目录
- 前言
- 一、要求
- 二、Stable diffusion WebUI项目
- 三、电脑基础工具安装及环境配置
- 1. 安装Anaconda
- 2. 配置conda环境
- 3. 创建python环境
- 4. 激活pyton环境并升级pip
- 5. 安装git
- 6.安装cuda
- 五、stable diffusion 环境配置及安装
- 1. 下载stable diffusion源码
- 配置windows命令窗口使用魔法
- 2.下载stable diffusion的训练模型
- 3.安装GFPGAN
- 4. 启动sd-webui项目
- 4.1 检查conda环境
- 4.2 进入根目录,启动sd-webui项目
- 六、使用stable diffusion
- 1. 设置中文界面
- 2. 简单使用
- 3. 进阶使用
- 总结
- 其它资料下载
最近看到朋友圈最近各种文字生图、图生图,眼花缭乱的图片AI生成,我也心动了,于是赶紧研究了下目前业内认为最强大的Midjourney、Adobe FireFly,本来想试用下,奈何全球人民太热情了,Midjourney被薅羊毛薅的不行了,原本Midjourney刚注册可以免费玩25次,现在也被Midjourney关闭了。
于是我决定找找有没有开源的,免费的,生成数量不受限制,生成时间快,不用排队,自由度高很多,不用被nsfw约束,可以调试和个性化的地方也更多的工具,经过一番探索,终于发现了,现在不少强大的图片AI生成工具,都基本运用到了Stable Diffusion这个框架模型。可以说,Stable diffusion是当前最多人使用且效果最好的开源AI绘图软件之一,属于当红炸子鸡了。
那我们就开始来看看,如何把Stable Diffusion这个框架模型部署到本地把。
前言
如果你能够使用各大在线的AI绘图平台来生成图像,那就相当于小学水平的熟练程度。
如果你可以使用本地化部署Stable Diffusion来运行ai绘画,那就和高中毕业生一样了,已经具备了一定的绘画技能。
当然要想到达大学毕业水平,也就是可以随心所欲地使用AI绘图,就需要了解更多的技术细节,并一步步提升它们的熟练程度。
一、要求
本地化部署运行Stable Diffusion有一些基本要求:
(1)需要拥有NVIDIA显卡,GT1060起,显存4G以上。(已经不需要3080起,亲民不少)
(2)操作系统需要win10或者win11的系统。
(3)电脑内存16G或者以上。
(4)最好会魔法上网,否则网络波动,有些网页打不开,有时下载很慢。
(5)耐心,多尝试,多搜索。
我的电脑是惠普的工作站,显存都16G,内存都64G,正常不需要这么高配置。给一个朋友的电脑配置供大家参考,Win11,I5,NVIDIA GT1060 5G,16G。
朋友电脑生成一张20step的图大概20-30s;
我的电脑生成一张20step的图大概5-6s,好一点的电脑,生成图确实快。

二、Stable diffusion WebUI项目
如果直接对stable diffusion项目进行本地化部署,使用基本需要使用纯代码界面,对于非程序员没那么友好。所以我选择了stable diffusion webui,它是基于stable diffusion 项目的可视化操作项目。通过可视化的网页操作,就可以更方便调试prompt,及各种参数,同时也附加了很多功能,比如img2img功能,extra放大图片功能等等。
因此stable diffusion webui项目是很多人部署到本地的首选。本教程也是以stable diffusion webui项目为例来操作的。
三、电脑基础工具安装及环境配置
1. 安装Anaconda
从anaconda官网,下载安装anaconda。具体教程详见官网教程。
如果觉得Anaconda太大,也可以从 https://docs.conda.io/en/latest/miniconda.html 下载并安装Miniconda,这里也可以参考官方安装步骤去安装Anaconda。
2. 配置conda环境
启动windows命令窗口,在搜索中输入cmd即可打开,输入以下命令:
conda config --set show_channel_urls yes
右键Anaconda图标,在属性中找到Anaconda所在根目录,就是下图红框的目录,然后打开该目录,就可以找到.condarc文件。
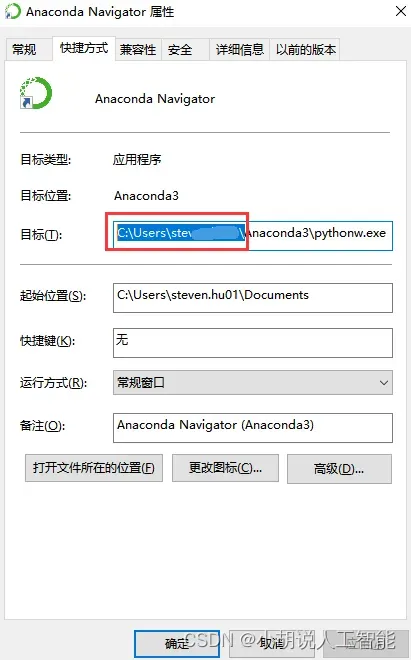
用记事本打开并修改.condarc文件。把下面的内容全部复制进去,全部覆盖原内容,ctrl+s保存,关闭文件。
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
在windows命令窗口中运行conda clean -i 清除索引缓存,以确保使用的是镜像站的地址。
conda clean -i
3. 创建python环境
在windows命令窗口中运行下面语句,创建python 3.10.6版本的环境。
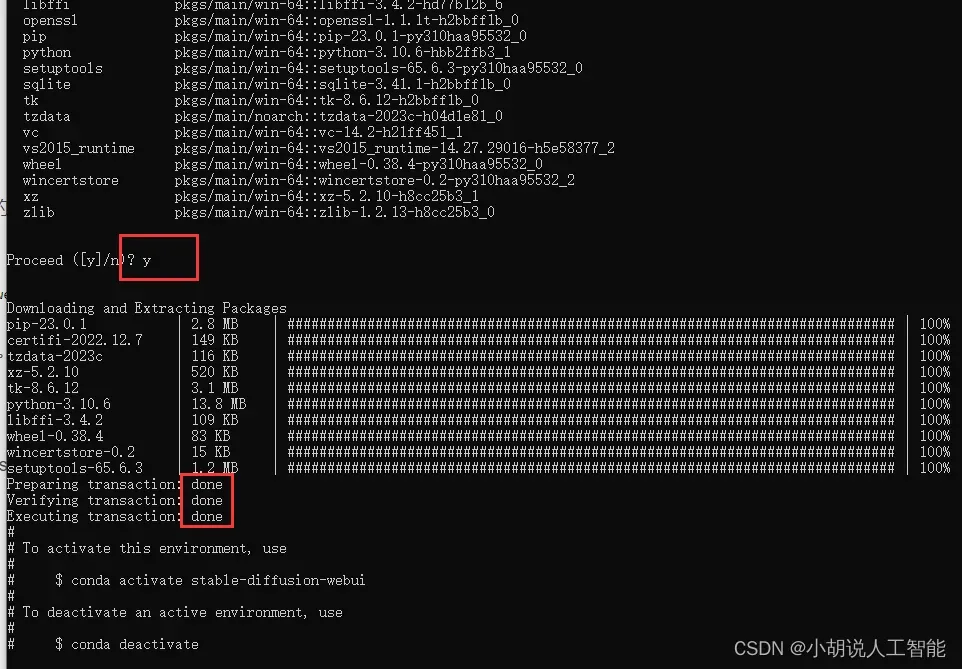
conda create --name stable-diffusion-webui python=3.10.6
系统可能会提示y/n, 输入y,按回车即可。
最终显示done,那就完成了。
4. 激活pyton环境并升级pip
继续在windows命令窗口中输入conda activate stable-diffusion-webui 回车。
conda activate stable-diffusion-webui
继续在cmd中升级pip
python -m pip install --upgrade pip
继续在windows命令窗口中设置pip的默认库包下载地址为清华镜像。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
5. 安装git
安装git其实不太难,只要一路点next就可以完成,具体可以参考git详细安装教程
软件包下载地址
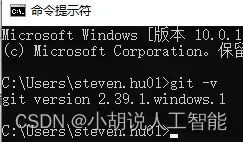
安装完成后,在windows命令窗口中运行下面命令,看到安装的git版本就表示安装成功了
git -v
6.安装cuda
cuda是NVIDIA显卡用来跑算法的依赖程序,所以我们必须安装它。打开NVIDIA cuda官网,(如果打不开,请用魔法上网。)
在windows命令窗口中运行下面命令,查看你的cuda版本
nvidia-smi
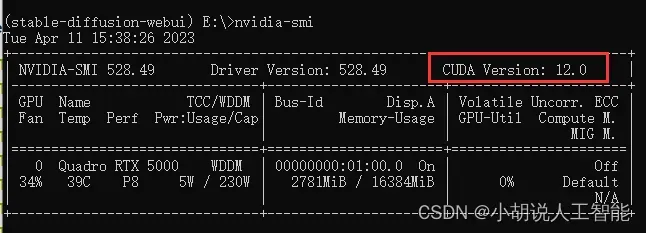
比如是11.7的版本,就下载11.7的链接,但是我这显卡配置比较高,显示的是12.0版本,我最后还是选择了较低的11.7版本的cuda,主要是现在stable diffusion项目中的torch不一定支持高版本的cuda。

然后按照自己的系统,选择win10或者11,exe(local),Download(如果下载慢,请用魔法上网。)
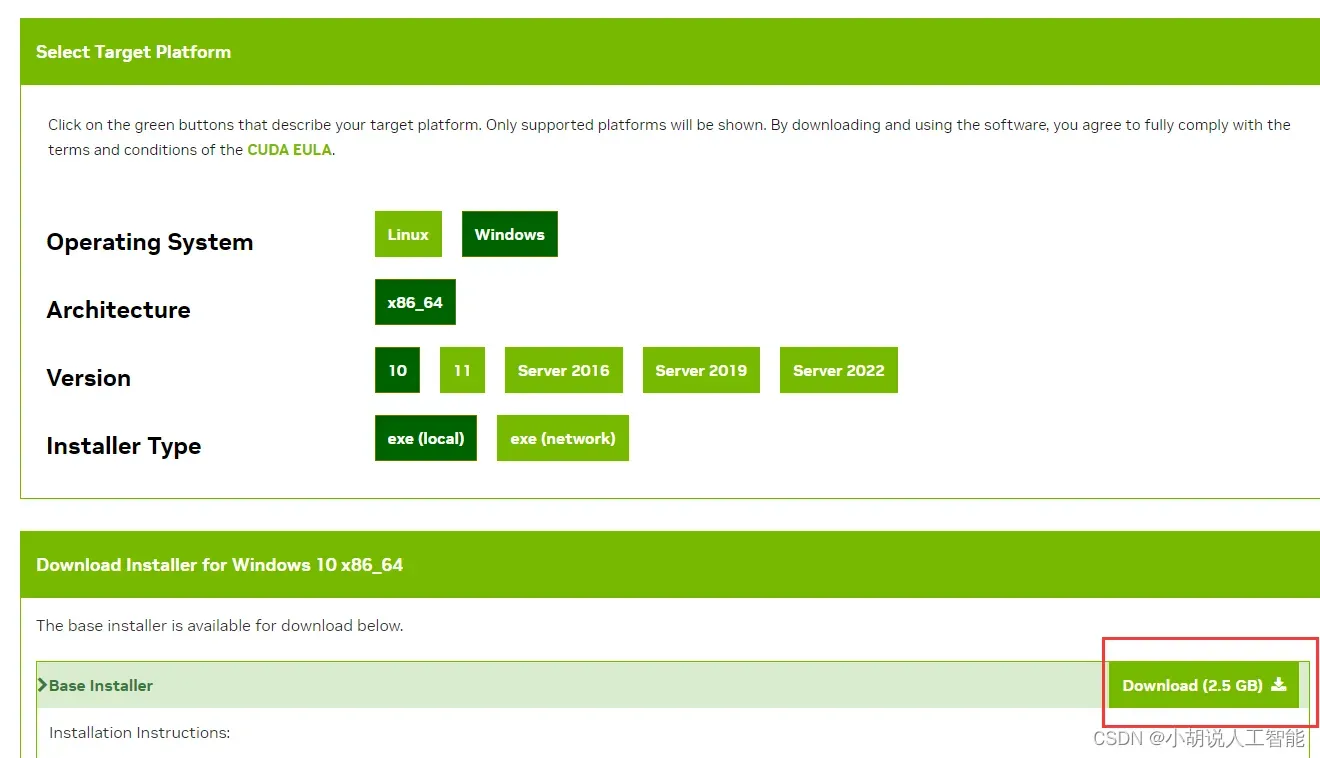
下载完后安装,这个软件2.5G,可以安装在c盘以外的地方。
到此,电脑的基础环境设置终于完事了。接下来,我们开始安装stable diffusion了。
五、stable diffusion 环境配置及安装
1. 下载stable diffusion源码
在windows命令窗口中运行下面命令,切换目录到其它硬盘空间更大的盘(不建议直接在c盘,主要是stable diffusion会有很多模型下载,会占用比较大硬盘空间,一般至少10G以上),比如e盘,则输入e: 按回车
e:
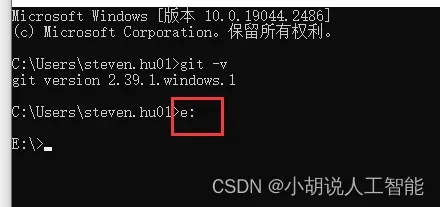
接下来克隆stable diffusion webui项目(下面简称sd-webui)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
如果最后显示了done,那就表示项目已经克隆到你指定盘下面了,比如说e:\stable-diffusion-webui
如果克隆得比较慢,建议打开魔法,然后按下面步骤配置windows命令窗口使用魔法。
配置windows命令窗口使用魔法
首先,查看本地魔法端口,如下图显示为10810,有些魔法,端口也可能是1080 10809啥的,如果实在不知道哪里查看,依次试试,应该就能找到了。
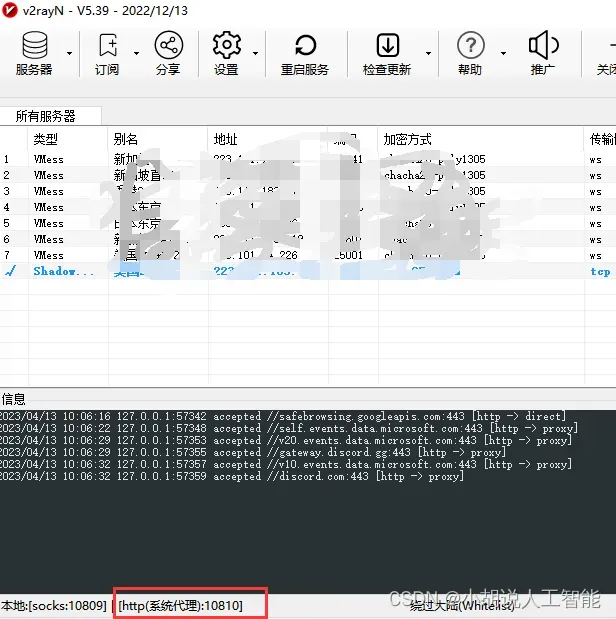
接着依次输入下面两个命令,按回车。其中10810就是上面查到的端口地址,如果你的是1080,就替换成1080
set http_proxy=http://127.0.0.1:10810
set https_proxy=http://127.0.0.1:10810
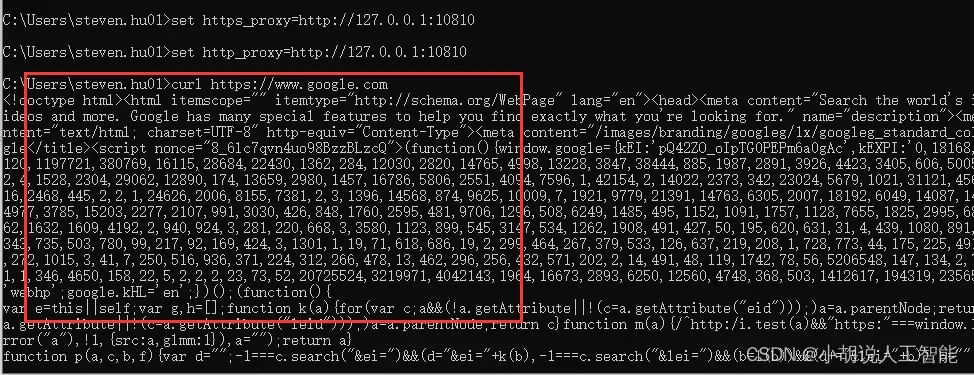
最后,检查下魔法是不是成功,使用以下命令,注意不要用ping,出来一堆html语言啥的,那就表示成功拉。
curl https://www.google.com
2.下载stable diffusion的训练模型
在stable diffusion模型库点击file and versions选项卡,下载sd-v1-4.ckpt训练模型。
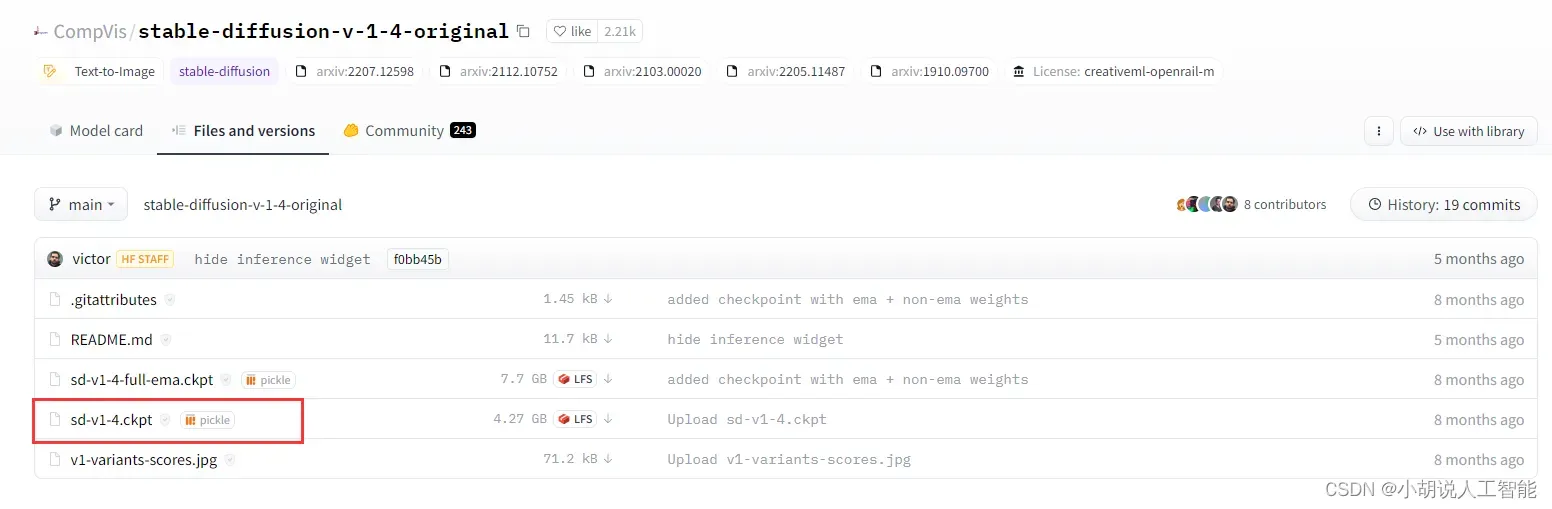
注:这个模型是用于后续生成AI绘图的绘图元素基础模型库。
后面如果要用waifuai或者novelai,其实更换模型放进去sd-webui项目的模型文件夹即可。
我们现在先用stable diffusion 1.4的模型来继续往下走。
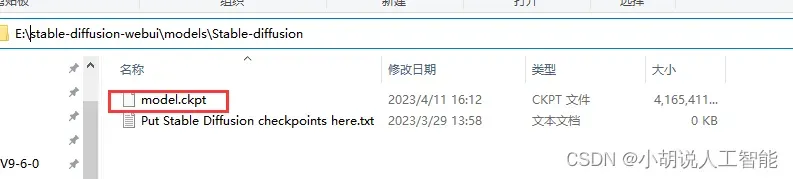
下载好之后,请把模型更名成model.ckpt,然后放置在sd-webui的models/stable-diffusion目录下。比如我的路径是e:\stable-diffusion-webui\models\Stable-diffusion
3.安装GFPGAN
这是腾讯旗下的一个开源项目,可以用于修复和绘制人脸,减少stable diffusion人脸的绘制扭曲变形问题。
打开GFPGAN—github地址
把网页往下拉,拉到readme.md部分,找到V1.4 model,点击蓝色的1.4就可以下载。
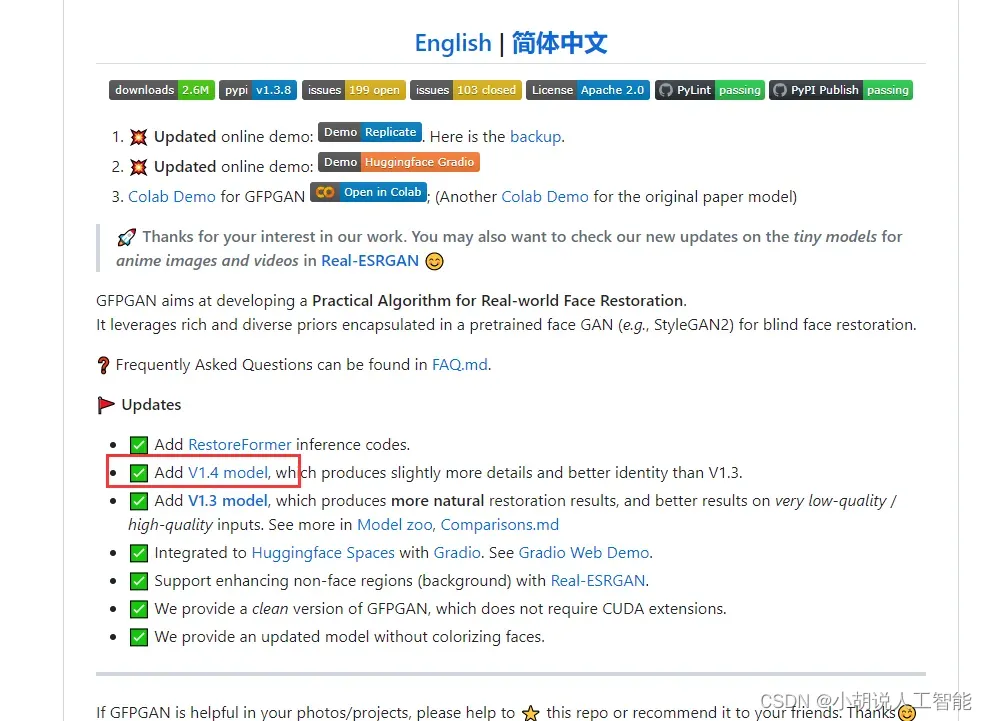
下载好之后,放在sd-webui项目的根目录下面即可,比如我的根目录是e:\stable-diffusion-webui
4. 启动sd-webui项目
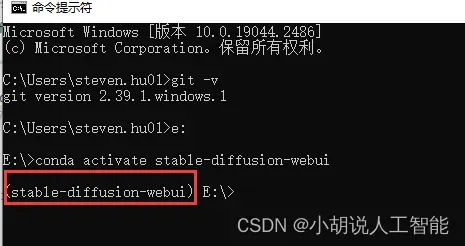
4.1 检查conda环境
在windows命令窗口中,检查是否启动了conda环境,如果没有在目录前看到(stable-diffusion-webui) 则表示没有启动conda环境,需要输入以下命令来启动:
conda activate stable-diffusion-webui
4.2 进入根目录,启动sd-webui项目
注意要先在windows命令窗口用cd 进入stable-diffusion-webui项目的根目录,如果你一直是按照上面步骤做下来的话,直接运行下面命令就可以进入(博主是直接git下载下来,然后放在其它目录,不用参考我的图片):
cd stable-diffusion-webui

接着运行下面命令:
webui-user.bat
然后回车,等待系统自动开始执行。直到系统提示:running on local URL: http://127.0.0.1:7860
注意:
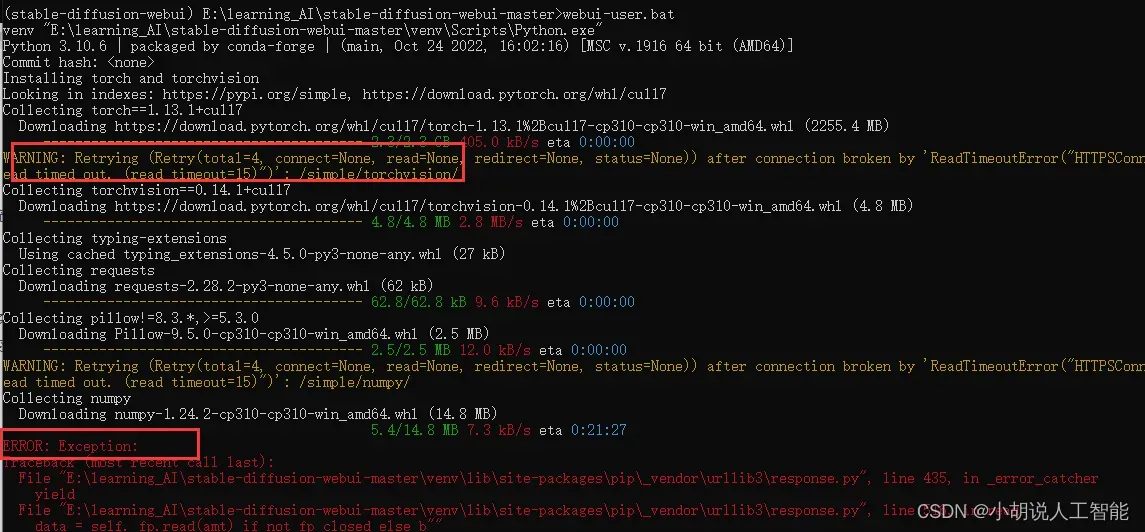
这一步可能经常各种报错,需要耐心和时间多次尝试。
不要关闭黑色小窗,哪怕它几分钟没有任何变化。
如果提示连接错误,可能需要开启魔法上网,再重新执行webui-user.bat命令(注意提前按照上面配置windows命令窗口使用魔法操作)。
六、使用stable diffusion
在浏览器中打开http://127.0.0.1:7860(注意,不要关闭上面运行的windows命令窗口)
1. 设置中文界面
注意,刚开始默认为英文显示界面,需要改成中文界面的话,可以按以下步骤操作。
先点击切换到【Extensions】,再点击【Available】,在【Hide extensions with tags】中,取消勾选“localization”,再点击【Load from】
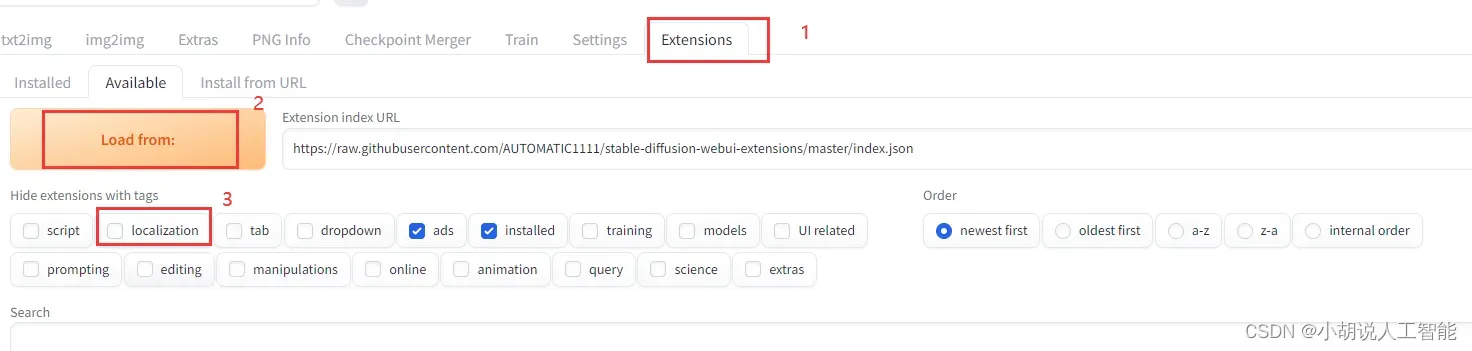
找到 zh_CN Localization 或 zh_TW Localization,点击Install按钮

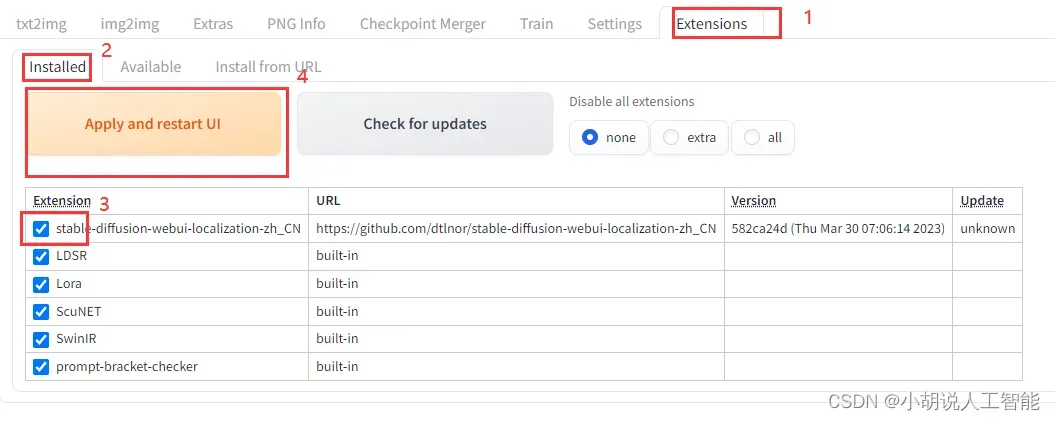
点击【 Installed】分页,确保页面下方已经勾选了“stable-diffusion-webui-localization-_”,点击【UI Apply and restart UI】,重启页面。
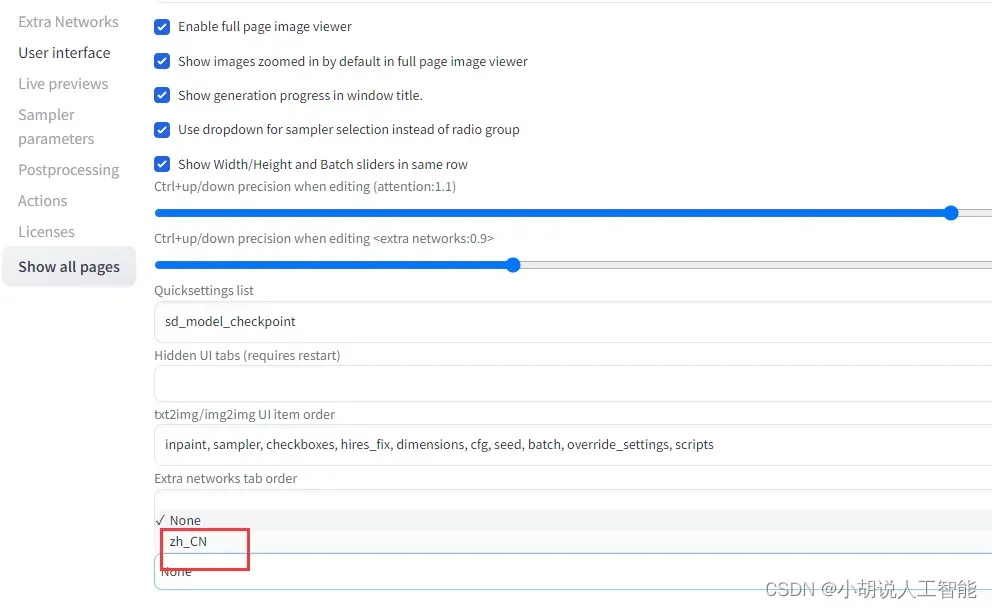
切换到【Settings】,左侧找到【User interface】,往下拉到底,下拉框内选择你需要的语言,比如zh_CN
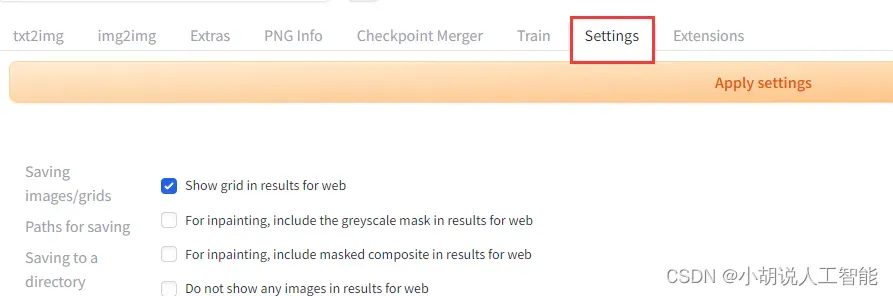
返回网页最上方,先点击【Apply settings】,再点击【UI Reload UI】

如果没有问题,你的界面就是中文的了。
2. 简单使用
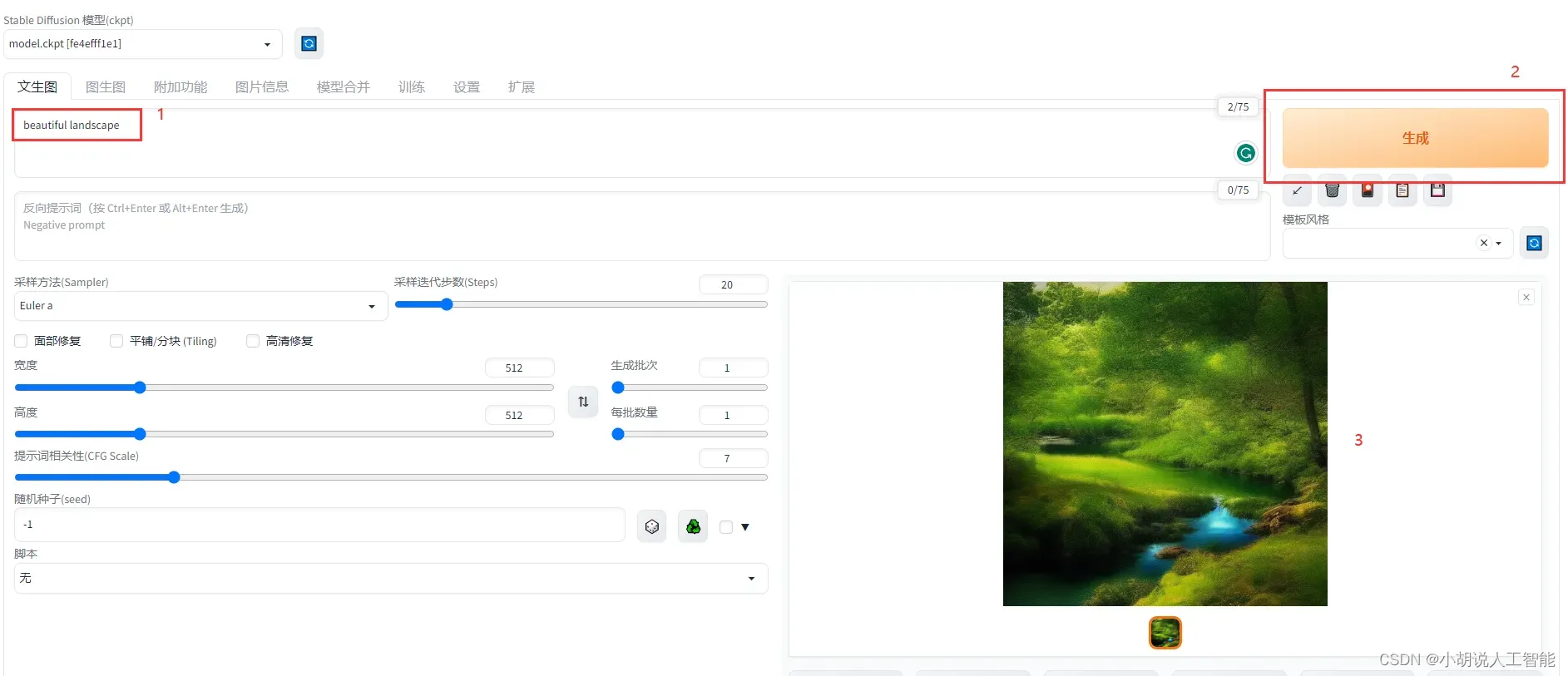
在prompt区域输入相关指令,比如beautiful landscape,然后点击右边的生成,即可生成第一张图片啦。
3. 进阶使用
篇幅有限,关于stable diffusion AI绘图各功能的详细操作,我这就不展开了。感兴趣的同学,可以上网搜索很多关于AI绘图tag/prompt的设置,也可以参考这篇博客。
总结
不得不说,现在sd-webui这个项目网页的交互功能,真的是好用多了,还加了很多新功能。
比如img2img功能,你可以对生成图片的一部分不满意的地方进行重新生成,比如嘴巴鼻子眼睛等。
甚至可以直接通过重新生成一部分内容的方式来换衣服。
还可以直接用extras功能放大生成的图片,最多放大4倍。(512512 放大4倍= 20482048)
博主大概花了1个小时就安装成功了,主要是用了魔法,很多时间就加速了。但小伙伴们可能在安装过程中还会遇到各种问题,如果解决不了,也可以在评论区评论或者找到我,无偿帮你调试哈。
当然如果你还是不想花那么多时间安装或者电脑没有高级显卡配置的花,博主后期会搭个服务器,到时免费开放给大家测试玩。
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
文章出处登录后可见!