Paper name
Adding Conditional Control to Text-to-Image Diffusion Models
Paper Reading Note
URL: https://arxiv.org/pdf/2302.05543.pdf
代码 URL:https://github.com/lllyasviel/ControlNet
TL;DR
- 提出 ControlNet,通过控制大型图像扩散模型(如 Stable Diffusion)以学习特定任务的输入条件,比如基于输入的 edge/depth 等图片信息,生成与输入文本对应的彩色图片
Introduction
背景
- 由于存在大型文本到图像模型,生成视觉上有吸引力的图像可能只需要用户输入简短的描述性提示。在输入一些文本并获得图像后,可能会自然而然地提出几个问题:
- 这种基于提示的控件是否满足用户的需求?例如,在图像处理中,考虑到许多具有明确问题公式的长期任务,是否可以应用这些大型模型来促进这些特定任务?
- 应该建立什么样的框架来处理各种各样的问题条件和用户控制?
- 在特定任务中,大型模型能否保留从数十亿张图像中获得的优势和能力?
- 为了回答这些问题,调查了各种图像处理应用,并有三个发现:
- 任务特定域中的可用数据规模并不总是像普通图像文本域中的那样大,许多特定问题(例如,物体形状/法线、姿态估计等)的最大数据集大小通常小于 100k,即比 LAION5B 小
倍
- 当使用数据驱动解决方案处理图像处理任务时,大型计算集群并不总是可用的
- 各种图像处理问题有不同形式的问题定义、用户控件或图像标注
- 任务特定域中的可用数据规模并不总是像普通图像文本域中的那样大,许多特定问题(例如,物体形状/法线、姿态估计等)的最大数据集大小通常小于 100k,即比 LAION5B 小
本文方案
- 本文提出 ControlNet,一种端到端的神经网络架构,它控制大型图像扩散模型(如稳 Stable Diffusion)以学习特定任务的输入条件
- ControlNet 将大型扩散模型的权重克隆为“trainable copy”和“locked copy”:
- locked copy 保留了从数十亿张图像中学习到的网络能力
- trainable copy 则在任务特定的数据集上进行训练,以学习条件控制
- 可训练和锁定的神经网络块与称为“zero convolution”的独特类型的卷积层连接,其中卷积权重以学习的方式从零逐渐增长到优化后参数
- ControlNet 将大型扩散模型的权重克隆为“trainable copy”和“locked copy”:
- 对于如下图片,ControlNet 对原始图片生成 Canny edge 图,在生成右边的图片时不需要原始图片,仅基于 Canny edge 图和文本 prompt 作为输入。本文用的 prompt 是固定的: “a high-quality, detailed, and professional image”

Dataset/Algorithm/Model/Experiment Detail
实现方式
ContronNet
- 保留并固定原始大模型参数,在旁侧增加一个模块分支,该分支的参数基于原始模型参数初始化,并在模块前后增加 zero convolution(1×1 卷积,weight 和 bias 由 0 初始化)层
- 这样设计的好处是当 ControlNet 应用于某些神经网络块时,在任何优化之前,它不会对深层神经特征造成任何影响。任何神经网络块的能力、功能和结果质量都得到了完美的保留,任何进一步的优化都将变得与微调一样快
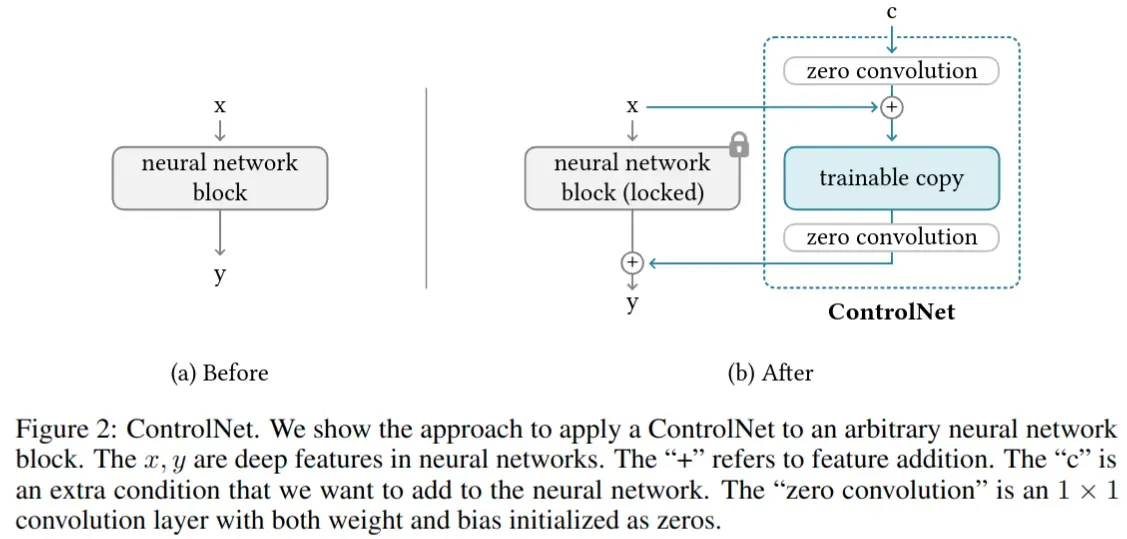
- 这样设计的好处是当 ControlNet 应用于某些神经网络块时,在任何优化之前,它不会对深层神经特征造成任何影响。任何神经网络块的能力、功能和结果质量都得到了完美的保留,任何进一步的优化都将变得与微调一样快
ControlNet in Image Diffusion Model
- 稳定扩散(Stable Diffusion)是一个基于数十亿图像训练的大型文本到图像扩散模型。该模型本质上是一个U-net,具有编码器、中间块和跳跃连接解码器。Stable Diffusion 模型结合 ControlNet 的形式如下
- 其中输入图片会参考 VQ-GAN 的方式由 512×512 预处理到 64×64
- Condition 会通过四层的卷积层(4x4k,2x2s) 同样由 512×512 处理到 64×64
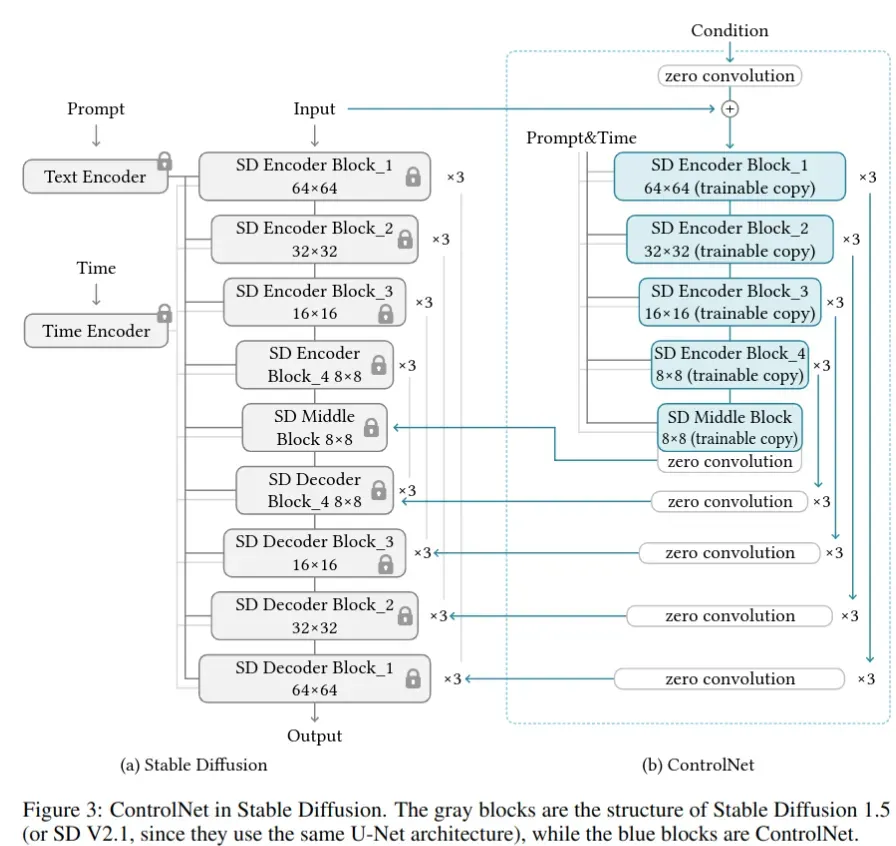
- 由于原始权重被锁定,训练时不需要在原始编码器上进行梯度计算。这可以加快训练速度并节省GPU内存,因为可以避免原始模型上一半的梯度计算。使用ControlNet 训练稳定的扩散模型只需要在每次训练迭代中增加大约 23% 的GPU内存和 34% 的时间(在单个Nvidia A100 PCIE 40G上测试)
training
-
给定图像z0,扩散算法逐渐向图像添加噪声并产生噪声图像zt,其中t是噪声被添加的次数。当t足够大时,图像近似于纯噪声。给定一组条件,包括时间步长t、文本提示ct以及任务特定条件cf,图像扩散算法学习网络θ以预测添加到噪声图像zt的噪声
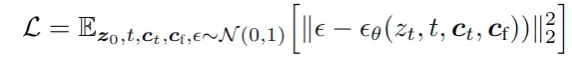
其中L是整个扩散模型的总体学习目标 -
在训练期间,将 50% 的文本 prompt ct 随机替换为空字符串。这有助于 ControlNet 从输入条件图(例如Canny边缘图或人类涂鸦等)中识别语义内容。这主要是因为当提示对于 Stable Diffusion 模型不可见时,编码器倾向于从输入控制映射中学习更多的语义来代替提示
Improved Training
- 讨论改进 ControlNets 训练的几种策略,特别是在计算设备非常有限的极端情况下
- Small-Scale Training:部分中断ControlNet和稳定扩散之间的连接可以加速收敛。即把上图中 ControlNets 和 Stable Diffusion 网络的连接减少,只连接 Middle Block 可以提升训练速度 1.6 倍
- Large-Scale Training:这里,大规模训练指的是既有强大的计算集群(至少8个Nvidia A100 80G或同等),又有大数据集(至少100万个训练图像对)的情况。这通常适用于数据容易获取的任务,例如Canny检测到的边缘图。在这种情况下,由于过度拟合的风险相对较低,可以首先训练 ControlNets 足够多的迭代次数(通常超过50k步),然后解锁稳定扩散的所有权重,并将整个模型作为一个整体进行联合训练
实验结果
实验设置
- prompt 类型
- 无提示:使用空字符串“”作为提示
- 默认提示:由于稳定扩散基本上是用提示训练的,因此空字符串可能是模型的意外输入,如果没有提供提示,SD 倾向于生成随机纹理贴图。更好的设置是使用无意义的提示,如“一张图片”、“一张漂亮的图片”和“一张专业的图片”等。在本文的设置中,使用“专业、详细、高质量的图片”作为默认提示
- 自动提示:为了测试全自动 pipeline 的最先进的最大化质量,还尝试使用自动图像字幕方法(例如,BLIP),使用“默认提示”模式获得的结果生成提示。然后使用生成的提示再次扩散
- 用户提示:用户给出提示。
可视化效果
-
基于 Canny edge 作为 control 输入的效果



-
使用线段作为 control 输入的效果

-
素描作为输入


-
Openpifpaf pose 作为输入

Thoughts
- 主要创新点应该是提出来的 HyperNetwork 设计有节省算力的效果
- 文章中设计的 HyperNetwork 主要作用于 Unet 类型的卷积网络,转换到一些 LLM 的transformer 结构中可能需要一定适配
文章出处登录后可见!
已经登录?立即刷新