普里姆(prim)算法
- 一、定义
- 二、思路
- 三、代码实现
- 四、代码解析
一、定义
普里姆算法是一种构造性算法。假设G = (V, E)是一个具有n个顶点的带权连通图,T = (U,TE)是最小生成树,其中U是T的顶点集,TE是T的边集,则由G构造从起始点v出法的最小生成树T的步骤如下:
- 初始化U = { v },以v到其他顶点的所有边为侯选边。
- 重复以下步骤(n – 1)次,使得其他(n – 1)个顶点被加入U中。
(1). 从候选边中挑选权值最小的边加入TE,设该边在V—U中的顶点是k,将k加入U中。
(2). 考察当前V—U中的所有顶点j,修改侯选边,若(k,j)的权值小于原来和顶点关联的侯选边,则用(k,j)取代后者作为侯选边。
二、思路
我们可以将定义理解为:将图的所有顶点分为两类,A类(保存已经查找过的顶点),B类(保存未查找过的顶点),从任一顶点开始,并将其从B类移至A类,然后开始寻找B类中(的顶点)到A类顶点之间权值最小的顶点,将其从B类中移至A类,重复上述操作,直至B类中没有顶点。所走过的顶点和边就是该连通图的最小生成树。
由此图为例:
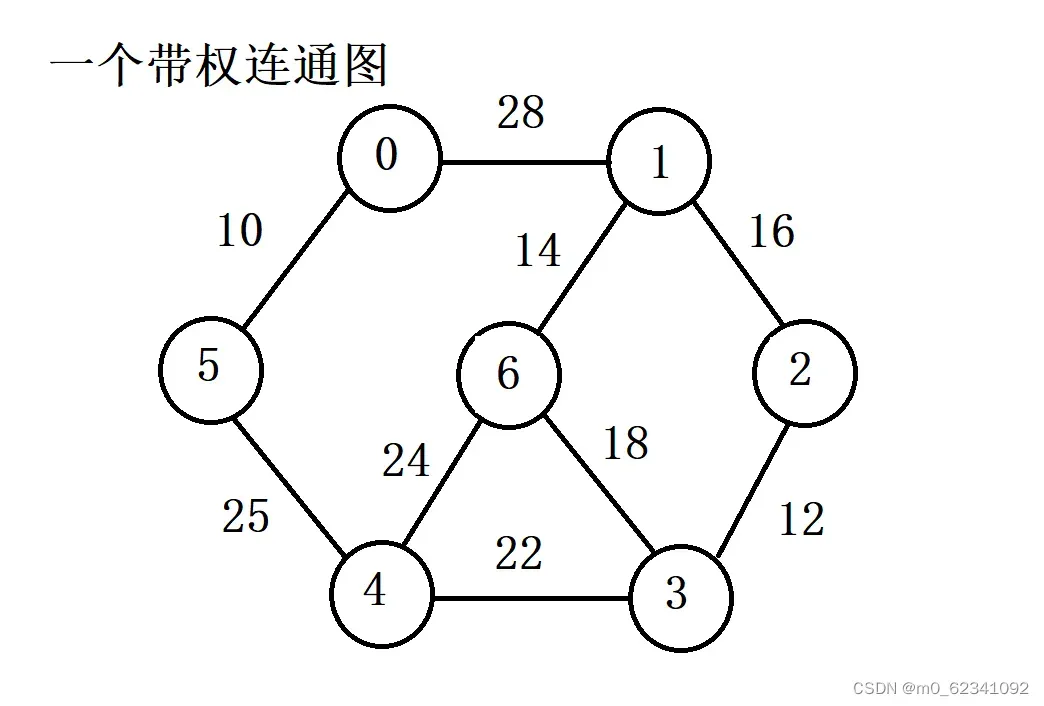
初始状态
A类 = { }
B类 = { 0, 1, 2, 3, 4, 5, 6 }
假设从顶点2开始遍历
A类 = { 2 }
B类 = { 0, 1, 3, 4, 5, 6 }
遍历第一次后
A类 = {2, 3 }
B类 = { 0, 1, 4, 5, 6 }
遍历第二次后
A类 = { 1, 2, 3 }
B类 = { 0, 4, 5, 6 }
由此类推,直至B类中无顶点。
A类 = { 0, 1, 2, 3, 4, 5, 6 }
B类 = { }
图型讲解如下:
假设从顶点2开始遍历。

寻找B类到A类顶点之间权值最小的顶点(在现有的两条边寻找权值最小的边)。(上图为顶点3)将其添加至A类顶点中。

步骤同上。在现有的三条边(权值为12的边已经遍历过所以不计入)中寻找权值最小的边。(上图为顶点1)将其添加至A类中。大家注意在这里我们去掉了权值为18的边,这是因为从顶点1可以通过权值为14的边到达顶点6,从顶点3可以通过权值为18的边到达顶点6,根据定义我们要寻找顶点间权值最小的边,所以我们用权值为14的边替换权值为18的边。

步骤同上。在现有的三条边中寻找权值最小的边。(上图为顶点6)将其添加至A类。大家注意在这里增加顶点6,之后我们本应该可以获得一条从顶点6到顶点4权值为24的边,但是由于我们有从顶点3到顶点4的权值为22的边,所以根据定义,我们无需添加顶点6到顶点4权值为24的边

重复上述步骤。我们就可以通过prim算法得到最终的最小生成树。

看完了讲解,接下来让我们看看prim算法的代码实现吧!
三、代码实现
\*
#define MAXV <最大顶点数>
#define INF 32767 //定义无穷大
typedef struct {
int no; //顶点的编号
InfoType info; //顶点的其他信息
}VertexType; //顶点的类型
typedef struct {
int edges[MAXV][MAXV]; //邻接矩阵数组
int n, e; //顶点数,边数
VertexType vexs[MAXV]; //存放顶点信息
}MGraph; //完整的图邻接矩阵类型
*\
void Prim(MGraph g,int v) { //传入一个邻接矩阵,和起始顶点
int lowcost[MAXV];
int closest[MAXV];
int min;
int i,j,k = 0;
for (i=0; i<g.n; i++) { //给lowcost[]和closest[]置初值
lowcost[i]=g.edges[v][i];
closest[i]=v;
}
lowcost[v] = 0;
for (i=1; i<g.n; i++) { //找出n-1个顶点
min=INF;
for (j=0; j<g.n; j++) { //在(V-U)中找出离U最近的顶点k
if (lowcost[j]!=0 && lowcost[j] < min) {
min=lowcost[j];
k=j; //k记录最近顶点的编号
}
}
printf(" 边(%d,%d)权为:%d\n", closest[k], k, min);
lowcost[k]=0; //标记k已经加入U
for (j=0; j<g.n; j++){ //对(V-U)中的顶点j进行调整
if (g.edges[k][j]<lowcost[j]) {
lowcost[j]=g.edges[k][j];
closest[j]=k; //修改数组lowcost和closest
}
}
}
}
四、代码解析
初看代码相信很多人都是一头雾水,接下来就让我们对代码进行刨析。
我们先将上述的带权连通图转化成邻接矩阵为后续讲解做准备。
{ 0 , 28, INF, INF, INF, 10, INF }
{ 28, 0, 16, INF, INF, INF, 14 }
{ INF, 16, 0, 12, INF, INF, INF}
{ INF, INF, 12, 0, 22, INF, 18 }
{ INF, INF, INF, 22, 0, 25, 24 }
{ 10, INF, INF, INF, 25, 0, INF}
{ INF, 14, INF, 18, 24, INF, 0}
首先让我们一起看看这几句代码
for (i=0; i<g.n; i++) { //给lowcost[]和closest[]置初值
lowcost[i]=g.edges[v][i];
closest[i]=v;
}
这三行代码时我们整个算法的开始。那么这三行代码是在表达什么意思呢?
假设我们从顶底2开始,那么循环结束两个数组的值为
lowcost[] = { INF, 16, 0, 12, INF, INF, INF }
closest[] = { 2, 2, 2, 2, 2, 2, 2}
我们尝试着这样去理解一下。
lowcost数组中的每一个元素,我们将它理解为,A类元素到B类元素的最短距离。(无穷大表示目前还不能通过A类元素到达B类元素,0表示已经遍历过该顶点)
例如:
- lowcost数组的第一个元素为INF,表示顶点2没有到达顶点0的路径。
- lowcost数组的第二个元素为16,这表示顶点2到顶点1的路径为16。
那么肯定有人有一个疑问为什么这里说的都是顶点2到其他的顶点的路径,那么请大家看看下面这句话。
closest数组中的每一个元素,我们将它理解为,lowcost数组中的边是哪一个顶点的邻边。或者也可以理解为A类元素暂且只有顶点为2的元素。
- 比如lowcost中第四个元素时权值为12的边,这条边是顶点2的临边。
那么为什么这样去做,请大家跟着我一起继续向下看。
在分析了算法的开始之后,让我们看看接下来的几行代码
for (i=1; i<g.n; i++) { //循环n-1次 找出n-1个顶点
min=INF;
for (j=0; j<g.n; j++) { //在(V-U)中找出离U最近的顶点k
if (lowcost[j]!=0 && lowcost[j] < min) {
min=lowcost[j];
k=j; //k记录最近顶点的编号
}
}
printf(" 边(%d,%d)权为:%d\n", closest[k], k, min);
lowcost[k]=0; //标记k已经加入U
for (j=0; j<g.n; j++){ //对(V-U)中的顶点j进行调整
if (g.edges[k][j]<lowcost[j]) {
lowcost[j]=g.edges[k][j];
closest[j]=k; //修改数组lowcost和closest
}
}
}
接下来让我们来看看大的for循环中的第一个小循环。
for (j=0; j<g.n; j++) { //在(V-U)中找出离U最近的顶点k
if (lowcost[j]!=0 && lowcost[j] < min) {
min=lowcost[j];
k=j; //k记录最近顶点的编号
}
}
这个循环的意思为找出现有边中权值最小的边。并用k记录该边所连接的顶点。
那么在接下来输出(或其他操作)时我们就可以将这条边完整的输出出来。
printf(" 边(%d,%d)权为:%d\n", closest[k], k, min);
之后就到了整段代码的第二个核心。(那么什么是第一个核心,等我们一起看完整段代码后就会浮出水面)
lowcost[k]=0; //标记k已经加入U
for (j=0; j<g.n; j++){ //对(V-U)中的顶点j进行调整
if (g.edges[k][j]<lowcost[j]) {
lowcost[j]=g.edges[k][j];
closest[j]=k; //修改数组lowcost和closest
}
}
首先我们先将lowcost数组中最小边连接的顶点置0,表示该点已经加入A类。
然后大家注意这个if判断语句中的条件。
g.edges[k][j] < lowcost[j]
如果新顶点的邻边比现有待选边的权值小,就将其替换。目的还是为了确保下一次能找到最小边。
整段代码第一次执行结束后,让我们再来看看lowcost数组和closest的值。
lowcost[] = { INF, 16, 0, 0, 22, INF, 18 }
closest[] = { 2, 2, 2, 2, 3, 2, 3 }
这样下来我们不仅将新的顶点添加了进来(lowcost数组中索引为3的顶点值为0),还将新顶点的临边添加进来,最后还保证了待选边的最小特征。
好了,prim算法的讲解到此结束。
文章出处登录后可见!