近日,Meta发布了LLama的最新版本——LLama2,尽管其对中文的处理能力尚有待提升,但其整体表现无疑是令人瞩目的。在发布当天,我便迫切地将其下载下来进行试用,发现相比之前的版本,LLama2在多个方面都实现了显著的进步,特别是在编程能力上的提升更为显著。在此,我与诸位分享一下如何在Linux环境下部署LLama2模型,以及如何将该模型如何利用YourChat在团队中进行共享。
一、下载注册模型
首先,我们需要访问此网址https://ai.meta.com/resources/models-and-libraries/llama-downloads/,并提供一些基本信息。所需填写的信息包括姓名、电子邮箱、国家和公司等,按照真实情况填写即可。尽管审核过程并不严格,但考虑到某些特殊因素,建议在国家一栏选择美国。
注册完毕后,可能需要等待一段时间。我本人等待了大约一个小时后,收到了Meta发来的邮件。邮件如下:

邮件中会附带一个key,也就是图片中涂黑的部分。大概格式是一个网址,但是访问这个网址是没有用的,要把这个key复制下来,因为我们后续会用到它。
二、下载LLama 2
截至目前,LLama2已推出了7B、13B、70B、7B-chat、13B-chat、70B-chat这六种模型,并为聊天功能推出了chat版本。值得一提的是,chat版本采用了RLHF进行了微调,这在当前的大语言模型中无疑是非常前沿的。此外,30B版本也将很快推出。
我们接下来将通过官方的脚本下载模型。首先,我们需要访问LLama的官方GitHub仓库https://github.com/facebookresearch/llama,并克隆该项目库。完成克隆后,在项目库中找到并运行download.sh脚本,然后按照提示输入你之前复制的key,并选择你需要的模型,就可以开始下载了。下载服务由Meta自家提供,下载速度非常快,我当时是满速下载完成的。
我当时选择了下载所有的模型,以下是我下载完成后的文件列表。

以llama-2开头的文件夹即为刚刚下载的模型,你可以根据自己的需求选择使用其中一个。
这是官方对硬件的要求:

可以看到,其中A10G有24G显存,也就是说我用的4090显卡只能运行7b的模型。不过在我测试7b模型的时候,发现显存占用在13G左右,等GPTQ支持LLama2后,运行13b模型应该没什么问题。
三、转换模型
官方指南为我们提供了两种部署方式——transformers和oobabooga的text-generation-webui,因为我们是要实际进行部署,就需要选择text-generation-webui。如果有稍微留意一下模型格式,我们可以发现刚刚下载的模型是.pth格式,通常由PyTorch生成,但是text-generation-webui默认使用的是huggingface格式的模型,因此我们需要进行一次转换操作。
在我写这篇文章的时候,transformer库还没有提供对应LLama2的转换脚本,但预计会很快更新。事实上,我们可以先借用一下第一代LLama的转换脚本进行转换,只需要稍微”欺骗”一下脚本就行。
首先,我们需要将这个repo https://github.com/huggingface/transformers.git 克隆到本地,脚本文件的路径是:src/transformers/models/llama/convert_llama_weights_to_hf.py。
在转换之前,我们需要进行一个操作,以使模型能够按照脚本预设的目录运行。对于使用过上一代模型的读者可能已经了解,LLama提供了7b、13b、30b、65b四种不同规模的模型,因此要使用第一代LLama的转换脚本,我们需要将下载的模型名称更改为这些名称,以便脚本能正确识别。例如,如果我使用的是7b-chat模型,那么我需要将7b-chat文件夹重命名为7B。总的来说,如果模型是7b-chat或7b则需要改名为7B,如果模型是13b-chat或13b则需要改名为13B,但对于70b的模型,我并不确定其参数是否能匹配65b的,如果你有能力运行的话,可以试一下。
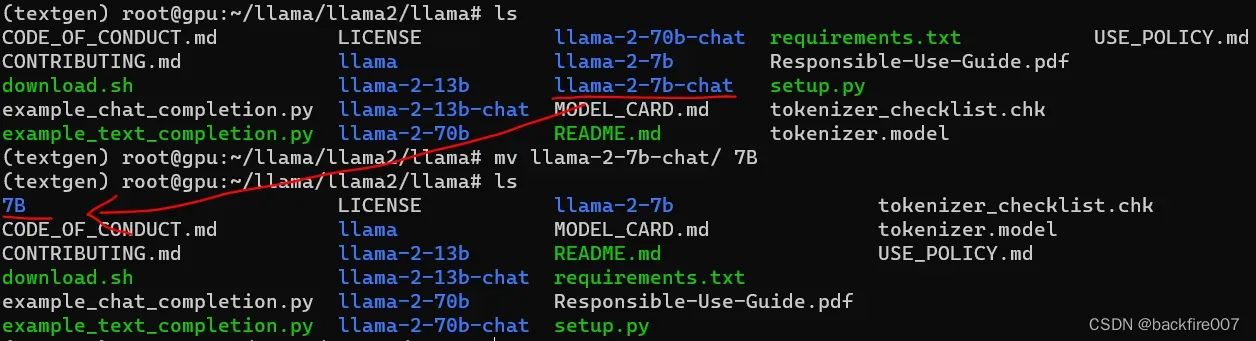
重命名完成后,就可以开始运行convert_llama_weights_to_hf.py脚本进行模型转换,具体的参数如下:
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir [llama repo所在路径] \
--model_size [7B,13B] \
--output_dir [huggingface格式模型输出文件夹]转换完成后,你可以在output_dir也就是huggingface格式模型输出文件夹中找到以下文件:
config.json
pytorch_model-00001-of-00002.bin
pytorch_model-00002-of-00002.bin
tokenizer_config.json
generation_config.json
tokenizer.model
special_tokens_map.json
pytorch_model.bin.index.json有了这些文件,我们就可以进行下一步了。
四、搭建text-generation-webui
text-generation-webui是github上的一个开源项目,也是目前运行开源模型最广泛使用的软件之一。如果你之前用过第一代LLama,应该对这个项目比较熟悉。
text-generation-webui的安装方式相当简单,同样需要从github上克隆项目:https://github.com/oobabooga/text-generation-webui/。克隆完成后,我们把刚才转换好的huggingface格式的模型文件夹整个放入models中,目录结构如下:

我们将刚才生成好huggingface格式的模型文件夹整个放入models中,文件结构如下图:
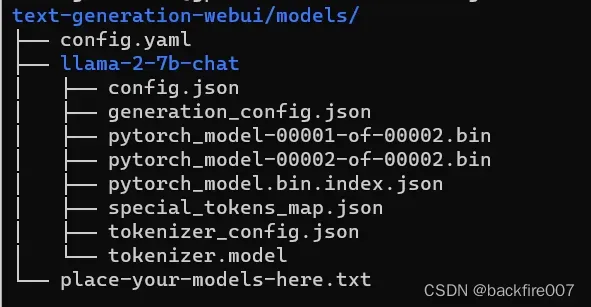
其中llama-2-7b-chat是我在上一步output_dir中指定的huggingface输出文件夹。
如果这一步做完了,模型部署这块就大功告成啦。现在我们运行text-generation-webui就可以和llama2模型对话了,具体的命令如下:
python server.py --model [output_dir中指定的huggingface输出文件夹名字] --api --listen五、分发模型
现在,你的Llama2模型已经搭建好了,怎么样把它分享给你的朋友或同事使用呢?我们用YourChat来完成这个工作。YourChat是一个聊天客户端,它支持text_generation_webui的API,适配了Android、iOS、Windows和MacOS,以下我们以Windows版本为例,当然其他平台也大同小异。
在上一步,我们在启动text_generation_webui的时候添加了一个—api参数,这就让text_generation_webui支持了API调用。如果你想要使用YourChat,那这个API功能就必须要打开。
首先,让我们把刚刚搭建的text_generation_webui添加到YourChat的服务里面。如果你是第一次使用YourChat,它会弹出一个新手教程。如果你没有改动过text-generation-webui服务的参数,那就按照教程的指引,填入服务的IP地址就可以了。
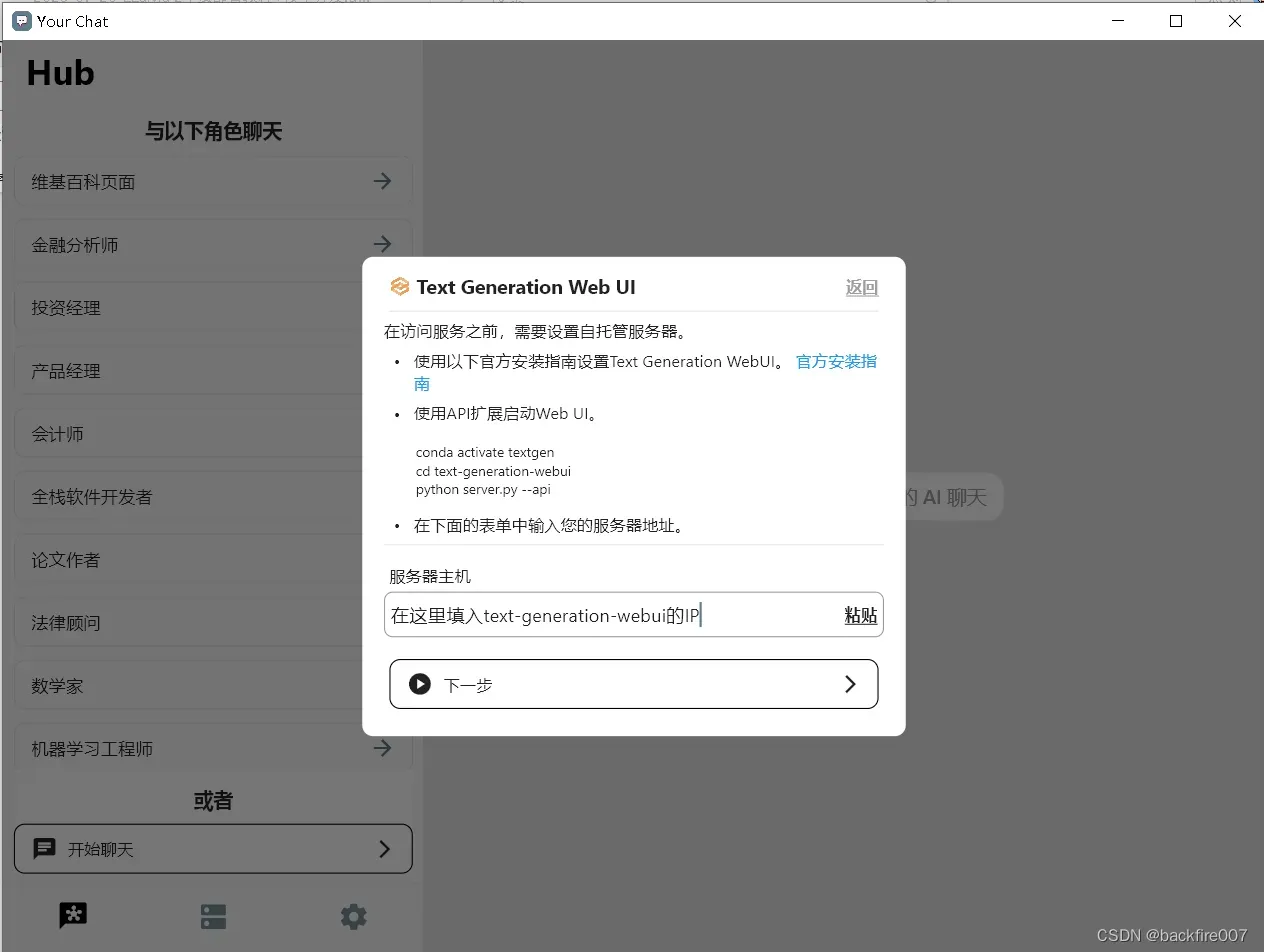
如果你之前已经下载过YourChat,那就在YourChat的”服务”界面,点击右下角的”+”按钮,添加一个新的服务。在”名称”栏中,输入你的服务名称,比如模型名字”llama-2-7b-chat”。在”Host”栏中,填写你的模型服务器的地址,例如”192.168.2.2″。
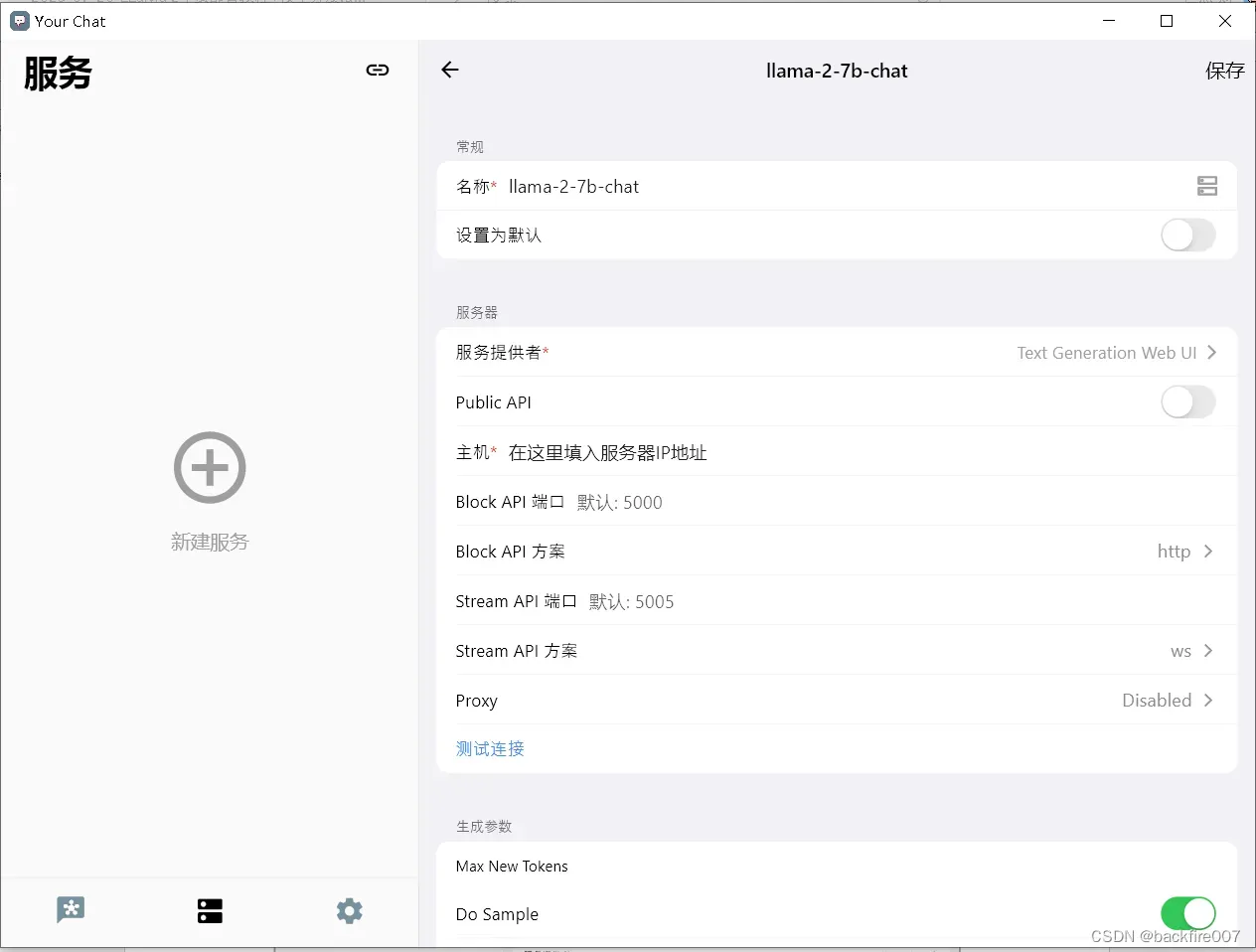
然后点击右上角的保存按钮,你的Llama2模型就成功地被添加到了YourChat中,你现在可以开始和Llama进行聊天了。
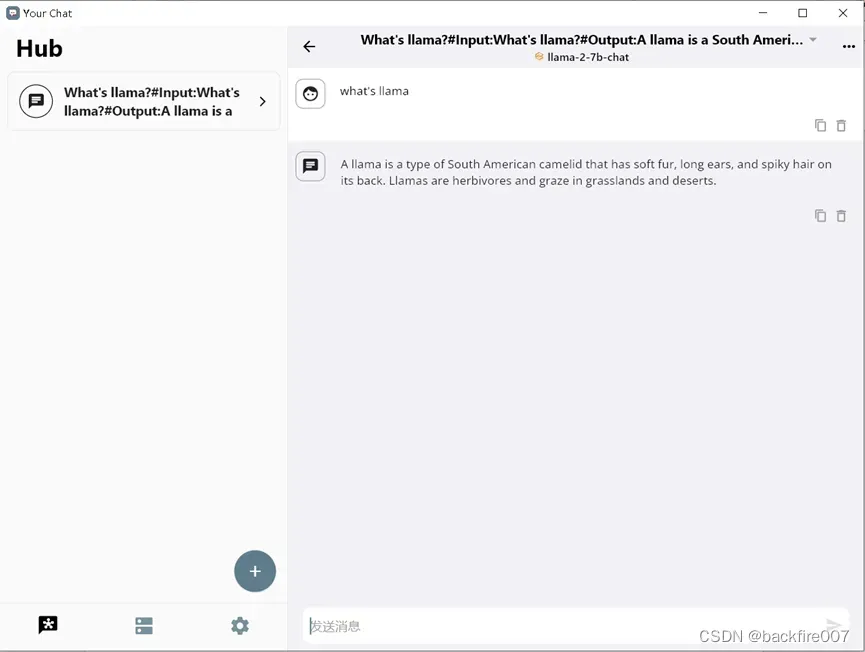
不过看起来,Llama2并不清楚它就是我们所说的”llama”。
使用YourChat的一个大优势是能方便地分享模型。YourChat支持订阅链接功能,也就是说,你把模型设置好,使用YourChat的订阅链接功能生成一个链接,那你的同事就可以用YourChat无缝同步你的设置,然后就可以和你的模型进行对话了。加上Yourchat也支持OpenAI的API,这个种类似一键分发的功能确实是非常方便
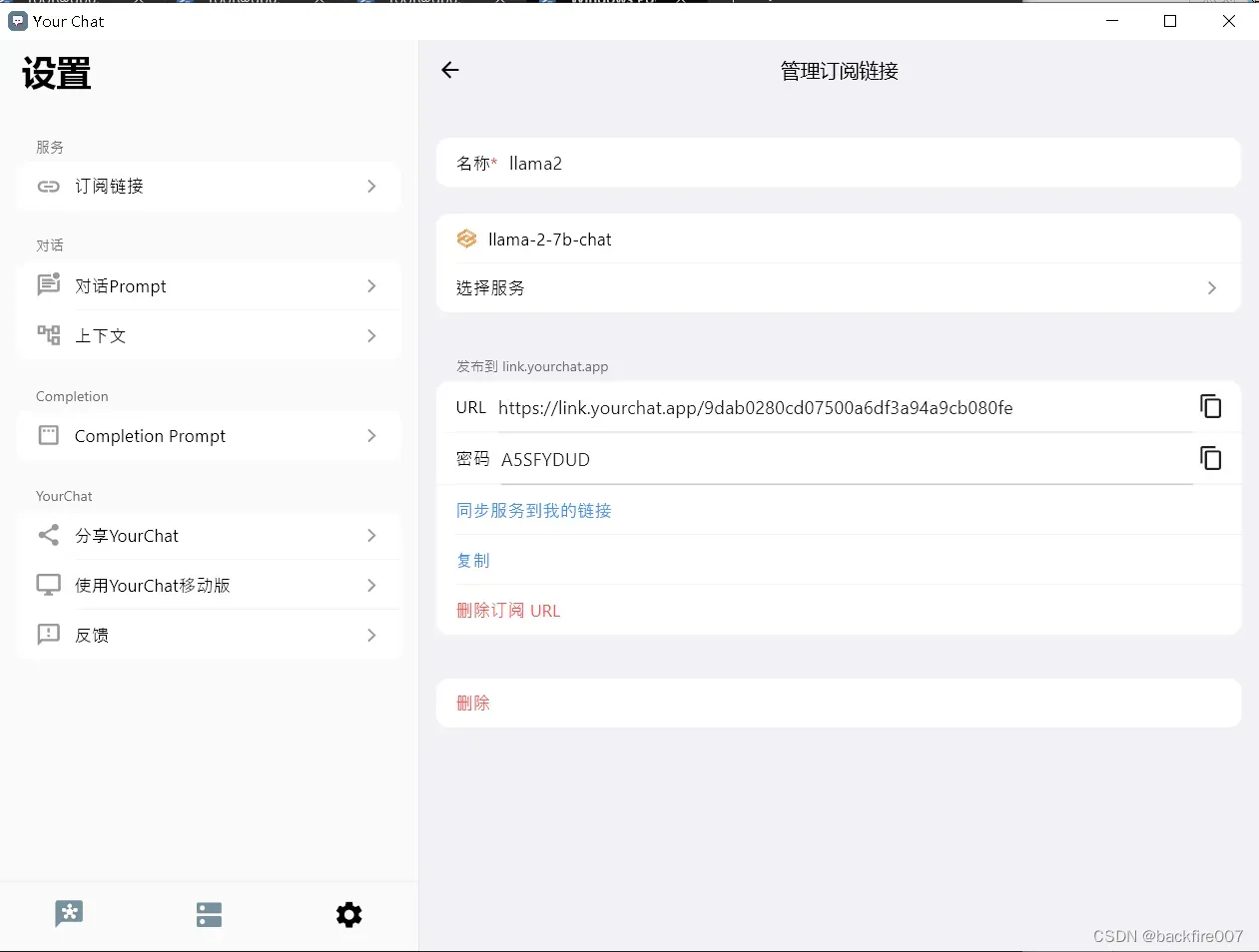
具体的操作步骤是:进入”设置”->”订阅链接”界面,点击”新建订阅链接”。然后在新弹出的页面中输入订阅的名称,比如”llama”,并在服务列表中勾选你刚刚设置的LLama2服务。点击”发布服务到我的链接”后,你就得到了一个订阅链接,链接中包含一个8位数的密码。然后,你只需要把这个链接分享给你的同事们。
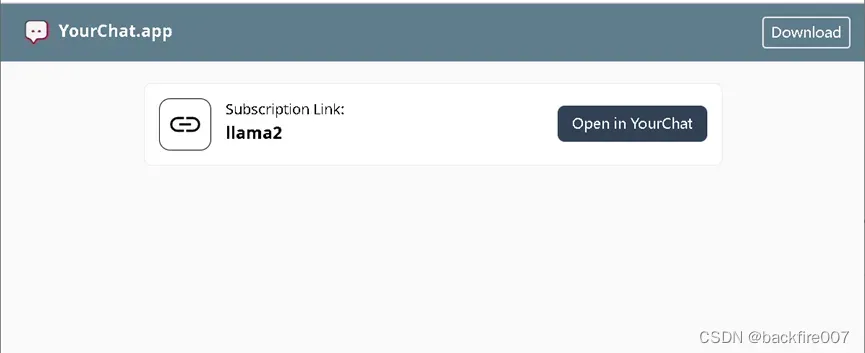
你的同事们在收到你的订阅链接后,下载个yourchat,用浏览器访问下链接,就可以访问你的llama2了
六、结语
至此,我们就完成了llama2模型的搭建和分发。虽然目前我们只在局域网中进行了分发,但如果你需要在公网中发布,还可以配合使用text_gernation_webui的public-api功能。最后,按照惯例,让我们看看llama如何为RLHF创作一首诗吧:
The RLHF algorithm for language modeling,
Is like a black box wearing a hat,
The input is the text, and it’s fed to the LLM,
It takes the text and then it’s read,
The output is the probability of each word,
And it’s used to predict what comes next,
This process repeats until the end of the text,
Then the final probability distribution is produced,
Which can be used to generate new sentences with the LLM.
文章出处登录后可见!