文章目录
- 📌提炼
- ❓什么是 AlpacaEval
- 🔎AlpacaEval 排行榜 包含的 测试 模型 和数据
- 💯在不同的测试集上各个大模型的能力评分
- 🚀AlpacaEval Leaderboard 大模型的能力综合评分
- 💼 普遍国内白领 如何快速应用 大模型
🤖️在这个AI爆发的元年🎨 🤖️AI不能取代我们 不会用AI的人才会被取代🎨
📌提炼
- GPT-4 登顶商用模型
- 微软 WizardLM 登顶开源模型
❓什么是 AlpacaEval
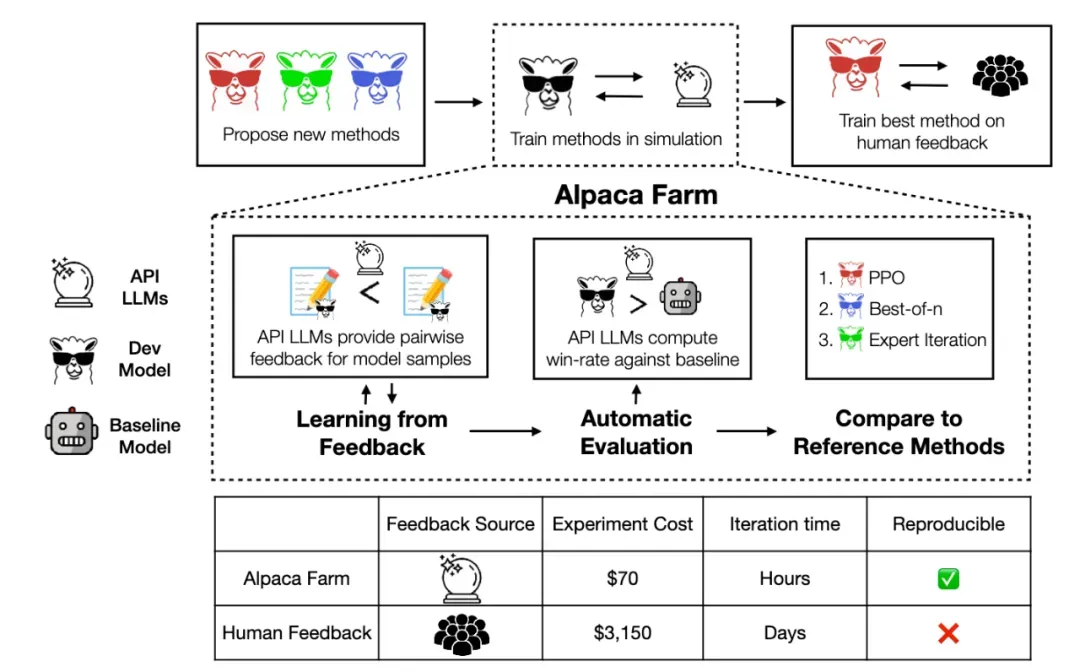
- AlpacaEva 是来自斯坦福的团队发布的一款 大语言模型 自动评测系统,
- 它是一种基于 LLM 的全自动评估基准,且更加快速、廉价和可靠。
- 同时包含了应的 AlpacaEval Leaderboard(大语言模型排行榜)。
- AlpacaEval 是一个模拟沙盒,能够快速、廉价地对从人类反馈中学习的方法进行实验。它用API LLMs模拟人类反馈,提供一个经过验证的评估协议,并提供一套参考方法的实现。
- 虽然仅基于 GPT-4 进行自动评估,但与基于 1.8 万条真实人类标注排序结果之间高达 0.94 的皮尔逊相关系数,证明了 AlpacaEval 榜单 排名的高可靠性。
🔎AlpacaEval 排行榜 包含的 测试 模型 和数据
选择了目前在 商用领域 和 开源社区 很火 的模型 ,包括但不限于以下模型
- GPT-4 (open ai)
- Claude (anthropic)
- PaLM 2 (google)
- WizardLM (microsoft)
甚至还开设了一个 「准中文」 排行榜
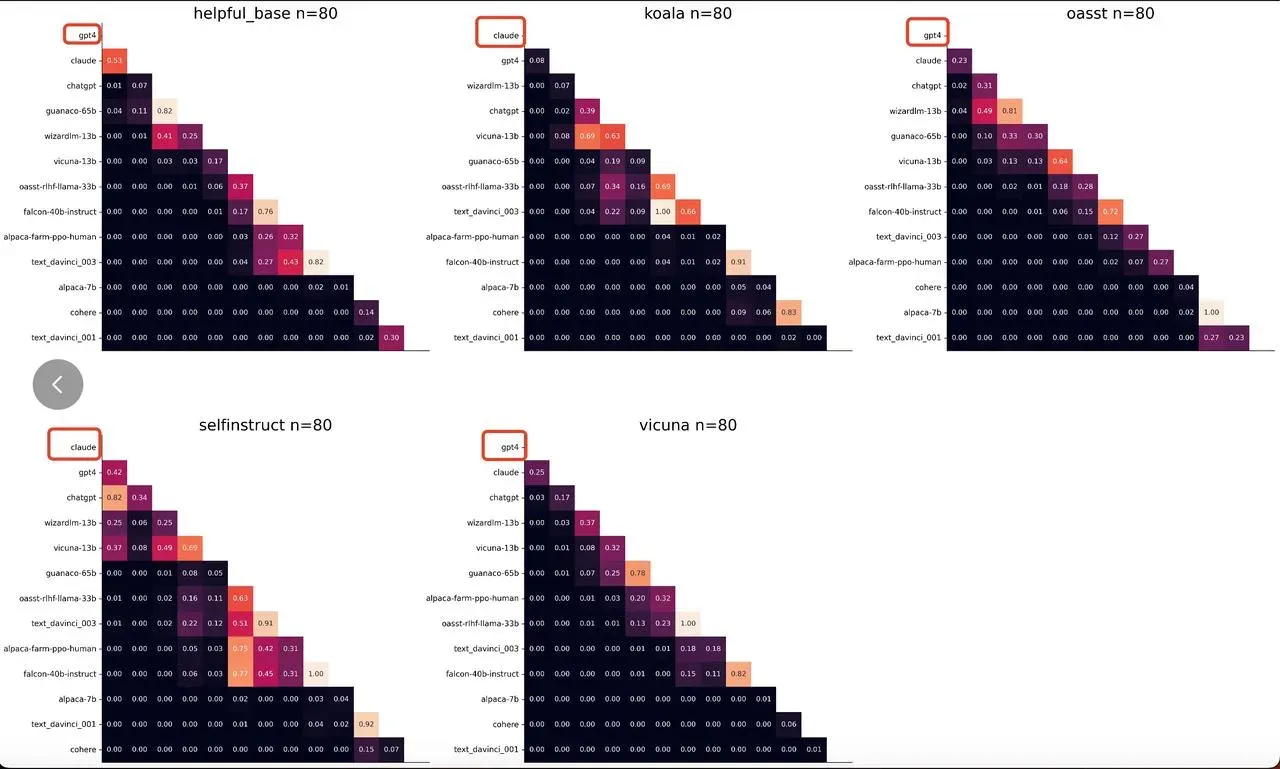
💯在不同的测试集上各个大模型的能力评分
🚀AlpacaEval Leaderboard 大模型的能力综合评分
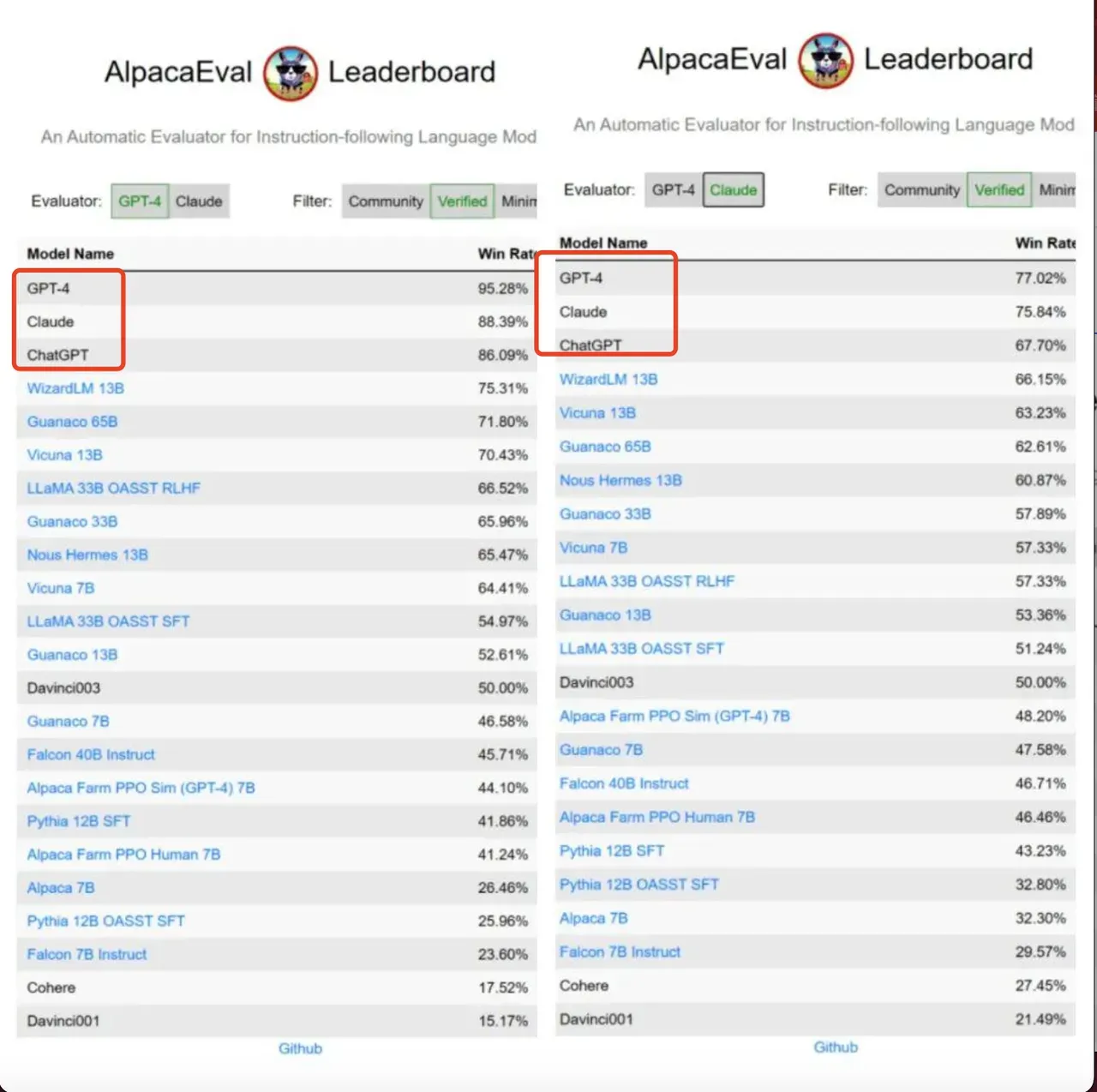
📌总结:
- GPT-4 综合评分 稳居第一,胜率超过了95%
- 胜率都在 80% 以上的 Claude 和 ChatGPT 分别排名第二和第三,其中 Claude 以不到 3% 的优势超越 ChatGPT-3.5。
- 值得关注的是,获得第四名的是一位排位赛新人——微软华人团队发布的 WizardLM。WizardLM 以仅 130 亿的参数版本排名第一,击败了 650 亿参数量的 Guanaco。
💼 普遍国内白领 如何快速应用 大模型
对于国内的很多办公白领来说,使用 GPT 4服务的难度有些大,
- 需要特定的上网服务 和 国外邮箱
- 国外的信用卡
- 即使注册 成功了还会有因为ip变动被封号的风险
在这里给大家推荐一个AI工具
- 可直接使用
- 用户使用体验良好
- 接口稳定
👑 TomChat(https://www.tomchat.fun)
🤖 支持gpt4 / gpt-3.5 / claude /code-llm
🎨 支持 AI绘画
🆓 每天十次免费使用机会
🪄 无需魔法
🤖️在这个AI爆发的元年🎨
🤖️AI不能取代我们 不会用AI的人才会被取代🎨
文章出处登录后可见!
已经登录?立即刷新