需要源码和数据集请点赞关注收藏后评论区留言私信~~~
隐马尔可夫模型(HMM)是关于时序的概率模型,它可用于标注等问题中
基本思想
假设一个盒子里可以装两个骰子,骰子的种类有四面的和六面的两种。现在进行猜骰子实验,该实验由实验者和分析者完成。
实验者每次随机从盒子中取出一个骰子,然后补入一个另外种类的骰子。实验者记录下每次实验后盒子中不同种类骰子的数量,可得到一个盒子状态的序列。
实验者在每次实验后掷一次骰子,并将两个骰子的点数之和告诉他。于是分析者将得到一个数字序列,称为观察序列。
用盒子中四面骰子的数量来标记盒子的状态:若盒子中有k个四面骰子,则称系统处于状态k。显然盒子状态的取值空间为I={0,1,2}。
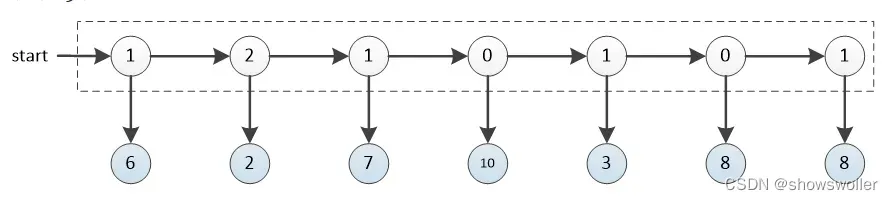
实验者在实验中能抓出什么骰子只与当前盒子的状态有关,而与盒子以前的状态无关。具有这种特性的序列,被称为具有马尔可夫性。
盒子状态的变化可以由所谓的初始概率和转移概率来确定。
初始概率是指盒子最初处于什么状态的概率。盒子可能出现的状态有0、1、2三种,假设两种骰子随机等概放入,那么三种状态出现的概率分别为0.25、0.5、0.25,用一个向量π=(π_0,π_1,π_2)=(0.25,0.5,0.25)来表示,称此向量为初始状态概率向量。
一步转移概率矩阵:
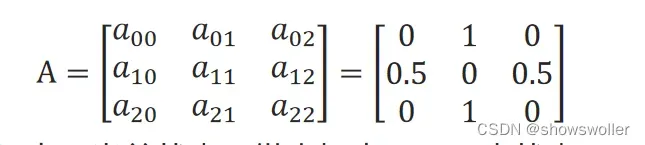
矩阵的横坐标表示当前状态,纵坐标表示下一步状态。 对分析者不可见的状态序列可以认为是由π和A依概率产生的。
分析者见到的观测值又是由状态值依据所谓的观测概率(或称为发射概率)产生的。
第1个状态为1,说明盒子中有一个四面的骰子和六面的骰子。此时,能掷出的点数分别为2、3、4、5、6、7、8、9、10共9个。用b_1(2)表示在状态1时观测到点数2的观测概率,可知:b_2(2)=1/4×1/6=1/24。
计算出所有观测概率,并写成矩阵形式,可得到观测概率矩阵:

可见,隐马尔可夫模型是由π、A以及B依概率确定。π和A决定状态序列,B决定观测序列。记隐马尔可夫模型为λ,λ可以由三元符号表示,即:
λ=(A,B,π)
隐马尔可夫模型在实际应用中,一般有三种问题:
1.概率计算问题
给定模型λ=(A,B,π)和观测序列O={o_1,o_2,…,o_T},计算在模型λ下观测序列O出现的概率P(O|λ)。
可以通过穷举状态序列的方法来计算指定观测序列的概率。一般采用用时较少的前向-后向算法(forward-backward algorithm)来计算。
2.学习问题
估计出隐马尔可夫模型的参数λ=(A,B,π)的问题是学习问题。隐马尔可夫模型的学习分为监督学习和无监督学习。监督学习的训练样本包含有观测序列和状态序列,无监督学习的训练样本只含有观测序列。
3.预测问题,也称为解码(decoding)问题
已知观测序列O={o_1,o_2,…,o_T}和模型λ=(A,B,π),求使条件概率P(Q|O)最大的状态序列Q={q_1,q_2,…,q_T},即给定观测序列,求最有可能的状态序列。
hmmlearn隐马尔可夫模型扩展库曾经是scikit-learn项目的一部分,现已独立成单独的Python扩展库。在Anaconda环境中,可以用“conda install hmmlearn”命令直接安装。
hmmlearn实现了三种常用的观测概率分布的隐马尔可夫模型:多项式分布、高斯分布和高斯混合分布隐马尔可夫模型。 多项式分布隐马尔可夫模型假定观测概率b_i(j)符合多项式分布。 高斯分布隐马尔可夫模型假定观测概率b_i(j)服从高斯分布。 高斯混合分布隐马尔可夫模型假定观测概率b_i(j)服务多个叠加的高斯分布。
中文分词应用示例
自然语言处理领域的很多问题都是序列标注问题。中文分词是将中文句子分解成有独立含义的字或词,如“我爱自然语言处理”可分解成“我 爱 自然 语言 处理”或“我 爱 自然语言 处理”。
标注分词方法给句子中的每个字标记一个能区分词的标签,如SBME四标注法中,“S”表示是该字是单字,“B”表示该字是一个词的首字,“M”表示该字是一个词的中间字,“E”表示该字是一个词的结尾字。

对分词模型来说,就是要对输入序列产生正确的输出序列。采用隐马尔可夫模型作为分词模型时,输入序列是观测值序列,输出的标签序列是隐状态序列。
应用隐马尔可夫模型来分词,先要用大量的训练样本来训练模型,属于监督学习。在自然语言处理领域,训练样本称为语料。
用语料来有监督训练隐马尔可夫模型比较容易理解。用概率论的极大似然估计法和矩估计法都可以得到用频率来估计概率的结论。也就是说,对隐马尔可夫模型的三要素A,B,π,只需要统计它们中的每个元素在语料库中出现的频率即可。为了防止出现概率为0的情况,可采取如多项式朴素贝叶斯分类器中用到的平滑技术。
代码输出如下


分词结果如下
![]()
部分代码如下
import numpy as np
file = open("traindata.txt", encoding='utf-8')
test_str = "中国首次火星探测任务天问一号探测器实施近火捕获制动"
new_sents = []
sents_labels = []
for line in file.readlines():
line = line.split()
new_sent = ''
sent_labels = ''
for word in line:
if len(word) == 1:
new_sent += word
sent_labels += 'S'
elif len(word) >= 2:
new_sent += word
sent_labels += 'B' + 'M'*(len(word)-2) + 'E'
if new_sent != '':
new_sents.append([new_sent])
sents_labels.append([sent_labels])
print("训练样本准备完毕!")
print('共有数据 %d 条' % len(new_sents))
print('平均长度:', np.mean([len(d[0]) for d in new_sents]))
# 统计转移概率矩阵A和观测概率矩阵B
A = np.zeros((4, 4))
B = np.zeros((4, 65536)) # GB2312编码
for i in range(len(sents_labels)):
for j in range(len(sents_labels[i][0])):
B[state.index(sents_labels[i][0][j]), ord(new_sents[i][0][j])] += 1 # 观测频率加1
for j in range(len(sents_labels[i][0]) - 1):创作不易 觉得有帮助请点赞关注收藏~~~
文章出处登录后可见!