目录
卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)又叫卷积网络(Convolutional Network),是一种专门用来处理具有类似网格结构的数据的神经网络。卷积神经网络一词中的卷积是一种特殊的线性运算。卷积网络是指那些至少在网络的一层中使用卷积运算来代替一般的矩阵乘法的神经网络。
卷积神经网络的出现,极大的缓解了全连接神经网络中存在的一个典型的问题:数据的波形被忽视了!众所周知,全连接神经网络在进行数据输入的时候,需要将一个二维或者三维的数据展平为一维的数据。而我们知道在计算机中图形是一个三维的数据,因为需要存储一些类似 RGB 各个通道之间关联性的空间信息,所以三维形状中可能隐藏有值得提取的本质模式。而全连接展平会导致形状的忽视。因此需要利用卷积神经网络来保持形状的不变。
典型应用场景:图像识别、语音识别等。
典型结构如下图所示:
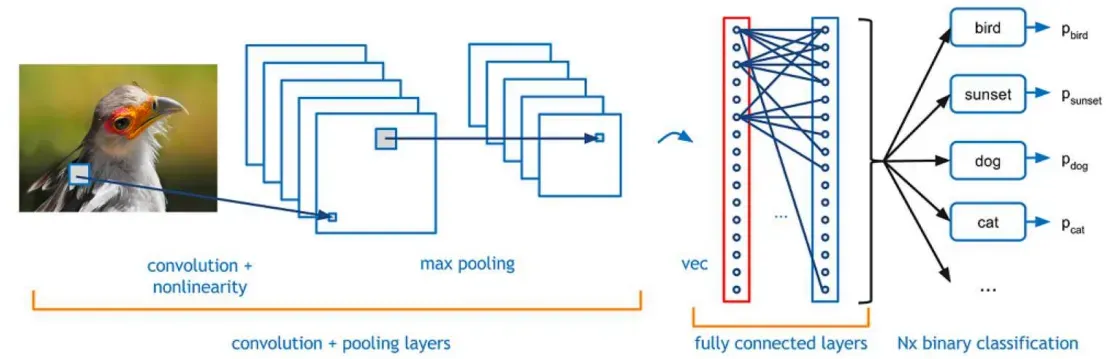
为什么要使用卷积神经网络?
对于计算机视觉来说,每一个图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB三种颜色(不计算透明度),我们以手写识别的数据集MNIST举例,每个图像的是一个长宽均为28,channel(通道数)为1的单色图像,如果使用全连接的网络结构,即,网络中的神经与相邻层上的每个神经元均连接,那就意味着我们的网络有28×28=784个神经元(RGB3色的话还要乘3),hidden层如果使用了15个神经元,需要的参数个数(w和b)就有:28×28×15×10+15+10=117625个,这个数量级到现在为止也是一个很恐怖的数量级,一次反向传播计算量都是巨大的,这还只是一个单色的28像素大小的图片,如果我们使用更大的像素,计算量可想而知。
上面说到传统的网络需要大量的参数,但是这些参数是否重复了呢,例如,我们识别一个人,只要看到他的眼睛,鼻子,嘴,还有脸基本上就知道这个人是谁了,只是用这些局部的特征就能做做判断了,并不需要所有的特征。 另外一点就是我们上面说的可以有效提取了输入图像的平移不变特征,就好像我们看到了这是个眼睛,这个眼睛在左边还是在右边他都是眼睛,这就是平移不变性。并且我们也一般认为两个靠近的物品他俩都有相似的属性。这也是图像本身的特性,这一特性在把NLP中transformer模型迁移到CV领域而产生的swin-transformer这一篇论文中起到了很大的影响力。 我们通过卷积的计算操作来提取图像局部的特征,每一层都会计算出一些局部特征,这些局部特征再汇总到下一层,这样一层一层的传递下去,特征由初级变为高级,最后在通过这些局部的特征对图片进行处理,这样大大提高了计算效率,也提高了准确度。(最后的心得的时候会详细说明每一次卷积提取特征,到底提取的是什么)
神经网络中的各层
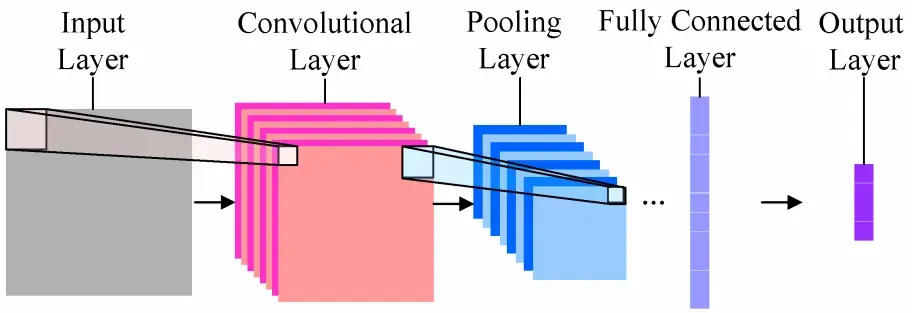
- 输入层(Input Layer):主要是对原始的图像数据进行预处理
- 卷积层(Convolution Layers):可以看作是输入样本和卷积核的内积运算。从前一层提取移位不变特征。即当输入数据是图像的时候,卷积层会以3维(H,W,C)(H为高度,W为宽度,C为channel通道数)数据的形式接收输入数据,并同样以3维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。注:卷积层的输入和输出数据通常又被称为特征图(Feature Map)。卷积层的输入数据称为输入特征图(Input Feature Map),输出数据称为输出特征图(Output Feature Map)。卷积层一般由线性层和激活函数组成。
- 池化层(Pooling Layers):作用是减小卷积层产生的特征图尺寸。将前一层的多个单元的激活组合为一个单元。池化是缩小高、长方向上的空间的运算,通常减小一半。(其实池化层也有提取特征的意义,但其主要目的是减少计算量)
- 全连接层(Fully Connected Layers):收集空间扩散信息(将2维矩阵或多维矩阵拉直,变成上图那样“一列”的向量)
- 输出层(Output Layer):选择类
卷积操作
卷积运算相当于图像处理中的“滤波器运算”。卷积运算会对输入数据应用滤波器(卷积核)(Filter)。
假设,一个初始的图像大小为 J∗K, 同时有 L个通道,如下图所示:
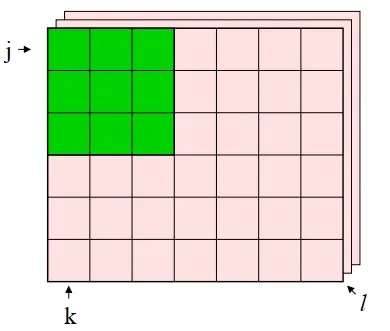
我们应用一个 M∗N 大小的滤波器。图中绿色的格子就是一个 3*3 的滤波器。卷积运算的整个操作为:将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(整个操作也被称为乘积累加运算),然后,将这个结果保存到输出的对应位置。(下文的心得部分,那里有动态图并且也有相应解释)
将计算过程公式化,公式如下:
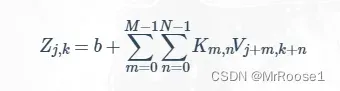
其中 Km,n表示滤波器的 m,n位置的数据,Vj+m,k+n 表示图像的 j+m,k+n位置的数据,b 是偏置项。
新生成的卷积层大小,用公式表示为:(J+1−M)∗(K+1−N)
将计算过程图像化,如下图所示:
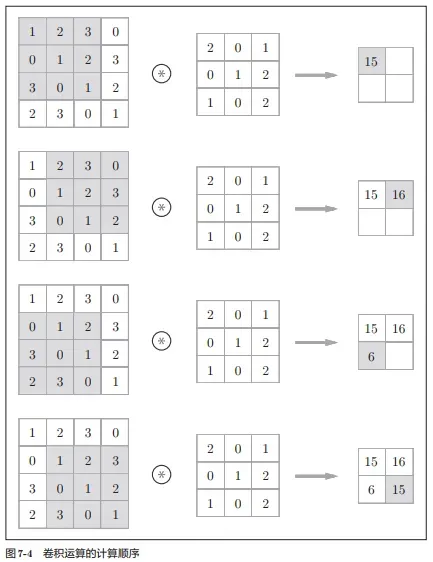
其中,滤波器的参数就是权重(Weights),同时还有有个偏置项(Bias),这个偏置项会被加到滤波器最后的输出上。
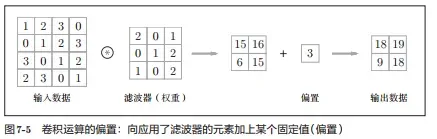
权重共享
我们可以根据上图看到,对一层中的每一个 M×N(M=3,N=3)块输入应用相同的权值,计算卷积层中的下一个隐藏单元,这就是个权重共享(Weight Sharing)的概念。
填充
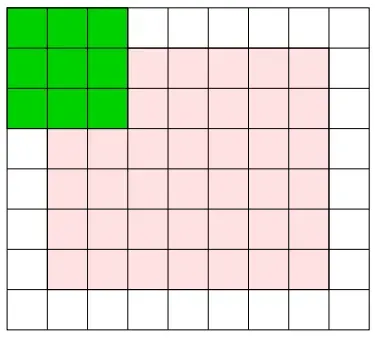
填充(Padding):在进行卷积操作之前,有时候要向周围填入固定的数据,比如用数值 0 进行填充,也叫零填充(Zero Padding)。填充的宽度用字母 P 表示。
应用填充之后,卷积层的输出大小将可以和卷积之前的层一样,如图所示,其中粉色的 6 * 7 的格子是原始的图像尺寸,我们在周围加上一圈数值为 0 的格子,用白色表示:
以步幅 1 (步幅的大小为滤波器每次移动小方格的个数)进行卷积,如下图所示:
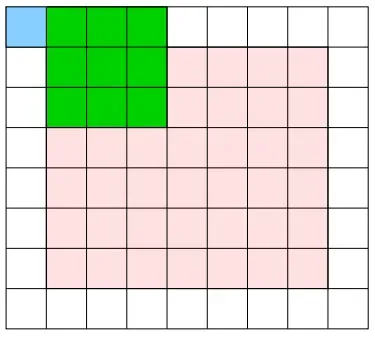
最终我们得到了一个大小为 6 * 7 的蓝色的卷积层,和原始图像的尺寸相同,如下图所示:
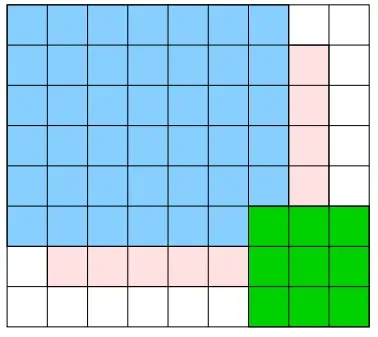
这主要也是为了避免卷积过程中过一个典型的问题:如果每次进行卷积运算都会缩小空间,那么在某个时刻输出大小就有可能变成 1,导致无法再应用卷积运算。为了避免这个情况的出现,就需要使用填充。
新的卷积层尺寸,公式为:(J+2P+1−M)∗(K+2P+1−N)
步幅
步幅(Stribe):应用滤波器间隔的位置称为步幅。在上面的例子中,采用的步幅为 1。
我们可以将步幅改为 2,那么卷积过程就会变成下图所示的:
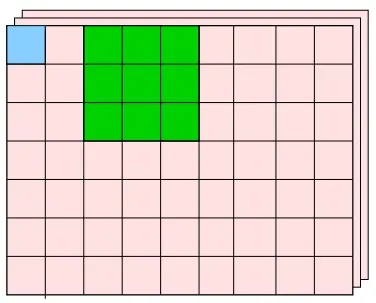
可以看到应用滤波器的窗口的间隔变成了 2 个元素,如下图所示:
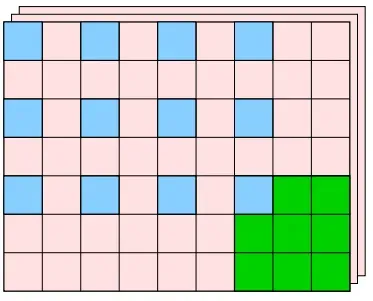
最终,新的一层的尺寸变为一个 3 * 4 的层。用公式表示为(设步长为s):
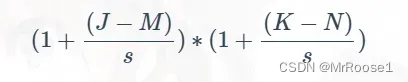
至此,结合卷积、填充、步幅相关的公式,我们可以得出最完整的卷积层尺寸计算公式:
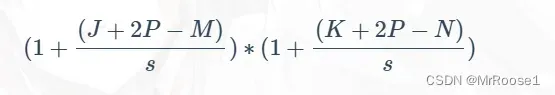
3 维数据的卷积运算
在一开始,虽然我们假设了一个初始的图像大小为 J∗K, 同时有 L 个通道。但是我们讨论的卷积操作一直只在单层上进行的,下面我们就讨论一下在 3 维情况下的卷积运算。
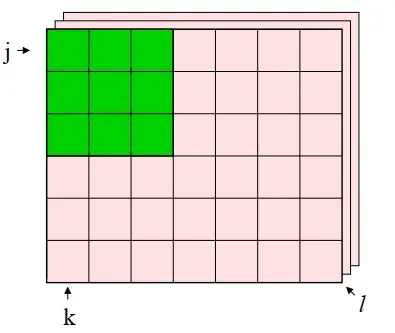
当在通道方向上有多个特征图的时候,会按照通道进行输入数据滤波器的卷积运算,并将结果按照像素的位置,累计相加,从而得到输出。计算步骤如下图所示:
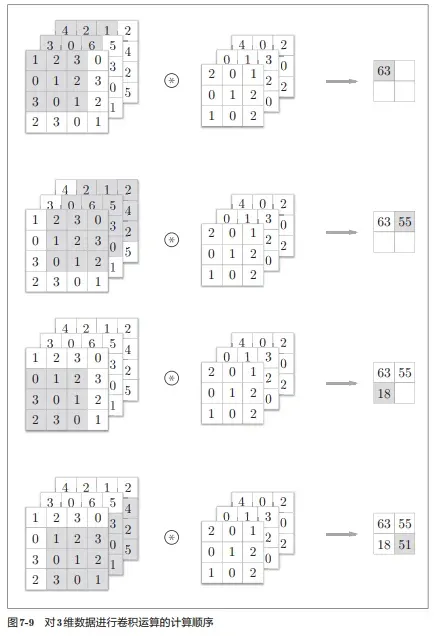
至此,我们的公式可以总结为:
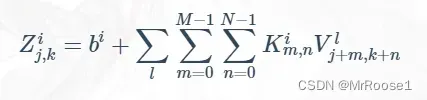
其中 ![]() 表示第 i 个滤波器的 m,n位置的数据,
表示第 i 个滤波器的 m,n位置的数据,![]() 表示图像第 l 层通道的 j+m,k+n 位置的数据,
表示图像第 l 层通道的 j+m,k+n 位置的数据,![]() 是第 i个偏置项。根据之前的权重共享的概念,我们可以知道,每一层通道是共用一个滤波器的相同权重的,同样也共用相同的偏置。
是第 i个偏置项。根据之前的权重共享的概念,我们可以知道,每一层通道是共用一个滤波器的相同权重的,同样也共用相同的偏置。
激活函数
激活函数是非线性神经网络的关键之一。如果不使用激活函数,那么每层节点的输入和上层节点的输出都将会是线性关系。这种网络结构就是原始感知机(Perceptron),其网络的拟合逼近能力十分有限。因此,神经网络特别是深度神经网络只有具有非线性能力才会具有强大的拟合表达能力。而要使网络具有非线性能力,只需要在网络层之间使用非线性函数就可以实现。这就是激活函数的作用和能力。
理论上完美的激活函数应该具有以下特征:
- 非线性。网络上下层间只有线性变换无法使网络具有无限拟合逼近的能力。
- 连续可微。这是使用梯度下降法的前提。
- 在原点处近似线性。这样当权值初始化为接近0的随机值时,网络可以学习的较快,不用可以调节网络的初始值。
- 范围最好不饱和。当有饱和的区间段时,如果网络权重优化进入到该区间内,梯度近似为0,网络的学习就会停止。
- 单调性。具有单调性的激活哈数会使单层网络的误差是凸函数,能够使用其他算法优化。
虽然当前激活函数比较多,但是目前还没有可以同时满足以上这些性质的激活函数。本文从实际角度出发,在输出层,分类问题我们需要考虑两个问题:
- 每个输出信号值在0~1之间;
- 所有输出信号的和为1。
输出层的激活函数
基于这两个要求,本文的模型输出分类中,输出层的激活函数用Softmax函数:
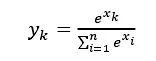
其中![]() 是输出层中的第k个输入信号,分母表示输出层共有n个输出信号(神经元),计算所有输出层中的输入信号的指数和。
是输出层中的第k个输入信号,分母表示输出层共有n个输出信号(神经元),计算所有输出层中的输入信号的指数和。 ![]() 则是第k个神经元的输出。
则是第k个神经元的输出。
卷积层的激活函数
本文在卷积层使用的激活函数为修正线性单元(Rectified Linear Unit,ReLU),其函数解析式为:
![]()
ReLU函数图像如下:
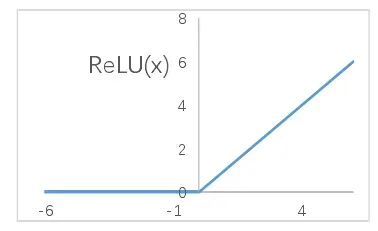
这个函数其实就是一个取最大值函数,注意到该函数并不是全区间可导,但是我们可以取sub-gradient。ReLU虽然简单,但却是近几年的重要成果,具有以下优点:
- 解决了梯度消失的问题(在正区间);
- 计算速度快,只需要判断输入是否大于0;
- 收敛速度远快于Sigmoid和Tanh。
池化
池化(Pooling)是缩小高、长方向上的空间的运算。通过减少卷积层之间的连接,降低运算复杂程度。和卷积操作类似的地方是,池化操作同样要引入一个 Filter,通过不断地滑动,使滤器覆盖的区域进行合并,只保留一个值。
最典型的池化过程叫做最大池化(Max Pooling),如下图所示,这是一个单层的池化:
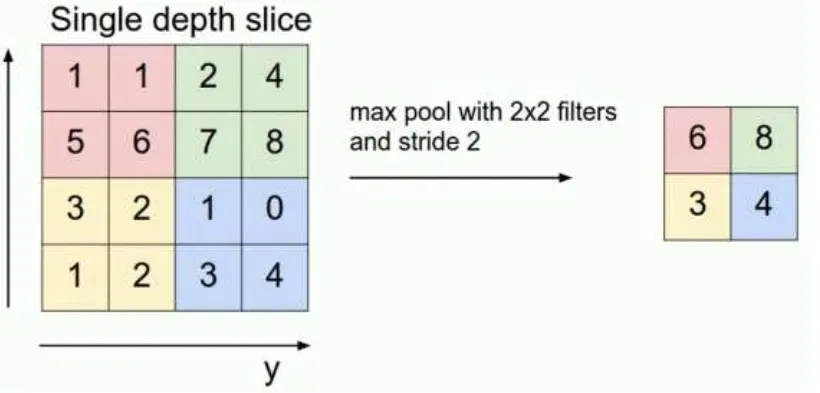
图中所示的步骤是,我们划定一个 2∗2的窗口,找出这个窗口中最大的那个值,作为下一层的数据,这个窗口以步幅 2 进行移动。一般来说,池化的窗口大小会和步幅设定成相同的值。
除了 Max Pooling 之外,还有 Average Pooling/Mean Pooling,即平均池化,是计算目标区域的平均值。在图像识别领域中,主要使用 Max Pooling。
重叠池化
重叠池化(Overlapping Pooling)是 AlexNet 中的一个概念。Overlapping Pooling 的概念和 No-Overlapping Pooling的概念相对。
- Overlapping Pooling:当步幅小于窗口宽度,会使池化窗口产生重叠区域。可以提升预测精度、缓解过拟合。
- No-Overlapping Pooling:当步幅等于窗口宽度,池化窗口没有重叠区域。如上图的展示。又叫一般池化,General Pooling
池化层的特征
- 没有要学习的参数:池化层和卷积层不同,没有要学习的参数。池化层只是从目标区域中取最大值或平均值。
- 通道数不发生变化:经过池化运算,输入数据和输出数据的通道数不会发生变化。即计算是按照通道独立进行的。
- 对微小的位置变化具有鲁棒性(健壮):输入数据发生微小偏差时,池化仍会返回相同的结果。
BN层
批量标准化(Batch Normalization,BN)层与卷积层,以及下文提到的池化层同属网络的一层。通常情况下,为了更好地训练深度学习神经网络,防止像Sigmoid类似的非线性激活函数过早饱和,我们会对输入的数据进行标准化、规范化,使其数据分布类似于正态分布。但在网络的训练过程中,因为每一层都必须学会适应每一个训练步骤的新分布,导致隐含层间的分布是不断变化的,因此会减慢训练过程,这被称为内部协变量转移问题。这也是深层网络通常更耗时的一个原因。
BN层就是规范化网络各层权重分布、解决内部协变转移问题的一种方法,强迫每一层的输入在每一个训练步骤中有大致相同的分布。使用BN层带来的效果是减少超参数,如参数初始化方式、学习率初始值、权重衰减系数、正则方式、Dropout率等的调优时间。因为超参数的设置会严重影响训练结果,不使用BN的网络通常在超参数的调优上回浪费很多时间。另外,使用BN会快速收敛,并且会提高网络泛化能力。BN算法的大致步骤如下:
- 计算各层输入的均值和方差;
- 使用先前计算的批次统计数据对图层输入进行归一化;
- 缩放并移动以获得图层的输出。
公式:
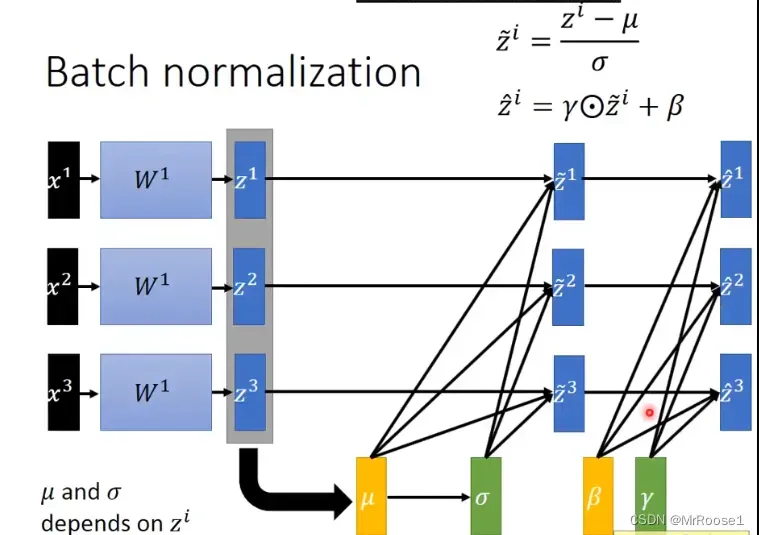
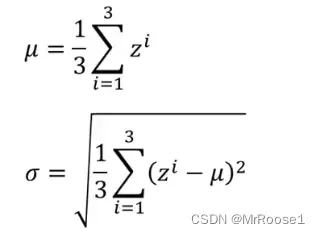
x1,x2,x3是输入,w1是可以认为是一个network,z1,z2,z3是network的输出,BN的作用在不同层之间,换句话就是A层的输出经过BN后再传到B层,以此类推。μ,ρ是随着w1的改变而改变的参数,BN主要也是通过(z-μ)/ρ来实现的。但一般如果我们不想经过BN层后均值和方差变为0和1时,一般会加上γ和β,这两个参数是常量,不随着w1的变化而变化。
全连接层
Full Connnected Layer,一般是作为最后的输出层使用,目的就是输出我们想要的结果,无论是分类,还是回归。
在全连接层之间的所有层中,特征都是使用矩阵表示的,所以再传入全连接层之前还需要对特征进行压扁(一般在pytorch中用view函数实现将多维矩阵拉直成一列向量),将他这些特征变成一维的向量,如果要进行多分类的话,就是用sofmax作为输出,如果要是回归的话就直接使用linear即可。
神经网络的训练
神经网络前向传递以及反向传播梯度更新的完整过程:
神经网络各层最开始的参数(权重:W,b等)都是随机的矩阵。输入的图像(RGB3个通道的矩阵)进入模型后由于刚开始参数(权重)是随机的,因此输出的特征图(多通道的矩阵)也会是随机的。导致前向传递(经历了各层的各种计算后)后的输出特征图(多通道的矩阵)也都是随机矩阵。这时候需要将输出的矩阵和标签(label)的矩阵进行损失(loss)的计算。将loss的值(每一层的参数的loss是不同的)传回各层中来更新参数。这就是完整的一次前向传递及反向传播梯度更新。
loss的计算方法:
在网易云课堂中,找吴恩达老师的《深度学习工程师》这门课的第一章《神经网络和深度学习》的第63节课【3.10(选修)直观理解反向传播】。跟着学就可以。
误差更新方法
和深度前馈网络相同,神经网络中的参数训练也采用误差的反向传播算法。我们知道在全连接层中的更新方法是根据链式法则从上到下的逐层更新参数。那么卷积层和池化层是如何更新的呢?就是将卷积层和池化层转变成全连接层的形式来看。
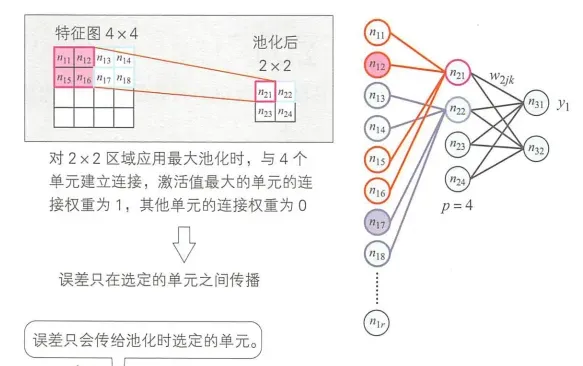
如下图所示是池化层的误差传播。我们假设红色边框区域中的最大值为 n12,那么误差就只在 n12 和 n21 之间传播,即只有这一条连接权重 w21 为 1, 其他红色区域的连接权重为 0。对于蓝色区域也是同样的处理办法。
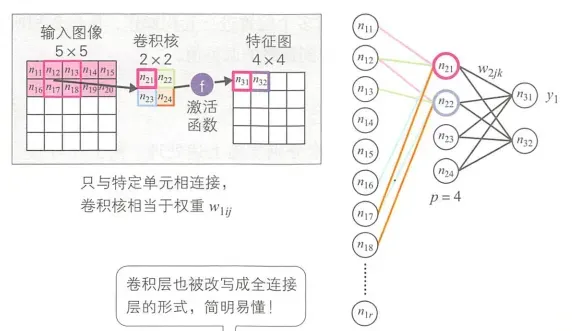
如下图所示是卷积层的误差传播。卷积层要看成只与特定单元相连接的全连接层。卷积核就相当于权重。卷积核的调整和深度前馈网络相同,也是从上层的连接权重开始逐层调整。
参数的设定方法
在构建和训练卷积神经网络的过程中,有非常多的参数需要设置,其中一部分是神经网络本身的参数,另一部分只与训练有关的参数。
与神经网络相关的主要参数如下:
- 卷积层的卷积核大小、卷积核个数
- 激活函数的种类
- 池化方法的种类
- 网络的层结构(卷积层的个数和全连接层的个数)
- Dropout 的概率
- 有无预处理
- 有无归一化
与训练有关的参数如下:
- Mini-Batch的大小
- 学习率
- 迭代次数
- 有无预训练
参数的影响力对比
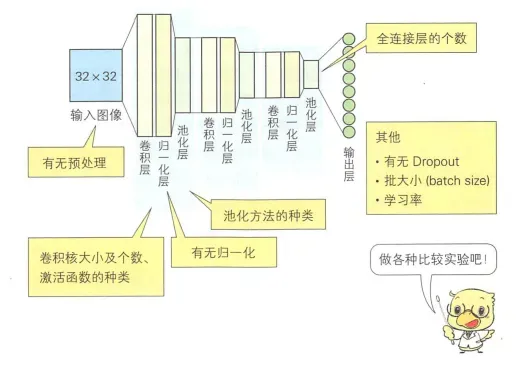
通常在构建和训练神经网络的时候,我们需要选择这些参数的最优组合,但是因为参数的数量过多,往往我们只能根据经验来选择。但是实际上有的参数对神经网络影响比较小,有的影响比较大。我们可以优先调整影响比较大的参数,再调整影响比较小的参数。假设我们有一个如下图所示的神经网络,应用 CIFAR-10 数据集进行训练,观察各个参数的影响。
参数的比较结果如下图所示:
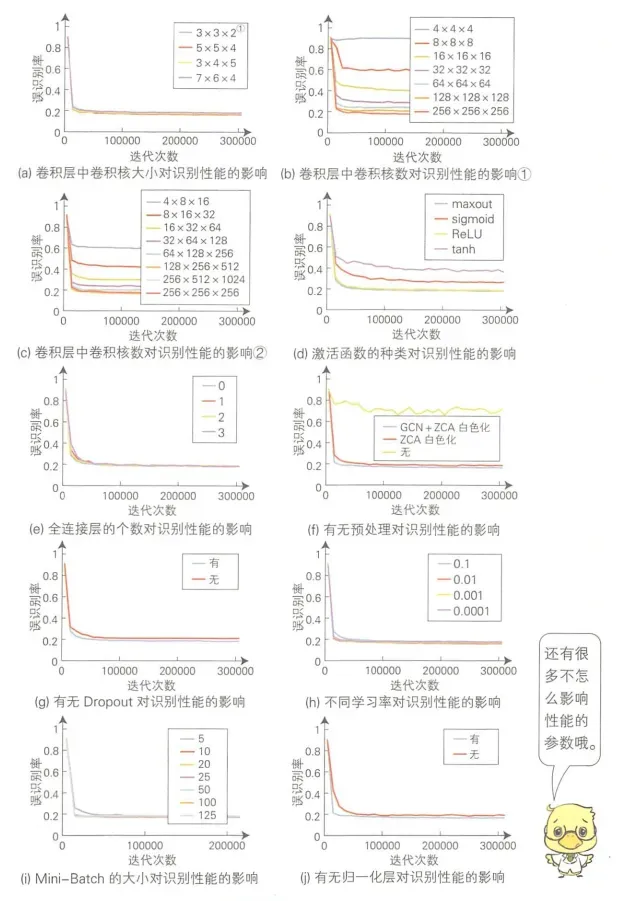
从图中可以看出,卷积层的卷积核个数、激活函数的种类和输入图像的预处理对模型存在较大的影响,应该首先确定这些重要参数。其他的参数影响相对较小,只需要在设定好重要参数之后进行微调就可以。但是要注意,对于不同的数据集和问题,重要的参数情况可能有变化,需要根据实际问题和研究,这个例子只是参考作用。
动手实践(Pytorch框架)
Pytorch的中文文档:
https://pytorch.apachecn.org/#/
Pytorch之Tensorboard(可视化):
(1条消息) Pytorch之Tensorboard(可视化)_MrRoose1的博客-CSDN博客
Pytorch之Transforms(数据预处理):
(1条消息) Pytorch之Transforms(数据预处理)_MrRoose1的博客-CSDN博客
Pytorch之Dataloader(数据集下载及分批次导入):
(1条消息) Pytorch之Dataloader(数据集下载及分批次导入)_MrRoose1的博客-CSDN博客
*Pytorch之Base_calcuate(卷积层,池化层,激活函数,全连接层,顺序容器(Sequential)):
(1条消息) Pytorch之Base_calcuate(卷积层,池化层,激活函数,全连接层,顺序容器(Sequential))_MrRoose1的博客-CSDN博客
Pytorch之loss(损失函数):
(1条消息) Pytorch之loss(损失函数)_MrRoose1的博客-CSDN博客_pytorch实现loss
Pytorch之Optim(优化器):
(1条消息) Pytorch之Optim(优化器)_MrRoose1的博客-CSDN博客
Pytorch之Save&Load(保存和加载模型):
(1条消息) Pytorch之Save&Load(保存和加载模型)_MrRoose1的博客-CSDN博客
Pytorch之训练的完整过程(最终篇):
(1条消息) Pytorch之训练的完整过程(最终篇)_MrRoose1的博客-CSDN博客_pytorch 训练过程
也可以跟着B站李沐老师来动手实践学习。
典型的CNN
LeNet
原理
LeNet 是在 1998 年提出的进行手写数字识别的网络。具有连续的卷积层和池化层(准确的讲是只抽取元素的子采样层),最后经全连接层输出结果。基本结构如下:
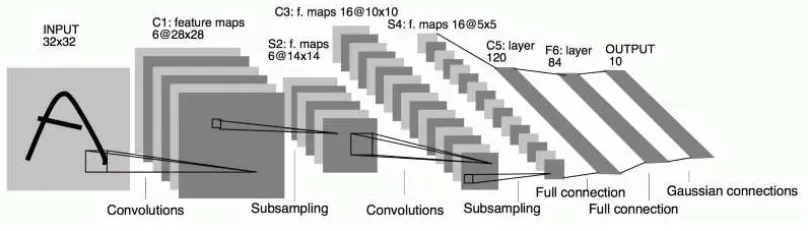
- C1:第一个卷积层的 5×5 的窗口从原始的 32×32 的图像中提取出 28×28 的特征数组。有6个卷积核,提取6种局部特征。
- S2:然后再进行子抽样,将其大小减半为14×14,降低网络训练参数及模型的过拟合程度。
- C3:第二个卷积层使用另一个 5×5 的窗口提取一个 10×10 的特征数组,使用了16个卷积核。
- S4:第二个子采样层将其简化为 5×5。
- C5、F6:这些激活然后通过两个全连接层进入对应数字 ‘0’ 到 ‘9’ 的10个输出单元。
和现在的 CNN 相比,LeNet 有几个不同点:
- 激活函数:LeNet中使用 Sigmoid 函数,而现在的 CNN 中主要使用 ReLU 函数。
- 池化/子采样:LeNet 中使用子采样缩小中间数据的大小,而现在的 CNN 中 Max Pooling 是主流。
Pytorch 实现
import torch.nn as nn
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 这里论文上写的是conv,官方教程用了线性层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = LeNet5()
print(net)AlexNet
原理
AlexNet 是一个引发深度学习热潮的导火索。基本结构如下:
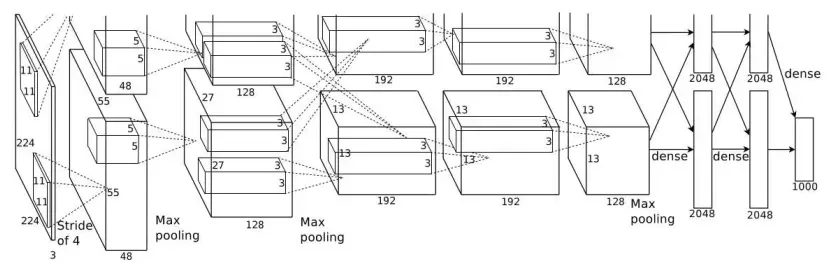
AlexNet 叠有多个卷积层和池化层,最后经由全连接层输出:
- 5 个卷积层和 3 个全连接层
- 利用重叠步幅的最大池化层
- 1000 个类的 Softmax
- 两个只在特定层进行交互的 GPU。上图中就是利用了两个 GPU,在第二个 Max Pooling 层进行交互,一直到最后进行输出两个 GPU 一直是在并行运算。
AlexNet 虽然在结构上和 LeNet 没有很大的不同,但是也有一些细节上的差异:
- AlexNet 的激活函数使用的是 ReLU
- 使用进行局部正规化的 LRN(Local Response Normalization)层
- 使用 Dropout
Pytorch 实现
因为 AlexNet 是 Pytorch 官方实现的,所以直接从 torchvision 包中调用
import torchvision
model = torchvision.models.alexnet(pretrained=False) #我们不下载预训练权重
print(model)各个神经网络对比
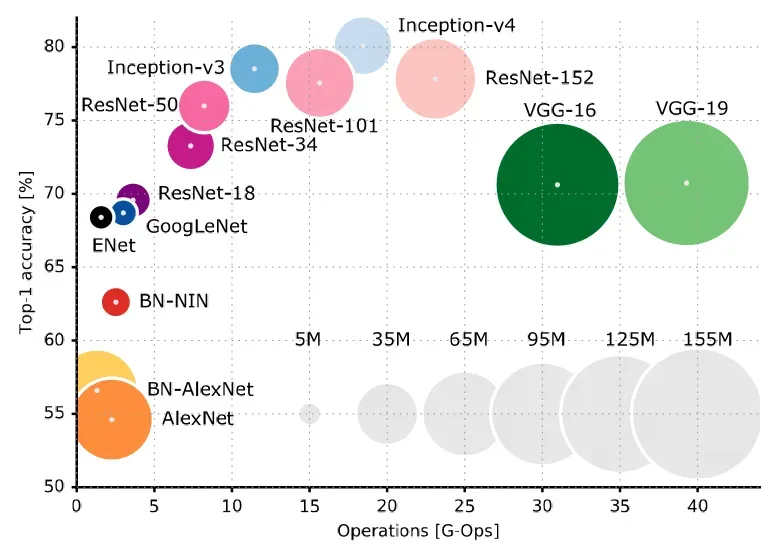
这是一个准确率和计算量之间的对比。横轴是数据量,纵轴是准确率。可以在一定程度上指导我们进行网络的选择!
*心得部分
1)很多人在介绍卷积神经网络的时候,包括很多书籍,比如《python深度学习》都想用一个形象的例子来介绍卷积神经网络的作用是提取图像的特征。以《python深度学习》为例,
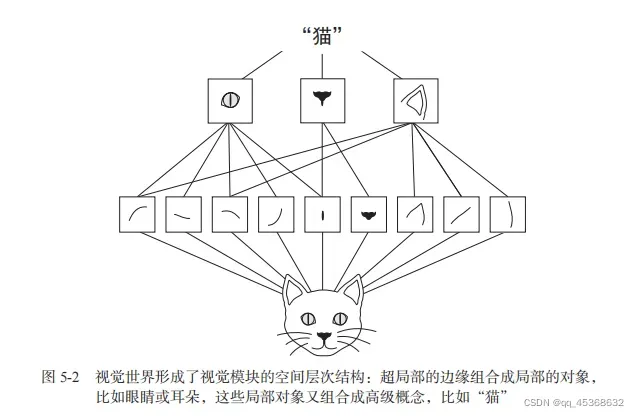
大家都会说,第一层卷积是为了提取一些线条和曲线的特征,再通过一层卷积提取到高级的特征,比如眼睛,鼻子,猫耳朵等。但其实这样的形容是不准确的,换句话来说只能是为了方便感性的了解,所以才举了一个特殊的例子。因为在卷积神经网络中,每一层提取的特征是什么,其实每一次都是不同的。因为每一个模型不同卷积层的参数(W,a,b等)的初始化都是随机的。因此我们不确定每次的第一层都是提取线条和曲线,还有可能是图片的其他语义特征只不过我们看不懂罢了,也有可能是我们没办法理解的数字矩阵。
还有一点可以解释为什么举这个例子不够准确,是因为我们都知道卷积神经网络是越卷积,图片(特征图)会越来越小,而通道数会越来越多。并且特征值的通道数和卷积核的个数是相等的。如果我们是要输入一张彩色图片,例如(256x256x3)这个图片的分辨率是256×256的。3代表彩色通道RGB中的R,G,B三个通道。然后第一次卷积的时候,假如卷积核是3×3的。但就算写的是3×3的卷积核,但实际上此卷积核只是分辨率是3×3,但其也有深度。她的深度是与要卷积的图片/特征图的通道数相同。比如第一次卷积的时候,通道数就是3,因此卷积核的深度也是3。由于特征图的通道数和卷积核的个数有关,因此如果第一次卷积的时候用了6个卷积核,所以通过第一次卷积后的特征图为254x254x6。然后假设第二次卷积的时候,卷积核是5×5。由于被卷积的特征图有6个通道,因此第二次卷积的卷积核分辨率是5×5,深度(通道数)为6。也就是说,随着卷积的次数的增加,卷积核的深度会随着特征图的通道数的增加而增加。我们又知道随着卷积的次数的增加,提取的特征也会越来越高级且越来越小。并且以第二次卷积为例,如果用12个分辨率为5×5的卷积核,经过第二次卷积后的特征图为250x250x12。具体是怎么计算的呢。(可以参考吴恩达老师的深度学习这门课的卷积神经网络这一节课)或者看图:

其中绿色部分是被卷积的特征图的一个通道矩阵,黄色部分(每个小方格下面的数字,第一行为1,0,1,第二行为0,1,0,第三行为1,0,1)为卷积核(分辨率为3×3),右侧粉色部分是卷积后的单通道特征图矩阵。回归刚刚的例子,第二次卷积的时候,被卷积的特征图分辨率为254×254,有6个通道,因此第二次卷积中的12个卷积核中的每一个卷积核都需要类似于上图的计算6次,每一个卷积核都需要计算出6个单通道特征图矩阵,然后根据像素的位置进行点对点的累计求和,把6张图加到1张图上。又因为一共有12个卷积核,所以通过第二次卷积,特征图才会有12个通道。如此看来,随着卷积的层次的加深,每一个卷积核求出的特征图就会和很多参数相关联,并且多通道的累加求和次数也会变多。因此特征图也就更加高级。但会不会就一定是眼睛鼻子耳朵呢,这个就不一定了,毕竟参数权重是随机的,虽然会有loss回归,但依旧在不同的训练过程中,每一层的特征提取都不一样。但有一点可以肯定的是,每一次卷积,提取的特征都会更加高级。
2)建议的学习顺序:回顾我自学CV的路程其实走了不少弯路,我总结了一下我认为比较正确的路线(只是建议,但并不代表适合所有人):
- 学会python的基础语法,建议看MOOC里嵩天老师(北京理工大学)的Python基础语法课,python就是一个语言工具,很容易上手,我们也不需要把python的全部函数都会用,就把常用的基本语法学会就ok,剩下的函数我们会在每一次的项目中慢慢积累(这门课我个人觉得够了)
- 学会配置运行环境(Anaconda):可以学习这篇文章(1条消息) Anaconda安装+环境管理+包管理+实际演练例子(全网最详细)_MrRoose1的博客-CSDN博客_anaconda安装(1条消息) Pycharm中如何配置已有的环境_MrRoose1的博客-CSDN博客_怎么配置pycharm环境
- 学习机器学习/深度学习的基本知识:通过阅读这篇文章及网易云课堂中吴恩达老师的《机器学习》《深度学习工程师》这两门课来掌握知识点。注意:吴恩达老师的课注重于理论知识公式推导,所以我建议先读我这篇文章,对神经网络有了一定的了解后再听他的课会有很多其他的思考和收获。这两门课先听《机器学习》中的线性回归部分,正则化部分,神经网络参数的反向传播算法部分(当然了,有时间的话可以全看完)。再听《深度学习工程师》的全部内容。我也不是说《机器学习》中其他部分不重要,其实都很重要,只不过对于新手来说,这样学效率能高一点(主要看人)。
- (其实是3的续说)我想简单介绍下我眼中的各个深度学习大佬的教学视频。 吴恩达老师:我在网易云课堂看课,老师的上课方式是全英文,但好在有字幕。讲课风格偏基础理论和公式推导。他想教你是如何一步步的实现神经网络的前向传播和反向传播梯度更新的全过程。李宏毅老师:我在B站看课,老师的台腔严重,时不时蹦出几个英文,且几乎没有字幕,我跟他学习的是GAN网络。讲的很好,就是听起来不舒服。李沐老师:我在B站看他的课,这个老师是上课方式最好的,几乎全程中文且视频有字幕。他的跟读论文这门课很不错。并且这个老师的讲课风格和吴恩达老师很互补,这个老师更偏向于实践。他会有实践课,很适合新手学习如何写代码。
- 学会了基本的机器学习和深度学习知识点后要开始学习pytorch和tensorflow,keras等框架,pytorch中文文档:https://pytorch.apachecn.org/#/ Tensorflow和Keras我是通过读一本书叫《Python深度学习》来学习的。这本书的特点是偏向实践,会根据实战来教你深度学习。

- 然后就需要学会使用Pycharm调试工具,因为我们在遇到新的项目的时候难免会使用别人的开源代码作为基础模型,如果模型过于新颖会出现全网几乎没有代码解读的情况,就只能我们自己Debug来自己一点点读懂代码结构(我就是这么学习的CycleGAN,当然这个模型也挺老的,但是通过Debug学习框架后,会记得比较牢固也能更加理解论文和实践之间的关系)可以跟着这篇文章来学习Pycharm的调试:(1条消息) Pycharm调试Debug篇(详细)_MrRoose1的博客-CSDN博客_pycharm 调试
- 到了最后就需要多做项目,通过项目来丰富自己的模型和知识体系了。
最后我想说一句:学习无捷径,本科的课程不会教这些的,都要靠自学,合理运用好B站,MOOC,网易云课堂,CSDN,知乎,Github我们就是王者,哈哈哈。一起加油吧。不知不觉码字码到了凌晨2点了,唉睡觉了睡觉了。
文章出处登录后可见!