encoder的输出结果做Global Avergae Pooling再放入分类层还是将CLS Token放入分类层都能够达到差不多的效果,但两者使用的学习率有所不同,一个是3×10-4,一个是8×10-4。若将CLS Token使用的学习率应用到GAP上,在ImageNet数据集上的准确率将大大降低。
Positional Embedding
对于计算机视觉任务,通常有三种方式来编码位置:
- 1D-Positional Embedding:即和论文中使用的位置编码方式一致,例如将图像分割成9宫格,顺序依次是1,2…9,则每一个位置用一个长度为768(和patch长度一致,统称为D)的向量表示。
- 2D-Positional Embedding:一张图像其实是一个二维数据,每一个patch有横纵坐标,因此为了更好的表示这种二维结构特征,可以使用一个长度为D/2的向量表示patch在横轴上的位置(1,2,3),使用一个长度为D/2的向量表示patch在纵轴上的位置(1,2,3),最后拼接起来就形成了一个长度为D的向量。
- Relative Positional Embedding:即相对位置编码,每一个patch的位置可以表示成与其它某一个patch的距离,实际上还是一种1D-Embedding。
各种位置编码方式下的实验结果如下: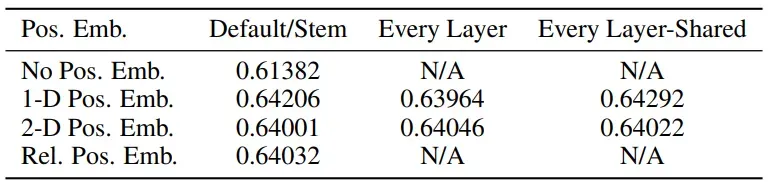
可以看到,当不使用位置编码时,实验结果是最差的,因为Transformer本身并不能学到序列中的位置信息。加入了Positional Embedding后,实验结果提升了3个点,说明了位置编码的有效性。但可以看出,其实各种位置编码方式最后的精度都差不多,论文对此的解释是,因为模型是对16×16这样的小的patch进行处理而不是处理一整张224×224的图片中的所有像素,因此找到各个patch之间的位置关系还是相对容易的。
Comparison
首先来看论文中定义的几种模型大小,分别是Base、Large和Huge,它们的区别主要体现在Transformer Encoder的Block数量、输入向量的大小、MLP的大小、多头自注意机制模块的头的数量以及模型参数: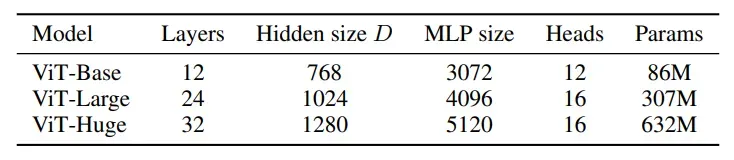 Vision Transformer的输出不仅与模型大小有关,也由输入大小有关,例如在图像尺寸固定的情况下,Patch Size越大,输入序列长度就越短,模型训练就越容易。因此,模型的命名方式加上了Patch Size这一属性,“for instance, ViT-L/16 means the “Large” variant with 16×16 input patch size”。
Vision Transformer的输出不仅与模型大小有关,也由输入大小有关,例如在图像尺寸固定的情况下,Patch Size越大,输入序列长度就越短,模型训练就越容易。因此,模型的命名方式加上了Patch Size这一属性,“for instance, ViT-L/16 means the “Large” variant with 16×16 input patch size”。
论文给出了各种模型架构在经过大规模数据集预训练后在不同数据集上Fine-tune的效果,如下: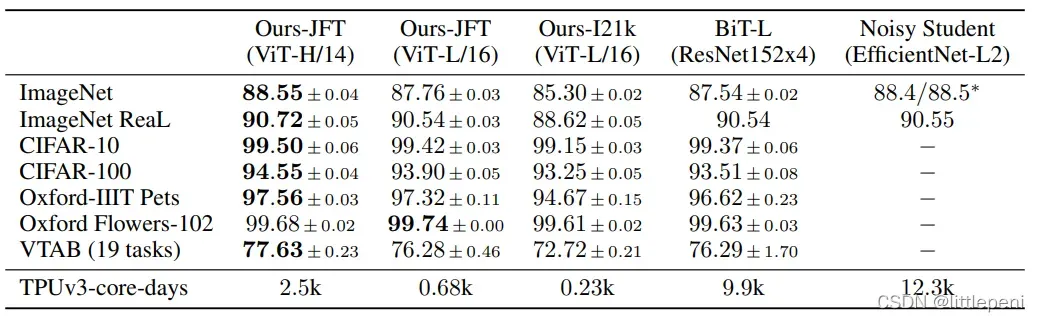
从结果中可以看出,通过JFT数据集预训练的ViT-H/14模型在各大数据集上都取得了最好的效果,仅有的一个没加粗的数据也和最好结果相差无几,说明了Vision Tranformer已经赶上Resnet等网络的效果甚至已经超越了。但是从表中可以看出,每一列的数据其实差别都不算太大,作者认为还没有发挥出Vision Transformer的威力,因此选择从另一个角度突出它的优势:便宜。表格中最后一行表明的是各个模型在TPUv3-core上进行预训练所需的天数,可以看出即使是最大的ViT-H/14模型所需要的训练时长也是远远低于BiT-L和Noisy Student的,由此说明了Vision Transformer可以在需要更少计算资源的情况下达到甚至超过其它模型的性能。
Pre-train On Different Size Of Dataset
论文进一步探究了Vision Transformer在不同Size的数据集上做预训练后的效果,这里主要是和BiT(即各种大小的Resnet)进行比较,结果如下: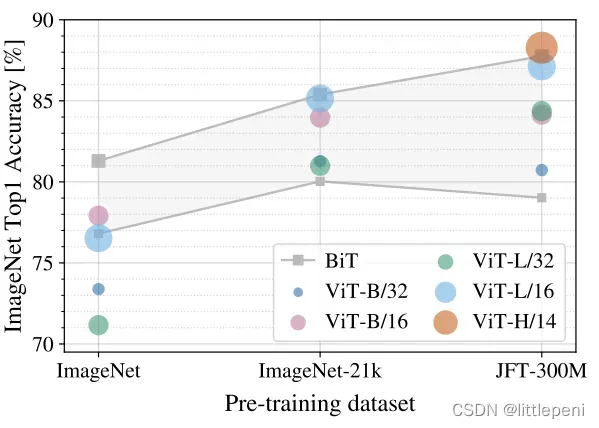
灰色线即表示BiT网络,下面的线表示Resnet50,上面的线表示Resnet152,因此整个灰色区域表示Resnet可以达到的效果范围。横轴表示不同Size的预训练数据集,从左至右Size依次变大(1k、21k、300m),纵轴表示在ImageNet-1k数据集上的识别准确率。从图中可以看出,当使用中小型数据集进行预训练时,ViT模型的效果是全面低于Resnet的;而使用ImageNet-21k数据集预训练时,ViT的效果已经能够和Resnet持平了;使用JFT-300M数据集时,ViT的效果已经全面压制Resnet了(即使是最小的ViT-B/32的效果也由于Resnet50)。因此,我们从结果中可以总结出两点信息:
- 至少要使用ImageNet-21k大小的数据集进行预训练,ViT的效果才能够和Resnet持平,若无法使用该规模的数据集做预训练(Training time is too long,money is not enough),还是使用卷积神经网络最佳;
- 当使用更大规模的数据集进行预训练时,ViT能够给你更好的效果。
作者也做了对模型性能的分析,对比了不同Size的预训练数据集对模型特征提取效果的影响,和上面大同小异: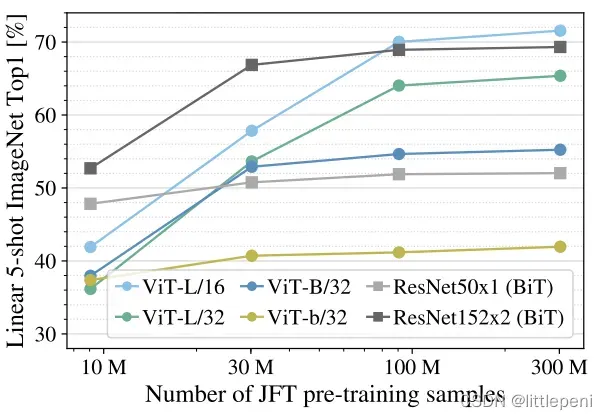
和上图不同的是,这张图中的横轴是同一个数据集,只是取了不同大小的子集,这样就消除了数据集之间分布差异可能带来的负面影响;此外,模型在预训练后并没有进行Fine-tune,而是直接作为一个特征提取器,在ImageNet数据集中抽取5个样本,验证分类效果。结果表明,在小型数据集上预训练后,ViT是远远不如Resnet的,而当预训练数据集规模逐渐增大后,ViT的效果与Resnet持平甚至优于Resnet了。
Comparison Of Training Costs
作者为了证明Vision Transformer训练起来便宜高效这一观点,对比了不同模型在同一训练成本下的验证效果: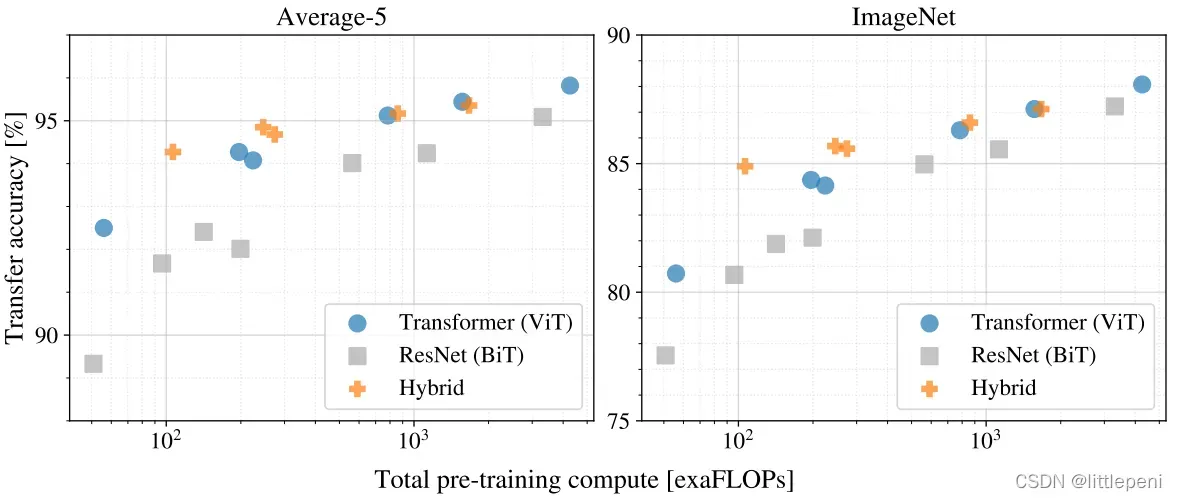
左图是在5个数据集上的验证效果的平均,右图是单独使用ImageNet数据集进行验证的效果,所有模型均使用JFT-300M数据集进行预训练。从两个图都可以看出,模型规模相同(即训练成本相同),当模型较小时,Hybrid模型(混合模型,即前面使用卷积神经网络得到较小的特征图,将特征图展开为序列,后面使用Transformer对序列进行处理)和ViT模型的效果都显著优于Resnet;当模型较大时,混合模型和ViT模型的性能相差不大,但依旧优于Resnet。最后,可以看出,当模型越来越大时,模型分类效果也越来越好,并没有出现性能饱和(即准确率达到一个平台后不再上升)的现象,还是比较理想的。
Visualization
作者探究了Vision Transformer的第一层即Linear Projection对图像特征提取的效果,如下:
可以看出,类似于卷积神经网络的第一层,Vision Transformer的第一层也能够提取到图像的底层特征,如颜色、纹理等。
作者又探究了Positional Embedding的作用,如下: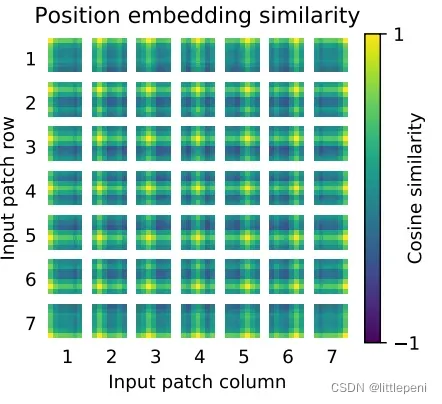
横纵轴都表示的是patch的下标。从图中可以看出,对于每一个patch,都是和自己相同位置的patch相似度最高,同行同列的patch次之,不同行不同列的patch相似度最低。因此,1D-Positional Embedding其实已经很好地学到了2D维度上的距离信息,这也是为什么上面实验中使用2D-Positional Embedding而效果并没有显著增加的原因。
最后,作者探究Vision Transformer中的自注意力机制是否真正在起作用。Transformer相比于CNN的优势就是能够处理长距离依赖,即利用自注意力机制,一个句子中的第一个词和最后一个词也能够相互有关联。因此,作者想证明Vision Transformer确实能够利用注意力机制获取图像的全局特征,而不仅仅只能捕捉到相邻元素之间的依赖关系。结果如下: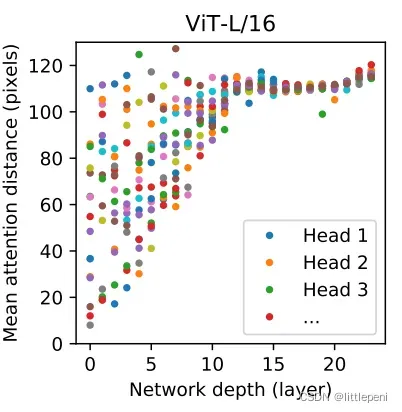
横轴表示Transformer Encoder中的block数量(一共有L个),纵轴表示平均注意力距离,可以类比于卷积核的感受野大小。由于这里是ViT-L/16模型,因此自注意力头有16个,即每一列有16个点。可以看到,在初始的block中,一些自注意力头的感受野较小,在20个pixels左右,但已经有一些自注意力头的感受野达到了全局图像大小,证明了Vision Transformer确实充分利用了Transformer的长距离处理优势。随着block的不断加深,网络已经开始充分提取到图像的高层语义特征即全局特征,因此所有的自注意力头的感受野都扩大到整张图像了。
Conclusion
- Vision Transformer填补了CV和NLP之间的鸿沟,仅使用一个标准的Transformer Encoder就能够在计算机视觉领域的任务上达到和CNN相同甚至更好的结果;
- 说明了当使用大规模预训练数据集时,Vision Transformer能够达到很好的迁移学习效果,广泛应用于各种下游任务;
- 促进了多模态领域的发展,对音频、文本、视频等模态的处理可以使用同一个Transformer实现,真正实现了CV和NLP的大一统;
- 终于挖了个大坑,在应用任务(目标检测、图像分割)、模型架构、训练方法(监督训练、自监督训练)方面还有很大的提升空间。
后记
如果觉得博主写得还不错,麻烦点赞加关注,谢谢!我之后还会介绍该领域的其它相关论文,下一篇博客即将介绍Kaiming He大神的最新力作Masked Autoencoder(MAE),链接:https://arxiv.org/pdf/2111.06377.pdf。敬请期待!
文章出处登录后可见!