目录
一、均方误差损失函数(The Mean-Squared Loss)
2、交叉熵损失函数(The Cross-Entropy Loss)
前言
损失函数,作为任何神经网络的关键成分之一,它定义了如何衡量当前模型输出与目标输出的差距。而模型学习时所需的权重参数也是通过最小化损失函数的结果来确定和进行调整的。通常情况下,我们将从一下几个损失函数中进行选择:
- 均方误差(MSE):通过取数据集的预测值和实际值之间的平方差的平均值来计算MSE。这种损失函数通常用于回归问题,其中的目标是预测连续的数值输出。
- 交叉熵(cross-entropy loss):经常用于分类任务,其中目标是预测输入属于某个类别的概率。通过取正确类别的预测概率的对数的负和来计算交叉熵损失。
- 铰链损失函数(hinge loss):铰链损失是机器学习中用于二元分类问题的一个数学函数。它也被称为最大裕度损失或SVM(支持向量机)损失。铰链损失测量二元分类模型的预测输出和实际输出之间的差异。
以及根据需要选择的特殊损失函数。
当给定一个特定的模型,每个损失函数都有其特殊的性质,这让训练结果的评价方式变得多种多样——例如,铰链损失在处理分类问题时具有最大裕度属性;当MSE损失函数与线性回归问题结合使用时,均方误差保证了结果为凸函数(用于后向传递)。
在这篇文章中,将主要讨论三种常见的损失函数:均方(MSE)损失、交叉熵损失和铰链损失。这些损失函数是在传统机器学习和深度学习模型中最常用的函数,所以本文清楚地讨论了每一个损失函数模型背后的基本理论,以及何时选择使用它们。
一、均方误差损失函数(The Mean-Squared Loss)
首先,定义一个具有两个维度输入的线性回归模型:
该模型的输入为特征向量(feature vector)。对于该模型的MSE均方误差的计算规则如下:
- 遍历用于训练的
个不同的训练示例(training examples)
- 对于其中每一个训练示例,计算其网络的输出向量
与目标标签向量
的平方误差
- 最后将计算的
1.1、从线性回归模型导出均方误差函数
在线性回归假设下,真正的标签向量(labels vector)将是特征向量的一个线性函数,同时叠加有一定的噪声附加项
。总的来说,该假设下
的表达式为:
在此处,有必要对噪声的分布做一个约束,即此处的 是一个满足零均值、具有单位方差的高斯噪声。具体地说,它将满足以下两种性质:
- 其期望为理想输出:
,其中
表示期望;
- 其方差为单位误差:
,其中
表示方差;
由于噪声的加入,当线性回归模型的输入为 时,模型的输出不一定为
,其输出将变为一个满足高斯分布的、不确定的值。
在受到高斯噪声影响的条件下,当输入已知为 时,观察到输出为
的概率为:
纵观训练集中的组不同的训练示例,结合上述推导出的条件概率,可以得到这
组训练示例与其输入数据之间的似然函数(也即:当输入为特征向量
时,有多大可能性能得到现在观察到的输出
):
为了方便运算,将上述的原始似然函数用对数进行化简。由于对数函数是一个单调递增的函数,因此使用对数不会影响其极值的分布和极点的位置。
上述的式子即为线性回归条件下的极大似然估计量,将它最大化的意义为:此时选择的参数 有最大的可能性、利用线性回归模型,从特征向量
得到标签向量
。不得不提的是,在定义损失函数时,通常将此函数描述为度量现有模型与理想模型的差距,因此损失函数通常被优化至最小值,即上述等式的相反数:
1.2、均方误差函数的使用场景
从上述讨论可知,如果你的输出是输入的实数函数,同时叠加有一定量的高斯噪声、具有恒定的均值和方差,那么推荐使用MSE损失函数。如果这些假设不成立(例如在分类的背景下),MSE损失可能不是最好的选择。
1.3、均方误差函数的一些讨论
在接触均方误差函数的时候,我将其理解为:评估当前模型输出 与得到的理想标签向量
之间的范式距离。那么既然如此,为何不选用差距的更高次方进行评估(例如4次方、6次方等高阶的偶数次方)?这种加剧惩罚的做法不应该给模型带来更快的逼近速度?
2、交叉熵损失函数(The Cross-Entropy Loss)
在线性回归模型中,模型的输出可以为任意取值,但在使用神经网络处理分类问题时,这种无约束的输出将不具有特定的物理含义。我们希望回归问题的模型输出 为一个总和为1的标签向量,其中
表示该输入被分类为每一个标签的可能性大小。
softmax运算[1]就提供了一种转换方式,它获取一个向量并将其映射为概率。softmax回归适用于分类问题,它使用了softmax运算中输出类别的概率分布。而交叉熵是一个衡量两个概率分布之间差异的很好的度量,它测量给定模型编码数据所需的比特数,其计算表达式如下:
2.1、从softmax运算到交叉熵
首先,介绍将任意的输出向量映射为概率的softmax函数:
softmax函数可以被视为进行了两步操作:
- 第一步:使用指数函数将输入的向量映射为正数(指数函数的性质,其输出均为正数;
- 第二步:对得到的正数做归一化,将其约束为符合概率定义的值。同时,由于指数函数为单调递增函数,并且具有良好的可导性。(可导性在反向传递时至关重要)
简单来说,softmax函数给出了一个向量 ,我们可以将其视为“对给定任意输入
,该输入被分类为每一个标签的可能性大小”。在理解了分类性质的神经网络的输出的基础上,分类器意图达到的最佳效果是:针对特征向量的第
个输入,当模型给出的预测概率为:
时,与其分类标签完全一致,基于此思想,我们定义交叉熵:
2.2、信息论视角中的交叉熵
交叉熵损失可以通过信息论来解释。在信息论中,Kullback-Leibler(KL)散度衡量两种概率分布的“不同”程度。我们可以将我们的分类问题视为具有两种不同的概率分布:
- 第一,我们实际标签的分布,其中所有的概率大小都集中在正确的标签上,而其余的标签上没有概率;
- 第二,我们正在训练的神经网络所输出的分布,其中概率的大小通过softmax函数改变原始输出的标签向量给出。
在信息论中,KL熵定义为:
需要指出的是,作为分类问题“正确答案”的标签向量通常使用独热编码,独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。
比如,若现在有一个关于性别的分类问题,将1000个输入分类为三个类别:{ 男、女、武装直升机},则对应的标签向量满足如下形式:{ = “男”}=(1,0,0)、{
= “女”}=(0,1,0)、{
= “武装直升机”}=(0,0,1)
基于此事实,我们考察式中的第一项:,当
为0或为1时,其取值始终为0.因此,在分类问题中上述的式子自然可以改写为:
在概率论视角下,可以将最小化交叉熵损失的任务解释为最小化上述两个分布之间的KL熵。例如,许多数据集仅被部分标记或具有分类噪声(即偶尔不正确),如果我们可以概率地将标签分配给数据集的未标记部分,或者将不正确的标签解释为从概率噪声分布中采样,那么我们仍然可以应用最小化KL熵的想法,尽管我们的基本实际分布将不再将所有概率质量集中在单个标签上。
3、铰链损失函数(The Hinge Loss)
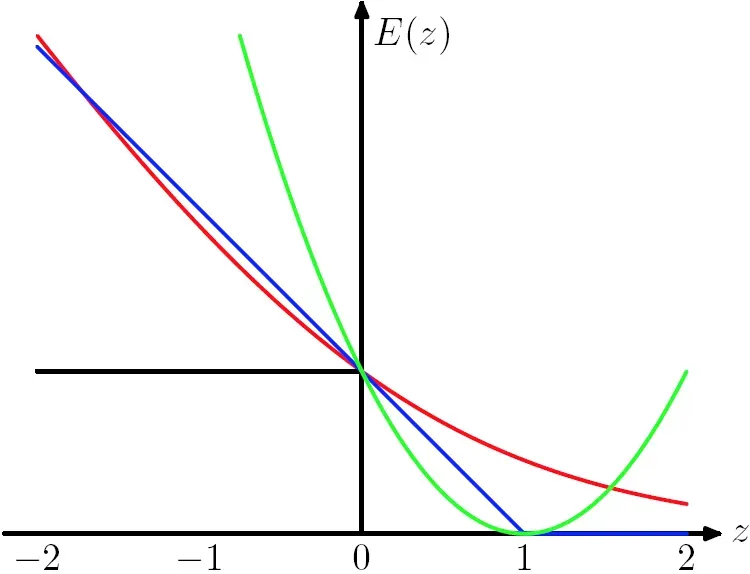
铰链损失函数(The Hinge Loss)又称为合页损失函数,其典型的图像为:

对于铰链损失函数的一个简单理解为:当分类神经网络的输出概率大与某个正确率阈值时,将不产生损失;反之,依据其与正确答案的偏离程度产生相应的线性损失。其计算表达式为:
式中,第一项是损失,第二项是正则化项。这个公式就是说 大于1时loss为0, 否则loss为
。因此,铰链损失函数不仅要分类正确,而且置信度足够高的时候,损失才为0,对学习有更高的要求。
文章出处登录后可见!