今年已过半,要说上半年哪个最火,那必然是AIGC了,稳站热门榜C位。正因为这个原因,与AIGC相关的论文也逐渐多了起来,它在各研究方向的应用技术更新也非常迅速,简直要看不过来了…
所以今天我就来和大家分享最近看到的AIGC应用论文,简单整理了一下,总共有60+篇,篇幅原因,论文解析就不多写了,大部分只列了标题,感兴趣的同学可以找我获取之后仔细研读,有了心得体验也欢迎大家讨论。
GAN
CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
标题:CoralStyleCLIP: 图像编辑的协同优化区域和层选择
内容:本文提出了CoralStyleCLIP,它在StyleGAN2的特征空间中引入了多层注意力引导的混合策略,以获得高保真度的编辑。作者提出了共同优化的区域和层选择策略的多种形式,展示了在不同架构复杂度下,编辑质量与时间复杂度之间的变化,同时保持简单性。实验表明,CoralStyleCLIP可以实现高质量编辑,同时保持易用性。

-
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
-
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
-
Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
-
Improving GAN Training via Feature Space Shrinkage
-
Look ATME: The Discriminator Mean Entropy Needs Attention
-
NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
-
DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
-
Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
-
SIEDOB: Semantic Image Editing by Disentangling Object and Background
医学图像
High-resolution image reconstruction with latent diffusion models from human brain activity
标题:使用潜在扩散模型从人脑活动重构高分辨率图像
内容:作者提出使用基于扩散模型的新方法来从功能磁共振成像获得的人脑活动中重构图像,以理解大脑如何表示世界,以及解释计算机视觉模型与我们的视觉系统之间的联系。具体来说,作者依赖于一种称为Stable Diffusion的潜在扩散模型。该模型降低了扩散模型的计算成本,同时保持了它们的高生成性能,通过研究不同组件(如图像隐向量Z、条件输入C以及去噪UNet的不同元素)与不同大脑功能的关系来描述潜在扩散模型的内在机制。作者表明,该方法可以直截了当地重构高分辨率、高保真度的图像,而无需额外的训练和复杂深度学习模型的微调。

-
Leveraging GANs for data scarcity of COVID-19: Beyond the hype
-
Why is the winner the best?
-
Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
扩散模型
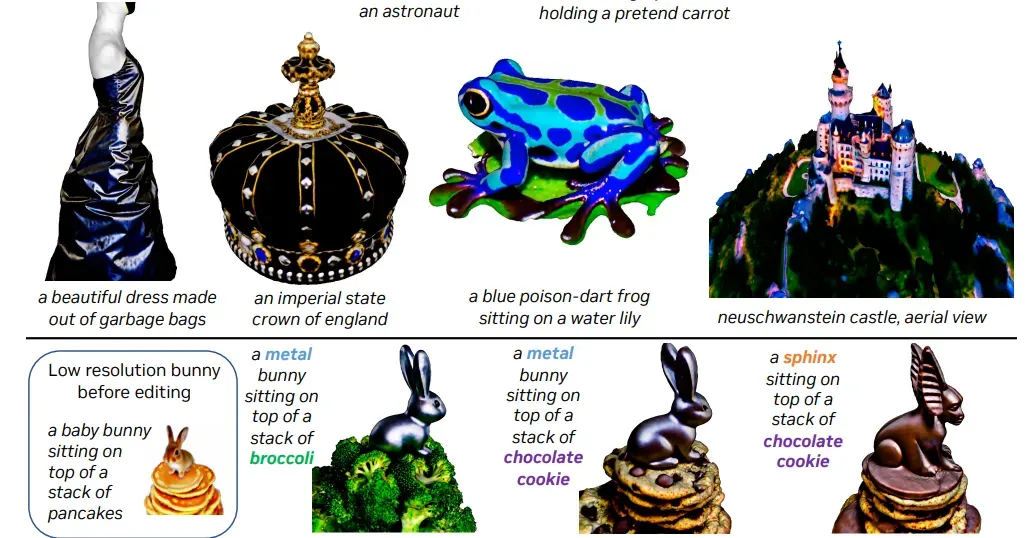
Magic3D: High-Resolution Text-to-3D Content Creation
标题:Magic3D: 高分辨率的文本到3D内容创建
内容:在本文中,作者通过利用两阶段优化框架来解决这些局限。首先,使用低分辨率扩散先验获得粗糙模型,并用稀疏3D哈希网格结构进行加速。利用粗略表示作为初始化,进一步优化具有高效可微渲染器的纹理3D网格模型,与高分辨率潜在扩散模型进行交互。该方法名为Magic3D,可以在40分钟内创建高质量的3D网格模型,比DreamFusion快2倍(据报告平均需要1.5小时),同时也实现了更高的分辨率。
-
TEXTure: Text-Guided Texturing of 3D Shapes
-
3DGen: Triplane Latent Diffusion for Textured Mesh Generation
-
Dreamix: Video Diffusion Models are General Video Editors
-
All are Worth Words: A ViT Backbone for Diffusion Models
-
Towards Practical Plug-and-Play Diffusion Models
-
Wavelet Diffusion Models are fast and scalable Image Generators
图像分割
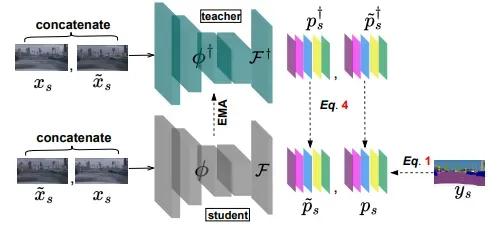
DiGA: Distil to Generalize and then Adapt for Domain Adaptive Semantic Segmentation
标题:DiGA: 先迁移泛化然后适应域自适应语义分割
内容:作者提出在热身阶段用一种新颖的对称知识蒸馏模块替换对抗训练,该模块仅访问源域数据并使模型具有域泛化能力。令人惊讶的是,这个域泛化的热身模型带来了实质性的性能提升,通过提出的跨域混合数据增强技术可以进一步放大。然后,对于自训练阶段,作者提出了一个无阈值的动态伪标签选择机制,以缓解上述阈值问题,使模型更好地适应目标域。大量实验表明,与现有技术相比,该框架在流行基准测试中取得了显著和持续的改进。
-
Generative Semantic Segmentation
-
Learning to Generate Text-grounded Mask for Open-world Semantic Segmentation from Only Image-Text Pairs
-
Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
域自适应、域泛化
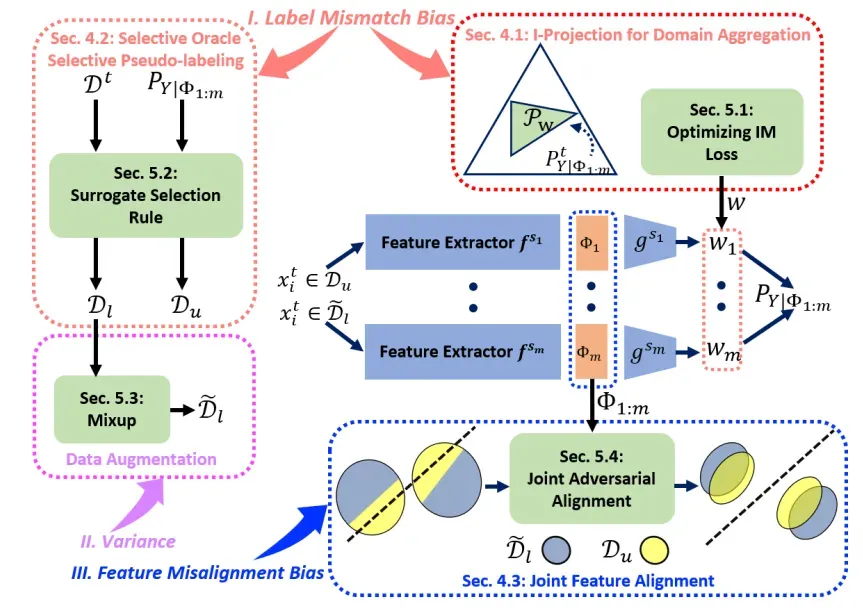
On Balancing Bias and Variance in Unsupervised Multi-Source-Free Domain Adaptation
标题:平衡偏差和方差在无监督多源无数据域自适应
内容:现有的多源无数据域自适应(MSFDA)方法通常使用源模型生成的伪标记数据来训练目标模型,这些方法聚焦于改进伪标记技术或提出新的训练目标。相反,作者旨在分析MSFDA的基本限制。特别是,作者推导了结果目标模型的泛化误差的一个信息论界,解释了一个固有的偏差-方差权衡。然后,从三个角度提供了如何平衡这种权衡的洞察,包括域聚合、选择性伪标记和联合特征对齐。
-
Sequential Counterfactual Risk Minimization
-
Provably Invariant Learning without Domain Information
-
Taxonomy-Structured Domain Adaptation
-
Generalization Analysis for Contrastive Representation Learning
-
Moderately Distributional Exploration for Domain Generalization
-
Distribution Free Domain Generalization
-
In Search for a Generalizable Method for Source Free Domain Adaptation
-
RLSbench: Domain Adaptation Under Relaxed Label Shift
-
Back to the Source: Diffusion-Driven Test-Time Adaptation
-
Domain Expansion of Image Generators
-
Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
图像转换/翻译
Masked and Adaptive Transformer for Exemplar Based Image Translation
标题:遮蔽自适应变压器用于范例基图像翻译
内容:本文提出了一个用于范例基图像翻译的新框架。最近的先进方法主要关注建立跨域语义对应关系,依次主导局部样式控制方式下的图像生成。不幸的是,跨域语义匹配具有挑战性,匹配错误最终降低生成图像的质量。为克服这个挑战,作者一方面提高了匹配的准确性,另一方面降低了匹配在图像生成中的作用。为实现前者,作者提出了一个遮蔽自适应变压器(MAT)来学习准确的跨域对应关系和执行上下文感知特征增强。为实现后者,我们使用输入的源特征和范例的全局样式代码作为补充信息,对图像进行解码。此外,作者还设计了一种新的对比样式学习方法,用于获取质量区分样式表示。

-
LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
-
Interactive Cartoonization with Controllable Perceptual Factors
-
LightPainter: Interactive Portrait Relighting with Freehand Scribble
-
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
-
Few-shot Semantic Image Synthesis with Class Affinity Transfer
可控文生图
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
标题:DreamBooth:微调文本到图像扩散模型实现主体驱动生成
内容:在本工作中,作者提出了一种“个性化”文本到图像扩散模型的新方法。给定很少的一些主体图像作为输入,作者微调一个预训练的文本到图像模型,以便它学习将唯一标识符与特定主体绑定。一旦主体嵌入到模型的输出域中,唯一标识符就可以用于在不同场景中合成主体的逼真图像。通过利用模型中嵌入的语义先验知识和一个新的自生类特定先验保留损失,作者的技术实现了在参考图像中没有出现的各种场景、姿势、视角和光照条件下合成主体的能力。

-
Ablating Concepts in Text-to-Image Diffusion Models
-
Multi-Concept Customization of Text-to-Image Diffusion
-
Imagic: Text-Based Real Image Editing with Diffusion Models
-
Shifted Diffusion for Text-to-image Generation
-
SpaText: Spatio-Textual Representation for Controllable Image Generation
-
Scaling up GANs for Text-to-Image Synthesis
-
GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
-
Variational Distribution Learning for Unsupervised Text-to-Image Generation
图像恢复
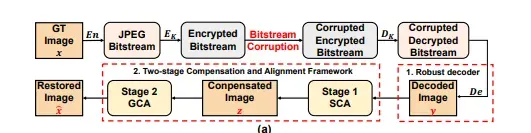
Bitstream-Corrupted JPEG Images are Restorable: Two-stage Compensation and Alignment Framework for Image Restoration
标题:比特流损坏的JPEG图像是可复原的:用于图像复原的两阶段补偿和对齐框架
内容:作者提出了一个稳健的JPEG解码器,后接一个两阶段的补偿和对齐框架来复原比特流损坏的JPEG图像。具体来说,稳健JPEG解码器采用了一个错误弹性机制来解码损坏的JPEG比特流。两阶段框架由自我补偿和对齐(SCA)阶段和引导补偿和对齐(GCA)阶段组成。SCA基于通过图像内容相似性估计的颜色和块位移自适应地进行块级图像颜色补偿和对齐。GCA利用从JPEG头中提取的低分辨率缩略图以粗细粒度指导全分辨率像素级图像复原。这是通过一个粗粒度引导pix2pix网络和一个细粒度引导的双向拉普拉斯金字塔融合网络实现的。
-
Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
-
Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
-
Generating Aligned Pseudo-Supervision from Non-Aligned Data forImage Restoration in Under-Display Camera
-
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
-
Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Model
-
Robust Model-based Face Reconstruction through Weakly-Supervised Outlier Segmentation
-
Robust Unsupervised StyleGAN Image Restoration
布局可控生成
LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
标题:可控布局到图像生成的扩散模型
内容:作者提出了一个名为LayoutDiffusion的扩散模型,相比以前的工作,它可以获得更高的生成质量和更大的可控性。为了克服图像和布局的困难多模融合,作者提出通过区域信息构建结构化的图像块,并将 patched 图像转换为特殊布局与正常布局以统一形式融合。此外,作者还提出了布局融合模块(LFM)和对象感知交叉注意力(OaCA),用于建模多个对象之间的关系,并设计为对象感知和位置敏感,从而可以精确控制空间相关信息。
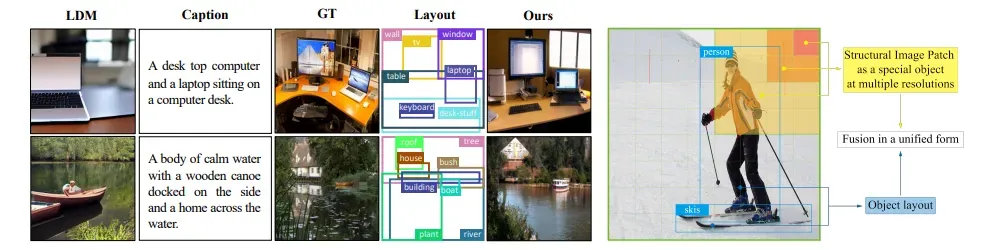
-
LayoutDM: Discrete Diffusion Model for Controllable Layout Generation
-
PosterLayout: A New Benchmark and Approach for Content-aware Visual-Textual Presentation Layout
-
Unifying Layout Generation with a Decoupled Diffusion Model
-
Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
关注下方《学姐带你玩AI》🚀🚀🚀
回复“AIGC论文”免费领取论文原文+代码合集
码字不易,欢迎大家点赞评论收藏!
文章出处登录后可见!