图像标注工具Lable
labelme 是一款图像标注工具,主要用于神经网络构建前的数据集准备工作,因为是用 Python 写的,所以使用前需要先安装 Python 集成环境 anaconda。
anaconda 安装
anaconda下载地址如下:
https://www.anaconda.com/products/distribution
找到对应自己电脑操作系统位数的版本,直接下载,下载后安装,正常情况下,根据提示,一直 next 就可以,直到提示安装完成
Lableme安装
labelme 安装前,需要先创建 anaconda 虚拟环境 labelme,进入 Anaconda Prompt,输入如下命令,该命令表示创建虚拟环境 labelme。
conda create -n labelme python=3.8
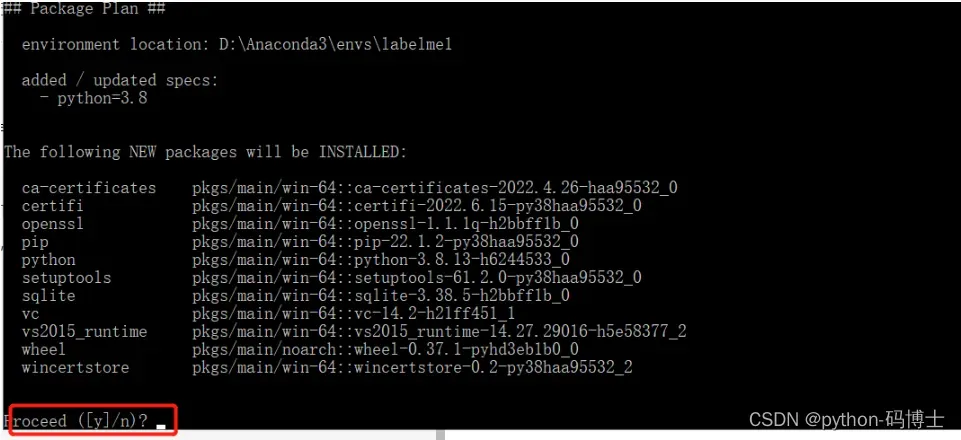
输入如上命令,会运行几秒钟,正式开始创建前,会出现([y]/n)?字样,表示是·否同意创建的意思,输入 y,按 enter,等待运行结束
输入:
conda env list
查看当前已安装的虚拟环境
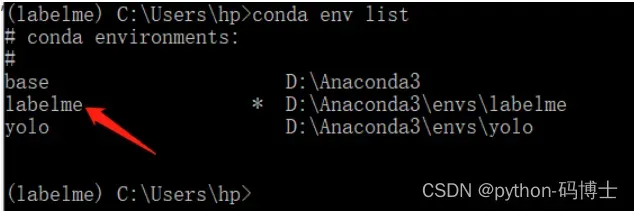
创建好虚拟环境后,需要激活,用如下命令
conda activate labelme
labelme 正常运转需要各种依赖的包,下面的 pypt 和 pillow 就是,它们用如下命令安装
conda install pyqt5
conda install pillow
安装好 labelme 依赖的包之后,正式开始安装 labelme,用如下命令,先用 conda 命令,如果安装不成功,则用 pip 命令
conda install labelme=3.16.2
#conda 安装命令如果出错也可以使用 pip 命令,使用逻辑等号"=="
pip install labelme==3.16.2
#也可以直接
conda install labelme
# 或者
pip install labelme
中间有可能会再次出现([y]/n)?,也有可能不出现,玄学,如果出现,则和之前的操作一样,输入y,按下 enter,等待安装结束。如果不出现,运行一段时间后,如果看到有 successfully installed labelme 等字样,则表示安装成功
这一步一定要注意安装的版本号,如果直接安装 labelme 不标注版本号在后续 json 到 dataset 的时候会出现异常,一般来说3.16的版本都可以
lableme使用
以后每次使用 labelme 时,都需要桌面搜索进入 anaconda prompt,用如下命令激活 labelme 环境
activate labelme
用如下命令打开 labelme
labelme
输入如上命令后,会弹出 labelme 操作界面,如下:

图片打标实例
点击 Open Dir,选择待标注图片所在文件夹,批量导入
根据需求,选择圆、矩形、多边形(默认)等开始标注,一般为多边形
一个区域标注完成后,会自动弹出对话框,键入标签名称
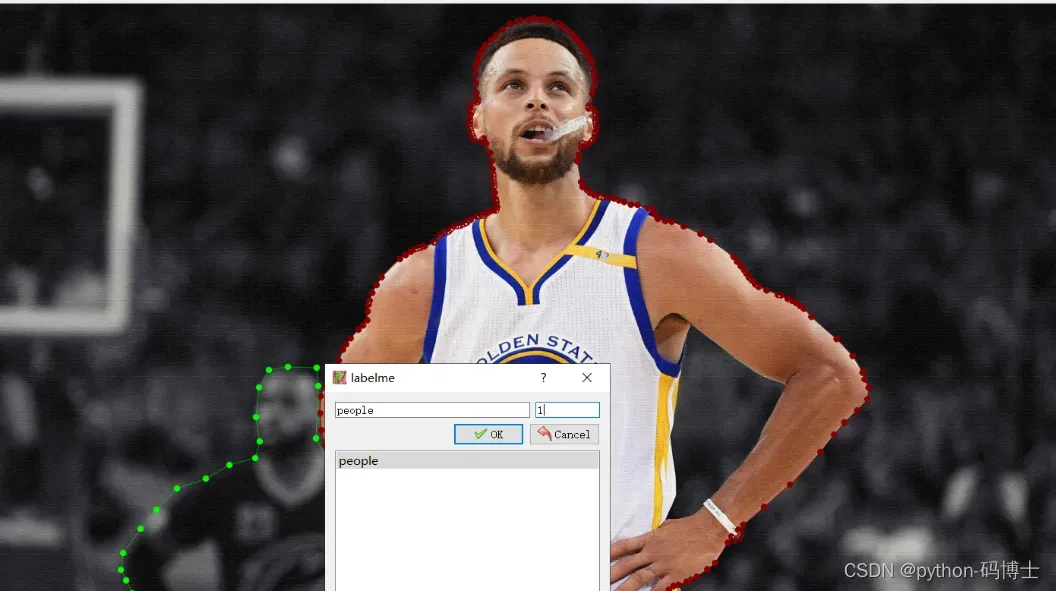
所有区域标注完成后,点击左侧栏 Save,会自动保存对应的 json 数据
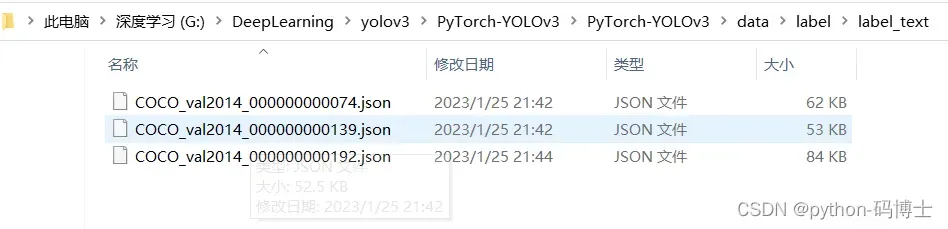
每一个json文件都会包含这几项信息:
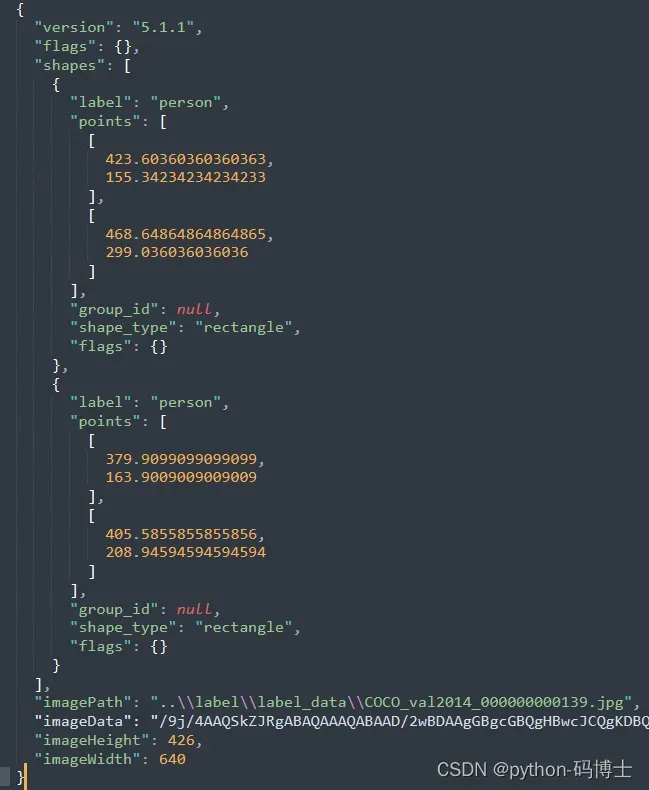
label:标注的类别
points:标注的信息,这里是左上和右下角的坐标,后面使用需要转换
shape type:标注框的类型,这里是矩形框
shapes:一张图像上的所有标注信息
imagePath:标注图片所在的路径
imageHeight:标注图片的高
imageWidth:标注图片的宽
标注文件的使用(以YOLO v3为例)
一、写好模型所需的配置文件
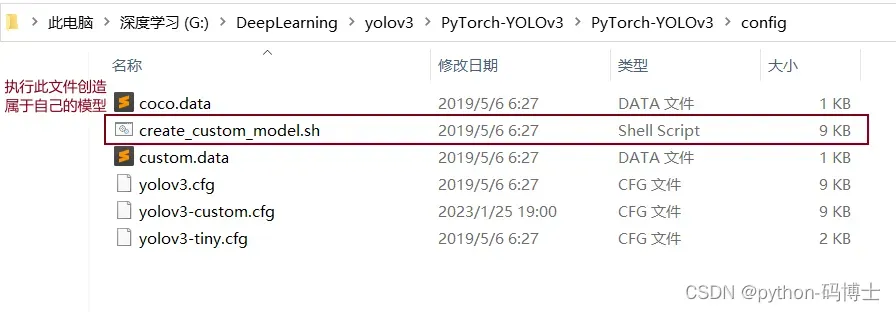
执行步骤如下
1、在此文件夹右击,选择Git Bash Here(没有的去下载安装)
2、输入命令bash create_custom_model.sh 2是多少分类数字就写几,演示案例2分类
ps: create_custom_model.sh不能重复执行,要先把yolov3-custom.cfg删除掉才可以
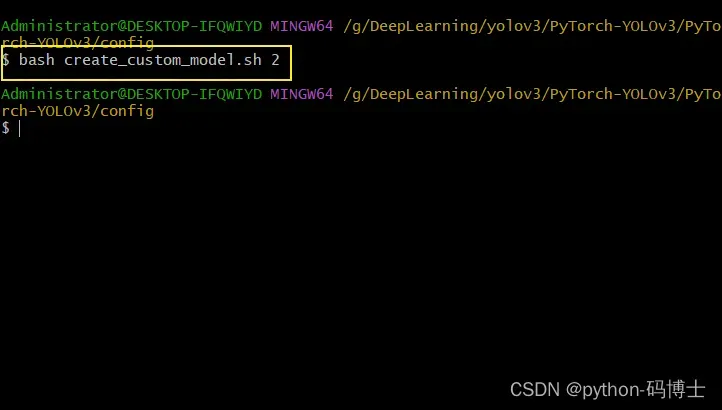
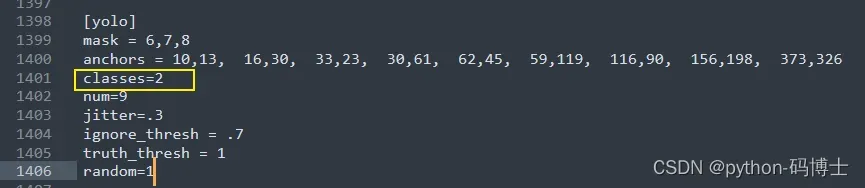
3、执行之后会出现yolov3-custom.cfg这个文件,里面的内容和官方的网络模型配置文件(yolov3.cfg)差不多,只是yolo层的classes会变成2(是几分类就变成几)。
这里我们可以根据自己的任务用K-means聚类算法更改anchors,使其更符合我们的任务,这里的框完全够用,我就不改了。
二、标签格式转换
labelme ——-→ X1,Y1,X2,Y2
yolo-v3———→Cx,Cy,W,H 相对位置(取值范围0-1)
我们需要把labelme格式的框坐标转为yolo格式的。
这里我们需要用到json2yolo.py:
import json
import os
name2id = {'person':0,'dog':1} # 转换类别的定义(有多少类别就写对应的)
def convert(img_size, box):
# 计算放缩比例
dw = 1./(img_size[0])
dh = 1./(img_size[1])
# 计算Cx,Cy,W,H的值
x = (box[0] + box[2])/2.0 - 1
y = (box[1] + box[3])/2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
# 归一化操作
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def decode_json(json_floder_path,json_name):
# 输出转换好的标签路径
txt_name = 'G:\\DeepLearning\\yolov3\\PyTorch-YOLOv3\\PyTorch-YOLOv3\\data\\label\\labels\\' + json_name[0:-5] + '.txt'
txt_file = open(txt_name, 'w')
# 读取json文件的路径 json_floder_path:生成标签的文件夹
json_path = os.path.join(json_floder_path, json_name)
data = json.load(open(json_path, 'r', encoding='gb2312'))
# 提取W,H的值
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label'] # 得到标签类别
if (i['shape_type'] == 'rectangle'): # 判断是否为矩形框
# 提取x1,y1,x2,y2并做convert函数操作
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1,y1,x2,y2)
bbox = convert((img_w,img_h),bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_floder_path = 'G:\\DeepLearning\\yolov3\\PyTorch-YOLOv3\\PyTorch-YOLOv3\\data\\label\\label_text' # 文件路径
json_names = os.listdir(json_floder_path) # 读取文件夹的内容
for json_name in json_names: # 遍历每一个json文件传递给decode_json处理
decode_json(json_floder_path,json_name)
运行之后的结果
- 这个文件可以按
规则(下面《存放标签数据的文件夹有讲究》会讲到)放到data/custom/labels文件夹里(官方推荐),我这里随便放的,后期要注意路径的修改。(看第五步) - 训练集和验证集的标注文件放到两个文件夹,通过使用两次脚本或在这个脚本上加一些逻辑完成转换。
一行是一个矩形框, 第一列为类别,然后是Cx,Cy,W,H

存放标签数据的文件夹有讲究
存放标签数据的文件夹要和存放图片数据的文件夹对应,目的是找到图片对应的标签数据。
label是存放数据和标签的大文件夹,源码中在处理标签数据时会提取到的文件夹路径是label\label_data\train_label\xxx.jpg,label\label_data\val_label\xxx.jpg,当然.jpg会转为相应的.txt格式。因此我们需要在标签数据的文件夹上面再套一层存放数据和标签的大文件夹label,然后我们的源码路径做相应的更改即可,可以看下面图片理解。
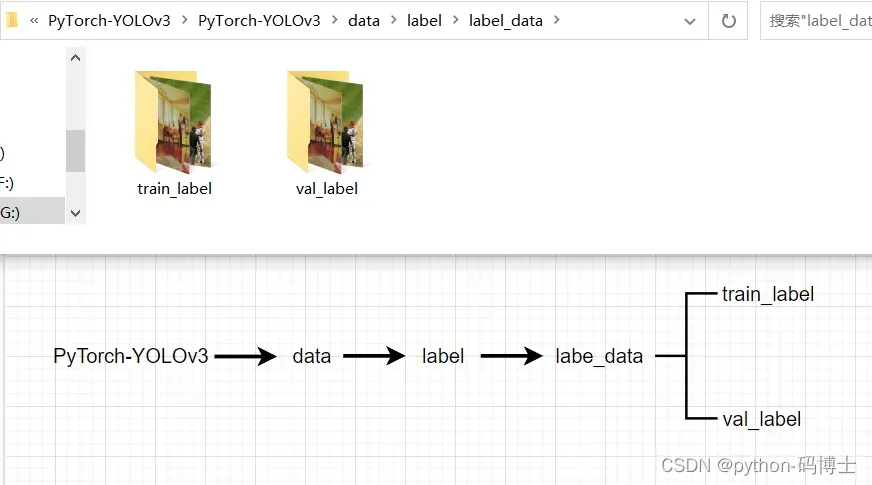
存放图片的文件夹路径
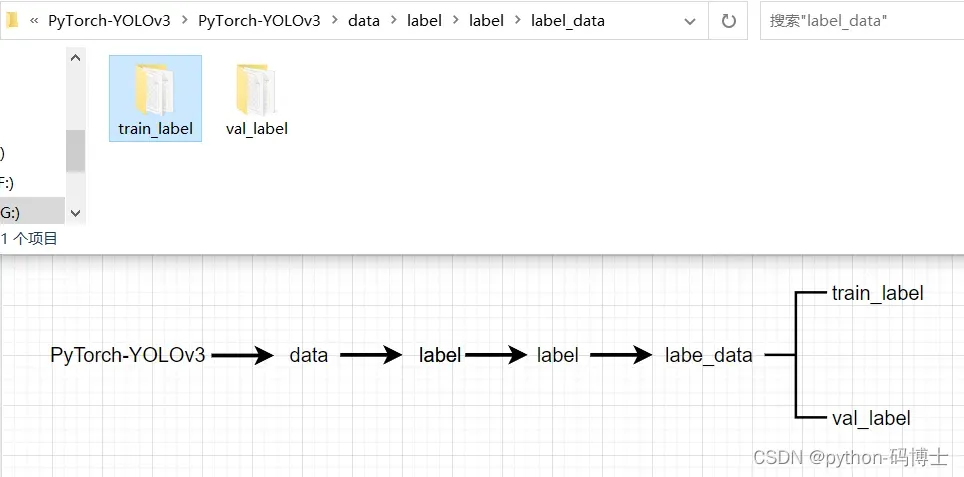
存放标签的文件夹路径
四、修改classes.names配置文件
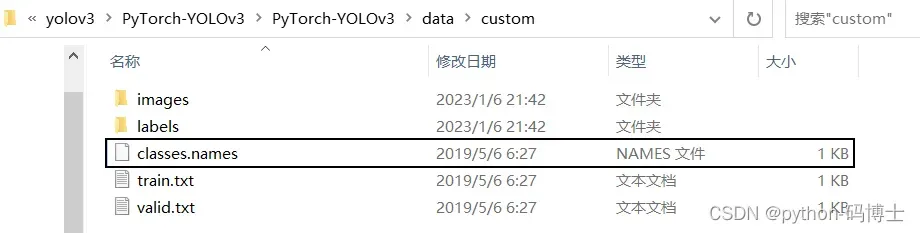
改为自己任务的类别名字(按自己定义的顺序写好),最后一个类别后面要留有一行,不然识别不到最后一个类别。
![]()
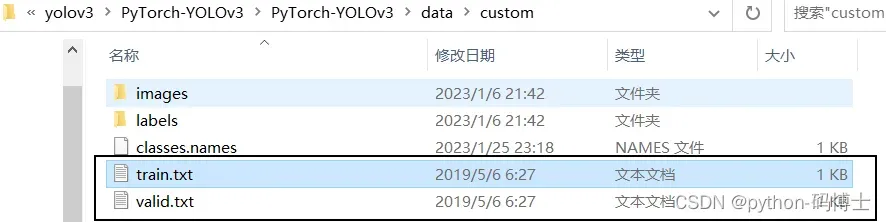
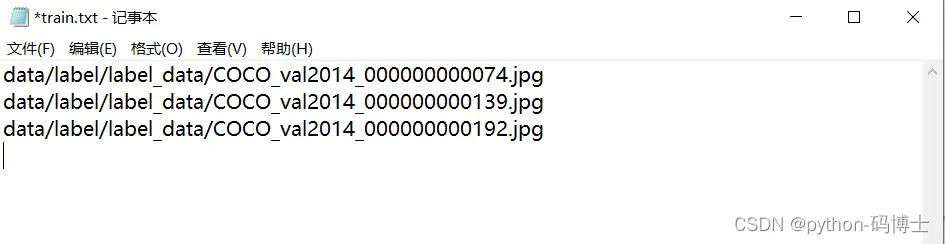
五、修改train.txt和val.txt
在存放数据和标签的大文件夹label下创建train.txt和val.txt。将图片路径写入train.txt和val.txt,这里可以写一个脚本,演示数据比较少,我直接复制,train.txt和val.txt也用同一批数据。
六、修改custom.data
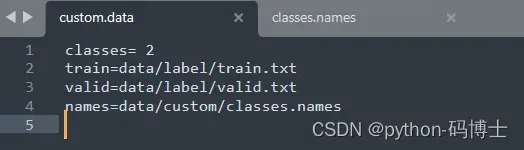
将classes和存放图片路径的.txt文件修改为自己的。
七、训练代码参数的更改
--model_def config/yolov3-custom.cfg # 更改为自己的配置文件
--data_config config/custom.data # 更改为自己的数据
--pretrained_weights weights/darknet53.conv.74 # 用训练好的模型做微调,可加可不加
八、修改数据集路径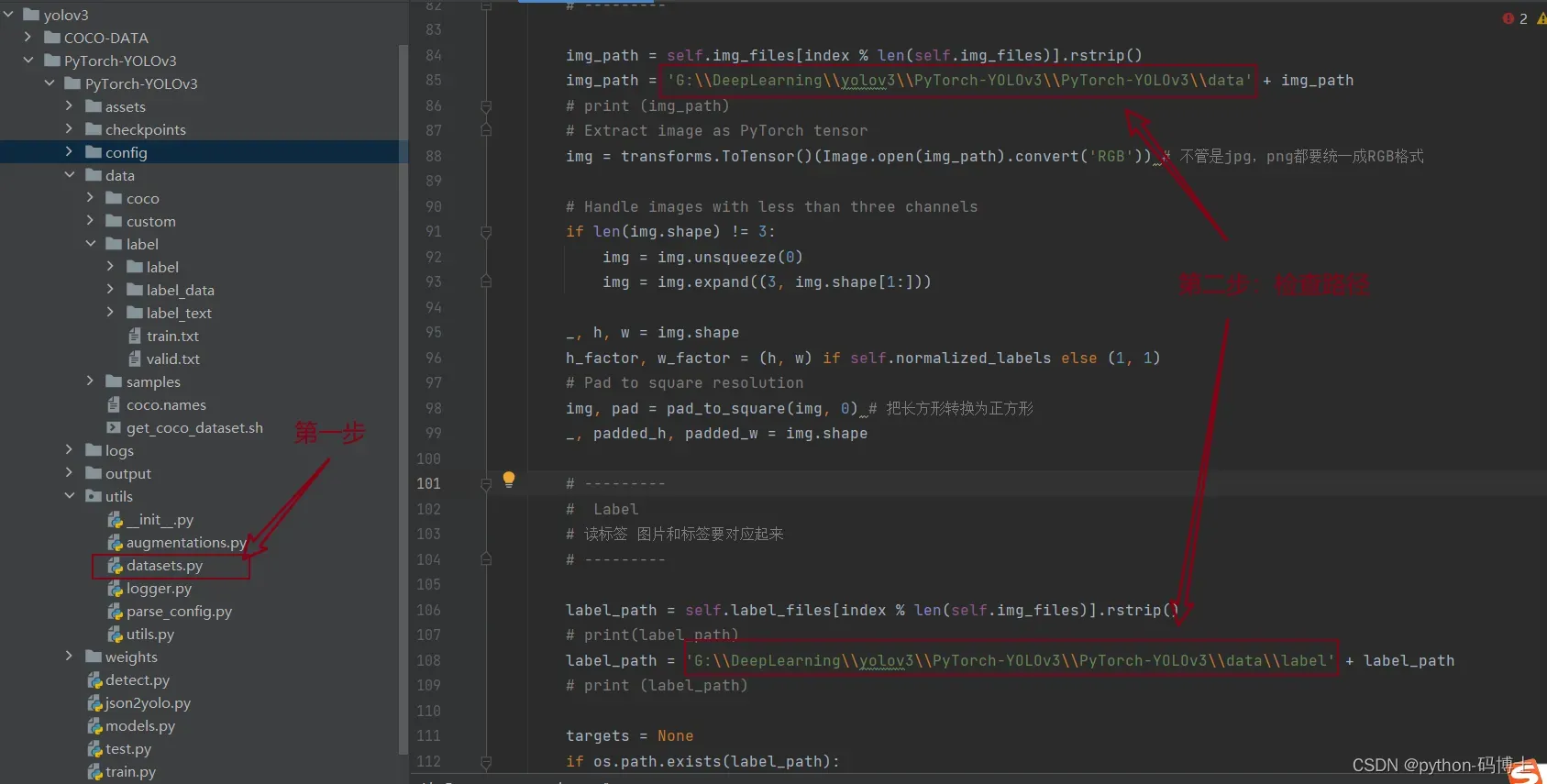
然后进行训练就可以了
九、预测操作
--image_folder data/samples/ # 把需要预测的数据放到这里
--checkpoint_model checkpoints/yolov3_ckpt_100.pth # 训练好模型的路径
--class_path data/custom/class.names # 画图时要把框上的类别显示出来
文章出处登录后可见!